spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言
本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3
本文基于前两篇文章eureka-server、eureka-client、eureka-ribbon和eureka-feign的实现。
参考
- eureka-server
- eureka-client
- eureka-ribbon
- eureka-feign
概述
现实生产环境当中,随着业务的发展,系统规模是越来越大的,各个服务之间的调用也越来越复杂,通常一个由客户端发起的请求在后端系统中会经过N个不同服务的来产生结果,这样就会产生一个调用链路,每一条链路都有可能出现不通的错误或者是延迟,当出现错误或者延迟的情况下,追踪问题变的非常困难,所以Spring cloud为我们提供了Sleuth分布式链路追踪,能帮忙我们快速定位问题以及相应的监控。(我这里的demo模块也好多,过后需要整理下,不影响小伙伴们的学习)
1. Sleuth简单使用
1.1 在相关工程中添加Sleuth依赖
在eureka-client、eureka-ribbon、eureka-feign工作中增加Sleuth依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
1.2 添加日志记录
在需要输入日志的地方增加日志打印。这里只简单例举eureka-ribbon工程中的controller日志。
package spring.cloud.demo.eurekaribbon.controller;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import spring.cloud.demo.eurekaribbon.service.EurekaRibbonService;
/**
* @auther: maomao
* @DateT: 2019-09-17
*/
@RestController
@Slf4j
public class EurekaRibbonConntroller {
@Autowired
private EurekaRibbonService eurekaRibbonService;
@RequestMapping("/sayHello")
public String syaHello() {
log.info("eureka-ribbon server......");
String message = eurekaRibbonService.sayHello();
log.info("[eureka-ribbon][EurekaRibbonConntroller][syaHello], message={}", message);
return "ribbon result: " + message;
}
}
1.3 启动服务
准备工作已经完成,这时候我们按顺序启动所有服务。然后我们访问 http://localhost :8901/sayHello,查看控制台会输出,
2019-11-06 19:48:48.058 INFO [eureka-ribbon,086a3ab9cf8d31a8,086a3ab9cf8d31a8,false] 59750 --- [nio-8901-exec-9] s.c.d.e.c.EurekaRibbonConntroller : ribbon request, server=eureka-ribbon 调用 服务 eureka-client/info 服务 eureka-client/info 返回信息:http://eureka1.client.com:8801/info 调用 服务 eureka-client/info success 2019-11-06 19:48:48.351 INFO [eureka-ribbon,086a3ab9cf8d31a8,f06ab1e22c04430a,false] 59750 --- [ibbonService-10] s.c.d.e.service.EurekaRibbonService : ribbon->EurekaRibbonService->sayHello->调用 服务 eureka-client/info 返回信息:message=http://eureka1.client.com:8801/info 2019-11-06 19:48:48.351 INFO [eureka-ribbon,086a3ab9cf8d31a8,086a3ab9cf8d31a8,false] 59750 --- [nio-8901-exec-9] s.c.d.e.c.EurekaRibbonConntroller : ribbon request, server=eureka-ribbon, message=http://eureka1.client.com:8801/info
日志说明:
