AOP实现mysql的主从数据库:读写分离
首先,为什么会碰到这样的问题?
昨天写的一个业务上线了,但是在dev环境和test环境都能跑,但是到了线上环境发生 数据不能插入 的问题。
问了老大之后发现线上数据库是读写分离的,然后通过过滤器的才能进入写数据库卡,我的函数命名规范问题不符合过滤器的要求,导致从controller不能进入逻辑函数。
主要原因:
- 线上数据库是主从分离(即读写分离,写数据的情况下连接主库,读数据的时候连接从库)
- 而为什么跟函数命名规范相关?
- 代码中实现数据库读写分离是通过AOP的拦截器在方法开始执行前后插入我们想要的代码来实现 动态切换数据源 的功能
- 为什么要用AOP来实现数据源的切换?为什么要读写分离?AOP是如何实现读写分离的?
2.什么是AOP
2.1 AOP定义
AOP目标是 把业务的共性问题 提取出来集中放到一个统一的地方管理和控制。
2.2 应用场景
- 参数验证或者判空等公共方法
- 异常处理
- 事务管理
- 缓存
- 热修复:比如代码上线之后,有小改动,可以发起一个热修。即把有bug的方法替换成我们修复之后的方法
2.3 AOP方法
不同方法在java的完整周期(类加载期间,编译期,运行期间等)中 不同的时间段插入切面的方式不同 (即我们想要他在这个时间完成的方法,这里建议先了解 AOP的5种增强类型 )。
- 动态织入Hook方式:比静态织入方式灵活,在 运行期间,目标类加载之后 ,为接口动态生成代理类,将切面植入到代理类中。 常见的有:Dexposed,Xposed,epic(在native层修改java method对应的native指针)
- 动态字节码生成:cglib+DexMaker;
Cglib 是一个强大的,高性能的 Code 生成类库。 原理是在运行期间目标字节码加载后,通过字节码技术为一个类创建子类, 并在子类中采用方法拦截的技术拦截所有父类方法的调用,顺势织入横切逻辑。 由于是通过子类来代理父类,因此不能代理被 final 字段修饰的方法。 复制代码
- 静态织入方式 : 编译期间 APT AspectJ Javassist
在java编译期间有不同的织入方法
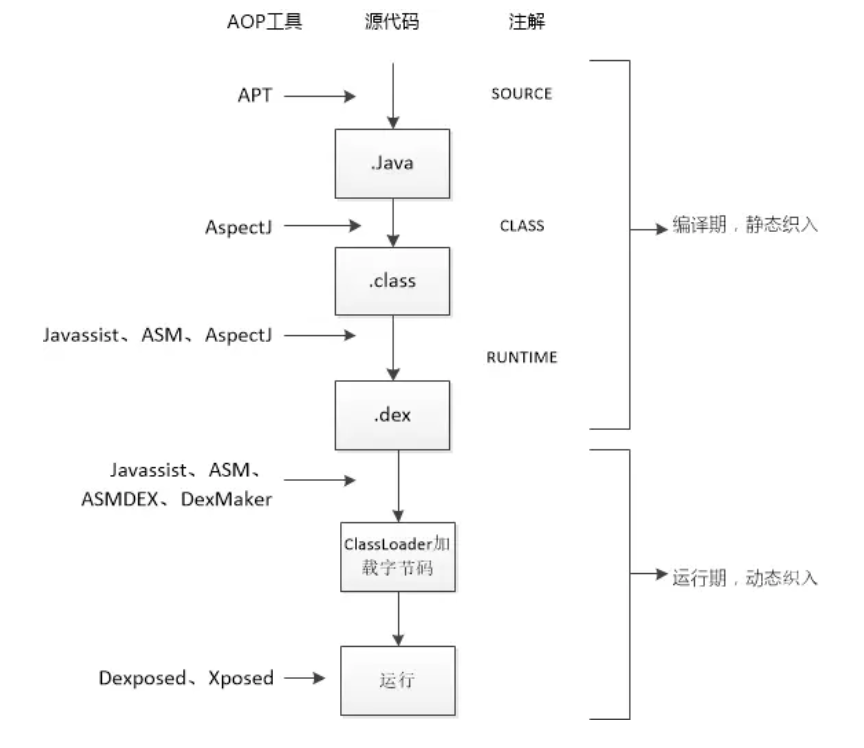
2.3 AspectJ
2.3 Javassist
对于AOP来说,最重要的点在于:
- 理解应用场景
- 考虑在什么期间插入代码,选用合适的AOP方法
- 考虑怎么过滤方法,找到注入点的描述,比如公司的项目是通过方法名来过滤
- 考虑以怎样的方式处理代码,是在代码执行之前?执行之后?(5种增强类型)
参考: juejin.im/post/5c0153…
3.读写分离
3.1 为什么要master-slave
1.将读操作和写操作分离到不同的数据库上,避免主服务器出现性能瓶颈; 2.主服务器进行写操作时,不影响查询应用服务器的查询性能,降低阻塞,提高并发; 3.数据拥有多个容灾副本,提高数据安全性。 4.同时当主服务器故障时,可立即切换到其他服务器,提高系统可用性; 复制代码
3.2读写分离能解决什么问题
- 1.高可用:master宕机,立即切换到slave机器上;
- 2.负载均衡:读写分离也算是负载均衡的一种,主要指多台从数据库(slave)与主数据库(master)之间的数据均衡;
- 3.数据备份:一般会写定时任务备份到不同的slave,保证数据安全;
- 4.业务模块化:一个业务模块读取一个slave,这个可以针对不同的业务模块对不同的数据库进行处理(比如索引的创建以及存储引擎的选择);
- 5.扩展性:scale-up:主要指服务器性能扩展;scale-out:主要指增加服务器的数量;
1、冷备份(定时全量/增量备份) 2、热备份(在主从架构上实现) 3、主从架构(N主M从) 4、读写分离(在主从架构上实现) 5、数据分片(分库分表(垂直分库 水平分表)) 复制代码
参考: www.jianshu.com/p/b7834c990…
3.3 读写分离的缺点
- 成本增加
- 数据延迟
- 写数据库压力较大
3.4 主从复制方式
- 基于日志 binlog
- 基于GTID 全局事务标识符
1、Master将数据改变记录到二进制日志(binary log)中,也就是配置文件log-bin指定的文件,这些记录叫做二进制日志事件(binary log events) 2、Slave通过I/O线程读取Master中的binary log events并写入到它的中继日志(relay log) 3、Slave重做中继日志中的事件,把中继日志中的事件信息一条一条的在本地执行一次,完成数据在本地的存储,从而实现将改变反映到它自己的数据(数据重放) 复制代码
4.项目中AOP是如何实现主从读写分离的?
