JDK源码那些事儿之ConcurrentLinkedQueue
阻塞队列的实现前面已经讲解完毕,今天我们继续了解源码中非阻塞队列的实现,接下来就看一看ConcurrentLinkedQueue非阻塞队列是怎么完成操作的
前言
JDK版本号:1.8.0_171
ConcurrentLinkedQueue是一个基于链表实现的无界的线程安全的FIFO非阻塞队列。最大的不同之处在于非阻塞特性,之前讲解的阻塞队列都会通过各种方式进行阻塞操作,在ConcurrentLinkedQueue中通过CAS操作来完成非阻塞操作。其中head和tail的更新类似之前在LinkedTransferQueue中讲解的slack(松弛度)机制,只有在slack阈值大于等于2时才会进行更新,尽量减少CAS的操作次数,当然,这样的操作也提高了代码实现的复杂度
类定义
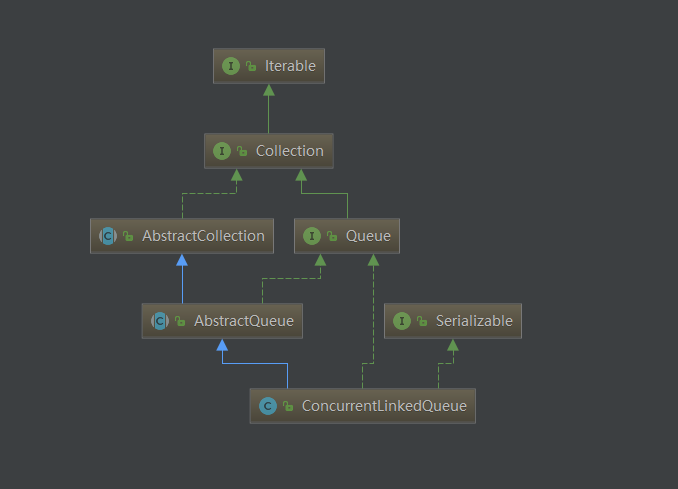
从关系图上我们也可以看到ConcurrentLinkedQueue没有去实现BlockingQueue接口
public class ConcurrentLinkedQueue<E> extends AbstractQueue<E>
implements Queue<E>, java.io.Serializable
实现流程
为了了解其内部实现的操作,可以看下面的过程图理解其内部结点入队出队的转换过程


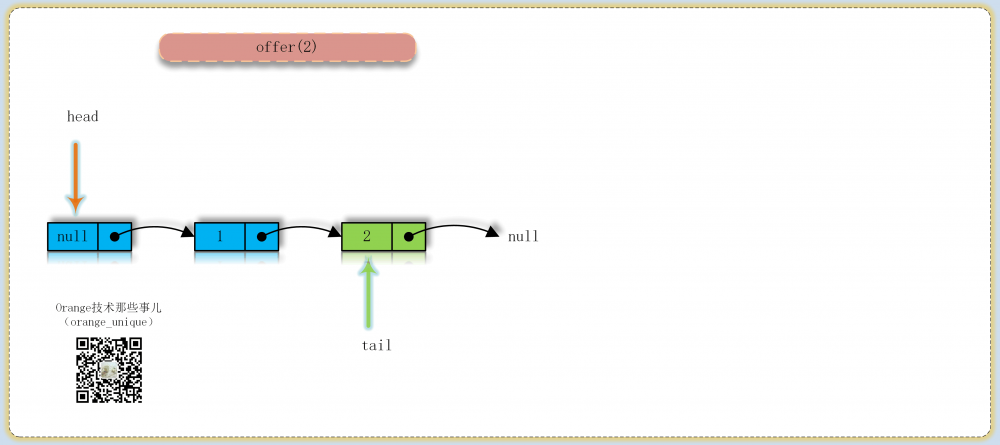
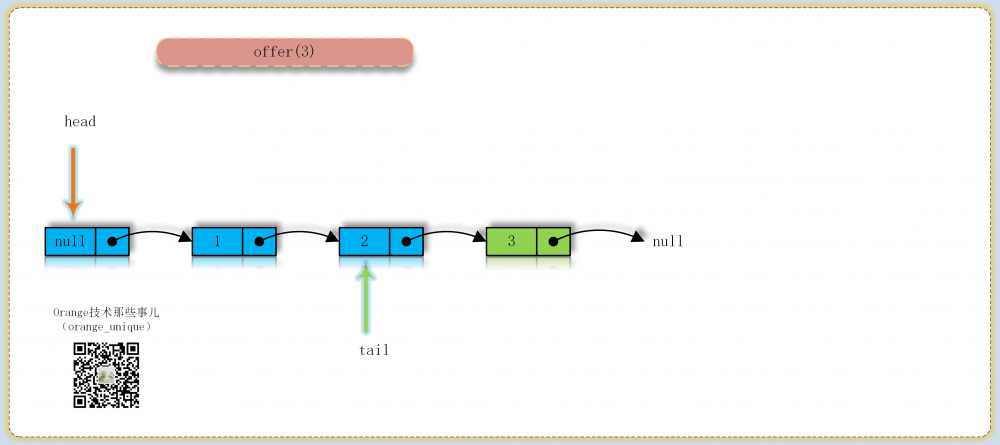
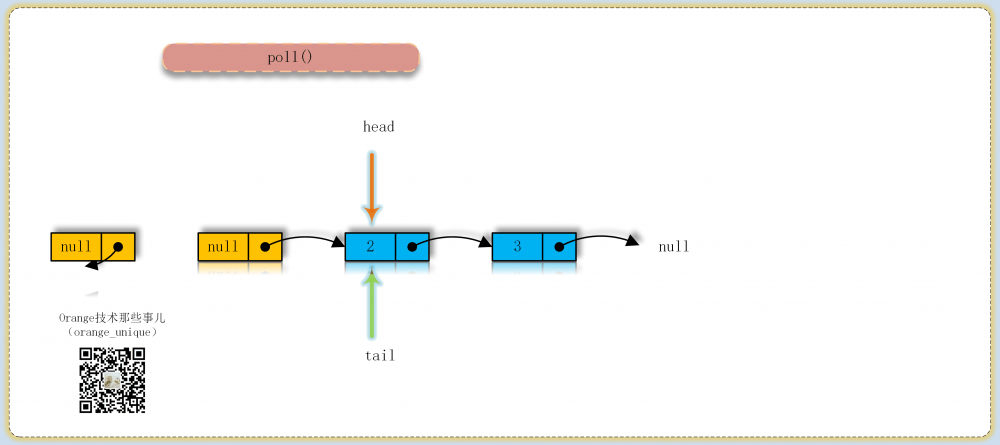
常量/变量
除了CAS需要使用的常量,就只剩下head和tail两个引用结点,在其注释部分可以看到作者的说明,这里解释下:
head结点:
- 所有未删除结点都可以head结点通过执行succ()方法访问
- head结点非null
- head结点next不能指向自己
- head结点的item可能为null,也可能不为null
- tail结点可以落后于head结点,此时,从head结点不能访问到tail结点
tail结点(tail的next为null):
- 队列最后一个结点可以通过tail结点执行succ()方法得访问
- tail结点非null
- tail结点的item可能为null,也可能不为null
- tail结点可以落后于head结点,此时,从head结点不能访问到tail结点
- tail结点next可能指向自己,也可能不指向自己
由于head结点和tail结点不是实时更新,达到松弛度阈值才进行更新,有可能导致head结点在tail结点之后的现象
/**
* A node from which the first live (non-deleted) node (if any)
* can be reached in O(1) time.
* Invariants:
* - all live nodes are reachable from head via succ()
* - head != null
* - (tmp = head).next != tmp || tmp != head
* Non-invariants:
* - head.item may or may not be null.
* - it is permitted for tail to lag behind head, that is, for tail
* to not be reachable from head!
*/
private transient volatile Node<E> head;
/**
* A node from which the last node on list (that is, the unique
* node with node.next == null) can be reached in O(1) time.
* Invariants:
* - the last node is always reachable from tail via succ()
* - tail != null
* Non-invariants:
* - tail.item may or may not be null.
* - it is permitted for tail to lag behind head, that is, for tail
* to not be reachable from head!
* - tail.next may or may not be self-pointing to tail.
