【架构师修炼之路】Redis 极简教程 : 基本数据结构, 跳表原理, Spring Boot 项目使用实例
引言
本文主要介绍 Spring Boot 应用中使用 Redis 的基础知识.
Redis 是什么
Redis: REmote DIctionary Server

Redis is an in-memory database that persists on disk. The data model is key-value, but many different kind of values are supported: Strings, Lists, Sets, Sorted Sets, Hashes, Streams, HyperLogLogs, Bitmaps. http://redis.io
Github:
https://github.com/antirez/redis
Redis(全称:Remote Dictionary Server 远程字典服务)是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。
这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Redis 是一个高性能的key-value数据库。redis的出现,很大程度补偿了memcached这类key/value存储的不足,在部 分场合可以对关系数据库起到很好的补充作用。它提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
安装 Redis
Mac上执行命令:
brew install redis
启动服务端进程
$ redis-server
99190:C 10 Nov 2019 12:14:42.903 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
99190:C 10 Nov 2019 12:14:42.904 # Redis version=5.0.6, bits=64, commit=00000000, modified=0, pid=99190, just started
99190:C 10 Nov 2019 12:14:42.904 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
99190:M 10 Nov 2019 12:14:42.905 * Increased maximum number of open files to 10032 (it was originally set to 256).
_._
_.-``__ ''-._
_.-`` `. `_. ''-._ Redis 5.0.6 (00000000/0) 64 bit
.-`` .-```. ```// _.,_ ''-._
( ' , .-` | `, ) Running in standalone mode
|`-._`-...-` __...-.``-._|'` _.-'| Port: 6379
| `-._ `._ / _.-' | PID: 99190
`-._ `-._ `-./ _.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' | http://redis.io
`-._ `-._`-.__.-'_.-' _.-'
|`-._`-._ `-.__.-' _.-'_.-'|
| `-._`-._ _.-'_.-' |
`-._ `-._`-.__.-'_.-' _.-'
`-._ `-.__.-' _.-'
`-._ _.-'
`-.__.-'
99190:M 10 Nov 2019 12:14:42.917 # Server initialized
99190:M 10 Nov 2019 12:14:42.922 * Ready to accept connections
启动客户端:
$ redis-cli
127.0.0.1:6379> set hello "Hello Redis"
OK
127.0.0.1:6379> get hello
"Hello Redis"
Redis 5种基本数据结构
redis提供五种数据类型:string,hash,list,set及zset(sorted set)。
字符串 string
string是最简单的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value,其上支持的操作与Memcached的操作类似。但它的功能更丰富。
redis采用结构sdshdr和sds封装了字符串,字符串相关的操作实现在源文件sds.h/sds.c (https://github.com/antirez/sds/blob/master/sds.c)中。
https://github.com/antirez/sds
数据结构定义如下:
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
命令行实例:
127.0.0.1:6379> set hello "Hello Redis"
OK
127.0.0.1:6379> get hello
"Hello Redis"
127.0.0.1:6379> set a 10
OK
127.0.0.1:6379> incr a
(integer) 11
127.0.0.1:6379> get a
"11"
列表 list
是LinkedList, 插入删除 O(1), 索引 O(n).
