Java 基础:String——常量池与 intern
在 Java 中方法区与常量池 一节中有讲到常量池的分类,以及三种常量池之间的关联,其中有提到 String 类中的 intern() 方法,可以在运行期间将 Class 文件常量池中未出现的常量放入到运行时常量池,以及将字符串对象的引用加入到全局字符串常量池中。
本章节接着上节对 String 源码的学习,对 String 类中的 intern() 方法进行更加深入的分析总结。
字符串字面量
字面量 一词我最早是在学习 Class 文件常量池中接触到的,之前也没有详细了解过,经查询相关资料得知, 字符串字面量 是在 Java™语言规范的 3.10.5. String 字面量 中定义的。关于字符串字面量通俗点解释就是,使用双引号""创建的字符串,在堆中创建了对象后其引用插入到字符串常量池中(jdk1.7后),可以全局使用,遇到相同内容的字面量,就不需要再次创建。举个例子:
String str1 = "abc"; //运行时会在堆中新建一个“abc”的对象,然后将其引用存入到字符串常量池中,且返回给 str1
String str2 = new String("abc"); //运行时会先去字符串常量池中查看是否有“abc”对象的引用,如果有则不需要创建。之后在堆中创建一个“abc”对象,将该对象的引用返回给 str2
复制代码
字符串常量池
上一节中主要讲述了字符串常量池的存放位置和存放内容,这里讲点更加详细的内容。
首先是字符串常量池中存放内容的验证,在 jdk6 中,常量池的位置在永久代(方法区)中,此时常量池中存储的是对象。在 jdk7中,常量池的位置在堆中,此时,常量池存储的是引用。在 jdk8 中,永久代(方法区)被元空间取代了。下面我们通过一个例子进行验证:
String s1 = new String("abc");
String s2 = s1.intern();
String s3 = "abc";
System.out.println(s1 == s3);
System.out.println(s2 == s3);
System.out.println(System.identityHashCode(s1));
System.out.println(System.identityHashCode(s3));
