Java 中基于各种数据类型分析 == 和 equals 的区别
前言
Java 中的数据类型,可分为两类:
- 基本数据类型,也称原始数据类型。byte,short,char,int,long,float,double,boolean 它们之间的比较,应用双等号(==),比较的是它们的值。
- 复合数据类型(类)。当它们用双等号进行比较的时候,比较的是它们在内存中的存放地址,所以,除非是同一个 new 出来的对象,它们的比较后的结果为 true,否则比较后结果为 false。Java 当中所有的类都是继承于 Object 这个基类的,在 Object 中的基类中定义了一个 equals 的方法,这个方法的初始行为是比较对象的内存地址,但在一些类库当中这个方法被覆盖掉了,如 String,Integer,Date 在这些类当中 equals 有其自身的实现(在重写 equals 方法的时候,有必要重写对象的 hashCode 方法,从而保证程序完整性),而不再是比较类在堆内存中的存放地址了。
对于复合数据类型之间进行 equals 比较,在没有覆写 equals 方法的情况下,它们之间的比较还是基于它们在内存中的存放位置的地址值的,因为 Object 的 equals 方法也是用双等号进行比较的,所以比较后的结果跟双等号的结果相同。
分析
一、int 和 Integer
- int 是基本数据类型,Integer 是 int 的包装类,也叫做复合数据类型。
- Integer 变量必须实例化后才能使用;int 变量不需要;
- Integer 实际是对象的引用,指向此 new 的 Integer 对象;int 是直接存储数据值 ;
- Integer 的默认值是 null;int 的默认值是0。
1、Integer 对象使用 new 关键字生成
Integer i = new Integer(100);
Integer j = new Integer(100);
System.out.println("i == j:" + (i == j)); //false
System.out.println("i.equals(j):" + (i.equals(j))); //true
System.out.println("i.hashCode():" + i.hashCode());
System.out.println("j.hashCode():" + j.hashCode());
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:false i.equals(j):true i.hashCode():100 j.hashCode():100 i,it's memory address:356573597 j,it's memory address:1735600054 复制代码
正如上文提到的那样,复合数据类型使用双等号的时候是比较其在内存中的地址是否相同。一般而言,Object 的 hashCode()默认是返回内存地址的,在本例中直接输出对象的 hashCode 可以发现两者是一致的,那为什么==比较结果为 false呢?原因在于hashCode()可以重写,所以 hashCode()不能代表对象在内存的地址。System.identityHashCode(Object)方法可以得到对象的内存地址结果(严格意义上来讲,System.identityHashCode 的返回值和内存地址不相等的,该值是内存地址通过算法换算的一个整数值),不管该对象的类是否重写了 hashCode()方法。
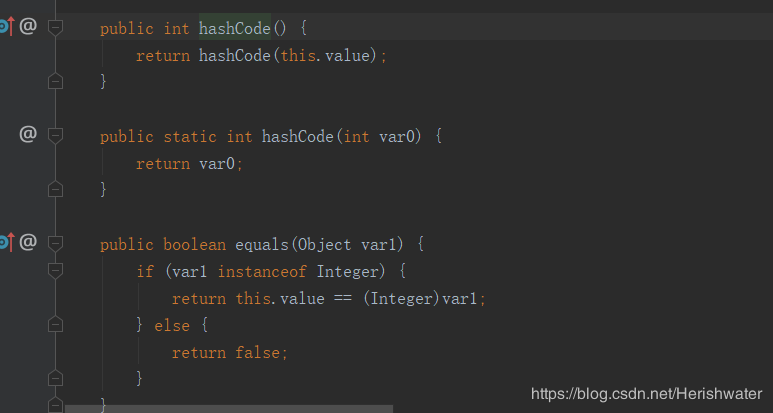
如上图所示,Integer 类中关于 equals()方法和 hashCode()方法进行了重写,所以如果想比对内存地址的不同,需要使用System.identityHashCode(Object)方法。
2、表面上不是 new 关键字生成的 Integer 对象
Integer i = 100;
Integer j = 100;
System.out.println("i == j:" + (i == j)); //true
System.out.println("i.equals(j):" + (i.equals(j))); //true
System.out.println("i.hashCode():" + i.hashCode());
System.out.println("j.hashCode():" + j.hashCode());
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:true i.equals(j):true i.hashCode():100 j.hashCode():100 i,it's memory address:21685669 j,it's memory address:21685669 复制代码
这里就不得不提出另一种情况:
Integer ii = 128;
Integer jj = 128;
System.out.println("ii == jj:" + (ii == jj)); //true
System.out.println("ii.equals(jj):" + (ii.equals(jj))); //true
System.out.println("ii.hashCode():" + ii.hashCode());
System.out.println("jj.hashCode():" + jj.hashCode());
System.out.println("ii,it's memory address:" + System.identityHashCode(ii));
System.out.println("jj,it's memory address:" + System.identityHashCode(jj));
//结果为
ii == jj:false
ii.equals(jj):true
ii.hashCode():128
jj.hashCode():128
ii,it's memory address:2133927002