list是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等。操作中key理解为链表的名字。
对list的定义和实现在源文件adlist.h/adlist.c,相关的数据结构定义如下:
#ifndef __ADLIST_H__
#define __ADLIST_H__
/* Node, List, and Iterator are the only data structures used currently. */
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct listIter {
listNode *next;
int direction;
} listIter;
typedef struct list {
listNode *head;
listNode *tail;
void *(*dup)(void *ptr);
void (*free)(void *ptr);
int (*match)(void *ptr, void *key);
unsigned long len;
} list;
/* Functions implemented as macros */
#define listLength(l) ((l)->len)
#define listFirst(l) ((l)->head)
#define listLast(l) ((l)->tail)
#define listPrevNode(n) ((n)->prev)
#define listNextNode(n) ((n)->next)
#define listNodeValue(n) ((n)->value)
#define listSetDupMethod(l,m) ((l)->dup = (m))
#define listSetFreeMethod(l,m) ((l)->free = (m))
#define listSetMatchMethod(l,m) ((l)->match = (m))
#define listGetDupMethod(l) ((l)->dup)
#define listGetFree(l) ((l)->free)
#define listGetMatchMethod(l) ((l)->match)
/* Prototypes */
list *listCreate(void);
void listRelease(list *list);
void listEmpty(list *list);
list *listAddNodeHead(list *list, void *value);
list *listAddNodeTail(list *list, void *value);
list *listInsertNode(list *list, listNode *old_node, void *value, int after);
void listDelNode(list *list, listNode *node);
listIter *listGetIterator(list *list, int direction);
listNode *listNext(listIter *iter);
void listReleaseIterator(listIter *iter);
list *listDup(list *orig);
listNode *listSearchKey(list *list, void *key);
listNode *listIndex(list *list, long index);
void listRewind(list *list, listIter *li);
void listRewindTail(list *list, listIter *li);
void listRotate(list *list);
void listJoin(list *l, list *o);
/* Directions for iterators */
#define AL_START_HEAD 0
#define AL_START_TAIL 1
#endif /* __ADLIST_H__ */
命令行实例:
127.0.0.1:6379> rpush b 1 2 3 4 5
(integer) 5
127.0.0.1:6379> llen b
(integer) 5
127.0.0.1:6379> lpop b
"1"
127.0.0.1:6379> lpop b
"2"
127.0.0.1:6379> lpop b
"3"
127.0.0.1:6379> lpop b
"4"
127.0.0.1:6379> lpop b
"5"
127.0.0.1:6379> lpop b
(nil)
quicklist概述
Redis对外暴露的上层list数据类型,经常被用作队列使用。比如它支持的如下一些操作:
lpush: 在左侧(即列表头部)插入数据。
rpop: 在右侧(即列表尾部)删除数据。
rpush: 在右侧(即列表尾部)插入数据。
lpop: 在左侧(即列表头部)删除数据。
这些操作都是O(1)时间复杂度的。
当然,list也支持在任意中间位置的存取操作,比如lindex和linsert,但它们都需要对list进行遍历,所以时间复杂度较高,为O(N)。
概况起来,list具有这样的一些特点:它是一个能维持数据项先后顺序的列表(各个数据项的先后顺序由插入位置决定),便于在表的两端追加和删除数据,而对于中间位置的存取具有O(N)的时间复杂度。这不正是一个双向链表所具有的特点吗?
list的内部实现quicklist正是一个双向链表。在quicklist.c的文件头部注释中,是这样描述quicklist的:
A doubly linked list of ziplists
它确实是一个双向链表,而且是一个ziplist的双向链表。
考虑到链表的附加空间相对太高,prev 和 next 指针就要占去 16 个字节 (64bit 系统的指针是 8 个字节),另外每个节点的内存都是单独分配,会加剧内存的碎片化,影响内存管理效率。后续版本对列表数据结构进行了改造,使用 quicklist 代替了 ziplist 和 linkedlist.
quickList 是 zipList 和 linkedList 的混合体,它将 linkedList 按段切分,每一段使用 zipList 来紧凑存储,多个 zipList 之间使用双向指针串接起来。
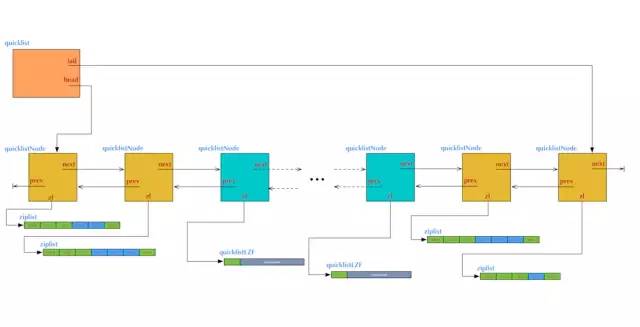
/* Node, quicklist, and Iterator are the only data structures used currently. */
typedef struct quicklist {
quicklistNode *head;
quicklistNode *tail;
unsigned long count; /* total count of all entries in all ziplists */
unsigned long len; /* number of quicklistNodes */
int fill : 16; /* fill factor for individual nodes */
unsigned int compress : 16; /* depth of end nodes not to compress;0=off */
} quicklist;
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist.
* We use bit fields keep the quicklistNode at 32 bytes.
* count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k).
* encoding: 2 bits, RAW=1, LZF=2.
* container: 2 bits, NONE=1, ZIPLIST=2.