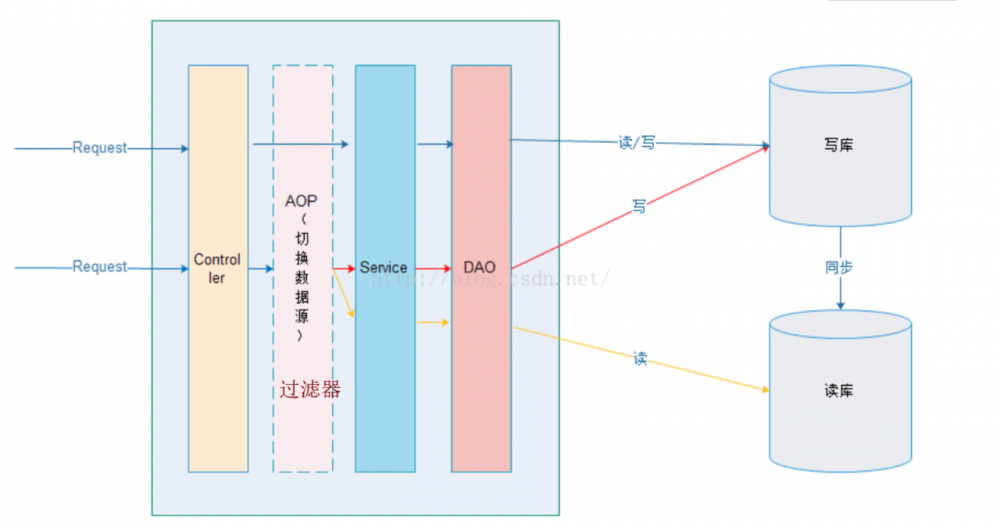
1.数据源配置spring_mybatis.xml
data所有数据源列表:master 写库 slave 读库
数据源DynamicDataSource类需要通过继承AbstractRoutingDataSource
<bean id="dynamicDataSource" class="com.A.B.DynamicDataSource">
<property name="targetDataSources">
<map key-type="java.lang.String">
<entry key="master" value-ref="masterDataSource" />
<entry key="slave" value-ref="slaveDataSource" />
</map>
</property>
<property name="defaultTargetDataSource" ref="lingxu_masterDataSource" />
</bean>
配置dataAOP 动态设置数据源
<bean id="dataSourceAdvice" class="com.T.A.dsadvice.DataSourceAdvice" />
配置事务
<!-- spring aop manager transaction -->
<tx:advice id="txTransactionAdvice" transaction-manager="transactionManager">
<tx:attributes>
<!-- add transaction -->
<tx:method name="add*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="create*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="save*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="insert*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="update*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="change*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="modify*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="edit*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="delete*" propagation="REQUIRED" rollback-for="Exception"/>
<tx:method name="remove*" propagation="REQUIRED" rollback-for="Exception"/>
</tx:attributes>
</tx:advice>
添加两个数据源至aop:config
<aop:config>
<aop:advisor advice-ref="dataSourceAdvice" pointcut="execution(* com.T.A.service..*Service.*(..))" order="1"/>
<aop:advisor advice-ref="txTransactionAdvice" pointcut="execution(* com.T.A.service..*Service.*(..)))" order="2" />
</aop:config>
复制代码
2.数据源配置DynamicDataSource
//determineCurrentLookupKey是重写的AbstractRoutingDataSource的方法
//主要是确定当前应该使用哪个数据源的key,因为AbstractRoutingDataSource 中保存的多个数据源是通过Map的方式保存的
public class DynamicDataSource extends AbstractRoutingDataSource {
@Override
protected Object determineCurrentLookupKey() {
return DataSourceSwitcher.getDataSource();
}
}
复制代码
3.动态数据源配置
public class DataSourceAdvice implements MethodBeforeAdvice, AfterReturningAdvice, ThrowsAdvice 复制代码
正文到此结束
- 本文标签: 配置 存储引擎 key Property 备份 高并发 线程 NSA final mysql IO https map 字节码 XML http update id 数据库 IDE 并发 参数 bean db sql 索引 时间 src java Master tar 数据 缓存 mybatis Service 编译 安全 bug 代码 lib spring 主从架构 UI cglib value Action 服务器 高可用 压力 管理 dataSource rmi AOP 负载均衡
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