jj,it's memory address:1836019240
复制代码
对于两个非 new 生成的 Integer 对象,进行比较时,如果两个变量的值在区间 -128 到 127 之间,则比较结果为 true,如果两个变量的值不在此区间,则比较结果为 false。通过打印出来的地址可以看出来,当不在指定区间范围时,实际上是两个不同的对象。
具体原因: Java 在编译 Integer i = 100 ;时,会翻译成为 Integer i = Integer.valueOf(100)。而 Java API 中对 Integer 类型的valueOf 的定义如下,对于-128 到 127 之间的数,会存储在缓存中,Integer i = 127 时,会直接从缓存中获取,下次再 Integer j = 127时,同样从缓存中取,而不会 new 个新对象。
public static Integer valueOf(int var0) {
return var0 >= -128 && var0 <= Integer.IntegerCache.high ? Integer.IntegerCache.cache[var0 + 128] : new Integer(var0);
}
复制代码
其中 IntegerCache 类是 Integer 类的内部类,源代码如下:
private static class IntegerCache {
static final int low = -128;
static final int high;
static final Integer[] cache;
private IntegerCache() {
}
static {
int var0 = 127;
String var1 = VM.getSavedProperty("java.lang.Integer.IntegerCache.high");
int var2;
if (var1 != null) {
try {
var2 = Integer.parseInt(var1);
var2 = Math.max(var2, 127);
var0 = Math.min(var2, 2147483518);
} catch (NumberFormatException var4) {
}
}
high = var0;
cache = new Integer[high - -128 + 1];
var2 = -128;
for(int var3 = 0; var3 < cache.length; ++var3) {
cache[var3] = new Integer(var2++);
}
assert high >= 127;
}
}
复制代码
结合这两部分代码可以看出,当数值大小超过 127 时,就要调用 new Integer(Object),重新生成一个 Integer 对象,所以在区间范围外,== 比较返回结果为 false。
3、两个 int 变量比较
int i = 100;
int j = 100;
System.out.println("i == j:" + (i == j)); //false
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:true i,it's memory address:21685669 j,it's memory address:21685669 复制代码
对于这种简单数据类型,== 比较符就是比较它们的值大小。
4、new 生成的 Integer 对象和 int 变量比较
Integer i = new Integer(100);
int j = 100;
System.out.println("i == j:" + (i == j));
System.out.println("i.hashCode():" + i.hashCode());
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:true i.hashCode():100 i,it's memory address:2133927002 j,it's memory address:356573597 复制代码
基本数据类型 int 和它的包装类 Integer 比较时,Java 会自动拆包装为 int(将复合数据类型转化为基本数据类型),然后进行比较,实际上就变为两个 int 变量的比较。即使打印出来的地址不同,但是比较结果仍为 true,主要原因是因为不是通过比较内存地址进行判断的。
5、非 new 生成的 Integer 对象和 int 变量比较
int j = 100;
Integer k = 100;
System.out.println("j == k:" + (j == k));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
System.out.println("k,it's memory address:" + System.identityHashCode(k));
int ii = 128;
Integer jj = 128;
System.out.println("ii == jj:" + (ii == jj));
System.out.println("ii,it's memory address:" + System.identityHashCode(ii));
System.out.println("jj,it's memory address:" + System.identityHashCode(jj));
复制代码
执行结果为:
j == k:true j,it's memory address:356573597 k,it's memory address:356573597 ii == jj:true ii,it's memory address:2133927002 jj,it's memory address:1836019240 复制代码