* recompress: 1 bit, bool, true if node is temporarry decompressed for usage.
* attempted_compress: 1 bit, boolean, used for verifying during testing.
* extra: 10 bits, free for future use; pads out the remainder of 32 bits */
typedef struct quicklistNode {
struct quicklistNode *prev;
struct quicklistNode *next;
unsigned char *zl;
unsigned int sz; /* ziplist size in bytes */
unsigned int count : 16; /* count of items in ziplist */
unsigned int encoding : 2; /* RAW==1 or LZF==2 */
unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */
unsigned int recompress : 1; /* was this node previous compressed? */
unsigned int attempted_compress : 1; /* node can't compress; too small */
unsigned int extra : 10; /* more bits to steal for future usage */
} quicklistNode;
字典 hash
相当于 HashMap, rehash 的策略不同,redis 为了保证高性能,采用了新旧 hash 渐进式迁移的策略.
dict(hash表)
set是集合,和我们数学中的集合概念相似,对集合的操作有添加删除元素,有对多个集合求交并差等操作。操作中key理解为集合的名字。
dict中table为dictEntry指针的数组,数组中每个成员为hash值相同元素的单向链表。set是在dict的基础上实现的,指定了key的比较函数为dictEncObjKeyCompare,若key相等则不再插入。
在源文件dict.h/dict.c中实现了hashtable的操作,数据结构的定义如下:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
typedef struct dictType {
uint64_t (*hashFunction)(const void *key);
void *(*keyDup)(void *privdata, const void *key);
void *(*valDup)(void *privdata, const void *obj);
int (*keyCompare)(void *privdata, const void *key1, const void *key2);
void (*keyDestructor)(void *privdata, void *key);
void (*valDestructor)(void *privdata, void *obj);
} dictType;
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
...
命令行实例:
127.0.0.1:6379> hset c id 10000
(integer) 1
127.0.0.1:6379> hget c id
"10000"
127.0.0.1:6379> hgetall c
1) "id"
2) "10000"
集合 set
相当于 HashSet.
zset是set的一个升级版本,他在set的基础上增加了一个顺序属性,这一属性在添加修改元素的时候可以指定,每次指定后,zset会自动重新按新的值调整顺序。可以理解了有两列的mysql表,一列存value,一列存顺序。操作中key理解为zset的名字。
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned long span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
typedef struct zset {
dict *dict;
zskiplist *zsl;
} zset;
zset利用dict维护key -> value的映射关系,用zsl(zskiplist)保存value的有序关系。zsl实际是叉数
不稳定的多叉树,每条链上的元素从根节点到叶子节点保持升序排序。
命令行实例:
127.0.0.1:6379> sadd id 100
(integer) 1
127.0.0.1:6379> sadd id 100
(integer) 0
127.0.0.1:6379> sadd id 200
(integer) 1
有序集合 zset
跳跃表的数据结构.
混搭链表+数组.
SortedSet + HashMap
命令行实例:
127.0.0.1:6379> zadd prices 100 "Apple"
(integer) 1
127.0.0.1:6379> zadd prices 90 "Google"
(integer) 1
127.0.0.1:6379> zadd prices 80 "Microsoft"
(integer) 1
127.0.0.1:6379> zrange prices 0 -1
1) "Microsoft"
2) "Google"
3) "Apple"
127.0.0.1:6379> zrevrange prices 0 -1
1) "Apple"
2) "Google"