我们在控制台中可以查看到类似这样的日志:[eureka-ribbon,086a3ab9cf8d31a8,f06ab1e22c04430a,false],这些就是Sleuth帮忙我们生成的。
- 第一个值:eureka-ribbon,代表我们的应用名称。
- 第二个值:086a3ab9cf8d31a8,TraceID, 用来标识一条请求链路。
- 第三个值:f06ab1e22c04430a,SpanID,用来标识一个基本的工作单元。
- 第四个值:false,表示是否将该信息输出到其他日志收集服务中,例如:Zipkin。
TraceID和SpanID关系:一个链路对应多个基本工作单元,也就是一个TraceID对应多个SpanID。
我这里例举的eureka-ribbon工程中的控制台输出的日志内容,同理我们可以查看eureka-client工程的控制台输出,也会用类似的日志输出。
1.4 小结
至此,Spring cloud Sleuth分布式链路追踪就初步搭建完成,由此我们可以总结出,Sleuth的核心就是生成的TraceID和SpanID,一条链路的日志信息是由TraceID串联起来的。
2. 整合Logstash
有了日志输出还不够,我们还需要日志收集,官方文档使用的是Logstash,接下来我们开始整和Logstash。
2.1 加入Logstash依赖
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>6.2</version>
</dependency>
这里加入的是最新的logback依赖包,低版本的和Spring cloud 2.x版本不兼容。
2.2 增加logback-spring.xml
在eureka-client和eureka-ribbon中加入logback-spring.xml,这里需要注意的是,logback-spring.xml加载在application.yml配置之前,所以要新建bootstrap.yml,这样logback-spring.xml才能获取到对应的应用名称。
bootstrap.yml设置:
spring:
application:
name: eureka-ribbon
server:
port: 8901
logback-spring.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>INFO</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<appender-ref ref="logstash"/>
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>
2.3 重启相关服务
重新启动相关服务,并访问 http://localhost :8901/sayHello,在相应的控制台中可以看到类似日志,
2019-11-07 11:14:21.136 INFO [eureka-ribbon,0983491b6471be0f,48598b8942c2c814,false] 3288 --- [RibbonService-1] s.c.d.e.service.EurekaRibbonService : ribbon->EurekaRibbonService->sayHello->调用 服务 eureka-client/info 返回信息:message=http://eureka1.client.com:8801/info 2019-11-07 11:14:21.139 INFO [eureka-ribbon,0983491b6471be0f,0983491b6471be0f,false] 3288 --- [nio-8901-exec-1] s.c.d.e.c.EurekaRibbonConntroller : >>>traceId=null, spanId=null 2019-11-07 11:14:21.140 INFO [eureka-ribbon,0983491b6471be0f,0983491b6471be0f,false] 3288 --- [nio-8901-exec-1] s.c.d.e.c.EurekaRibbonConntroller : [eureka-ribbon][EurekaRibbonConntroller][syaHello], message=http://eureka1.client.com:8801/info, traceId=0983491b6471be0f
日志内容之前已经进行过详细的说明,这里就不在说明,这时我们可以在工程目录外发现有一个build的目录,我们进入这个build目录可以看到已应用名称开头的.json文件,该文件就是logback-spring.xml中配置的logstash的appender输出的日志文件。
2.3 小结
logstash的日志配置我们就完成了,logstash除了可以通过上面的方式生成json日志文件之外,还可以使用LogstashTcpSocketAppender将日志内容直接输出到logstash的服务端,这里就不过多说明,感兴趣的小伙伴可以自行研究。