比较结果都为 true,因为同 4 一样,由于自动拆箱的特性,其实是进行值的比较,所以结果为 true。接着分析打印的内存地址,当在[-128,127]区间范围内时,Integer 数组(参考 Integer 类中的 IntegerCache)是存放在常量池中的,而 int 变量同样也是,所以值相等时,内存地址一致。
6、非 new 生成的 Integer 对象和 new Integer()生成的对象
Integer i = new Integer(100); Integer j = 100; System.out.print(i == j); //false 复制代码
因为非 new 生成的 Integer 变量指向的是 Java 常量池中的对象,而 new Integer()生成的变量指向堆中新建的对象,两者在内存中的地址不同。
7、面试题
Integer i1 = 125;
Integer i2 = 125;
Integer i3 = 0;
Integer i4 = new Integer(127);
Integer i5 = new Integer(127);
Integer i6 = new Integer(0);
System.out.println("i1==i2:/t" + (i1 == i2));
System.out.println("i1==i2+i3:/t" + (i1 == i2 + i3));
System.out.println("i4==i5:/t" + (i4 == i5));
System.out.println("i4==i5+i6:/t" + (i4 == i5 + i6));
i3 = 5;
Integer i7 = 130;
System.out.println("i7==i2+i3:/t" + (i7 == i2 + i3));
复制代码
执行结果为:
i1==i2: true i1==i2+i3: true i4==i5: false i4==i5+i6: true i7==i2+i3: true 复制代码
对于 i1 == i2 + i3 、 i4 == i5 + i6 和 i7 == i2 + i3 结果为 true,是因为, Java 的数学计算是在内存栈里操作的 ,Java 会对 i5、i6 进行拆箱操作,其实比较的是基本类型(127=127+0),他们的值相同,因此结果为 true。对 i2+i3 来说,结果是在内存栈中(同 int 基本类型一样),所以不管是与 i1 还是 i7 比较,返回结果都为 true。
二、double 和 Double
1、new 生成的两个 Double 对象比较
Double i = new Double(100.0);
Double j = new Double(100.0);
System.out.println("i == j:" + (i == j));
System.out.println("i.equals(j):" + (i.equals(j)));
System.out.println("i.hashCode():" + i.hashCode());
System.out.println("j.hashCode():" + j.hashCode());
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:false i.equals(j):true i.hashCode():1079574528 j.hashCode():1079574528 i,it's memory address:1163157884 j,it's memory address:1956725890 复制代码
分别生成了两个不同的对象,地址也不同,所以比较结果范围为 false。此外,看到打印的 hashCode() 结果一致,再去看一下 Double 类源码可以发现,也重写了 equals 方法和 hashCode 方法。
2、表面上非 new 生成的 Double 对象比较
Double i = 100.0;
Double j = 100.0;
System.out.println("i == j:" + (i == j));
System.out.println("i.equals(j):" + (i.equals(j)));
System.out.println("i.hashCode():" + i.hashCode());
System.out.println("j.hashCode():" + j.hashCode());
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:false i.equals(j):true i.hashCode():1079574528 j.hashCode():1079574528 i,it's memory address:356573597 j,it's memory address:1735600054 复制代码
自动装箱,解析为 Double i = new Double(100.0); 因此实际上还是两个不同的对象。
3、new 生成的 Double 对象和 double 变量比较
Double i = 100.0;
double j = 100.0;
System.out.println("i == j:" + (i == j));
System.out.println("i.equals(j):" + (i.equals(j)));
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果为:
i == j:true i.equals(j):true i,it's memory address:21685669 j,it's memory address:2133927002 复制代码
自动拆箱,转换为 double 变量进行值比较。
三、float 和 Float
与 double 比较一致,只是两者的范围大小有差异,double 类型的取值范围更广。
四、short 和 Short
Short i = new Short(new Integer(100).shortValue());
Short j = new Short(new Integer(100).shortValue());