3) "Microsoft"
认识跳表
redis 中 zset 是一个有序非线性的数据结构,它底层核心的数据结构是跳表. 跳表(skiplist)是一个特俗的链表,相比一般的链表,有更高的查找效率,其效率可比拟于二叉查找树。
一张关于跳表和跳表搜索过程如下图:
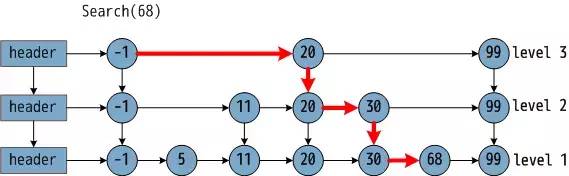
在图中,需要寻找 68,在给出的查找过程中,利用跳表数据结构优势,只比较了 3次,横箭头不比较,竖箭头比较。由此可见, 跳表预先间隔地保存了有序链表中的节点,从而在查找过程中能达到类似于二分搜索的效果, 而二分搜索思想就是通过比较中点数据放弃另一半的查找,从而节省一半的查找时间。
缺点即浪费了空间,自古空间和时间两难全。
插播一段:跳表在 1990年由 William Pugh 提出,而红黑树早在 1972年由鲁道夫·贝尔发明了。红黑树在空间和时间效率上略胜跳表一筹,但跳表实现相对简单得到程序猿们的青睐。redis 和 leveldb 中都有采用跳表。
(参考文章: http://ju.outofmemory.cn/entry/81525)
跳表的提出
跳表首先由William Pugh在其1990年的论文《Skip lists: A probabilistic alternative to balanced trees》中提出。由该论文的题目可以知道两点:
-
跳表是概率型数据结构。
-
跳表是用来替代平衡树的数据结构。准确来说,是用来替代自平衡二叉查找树(self-balancing BST)的结构。
看官可能会觉得这两点与之前文章中讲过的布隆过滤器有些相似,但实际上它们的原理和用途还是很不相同的。
由二叉树回归链表
考虑在有序序列中查找某个特定元素的情境:
-
如果该序列用支持随机访问的线性结构(数组)存储,那么我们很容易地用二分查找来做。
-
但是考虑到增删效率和内存扩展性,很多时候要用不支持随机访问的线性结构(链表)存储,就只能从头遍历、逐个比对。
-
作为折衷,如果用二叉树结构(BST)存储,就可以不靠随机访问特性进行二分查找了。
我们知道,普通BST插入元素越有序效率越低,最坏情况会退化回链表。因此很多大佬提出了自平衡BST结构,使其在任何情况下的增删查操作都保持O(logn)的时间复杂度。自平衡BST的代表就是AVL树、Splay树、2-3树及其衍生出的红黑树。如果推广之,不限于二叉树的话,我们耳熟能详的B树和B+树也属此类,常用于文件系统和数据库。
自平衡BST显然很香,但是它仍然有一个不那么香的点:树的自平衡过程比较复杂,实现起来麻烦,在高并发的情况下,加锁也会带来可观的overhead。如AVL树需要LL、LR、RL、RR四种旋转操作保持平衡,红黑树则需要左旋、右旋和节点变色三种操作。下面的动图展示的就是AVL树在插入元素时的平衡过程。

那么,有没有简单点的、与自平衡BST效率相近的实现方法呢?答案就是跳表,并且它简单很多,下面就来看一看。
设计思想与查找流程
跳表就是如同下图一样的许多链表的集合。

跳表具有如下的性质:
-
由多层组成,最底层为第1层,次底层为第2层,以此类推。层数不会超过一个固定的最大值L max 。
-
每层都是一个有头节点的有序链表,第1层的链表包含跳表中的所有元素。
-
如果某个元素在第k层出现,那么在第1~k-1层也必定都会出现,但会按一定的概率p在第k+1层出现。
很显然这是一种空间换时间的思路,与索引异曲同工。第k层可以视为第k-1级索引,用来加速查找。为了避免占用空间过多,第1层之上都不存储实际数据,只有指针(包含指向同层下一个元素的指针与同一个元素下层的指针)。
当查找元素时,会从最顶层链表的头节点开始遍历。以升序跳表为例,如果当前节点的下一个节点包含的值比目标元素值小,则继续向右查找。如果下一个节点的值比目标值大,就转到当前层的下一层去查找。重复向右和向下的操作,直到找到与目标值相等的元素为止。下图中的蓝色箭头标记出了查找元素21的步骤。

通过图示,我们也可以更加明白“跳表”这个名称的含义,因为查找过程确实是跳跃的,比线性查找省时。若要查找在高层存在的元素(如25),步数就会变得更少。当数据量越来越大时,这种结构的优势就更加明显了。
插入元素的概率性
前文已经说过,跳表第k层的元素会按一定的概率p在第k+1层出现,这种概率性就是在插入过程中实现的。
当按照上述查找流程找到新元素的插入位置之后,首先将其插入第1层。至于是否要插入第2,3,4...层,就需要用随机数等方法来确定。最通用的实现方法描述如下。
int randomizeLevel(double p, int lmax) {
int level = 1;
Random random = new Random();
while (random.nextDouble() < p && level < lmax) {
level++;
}
return level;
}
得到层数k之后,就将新元素插入跳表的第1~k层。由上面的逻辑可知,随着层数的增加,元素被插入高层的概率会指数级下降。
下面的动图示出以p=1/2概率在跳表中插入元素的过程。这种方法也被叫做“抛钢镚儿”(coin flip),直到抛出正面/反面就停止。
相对于插入而言,删除元素没有这么多弯弯绕,基本上就是正常的单链表删除逻辑,因此不再展开。
(参考链接:https://www.jianshu.com/p/09c3b0835ba6)
redis 数据存储
redis使用了两种文件格式:全量数据和增量请求。
全量数据格式是把内存中的数据写入磁盘,便于下次读取文件进行加载;
增量请求文件则是把内存中的数据序列化为操作请求,用于读取文件进行replay得到数据,序列化的操作包括SET、RPUSH、SADD、ZADD。
redis的存储分为内存存储、磁盘存储和log文件三部分,配置文件中有三个参数对其进行配置。
Spring Boot 项目实战
创建 Spring Boot 工程
创建 maven 工程, 目录树结构如下:
.