String s4 = new String("3") + new String("3");
String s5 = s4.intern();
String s6 = "33";
System.out.println(s4 == s6);
System.out.println(s5 == s6);
System.out.println(System.identityHashCode(s4));
System.out.println(System.identityHashCode(s6));
复制代码
执行结果:
jdk6 false true 536468534 796216018 false true 1032010069 1915296511 jdk7 false true 1163157884 1956725890 true true 356573597 356573597 复制代码
为了更好的解释,我们用图解的方式来分析究竟发生了什么。
JDK6
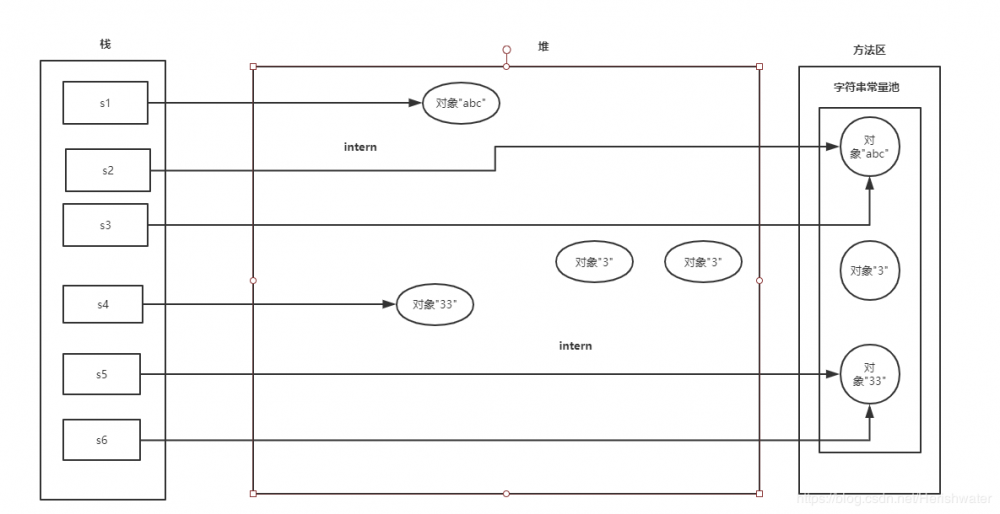
String s1 = new String("abc") ; 运行时创建了两个对象,一个是在堆中的”abc“对象,一个是在字符串常量池中的”abc”对象,将堆中对象的地址返回给 s1。
String s2 = s1.intern() ; 在常量池中寻找与 s1 变量内容相同的对象,发现已经存在内容相同对象“abc”,返回该对象的地址,赋值给 s2。
String s3 = "abc" ; 首先在常量池中寻找是否有相同内容的对象,发现有,返回对象"abc"的地址,赋值给 s3。
String s4 = new String("3") + new String("3") ;运行时创建了四个对象,一个是在堆中的“33”对象,一个是在常量池中的“3“对象。中间还有2个匿名的 new String("3") 这里我们不去讨论它们。
String s5 = s4.intern() ;在常量池中寻找与 ”33“对象内容相同的对象,没有发现“33”对象,在常量池中创建“33”对象,返回“33”对象的地址给 s5。
String s6 = "33" ;首先在常量池中寻找是否有相同内容的对象,发现有,返回对象"33"的地址,赋值给 s6。