System.out.println("i == j:" + (i == j)); //false
System.out.println("i.equals(j):" + (i.equals(j))); //true
System.out.println("i.hashCode():" + i.hashCode());
System.out.println("j.hashCode():" + j.hashCode());
System.out.println("i,it's memory address:" + System.identityHashCode(i));
System.out.println("j,it's memory address:" + System.identityHashCode(j));
复制代码
执行结果:
i == j:false i.equals(j):true i.hashCode():100 j.hashCode():100 i,it's memory address:1163157884 j,it's memory address:1956725890 复制代码
new 生成的 Short 对象是两个独立的,所以比较结果为 false。
五、long 和 Long
同 Integer 类一样,Long 类中也有一个内部类 LongCache,源码如下:
private static class LongCache {
static final Long[] cache = new Long[256];
private LongCache() {
}
static {
for(int var0 = 0; var0 < cache.length; ++var0) {
cache[var0] = new Long((long)(var0 - 128));
}
}
}
复制代码
使用同 Integer 一样,在[-128,127]区间范围内,也是使用 Long.valueOf(),在这个区间范围内的比较返回结果为 true。更多使用参考第一部分。
六、char 和 Character
char 类型存放的是字符型数据,常用范围:大写字母(A-Z):65 (A)~ 90(Z);小写字母(a-z):97(a) ~ 122(z);字符数字('0' ~ '9'):48('0') ~ 57('9')。char 和 int 直接可以相互转换,所以在使用上很相似,不同的是 Character i = 'a'; 这样声明时,区间范围为[0,127]。
七、String 比较
前面讲了那么多,终于来到 String 比较,本意上是记录关于 String 用==比较的情况,但是在学习的过程中,又重新了解了其他的数据类型,所以一并记录下来。
1、引用指向常量池中 String 常量时比较
String s1 = "abc";
String s2 = "abc";
System.out.println("s1 == s2:"+(s1 == s2));
System.out.println("s1.equals(s2):"+s1.equals(s2));
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println("s1,it's memory address:" + System.identityHashCode(s1));
System.out.println("s2,it's memory address:" + System.identityHashCode(s2));
复制代码
执行结果为:
s1 == s2:true s1.equals(s2):true 96354 96354 s1,it's memory address:1163157884 s2,it's memory address:1163157884 复制代码
首先说 s1 和 s2,在栈中开辟两块空间存放引用 s1 和 s2,在给 s1 赋值的时候去常量池中查找,第一次初始化的常量池为空的,所以是没有的,则在字符串常量池中开辟一块空间,存放 String 常量"abc",并把引用返回给 s1,当 s2 也是这样的过程,在常量池中找到了,所以 s1 和 s2 指向相同的引用,即 s1==s2 和 s1.equals(s2)都为 true。
String 类中重写了 equals 方法和 hashCode 方法,源码如下:
public boolean equals(Object var1) {
if (this == var1) {
return true;
} else {
if (var1 instanceof String) {
String var2 = (String)var1;
int var3 = this.value.length;
if (var3 == var2.value.length) {
char[] var4 = this.value;
char[] var5 = var2.value;
for(int var6 = 0; var3-- != 0; ++var6) {
if (var4[var6] != var5[var6]) {
return false;
}
}
return true;
}
}
return false;
}
}
public int hashCode() {
int var1 = this.hash;
if (var1 == 0 && this.value.length > 0) {
char[] var2 = this.value;
for(int var3 = 0; var3 < this.value.length; ++var3) {
var1 = 31 * var1 + var2[var3];
}
this.hash = var1;
}
return var1;
}
复制代码
因此当值内容相同时,计算得到的 hashCode() 值也是一致的。
2、引用指向堆空间中 String 对象
String s1 = new String("abc");
String s2 = new String("abc");