├── HELP.md
├── mvnw
├── mvnw.cmd
├── pom.xml
├── redis-demo.iml
└── src
├── main
│ ├── kotlin
│ │ └── com
│ │ └── example
│ │ └── redisdemo
│ │ └── RedisDemoApplication.kt
│ └── resources
│ ├── application.properties
│ ├── static
│ └── templates
└── test
└── kotlin
└── com
└── example
└── redisdemo
└── RedisDemoApplicationTests.kt
14 directories, 8 files
其中, pom.xml 新增 redis 依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置 Redis
redis.yml 配置文件
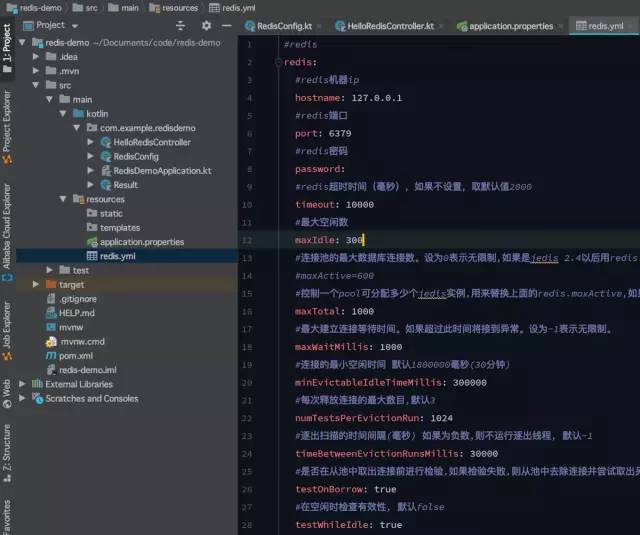
redis.yml 配置文件内容如下:
#redis
redis:
#redis机器ip
hostname: 127.0.0.1
#redis端口
port: 6379
#redis密码
password:
#redis超时时间(毫秒),如果不设置,取默认值2000
timeout: 10000
#最大空闲数
maxIdle: 300
#连接池的最大数据库连接数。设为0表示无限制,如果是jedis 2.4以后用redis.maxTotal
#maxActive=600
#控制一个pool可分配多少个jedis实例,用来替换上面的redis.maxActive,如果是jedis 2.4以后用该属性
maxTotal: 1000
#最大建立连接等待时间。如果超过此时间将接到异常。设为-1表示无限制。
maxWaitMillis: 1000
#连接的最小空闲时间 默认1800000毫秒(30分钟)
minEvictableIdleTimeMillis: 300000
#每次释放连接的最大数目,默认3
numTestsPerEvictionRun: 1024
#逐出扫描的时间间隔(毫秒) 如果为负数,则不运行逐出线程, 默认-1
timeBetweenEvictionRunsMillis: 30000
#是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个
testOnBorrow: true
#在空闲时检查有效性, 默认false
testWhileIdle: true
#redis集群配置
#spring.cluster.nodes=192.168.1.1:7001,192.168.1.1:7002,192.168.1.1:7003,192.168.1.1:7004,192.168.1.1:7005,192.168.1.1:7006
#spring.cluster.max-redirects=3
#哨兵模式
#sentinel.host1=192.168.1.1
#sentinel.port1=26379
#sentinel.host2=192.168.1.2
#sentinel.port2=26379
其中redis.yml是连接redis的配置文件.