*/
private transient volatile Node<E> tail;
// CAS操作
private static final sun.misc.Unsafe UNSAFE;
private static final long headOffset;
private static final long tailOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = ConcurrentLinkedQueue.class;
headOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("head"));
tailOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("tail"));
} catch (Exception e) {
throw new Error(e);
}
}
内部类
Node实现比较简单,没复杂的部分,主要是通过CAS操作进行更新变量
private static class Node<E> {
volatile E item;
volatile Node<E> next;
/**
* Constructs a new node. Uses relaxed write because item can
* only be seen after publication via casNext.
*/
Node(E item) {
UNSAFE.putObject(this, itemOffset, item);
}
boolean casItem(E cmp, E val) {
return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val);
}
void lazySetNext(Node<E> val) {
UNSAFE.putOrderedObject(this, nextOffset, val);
}
boolean casNext(Node<E> cmp, Node<E> val) {
return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val);
}
// Unsafe mechanics
private static final sun.misc.Unsafe UNSAFE;
private static final long itemOffset;
private static final long nextOffset;
static {
try {
UNSAFE = sun.misc.Unsafe.getUnsafe();
Class<?> k = Node.class;
itemOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("item"));
nextOffset = UNSAFE.objectFieldOffset
(k.getDeclaredField("next"));
} catch (Exception e) {
throw new Error(e);
}
}
}
构造方法
无参构造方法创建了空结点同时头尾结点指向这个空结点,集合参数构造时循环添加结点,比较简单,主要需要理解默认无参构造函数创建时发生的变化
public ConcurrentLinkedQueue() {
head = tail = new Node<E>(null);
}
public ConcurrentLinkedQueue(Collection<? extends E> c) {
Node<E> h = null, t = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (h == null)
h = t = newNode;
else {
t.lazySetNext(newNode);
t = newNode;
}
}
if (h == null)
h = t = new Node<E>(null);
head = h;
tail = t;
}
重要方法
updateHead
h != p的前提条件下尝试更新head指向到p,成功则尝试更新原head结点指向到自己,表示结点离队
/**
* Tries to CAS head to p. If successful, repoint old head to itself
* as sentinel for succ(), below.
*/
final void updateHead(Node<E> h, Node<E> p) {
if (h != p && casHead(h, p))