System.out.println(s4 == s6); 从上面可以分析出,s4 变量和 s6 变量地址指向的不是相同的对象,所以返回 false。
JDK7
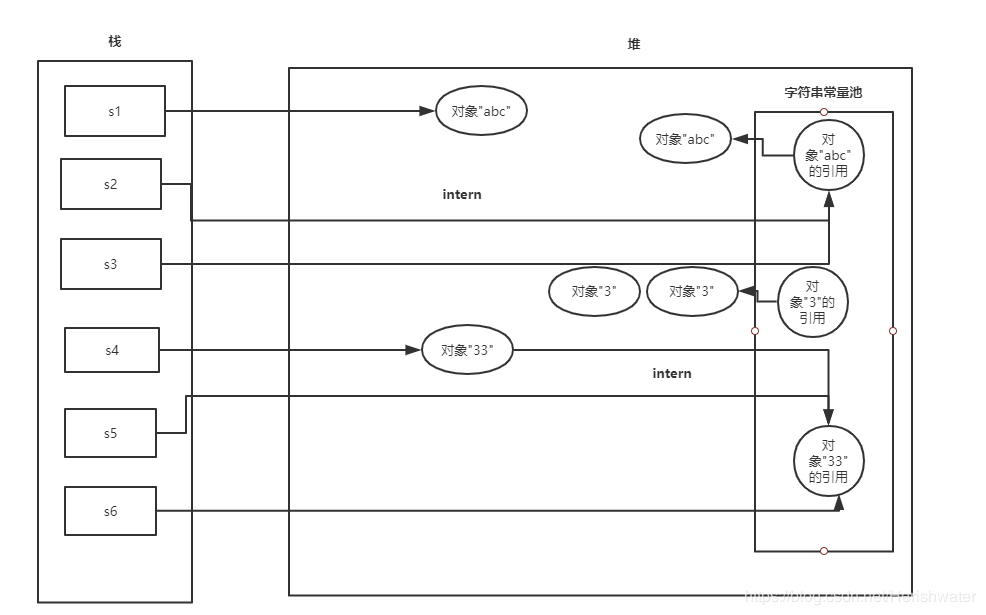
String s1 = new String("abc")
; 运行时创建了两个对象,一个是在堆中的”abc“对象,一个是在堆中创建的”abc”对象,并在常量池中保存“abc”对象的引用地址。
String s2 = s1.intern() ; 在常量池中寻找与 s1 变量内容相同的对象引用,发现已经存在内容相同对象“abc”的引用,返回该对象引用地址,赋值给 s2。
String s3 = "abc" ; 首先在常量池中寻找是否有相同内容的对象引用,发现有,返回对象"abc"的引用地址,赋值给 s3。
String s4 = new String("3") + new String("3") ;运行时创建了四个对象,一个是在堆中的“33”对象,一个是在堆中创建的”3”对象,并在常量池中保存“3”对象的引用地址。中间还有2个匿名的 new String("3") 这里我们不去讨论它们。
String s5 = s4.intern() ;在常量池中寻找与 ”33“对象内容相同的对象引用,没有发现“33”对象引用,将 s4 对应的”33“对象的地址保存到常量池中,并返回给 s5。
String s6 = "33" ;首先在常量池中寻找是否有相同内容的对象引用,发现有,返回对象"33"的引用地址,赋值给 s6。
System.out.println(s4 == s6); 从上面可以分析出,s4 变量和 s6 变量地址指向的是相同的对象,所以返回 true。
综上我们可以看出,字符串常量池中存放的内容在 jdk6 和 jdk7 中是不一样的,前者存放对象,后者存放对象的引用。
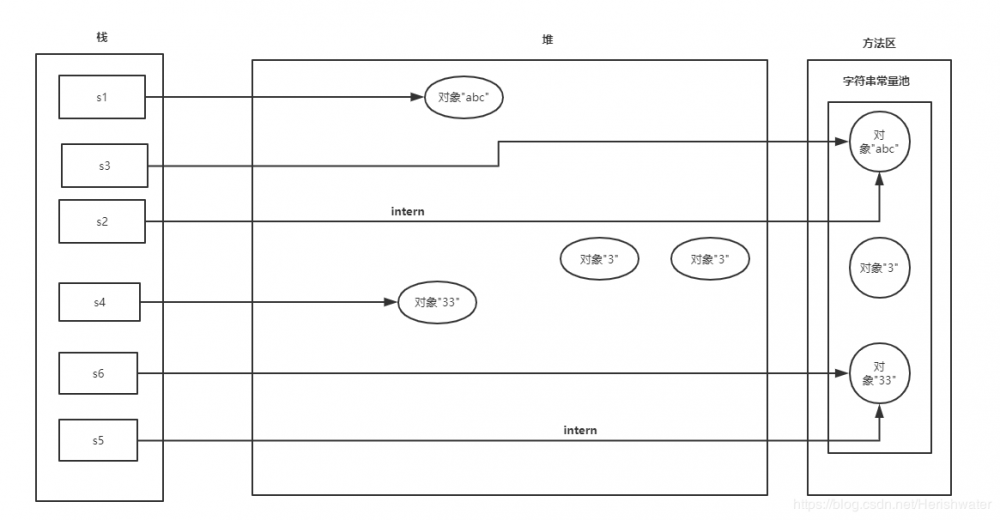
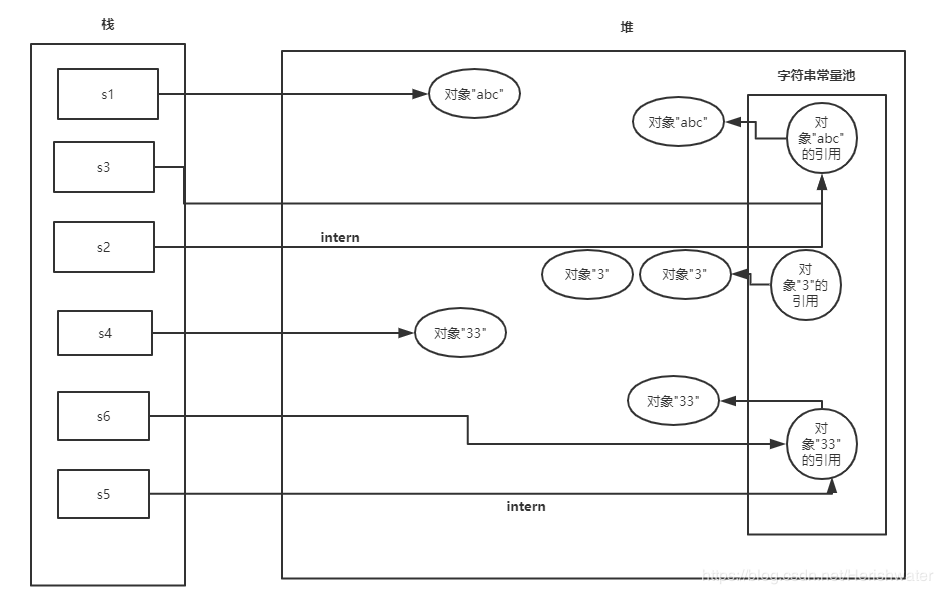
为了弄明白 intern()方法,对于上述的代码进行调整,来看看结果如何。
String s1 = new String("abc");
String s3 = "abc";
String s2 = s1.intern();
System.out.println(s1 == s3);