RedisConfig 配置类
package com.example.redisdemo
import org.springframework.beans.factory.annotation.Configurable
import org.springframework.boot.autoconfigure.AutoConfigureAfter
import org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration
import org.springframework.context.annotation.Bean
import org.springframework.data.redis.connection.lettuce.LettuceConnectionFactory
import org.springframework.data.redis.core.RedisTemplate
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer
import org.springframework.data.redis.serializer.StringRedisSerializer
import java.io.Serializable
@Configurable
@AutoConfigureAfter(value = [RedisAutoConfiguration::class])
class RedisConfig {
@Bean
fun redisTemplate(redisConnectionFactory: LettuceConnectionFactory): RedisTemplate<String, Serializable> {
val t = RedisTemplate<String, Serializable>()
t.keySerializer = StringRedisSerializer()
t.valueSerializer = GenericJackson2JsonRedisSerializer()
t.setConnectionFactory(redisConnectionFactory)
return t
}
}
// StringRedisSerializer: Simple {@link java.lang.String} to {@literal byte[]} (and back) serializer.
// GenericJackson2JsonRedisSerializer: Generic Jackson 2-based {@link RedisSerializer} that maps {@link Object objects} to JSON using dynamic typing.
// GenericJackson2JsonRedisSerializer implements RedisSerializer<Object>,
// RedisSerializer: Basic interface serialization and deserialization of Objects to byte arrays (binary data).
随着Spring Boot2.x的到来,支持的组件越来越丰富,也越来越成熟,其中对Redis的支持不仅仅是丰富了它的API,更是替换掉底层Jedis的依赖,取而代之换成了Lettuce(生菜).
Lettuce和Jedis的都是连接Redis Server的客户端程序。Jedis在实现上是直连redis server,多线程环境下非线程安全,除非使用连接池,为每个Jedis实例增加物理连接。Lettuce基于Netty的连接实例(StatefulRedisConnection),可以在多个线程间并发访问,且线程安全,满足多线程环境下的并发访问,同时它是可伸缩的设计,一个连接实例不够的情况也可以按需增加连接实例。
RedisAutoConfiguration 自动配置类
其中, RedisAutoConfiguration 自动配置类中初始化了两个 Redis 的操作类:
代码如下:
package org.springframework.boot.autoconfigure.data.redis;
import java.net.UnknownHostException;
import org.springframework.boot.autoconfigure.EnableAutoConfiguration;
import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;
import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;
import org.springframework.boot.context.properties.EnableConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisOperations;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.core.StringRedisTemplate;
/**
* {@link EnableAutoConfiguration Auto-configuration} for Spring Data's Redis support.
*
* @author Dave Syer
* @author Andy Wilkinson
* @author Christian Dupuis
* @author Christoph Strobl
* @author Phillip Webb
* @author Eddú Meléndez
* @author Stephane Nicoll
* @author Marco Aust
* @author Mark Paluch
* @since 1.0.0
*/
@Configuration(proxyBeanMethods = false)
@ConditionalOnClass(RedisOperations.class)
@EnableConfigurationProperties(RedisProperties.class)
@Import({ LettuceConnectionConfiguration.class, JedisConnectionConfiguration.class })
public class RedisAutoConfiguration {
@Bean
@ConditionalOnMissingBean(name = "redisTemplate")
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
RedisTemplate<Object, Object> template = new RedisTemplate<>();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
@Bean
@ConditionalOnMissingBean
public StringRedisTemplate stringRedisTemplate(RedisConnectionFactory redisConnectionFactory)
throws UnknownHostException {
StringRedisTemplate template = new StringRedisTemplate();
template.setConnectionFactory(redisConnectionFactory);
return template;
}
}
StringRedisTemplate与RedisTemplate区别点
两者的关系是 StringRedisTemplate 继承 RedisTemplate:
public class StringRedisTemplate extends RedisTemplate<String, String> {
/**
* Constructs a new <code>StringRedisTemplate</code> instance. {@link #setConnectionFactory(RedisConnectionFactory)}
* and {@link #afterPropertiesSet()} still need to be called.