3 整合Zipkin
在Spring cloud D版本以后,zipkin-server是通过引入依赖的方式构建的,到了E版本之后,官方就是开始启用了jar的形式来运行zipkin-server。所以我们先到zipkin的官网下载最新的zipkin.jar。
3.1 修改要跟踪的工程应用
在eureka-client、eureka-ribbon、spring-gateway增加相关依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
3.2 修改application.yml配置
在eureka-client、eureka-ribbon、spring-gateway应用的application.yml增加一下配置:
spring:
sleuth:
sampler:
probability: 1 #采样频率
web:
enabled: true
zipkin:
base-url: http://localhost:9411/ #zipkin服务地址
3.3 启动服务
启动eureka-client、eureka-ribbon、spring-gateway应用服务。
zipkin启动方式:java -jar zipkin.jar
运行zipkin.jar以后,我访问 http://localhost :9411/zipkin,这时候我们可以看到如下图显示:
然后我们在访问 http://localhost :8100/ribbon/sayHello?token=xxx地址(这个地址的请求链路是spring-gateway:eureka-ribbion:eureka-client),然后我们点击zipkin的查询按钮,我们可以看到如下显示:
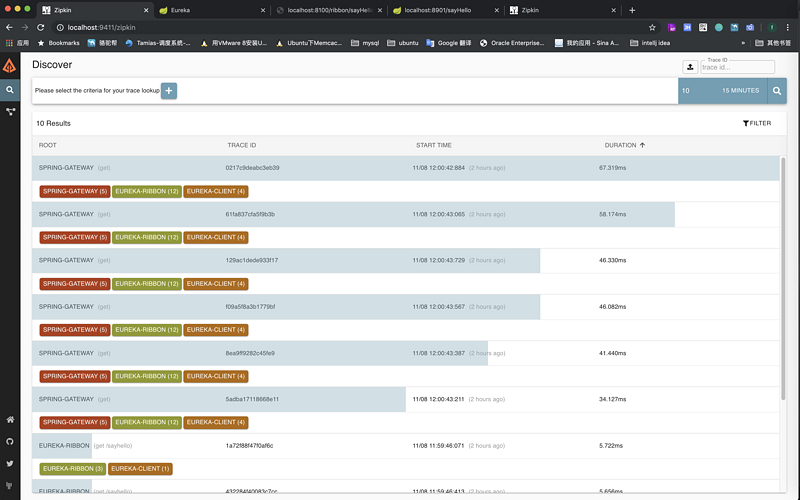
然后可以点击单个链路信息查看详细信息,如下图显示:
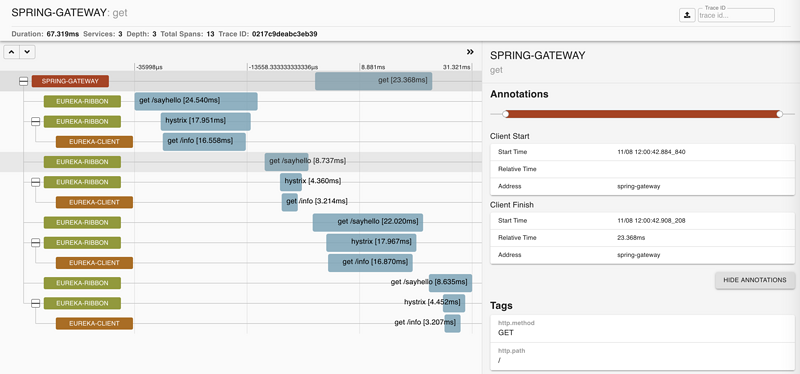
由这张图就可查看到详细链路追踪信息。
3.4 小结
至此,整合zipkin就完成了,这种默认的方式是http收集,我们还可以采用消息中间件来收集日志信息,感兴趣的小伙伴可以自行研究。
总结
本文重点讲述了Spring Cloud通过Sleuth+Zipkin实现了服务的跟踪,后续我会补充一篇结合ELK的日志收集。通过这篇文章我们也简单的了解了链路追踪的原理,就是通过traceId将整个过程串联起来,然后通过spanID来计算各个环节的时间延迟。
代码地址
gitHub地址
<center><font color=red>《Srping Cloud 2.X小白教程》目录</font></center>
- spring cloud 2.x版本 Eureka Server服务注册中心教程
- spring cloud 2.x版本 Eureka Client服务提供者教程
- spring cloud 2.x版本 Ribbon服务发现教程(内含集成Hystrix熔断机制)
- spring cloud 2.x版本 Feign服务发现教程(内含集成Hystrix熔断机制)
- spring cloud 2.x版本 Zuul路由网关教程
- spring cloud 2.x版本 config分布式配置中心教程
- spring cloud 2.x版本 Hystrix Dashboard断路器教程
- spring cloud 2.x版本 Gateway路由网关教程
- spring cloud 2.x版本 Gateway自定义过滤器教程
- spring cloud 2.x版本 Gateway熔断、限流教程
- spring cloud 2.x版本 Gateway动态路由教程
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
- 写作不易,转载请注明出处,喜欢的小伙伴可以关注公众号查看更多喜欢的文章。
- 联系方式:4272231@163.com

正文到此结束
- 本文标签: Eureka core Property 分布式 zuul 服务注册 web tar 代码 value src message id Feign Hystrix Dashboard zip GitHub XML client Logging 服务端 ribbon Dashboard 2019 java js Bootstrap json build 下载 IO Spring cloud 注册中心 UTC spring https IDE example 文章 NIO token Spring Cloud Sleuth Logback 目录 git UI App provider ACE ORM Hystrix Sleuth 限流 ip 配置 CTO 总结 Word bean ELK 配置中心 Agent tab map TCP REST http Service zipkin 路由网关 BIO root cat 时间
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