h.lazySetNext(h);
}
succ
获取p结点的后继结点,当next指向自己时,结点本身可能已经处于离队状态,此时返回head结点
/**
* Returns the successor of p, or the head node if p.next has been
* linked to self, which will only be true if traversing with a
* stale pointer that is now off the list.
*/
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
return (p == next) ? head : next;
}
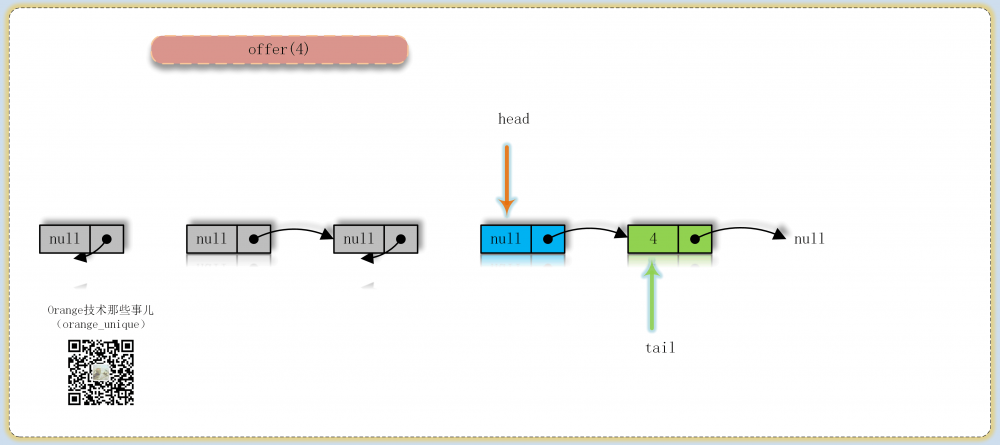
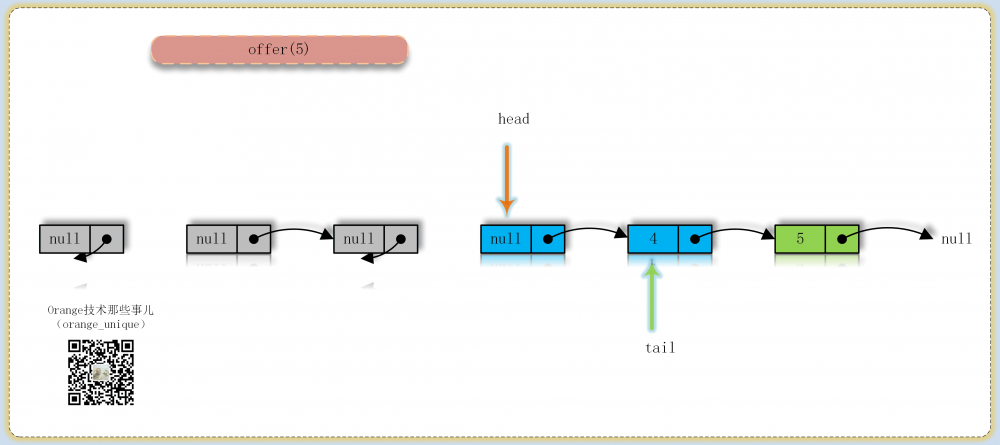
offer
入队操作核心方法,入队必成功,返回为true,表示入队会一直尝试操作直到成功,循环尝试中主要分为3种情况:
- 找到最后一个结点,尝试更新next指向新结点,失败则表示next被其他线程更新,此时重新循环判断,成功则判断tail结点指向是否已经滞后一个结点以上,如果是则尝试更新tail
- 之前找到的最后一个结点已经离队(p = p.next),如果tail已经被其他线程更新则更新到tail,否则从head结点开始找到最后一个结点(因为tail可以落后于head)
- 非最后一个结点同时这个结点也未离队,如果tail已经被其他线程更新则更新到tail,否则从当前结点的next开始继续循环
public boolean offer(E e) {
// 判空
checkNotNull(e);
final Node<E> newNode = new Node<E>(e);
// 循环直到成功
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
// p此时是最后一个结点
if (q == null) {
// 则开始尝试更新p的next指向新插入的结点
// p的next未更新成功说明next被其他结点抢先更新了,重新循环判断尝试
if (p.casNext(null, newNode)) {
// tail指向结点后已经添加了1个结点以上时才更新tail结点指向
// 即slack >= 2时才尝试更新
if (p != t) // hop two nodes at a time
// 失败可能被其他线程更新了
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
// p非最后一个结点,同时p = p.next则表示p本身已经离队,需要更新p
else if (p == q)
// tail结点已经被更新则更新tail否则从head结点开始寻找最后一个结点
p = (t != (t = tail)) ? t : head;
else
// p非最后一个结点,同时p未离队删除,如果tail被其他线程更新了则p更新成新的tail,否则p更新成p.next继续循环
p = (p != t && t != (t = tail)) ? t : q;
}
}
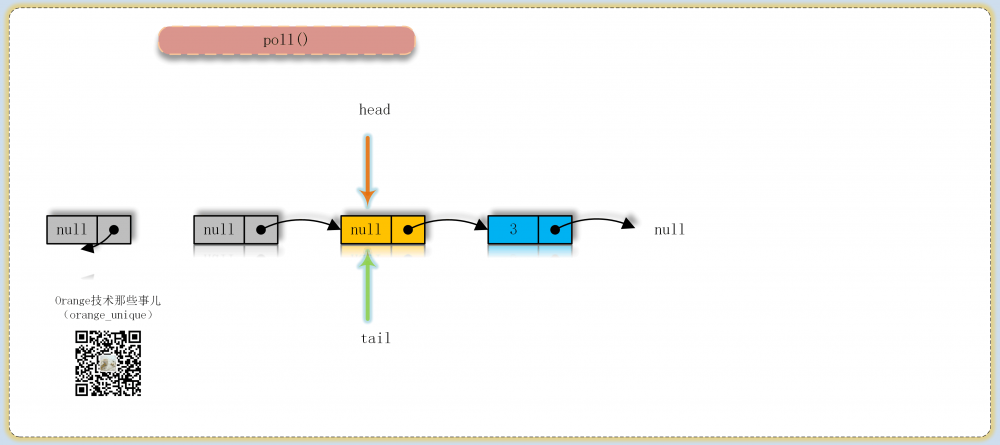
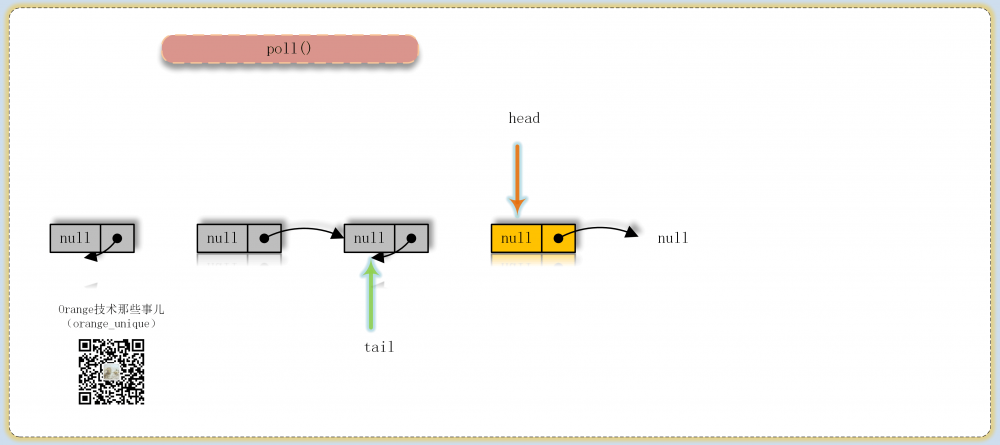
poll
出队操作核心方法,一直尝试直到成功,循环尝试中主要分为4种情况:
- 找到头结点,item非null则尝试更新成null以表示结点已出队,成功则判断是否需要更新head结点返回item
- item为null或item已经被其他线程获取,同时当前结点已经为最后一个结点,则尝试更新头head指向当前结点,返回null
- 当前结点非最后一个结点,如果已经离队则从head重新进行循环
- 当前结点未离队则更新到下一个结点进行循环判断
public E poll() {
restartFromHead:
// 循环尝试直到成功
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
// item非null则尝试更新成null(表示结点已出队)
if (item != null && p.casItem(item, null)) {
// 出队结点非之前的头结点,旧头结点h距离实际的head结点已经大于1则更新head
if (p != h) // hop two nodes at a time
// 出队结点后无结点则尝试更新head结点为出队结点本身(item = null),有结点则更新到出队结点后的那个结点
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