*/
public StringRedisTemplate() {
setKeySerializer(RedisSerializer.string());
setValueSerializer(RedisSerializer.string());
setHashKeySerializer(RedisSerializer.string());
setHashValueSerializer(RedisSerializer.string());
}
/**
* Constructs a new <code>StringRedisTemplate</code> instance ready to be used.
*
* @param connectionFactory connection factory for creating new connections
*/
public StringRedisTemplate(RedisConnectionFactory connectionFactory) {
this();
setConnectionFactory(connectionFactory);
afterPropertiesSet();
}
protected RedisConnection preProcessConnection(RedisConnection connection, boolean existingConnection) {
return new DefaultStringRedisConnection(connection);
}
}
RedisTemplate 实现 RedisOperations 接口.
-
两者的数据是不共通的;也就是说StringRedisTemplate只能管理StringRedisTemplate里面的数据,RedisTemplate只能管理RedisTemplate中的数据。
-
其实他们两者之间的区别主要在于他们使用的序列化类:
RedisTemplate使用的是JdkSerializationRedisSerializer 存入数据会将数据先序列化成字节数组然后在存入Redis数据库。
StringRedisTemplate使用的是StringRedisSerializer.
什么时候用StringRedisTemplate
当你的redis数据库里面本来存的是字符串数据或者你要存取的数据就是字符串类型数据的时候,那么你就使用StringRedisTemplate即可。
但是如果你的数据是复杂的对象类型,而取出的时候又不想做任何的数据转换,直接从Redis里面取出一个对象,那么使用RedisTemplate是更好的选择。
RedisTemplate使用时常见问题:
redisTemplate 中存取数据都是字节数组。当redis中存入的数据是可读形式而非字节数组时,使用redisTemplate取值的时候会无法获取导出数据,获得的值为null。可以使用 StringRedisTemplate 试试。
RedisTemplate中定义了5种数据结构操作
redisTemplate.opsForValue(); //操作字符串
redisTemplate.opsForHash(); //操作hash
redisTemplate.opsForList(); //操作list
redisTemplate.opsForSet(); //操作set
redisTemplate.opsForZSet(); //操作有序set
StringRedisTemplate常用操作
stringRedisTemplate.opsForValue().set("test", "100",60*10,TimeUnit.SECONDS);//向redis里存入数据和设置缓存时间
stringRedisTemplate.boundValueOps("test").increment(-1);//val做-1操作
stringRedisTemplate.opsForValue().get("test")//根据key获取缓存中的val
stringRedisTemplate.boundValueOps("test").increment(1);//val +1
stringRedisTemplate.getExpire("test")//根据key获取过期时间
stringRedisTemplate.getExpire("test",TimeUnit.SECONDS)//根据key获取过期时间并换算成指定单位
stringRedisTemplate.delete("test");//根据key删除缓存
stringRedisTemplate.hasKey("546545");//检查key是否存在,返回boolean值
stringRedisTemplate.opsForSet().add("red_123", "1","2","3");//向指定key中存放set集合
stringRedisTemplate.expire("red_123",1000 , TimeUnit.MILLISECONDS);//设置过期时间
stringRedisTemplate.opsForSet().isMember("red_123", "1")//根据key查看集合中是否存在指定数据
stringRedisTemplate.opsForSet().members("red_123");//根据key获取set集合
StringRedisTemplate的使用
springboot中使用注解@Autowired 即可
@Autowired
public StringRedisTemplate stringRedisTemplate;
Kotlin 代码操作 Redis
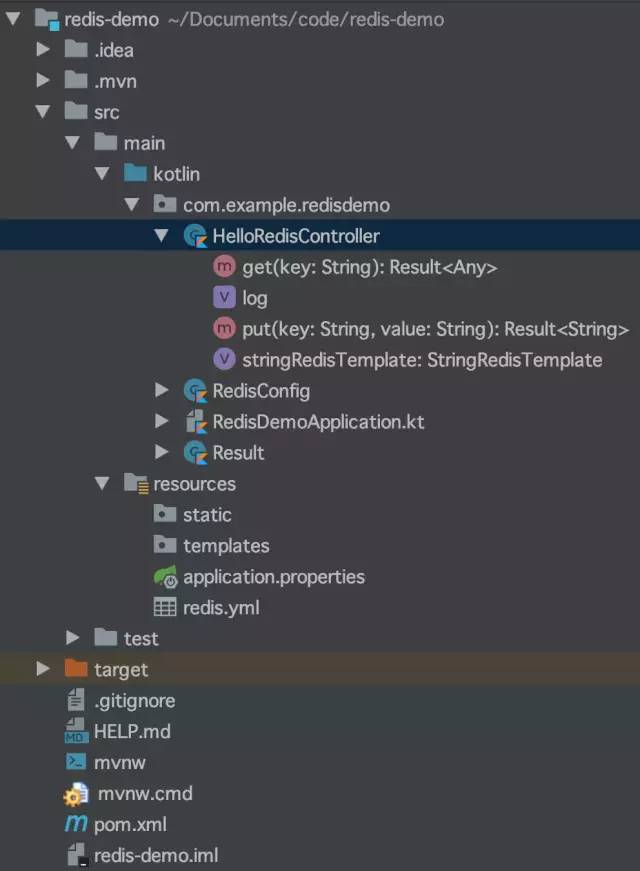