System.out.println("s1 == s2:"+(s1 == s2));
System.out.println("s1.equals(s2):"+s1.equals(s2));
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println("s1,it's memory address:" + System.identityHashCode(s1));
System.out.println("s2,it's memory address:" + System.identityHashCode(s2));
//sb.toString()相当于生成一个新的String对象
StringBuffer sb = new StringBuffer("abc");
String s3 = sb.toString();
System.out.println("s1 == s3:"+(s1 == s3));
System.out.println("s3,it's memory address:" + System.identityHashCode(s3));
复制代码
执行结果为:
s1 == s2:false s1.equals(s2):true 96354 96354 s1,it's memory address:1956725890 s2,it's memory address:356573597 s1 == s3:false s3,it's memory address:1735600054 复制代码
首先在栈中开辟两块块空间存放引用 s1 和 s2,然后是创建两个对象,在创建对象的时候是在堆里面开辟了一个空间,两个对象自然地地址空间就不相同,这点从打印结果上就可以看出,所以在 s1==s2 是为 false。另外有时会使用到 StringBuffer 对象,再调用 toString() 方法,根据源码可知,该方法也是创建一个新的对象,所以 s1==s3 结果为 false。
public synchronized String toString() {
if (this.toStringCache == null) {
this.toStringCache = Arrays.copyOfRange(this.value, 0, this.count);
}
return new String(this.toStringCache, true);
}
复制代码
3、String 常量与 String 对象比较
String s1 = "abc";
String s2 = new String("abc");
System.out.println("s1 == s2:"+(s1 == s2));
System.out.println("s1.equals(s2):"+s1.equals(s2));
System.out.println(s1.hashCode());
System.out.println(s2.hashCode());
System.out.println("s1,it's memory address:" + System.identityHashCode(s1));
System.out.println("s2,it's memory address:" + System.identityHashCode(s2));
String s3 = s2.intern();
System.out.println("s1 == s3:"+(s1 == s3));
System.out.println("s3,it's memory address:" + System.identityHashCode(s3));
复制代码
执行结果为:
s1 == s2:false s1.equals(s2):true 96354 96354 s1,it's memory address:1163157884 s2,it's memory address:1956725890 s1 == s3:true s3,it's memory address:1163157884 复制代码
s1 指向的是字符串常量池中的“abc”,s2 指向堆中的 String 对象“abc”,所以地址不相同,比较结果也就为 false。再者,String 类中的 intern()方法会从常量池中查找是否存在这样的值,如果存在则直接返回,不存在则往常量池中插入一个新的这样的值,然后返回。

在讲解上图之前,先看一组代码:
String s2 = new String("abc");
String s3 = s2.intern();
String s1 = "abc"; //由于此时常量池中已经有”abc“常量,所以s1直接指向”abc“
System.out.println(s1 == s3);
System.out.println("s1,it's memory address:" + System.identityHashCode(s1));
System.out.println("s3,it's memory address:" + System.identityHashCode(s3));
//执行结果
true
s1,it's memory address:1163157884
s3,it's memory address:1163157884
复制代码
黄色箭头的含义:当通过 new 生成字符串对象时,会先去常量池中查找是否存在”abc“值,如果没有则会在常量池中新建一个,然后堆中再创建一个常量池中此”abc”值的拷贝对象。
4、String 常量做拼接操作后比较
String s = "abc";
//第一种情况
String s2 = "ab";
String s4 = s2 + "c";
String s6 = new String("ab");
String s7 = s6 + "c";
System.out.println("s4,it's memory address:" + System.identityHashCode(s4));
System.out.println("s7,it's memory address:" + System.identityHashCode(s7));