System.out.println(s2 == s3);
String s4 = new String("3") + new String("3");
String s6 = "33";
String s5 = s4.intern();
System.out.println(s4 == s6);
System.out.println(s5 == s6);
复制代码
执行结果:
jdk6 false true false true jdk7 false true false true 复制代码
原理很简单,因为在调用 intern 方法前,先使用了字面量赋值语句,所以在常量池中都存在了与变量相同内容的对象(jdk6)或对象的引用(jdk7+),此时再调用 intern 方法,就会发现常量池里的对象地址和变量的地址不是指向同一个对象,自然就 false了。
JDK6
JDK7
字符串字面量是何时进入字符串常量池
//代码一
String s4 = new String("3") + new String("3");
String s6 = "33";
String s5 = s4.intern();
System.out.println(s4 == s6);
System.out.println(s5 == s6);
//代码二
String s4 = new String("3") + new String("3");
String s6 = "33";
String s5 = s4.intern();
复制代码
对该代码进行编译,之后通过 javap 命令查看其字节码。
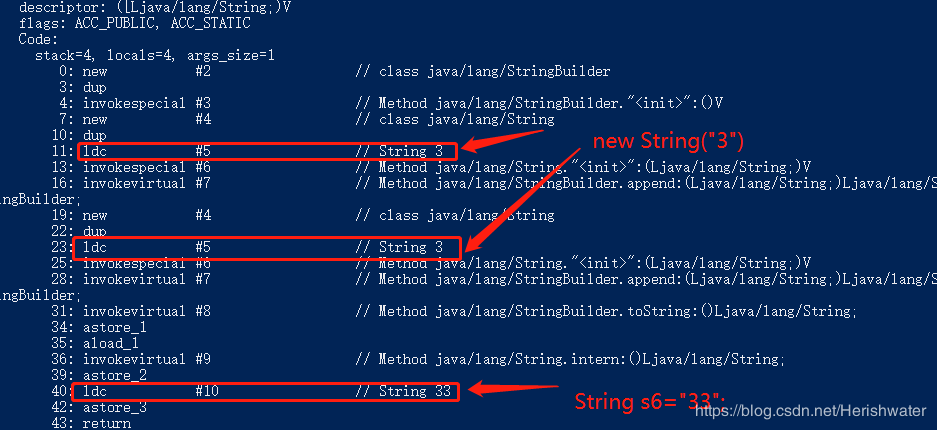
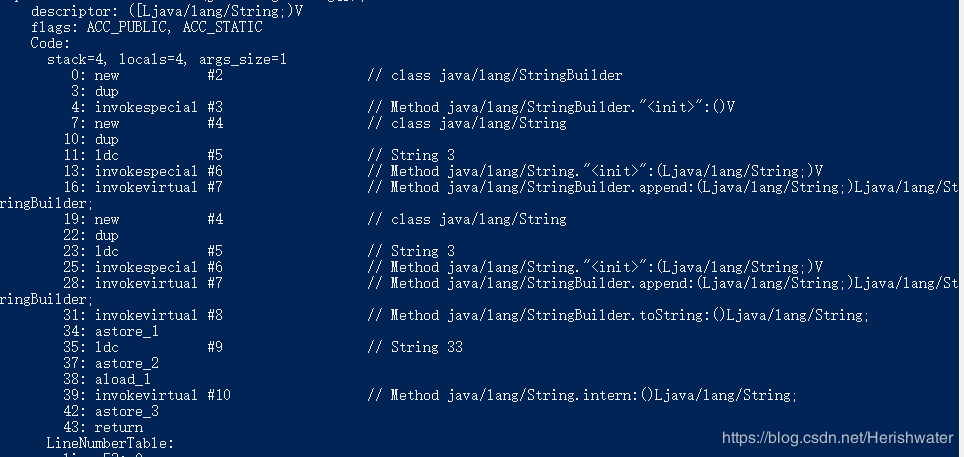
String s5 = s4.intern(); 的时候字符串常量池中是没有“33”对象的引用,在代码二中执行
String s5 = s4.intern(); 语句在字符串常量池中发现有“33”对象的引用,区别就在于
String s6 = "33"; 那么什么时候 Class 文件常量池中的字面量进入到字符串常量池中的呢?在上一节
Java 中方法区与常量池 中三种常量池的关联一栏有做解释,如有不懂,可以前往知乎参看
new String(“字面量”) 中 “字面量” 是何时进入字符串常量池的?