HelloRedisController.kt 代码如下:
package com.example.redisdemo
import org.slf4j.LoggerFactory
import org.springframework.beans.factory.annotation.Autowired
import org.springframework.data.redis.core.StringRedisTemplate
import org.springframework.web.bind.annotation.GetMapping
import org.springframework.web.bind.annotation.RequestMapping
import org.springframework.web.bind.annotation.RequestParam
import org.springframework.web.bind.annotation.RestController
@RestController
@RequestMapping("/redis")
class HelloRedisController {
val log = LoggerFactory.getLogger(this::class.java)
@Autowired
lateinit var stringRedisTemplate: StringRedisTemplate
@GetMapping("/put")
fun put(@RequestParam("key") key: String,
@RequestParam("value") value: String): Result<String> {
return try {
stringRedisTemplate.opsForValue().set(key, value)
Result(data = key, success = true, msg = null)
} catch (e: Exception) {
log.error("testRedis put:", e)
Result(data = key, success = false, msg = e.message)
}
}
@GetMapping("/get")
fun get(@RequestParam("key") key: String): Result<Any> {
return try {
val v = stringRedisTemplate.opsForValue().get(key)
Result(data = v, success = true, msg = null)
} catch (e: Exception) {
log.error("testRedis put:", e)
Result(data = null, success = false, msg = e.message)
}
}
}
运行测试
put key :
http://127.0.0.1:8080/redis/put?key=1&value=A
// http://127.0.0.1:8080/redis/put?key=1&value=A
{
"data": "1",
"msg": null,
"success": true
}
get key:
http://127.0.0.1:8080/redis/get?key=1
// http://127.0.0.1:8080/redis/get?key=1
{
"data": "A",
"msg": null,
"success": true
}
redis-cli 中查看数据:
127.0.0.1:6379> get 1
"A"
小结
本文简单介绍了 Redis 的入门基础知识, 同时简单地剖析了一下源码实现.
Redis 应用非常广泛, 要深入学习,理解背后的原理机制.
示例工程源码:
https://github.com/Jason-Chen-2017/redis-demo
Kotlin 开发者社区

国内第一Kotlin 开发者社区公众号,主要分享、交流 Kotlin 编程语言、Spring Boot、Android、React.js/Node.js、函数式编程、编程思想等相关主题。
越是喧嚣的世界,越需要宁静的思考。
正文到此结束
- 本文标签: 多线程 空间 json 开发 core 文章 IO web Sentinel remote Proxy ip 2019 进程 UI Apple 实例 参数 src python NIO zip springboot 端口 连接池 rand 线程 配置 Netty 注释 DOM 程序猿 dist ACE cache java 高并发 cmd LinkedList mina tk 数据库 安装 API 时间 遍历 REST example Word bean spring Spring Boot tab 索引 占用空间 HashSet tar map 管理 代码 Android list Connection 删除 函数式编程 rmi id 源码 HashTable pom 并发 js sql 大数据 GitHub HTML value 同步 http JavaScript 目录 服务端 测试 HashMap maven stream https 安全 redis Node.js App key 开源 ask connectionFactory mysql Master 升级版本 架构师 db zab git 集群 数据 Google CTO XML 锁 推广 message 文件系统 PHP EnableAutoConfiguration node 缓存 struct cat 开发者
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