// item为空或item已被其他线程获取
// p结点本身为最后一个结点,则尝试更新head并更新原h结点指向自己,返回null
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
// p非最后一个结点,p == p.next 则表示p结点已经离队,则跳转restartFromHead从头重新循环判断
else if (p == q)
continue restartFromHead;
// p非最后一个结点,p也未离队,则更新p指向p的下一个结点,循环判断
else
p = q;
}
}
}
peek
和poll方法类似,主要在于不会对结点进行出队操作,仅仅是获取头结点的item值,当然中间也可能帮助更新下head指向
public E peek() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
first
和poll方法类似,poll返回的是item这里返回的是结点,如果是null结点(item == null),这里判断下直接返回null
Node<E> first() {
restartFromHead:
for (;;) {
for (Node<E> h = head, p = h, q;;) {
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) {
updateHead(h, p);
return hasItem ? p : null;
}
else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
remove
从队列中删除元素,通过item是否为null判断结点是否已经离队,是则继续后继判断,casItem(item, null)成功则表示移除结点成功,失败则表示被其他线程出队操作了,则继续后继判断
public boolean remove(Object o) {
if (o != null) {
Node<E> next, pred = null;
for (Node<E> p = first(); p != null; pred = p, p = next) {
boolean removed = false;
E item = p.item;
// item判断(非离队结点),不满足则继续判断后继结点
if (item != null) {
if (!o.equals(item)) {
next = succ(p);
continue;
}
// 找到匹配结点则尝试更新item为null,表示当前结点已经离队
removed = p.casItem(item, null);
}
// 后继结点,到这说明匹配的结点已经删除了(别的线程删除或者当前线程删除)
next = succ(p);
// 取消匹配结点的关联
if (pred != null && next != null) // unlink
pred.casNext(p, next);
// 假如是当前线程删除的结点则返回,否则继续判断后继直到匹配或没有匹配结点才返回
if (removed)
return true;
}
}
return false;
}
addAll
将集合c中的元素添加到队列中,添加到原队列尾部类似于上面的offer方法
public boolean addAll(Collection<? extends E> c) {
if (c == this)
// As historically specified in AbstractQueue#addAll
throw new IllegalArgumentException();
// 定义两个指针结点指向集合c的头尾
// 先将c改造成Node链表
Node<E> beginningOfTheEnd = null, last = null;
for (E e : c) {
checkNotNull(e);
Node<E> newNode = new Node<E>(e);
if (beginningOfTheEnd == null)
beginningOfTheEnd = last = newNode;
else {
last.lazySetNext(newNode);
last = newNode;
}
}
if (beginningOfTheEnd == null)
return false;
for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
// p为队列最后一个结点
if (q == null) {
// 将队列与上面新创建的链表连接起来,更新失败再循环继续