,这位大神对此做了详细的讲解。
简单来说:
- HotSpot VM 的实现来说,加载类的时候,那些字符串字面量会进入到当前类的运行时常量池,不会进入全局的字符串常量池 ;在 resolve (解析)之后,才会在堆中创建对应这些 class 文件常量池中的字符串对象实例,并在字符串常量池中驻留其引用。
- 在字面量赋值的时候,会翻译成字节码 ldc 指令,ldc 指令触发 lazy resolution 动作
到当前类的运行时常量池(runtime constant pool,HotSpot VM里是ConstantPool + ConstantPoolCache)去查找该 index 对应的项
如果该项尚未 resolve 则 resolve 之,并返回 resolve 后的内容。
在遇到 String 类型常量时,resolve 的过程如果发现 StringTable 已经有了内容匹配的 java.lang.String 的引用,则直接返回这个引用;
如果 StringTable 里尚未有内容匹配的 String 实例的引用,则会在 Java 堆里创建一个对应内容的 String 对象,然后在 StringTable 记录下这个引用,并返回这个引用出去。
String s=new String("xyz") 涉及到几个对象
之前一直有个结论就是:当创建一个 string 对象的时候,去字符串常量池看是否有相应的字面量,如果没有就创建一个。
这个说法从来都不正确。
关于上述观点,可以查看 R大的回答: new一个String对象的时候,如果常量池没有相应的字面量真的会去它那里创建一个吗?我表示怀疑。
回到正题,宝典上有这样的面试题,当时记忆面试题的时候,原题是这样“ String s = new String("xyz"); 创建了几个String Object? ”,答案是两个或一个,如果常量池中有“xyz”对象的引用,则仅创建了一个对象;反之则创建了两个对象。
通过这段时间对 String 对象的学习,以及 JVM 内存的了解,回头再看这个问题,会觉得该面试题首先提问就存在歧义,主旨不清晰,当然也就没有合理的答案。接下来会介绍到 对象的创建和类加载机制 。
关于 对象的创建 ,用图解的形式展示:
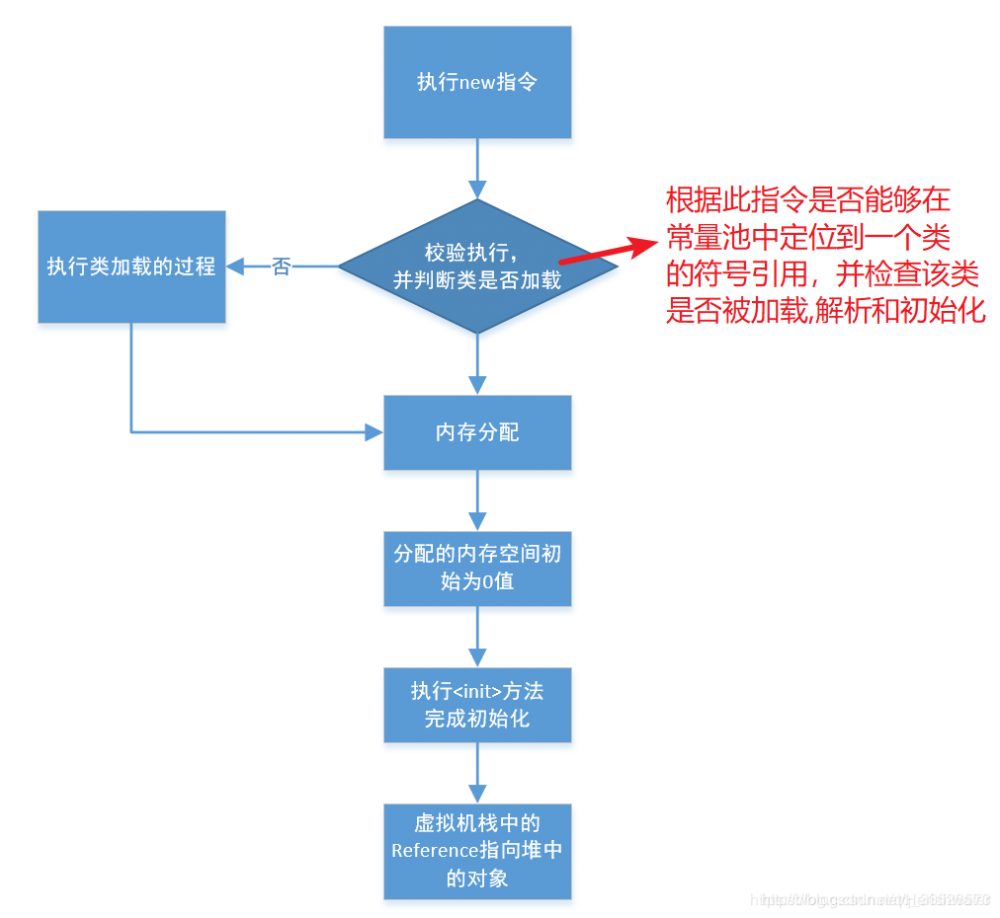
从图中我们可以发现对象创建的步骤如下
- 执行 new 指令
- 检查这个指令参数是否能够在常量池中定位到一个类的符号引用,并且检查这个符号引用所代表的类是否已经被加载,解析和初始化。
- 如果该类没有被加载则先执行类的加载操作
- 如果该类已经被加载,则开始给该对象在 jvm 的堆中分配内存。
- 虚拟机初始化操作,虚拟机对分配的空间初始化为零值。
- 执行 init 方法,初始化对象的属性,至此对象被创建完成。
- Java 虚拟机栈中的 Reference 执行我们刚刚创建的对象。
Java bytecode 代码
0: new #2; //class java/lang/String 3: dup 4: ldc #3; //String xyz 6: invokespecial #4; //Method java/lang/String."<init>":(Ljava/lang/String;)V 9: astore_1 复制代码
