《Java并发编程的艺术》学习 ——volatile
Java编程语言允许线程访问的共享变量,为了确保共享变量能够被准确和一致性的更新,线程应该确保通过排他锁单独获取到某个变量。
如果一个字段被声明成了volatile,那么他在Java线程的内存模型里面就可以被所有线程看到这边变量的一致性。
二、Volatile原理
2.1、volatile启动了什么作用呢?
被volatile修饰的变量后,把下列代码通过汇编编译时发现多了lock前缀命令
insatcen = new Insatcen() // insatcen 被 volatile 修饰 复制代码
那么这个lock前缀命令在多核处理器下会引发两个事情。
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作回使在其他CPU里缓存了该内存地址的数据无效
那么这个是什么意思呢?那就要简单说一下Java的内存模型了
2.2、java的内存模型
在Java中 所有的实例域、静态域和数组元素都存在堆内存中,堆内存在线程之间是共享的。而局部变量、方法定义参数和异常处理器是线程私有的,不会和其他线程共享。它们不存在内存可见行问题。
Java线程之间的通信是由Java内存模型控制的(JMM)。 如图所示:
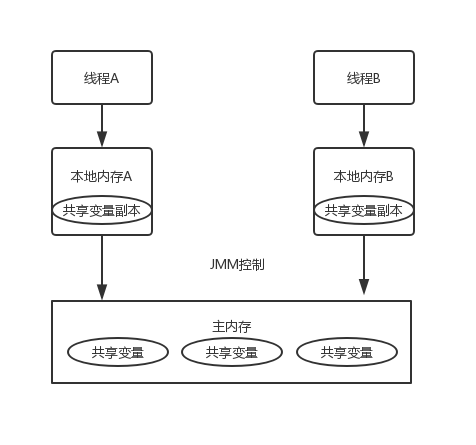
从抽象的角度看,线程之间共享变量储存在主内存中。但是每个线程由都有自己私有的本地内存,里面存放了该线程读/写共享变量的副本。但是这个本地内存是JMM的一个抽象概念,不是真实存在的。
所有如果线程A去更新一个共享变量X,线程A先更新自己的本地缓存,当线程A和线程B通信的时候,才把X更新到主内存中,并且线程B重新从主内存中获取。并且整个过程都必须要通过JMM来控制,这就保证了内存的可见行。
那么编译器中的lock命令就是引发来线程A和线程B的通信。来引发数据写会公共区域,并让其他线程的内存地址无效
2.3、指令重排序
在执行程序的时候,为了提高性能。编译器和处理器常常需要对指令进行重新排序。
排序主要分为一下三类:
- 编译器优化的重排序。编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序
- 指令级别的重排序。 现在的处理器采用了并行技术来将多条指令重叠执行。如果不存在数据依赖,处理器可以改变执行顺序。但是这种数据依赖只有在单处理器中才有效,不同处理器和不同线程之间的数据依赖不被编译器和处理器考虑。
- 内存系统的重排序。由于处理器使用缓存和读/写缓冲区,这使得加载和存储操作看上去可能是乱序执行的。
所有从源码到最终的结果 可能回经过这三种重排序:
源代码 > 编译器优化的重排序 > 指令级别的重排序 > 内存系统的重排序>最终的顺序
而这些重新排序都会导致多线程程序出现内存可见行的问题。JMM编译器会禁止特定类型的编译器重排序。通过插入特定的内存屏障指令,来禁止特定类型的处理器重新排序。 其他更多的重排序知识可以参考 《Java并发编程的艺术》 这本书
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