if (p.casNext(null, beginningOfTheEnd)) {
// tail更新失败重新尝试
if (!casTail(t, last)) {
t = tail;
if (last.next == null)
casTail(t, last);
}
return true;
}
}
// p非最后一个结点且已经离队
else if (p == q)
// tail结点已经被更新则更新为tail否则从head结点开始寻找最后一个结点
p = (t != (t = tail)) ? t : head;
else
// p非最后一个结点,同时p未离队删除,如果tail被其他线程更新了则p更新成新的tail,否则p更新成p.next继续循环
p = (p != t && t != (t = tail)) ? t : q;
}
}
迭代器
迭代器和之前队列讲解的迭代器相似,源码不是很复杂,同时remove方法这里是将item置为null,前后结点关联关系并不会操作,防止多线程遍历出现问题
构造方法中执行了advance()方法,提前设置好下次next执行时的结点nextNode,以及其item引用,hasNext判断nextNode即可,保证了迭代器的弱一致性,一旦hasNext返回true,那么调用next一定会得到相对应的item,即使该结点item已经被置为null
public Iterator<E> iterator() {
return new Itr();
}
private class Itr implements Iterator<E> {
/**
* next返回的Node
*/
private Node<E> nextNode;
/**
* 保存next的item,防止hasNext为true后结点被删除再调用next获取不到值的情况
*/
private E nextItem;
/**
* 最近一次调用next返回的结点,如果通过调用remove删除了此元素,则重置为null,避免删除了不该删除的元素
*/
private Node<E> lastRet;
/**
* 构造的时候就先保存了第一次调用next返回的Node
*/
Itr() {
advance();
}
/**
* Moves to next valid node and returns item to return for
* next(), or null if no such.
*/
private E advance() {
lastRet = nextNode;
E x = nextItem;
Node<E> pred, p;
if (nextNode == null) {
p = first();
pred = null;
} else {
pred = nextNode;
p = succ(nextNode);
}
for (;;) {
if (p == null) {
nextNode = null;
nextItem = null;
return x;
}
E item = p.item;
if (item != null) {
nextNode = p;
nextItem = item;
return x;
} else {
// 跳过null结点
Node<E> next = succ(p);
if (pred != null && next != null)
pred.casNext(p, next);
p = next;
}
}
}
public boolean hasNext() {
return nextNode != null;
}
public E next() {
if (nextNode == null) throw new NoSuchElementException();
return advance();
}
public void remove() {
Node<E> l = lastRet;
if (l == null) throw new IllegalStateException();
// rely on a future traversal to relink.
l.item = null;
lastRet = null;
}
}
总结
ConcurrentLinkedQueue是一个基于链表实现的无界的线程安全的FIFO非阻塞队列,整体源码上最主要的部分在于两点:
- 全程无锁操作,无阻塞操作,使用CAS更新变量
- head,tail结点非实时更新,在slack >= 2时才进行更新操作
结合图解很容易理清其实现以及操作流程,相比较于之前的LinkedTransferQueue源码算是简单了很多
以上内容如有问题欢迎指出,笔者验证后将及时修正,谢谢
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