在 Java 语言里,“new”表达式是负责创建实例的,其中会调用构造器去对实例做初始化;构造器自身的返回值类型是 void,并不是“构造器返回了新创建的对象的引用”,而是 new 表达式的值是新创建的对象的引用。
对应的,在 JVM里,“new”字节码指令只负责把实例创建出来(包括分配空间、设定类型、所有字段设置默认值等工作),并且把指向新创建对象的引用压到操作数栈顶。此时该引用还不能直接使用,处于未初始化状态(uninitialized);如果某方法a含有代码试图通过未初始化状态的引用来调用任何实例方法,那么方法a会通不过JVM的字节码校验,从而被JVM拒绝执行。
能对未初始化状态的引用做的唯一一种事情就是通过它调用实例构造器,在 Class 文件层面表现为特殊初始化方法“”。实际调用的指令是 invokespecial,而在实际调用前要把需要的参数按顺序压到操作数栈上。在上面的字节码例子中,压参数的指令包括 dup 和 ldc 两条,分别把隐藏参数(新创建的实例的引用,对于实例构造器来说就是“this”)与显式声明的第一个实际参数("xyz"常量的引用)压到操作数栈上。在构造器返回之后,新创建的实例的引用就可以正常使用了。
这里又引出 类加载 的概念,需要注意的是,我们平常说的加载大多不是指的类加载机制,只是类加载机制中的第一步加载。具体如下:
在代码编译后,就会生成 JVM(Java虚拟机)能够识别的二进制字节流文件(*.class)。而 JVM 把 Class 文件中的类描述数据从文件加载到内存,并对数据进行校验、转换解析、初始化,使这些数据最终成为可以被 JVM 直接使用的 Java 类型,这个说来简单但实际复杂的过程叫做 JVM 的类加载机制 。
Class 文件中的“类”从加载到 JVM 内存中,到卸载出内存过程有七个生命周期阶段。类加载机制包括了前五个阶段。
如下图所示:
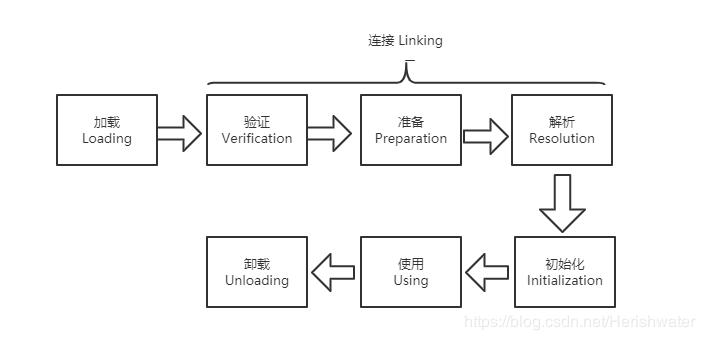
其中,加载、验证、准备、初始化、卸载的开始顺序是确定的,注意,只是按顺序开始,进行与结束的顺序并不一定。解析阶段可能在初始化之后开始。
另外,类加载无需等到程序中“首次使用”的时候才开始,JVM预先加载某些类也是被允许的。(类加载的时机)
在类加载阶段完后后,字符串字面量会进入到字符串常量池,同时包括为静态变量赋程序设定的初值。关于 JVM 类加载的讲解可以参看: JVM类加载过程 。
String s=new String("xyz") 该行代码运行即分为两个阶段:类加载阶段和代码片段自身执行的时候。所以当提问为“ String s=new String("xyz") 在运行时涉及到几个对象 ”时,合理的答案是:
两个,一个是字符串字面量"xyz"在堆中创建的对象,并将其引用驻留(intern)在全局共享的字符串常量池中,另一个是通过new
String(String)在堆中创建并初始化的、内容与"xyz"相同的对象
”String s=new String("xyz") 在类加载时涉及到几个对象“ ,该问题合理的答案就是一个。
扯点别的,如果问题改为” String s=new String("java") 在运行时涉及到几个对象 “,答案就不再是两个了,正确答案只有一个。详细讲解可以参看 R大的文章: 如何理解《深入理解java虚拟机》第二版中对String.intern()方法的讲解中所举的例子?
