我理解的零拷贝
我理解的零拷贝-原文链接
最近做的业务涉及到的 I/O 操作比较多,对于Linux上的 I/O 操作的优化 Zero Copy 早有耳闻,今天打算由上而下(从应用层到底层,当然并不会涉及到内核的细节)的研究一下这个问题。
什么是零拷贝
为了更好的描述 zero copy ,本文将以网络服务器的简单过程所涉及的内容展开,该过程通过网络将存储在服务端的文件中的数据提供给客户端。整个过程主要是网络的 I/O 操作,数据至少被复制了4次,并且几乎已经执行了许多用户/内核上下文切换。 如下图所示,经过了下面四个步骤:
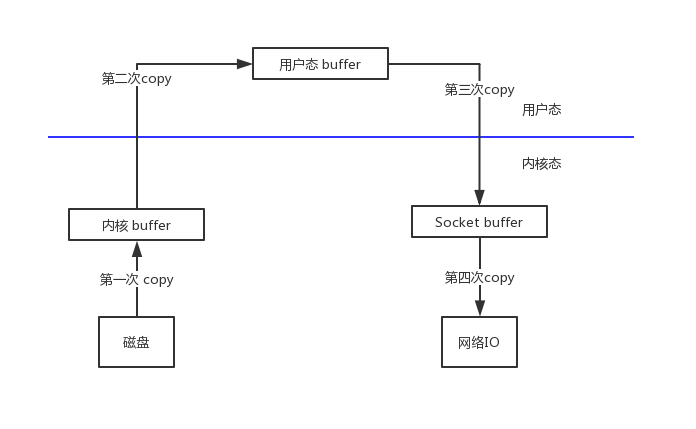
步骤一:操作系统发生 read 系统调用读取磁盘中的文件内容并将其存储到内核地址空间缓冲区中。
第二步:将数据从内核缓冲区复制到用户缓冲区,read 系统调用返回。调用的返回导致了从内核返回到用户模式的上下文切换,现在,数据存储在用户地址空间缓冲区中,它可以再次开始向下移动。
第三步:write 系统调用导致从用户模式到内核模式的上下文切换,执行第三个复制,将数据再次放入内核地址空间缓冲区中。但是这一次,数据被放入一个不同的缓冲区,这个缓冲区是与套接字相关联的。
第四步:写系统调用返回,创建第四个上下文切换。并将数据写入网络 I/O 中,网络传输中的服务端的操作逻辑到此结束。
从上图中我们知道,整个网络传输过程中数据被复制了多达4次之多,也进行了多次从用户态到内核态的切换。那么有没有可能减少数据的复制次数,提高网络 I/O 的效率呢?答案是肯定的。
那么到底什么是零拷贝呢?就是将数据直接从内核态的缓冲区中直接拷贝到 Socket 的缓冲区中,没有经过用户态的缓冲区,之所以被叫做零拷贝是相对于用户态来说的。如下图所示:
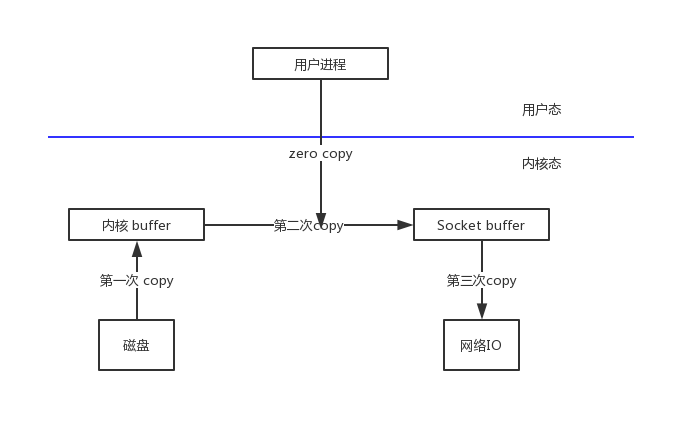
总的来说,从操作系统的角度来看是零拷贝,因为数据不是在内核缓冲区之间复制的。当使用零拷贝时,除了复制避免之外,还用其他性能优势,例如更少的上下文切换、更少的 CPU 数据缓存污染和没有 CPU 校验和计算。
零拷贝的 Java 实现
NIO 中的 FileChannel 拥有 transferTo 和 transferFrom 两个方法,可直接把 FileChannel 中的数据拷贝到另外一个 Channel,或直接把另外一个 Channel 中的数据拷贝到 FileChannel。该接口常被用于高效的网络/文件的数据传输和大文件拷贝。在操作系统支持的情况下,通过该方法传输数据并不需要将源数据从内核态拷贝到用户态,再从用户态拷贝到目标通道的内核态,同时也避免了两次用户态和内核态间的上下文切换,也即使用了“零拷贝”。
/**
* disk-nic零拷贝
*/
class ZeroCopyServer {
ServerSocketChannel listener = null;
public static void main(String[] args) {
ZerocopyServer dns = new ZerocopyServer();
dns.mySetup();
dns.readData();
}
protected void mySetup() {
InetSocketAddress listenAddr = new InetSocketAddress(9026);
try {
listener = ServerSocketChannel.open();
ServerSocket ss = listener.socket();
ss.setReuseAddress(true);
ss.bind(listenAddr);
System.out.println("监听的端口:" + listenAddr.toString());
} catch (IOException e) {
System.out.println("端口绑定失败 : " + listenAddr.toString() + " 端口可能已经被使用,出错原因: " + e.getMessage());