System.out.println("s == s4:"+(s == s4));
System.out.println("s == s7:"+(s == s7));
//第二种
final String s1 = "ab";
String s3 = s1 + "c";
String s5 = "ab" + "c";
System.out.println("s,it's memory address:" + System.identityHashCode(s));
System.out.println("s3,it's memory address:" + System.identityHashCode(s3));
System.out.println("s5,it's memory address:" + System.identityHashCode(s5));
System.out.println("s == s3:"+(s == s3));
System.out.println("s == s5:"+(s == s5));
//第三种
final String s8 = getData();
String s9 = s8 + "c";
System.out.println("s == s9:"+(s == s9));
System.out.println("s9,it's memory address:" + System.identityHashCode(s9));
复制代码
执行结果为:
s4,it's memory address:1163157884 s7,it's memory address:1956725890 s == s4:false s == s7:false s,it's memory address:356573597 s3,it's memory address:356573597 s5,it's memory address:356573597 s == s3:true s == s5:true s == s9:false s9,it's memory address:1735600054 复制代码
分析:
情况 1,JVM 对于字符串引用,由于在字符串的"+"连接中,有字符串引用存在,而引用的值在程序编译期是无法确定的,即 s2+"c" 或 s6+"c" 无法被编译器优化,只有在程序运行期来动态分配并将连接后的新地址赋给 s4 和 s7。所以上面程序的结果也就为 false。
情况 2,和 1 唯一不同的是 s1 字符串加了 final 修饰,对于 final 修饰的变量,它在编译时被解析为常量值的一个本地拷贝存储到自己的常量池中或嵌入到它的字节码流中。所以此时 s1+"c" 和 "ab"+"c" 效果是一样的,故上面的结果为 true。
情况 3,JVM 对于字符串引用 s8,它的值在编译期无法确定,只有在程序运行期调用方法后,将方法的返回值和”c“来动态连接并分配地址为 s9,故上面程序的结果为 false。
5、面试题
public class AAA {
public static void main(String[] args) {
// TODO Auto-generated method stub
String hello = "Hello", lo = "lo";
System.out.print((hello == "Hello") + " ");
System.out.print((Other.hello == hello) + " ");
System.out.print((other.Other.hello == hello) + " ");
System.out.print((hello == ("Hel" + "lo")) + " ");
System.out.print((hello == ("Hel" + lo)) + " ");
System.out.println(hello == ("Hel" + lo).intern());
System.out.println(System.identityHashCode(hello ));
System.out.println(System.identityHashCode(Other.hello ));
System.out.println(System.identityHashCode(other.Other.hello));
}
}
class Other {
static String hello = "Hello";
}
复制代码
package other;
public class Other {
static String hello = "Hello";
}
复制代码
执行结果为:
true true true true false true 1163157884 1163157884 1163157884 复制代码
重点说一下,在同包不同类下,引用自同一 String 对象相比较结果为 true。在不同包不同类下,依然引用自同一 String 对象。
结论:
字符串是一个特殊包装类,其引用是存放在栈里的,而对象内容必须根据创建方式不同定(常量池和堆).有的是编译期就已经创建好,存放在字符串常量池中,而有的是运行时才被创建,使用new关键字,存放在堆中。
总结
平时经常使用的数据类型,没有多去了解一下其内部的结构,对于一些概念性东西只是靠记忆,没有想过为何会是这样的结果。通过这次学习,不仅认识到了 int 和 Integer 的特殊,也对 String 类型有了一个较好的了解,对于数据在内存中的存储也有了一定的认识,从而对于“ == 和 equals 的区别”这样的问题也是豁然开朗。
参考链接
- www.cnblogs.com/dolphin0520…
- www.cnblogs.com/zhxhdean/ar…
- blog.csdn.net/xqhys/artic…
- blog.csdn.net/why15732625…
- www.cnblogs.com/SaraMoring/…
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