简单来说,就是上述代码运行时,字符串常量池中已经有引用”java“字符串字面量,所以类加载阶段没有创建”java“对象。
String“+”符号的实现
在我们使用中经常会用到+符号来拼接字符串,但是这个+符号在 String 中的实现还是有讲究的。如果是相加含有 String 对象,则底部是使用 StringBuilder 实现的拼接的。
通过以下的例子进行展示:
int n = 3;
String s1 = new String("3"+"3"+n);
s1.intern();
String s2 = "333";
System.out.println(s1 == s2);//true
String s3 = new String("a"+"bc");
final String s4 = "re";
String s5 = s4+"rt";
复制代码
查看编译后的字节码文件:
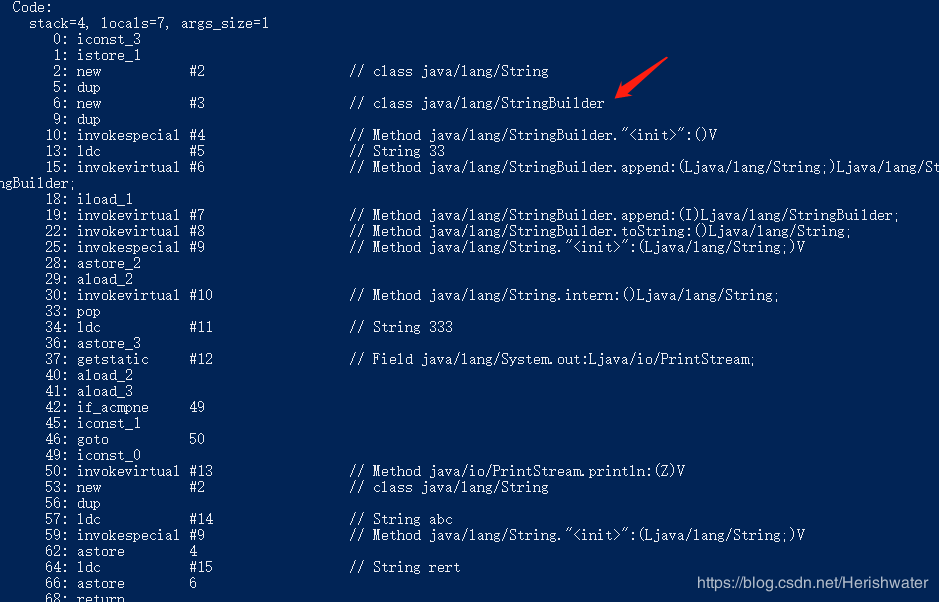
当相加的参数有字符串变量或者其他基础类型变量,注意都不能是 final 修饰的,底层会使用 StringBuilder 进行拼接。如果是字符串对象直接相加,或 final 变量与字符串对象相加,在编译阶段会直接拼接在一起,不需要使用 StringBuilder。
参考链接
- 请别再拿“String s = new String("xyz");创建了多少个String实例”来面试了吧
- 如何理解《深入理解java虚拟机》第二版中对String.intern()方法的讲解中所举的例子?
- new一个String对象的时候,如果常量池没有相应的字面量真的会去它那里创建一个吗?我表示怀疑。
- JVM类加载机制详解(一)JVM类加载过程
- java基础:String — 字符串常量池与intern(二)
- 详解JVM的内存对象介绍创建和访问
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