e.printStackTrace();
}
}
private void readData() {
ByteBuffer dst = ByteBuffer.allocate(4096);
try {
while (true) {
SocketChannel conn = listener.accept();
System.out.println("创建的连接: " + conn);
conn.configureBlocking(true);
int nread = 0;
while (nread != -1) {
try {
nread = conn.read(dst);
} catch (IOException e) {
e.printStackTrace();
nread = -1;
}
dst.rewind();
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
复制代码
说点题外话
对于 I/O 操作的优化也可以参考零拷贝的思路来对我们的系统进行优化,最近了解到 kafka 之所以可以能够承载高吞吐量跟它强依赖底层操作系统的 page cache 有很大关系,所以在使用 Kafka 并不是 jvm 的内存越大越好,跟零拷贝的减少数据在内核态与用户态之间的拷贝,上下文切换有异曲同工的操作,对 kafka 还不甚了解不敢多说了……
Kafka 官网看到的
为了弥补这种性能差异,现代操作系统在越来越注重使用内存对磁盘进行 cache。现代操作系统主动将所有空闲内存用作 disk caching ,代价是在内存回收时性能会有所降低。所有对磁盘的读写操作都会通过这个统一的 cache。如果不使用直接 I/O,该功能不能轻易关闭。因此即使进程维护了 in-process cache,该数据也可能会被复制到操作系统的 pagecache 中,事实上所有内容都被存储了两份。
此外,Kafka 建立在 JVM 之上,任何了解 Java 内存使用的人都知道两点:
- 对象的内存开销非常高,通常是所存储的数据的两倍(甚至更多)。
- 随着堆中数据的增加,Java 的垃圾回收变得越来越复杂和缓慢。
受这些因素影响,相比于维护 in-memory cache 或者其他结构,使用文件系统和 pagecache 显得更有优势--我们可以通过自动访问所有空闲内存将可用缓存的容量至少翻倍,并且通过存储紧凑的字节结构而不是独立的对象,有望将缓存容量再翻一番。 这样使得32GB的机器缓存容量可以达到28-30GB,并且不会产生额外的 GC 负担。此外,即使服务重新启动,缓存依旧可用,而 in-process cache 则需要在内存中重建(重建一个10GB的缓存可能需要10分钟),否则进程就要从 cold cache 的状态开始(这意味着进程最初的性能表现十分糟糕)。 这同时也极大的简化了代码,因为所有保持 cache 和文件系统之间一致性的逻辑现在都被放到了 OS 中,这样做比一次性的进程内缓存更准确、更高效。如果你的磁盘使用更倾向于顺序读取,那么 read-ahead 可以有效的使用每次从磁盘中读取到的有用数据预先填充 cache。
这里给出了一个非常简单的设计:相比于维护尽可能多的 in-memory cache,并且在空间不足的时候匆忙将数据 flush 到文件系统,我们把这个过程倒过来。所有数据一开始就被写入到文件系统的持久化日志中,而不用在 cache 空间不足的时候 flush 到磁盘。实际上,这表明数据被转移到了内核的 pagecache 中。
关于文中多次出现的用户态,内核态
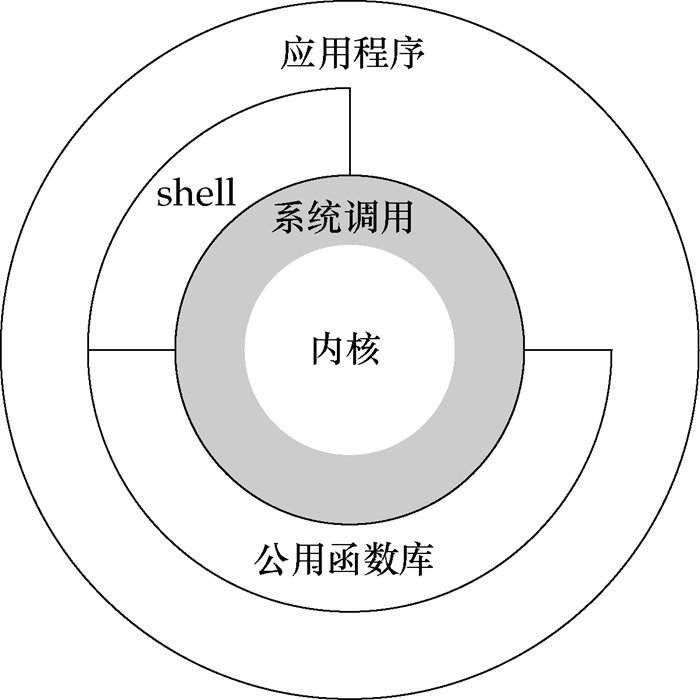
如上图所示,从宏观上来看,操作系统的体系架构分为用户态和内核态。内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程序运行的环境。用户态即上层应用程序的活动空间,应用程序的执行必须依托于内核提供的资源,包括 CPU 资源、存储资源、I/O 资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

