Skywalking源码分析指北第十一篇——DataCarrier

前情回顾
前文介绍了 Skywalking 中提供的一些插件,例如,Tomcat 插件、Dubbo 插件等等,同时也简单介绍了 Tomcat 的架构以及 Dubbo Filter 相关的基础知识。从本节开始,我们来看 Skywalking Agent 发送 Trace 数据的相关实现。
DataCarrier


DataCarrier 是一个轻量级的生产者-消费者模式的实现库, Skywalking Agent 在收集到 Trace 数据之后,会先将 Trace 数据写入到 DataCarrier 中缓存,然后由后台线程定时发送到 Skywalking 服务端。呦吼,和前面介绍的 Dubbo MonitorFilter 的实现原理类似啊,emmm,其实多数涉及到大量网络传输的场景都会这么设计:先本地缓存聚合,然后定时发送。
DataCarrier 实现在 Skywalking 中是一个单独的模块,如下图所示,行吧,这么多?!有的看了:
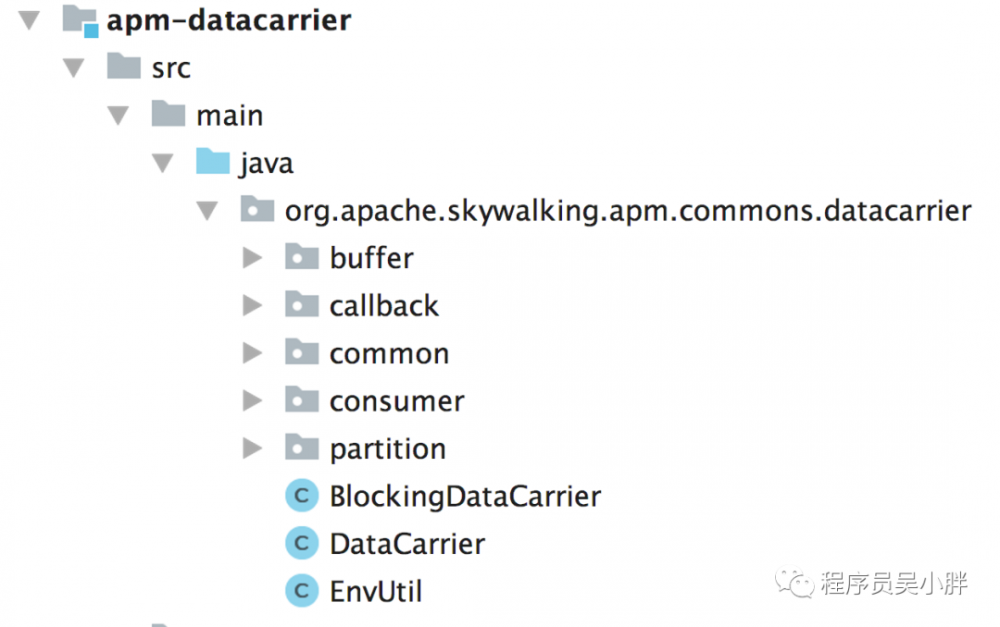
首先来看 Buffer 这个类,它是一个环形缓冲区,是整个 DataCarrier 最底层的一个类,其核心字段如下:
// 真正缓存数据的数组
private final Object[] buffer;
// BufferStrategy指定了缓冲区满了之后的填充策略,是个枚举,有三个可选项:
// 1.BLOCKING(默认),写入线程阻塞等待,直到数据被消费为止
// 2.OVERRIDE,复写旧数据,旧数据被丢弃
// 3.IF_POSSIBLE,如果无法写入则直接返回false,由应用程序判断如何处理
private BufferStrategy strategy;
// 环形的指针,后面展开详细说其实现
private AtomicRangeInteger index;
// 回调函数集合
private List<QueueBlockingCallback<T>> callbacks;
这里的 AtomicRangeInteger 是环形指针,我们可以指定其中的 value字段(AtomicInteger类型)从 start值(int类型)开始递增,当 value 递增到 end值(int类型)时,value字段会被重置为 start值,从而实现环形指正的效果。
Buffer.save() 方法负责向当前 Buffer 缓冲区中填充数据,实现如下:
boolean save(T data) {
int i = index.getAndIncrement();
// 如果当前位置空着,则不用走strategy指定冲突处理策略,直接填充即可,皆大欢喜
if (buffer[i] != null) {
switch (strategy) {
case BLOCKING:
boolean isFirstTimeBlocking = true;
while (buffer[i] != null) {// 自选等待当前位置被释放
if (isFirstTimeBlocking) { // 第一个阻塞在当前位置的线程,会通知所有注册的Callback
isFirstTimeBlocking = false;
for (QueueBlockingCallback<T> callback : callbacks) {
callback.notify(data);
}
}
Thread.sleep(1L); // sleep 1s
}
break;
case IF_POSSIBLE:
return false; // 直接返回false
case OVERRIDE: // 啥都不做,直接走下面的赋值,覆盖旧数据
default:
}
}
buffer[i] = data; // 向当前位置填充数据
return true;
}
个人感觉: BLOCKING 策略下,Buffer 在写满之后,index 发生循环, 可能会出现两个线程同时等待写入一个位置的情况,有并发问题啊,会丢数据~~~看官大佬们可以自己思考一下~~~
生产者用的是 save() 方法,消费者用的是 Buffer.obtain() 方法:
public LinkedList<T> obtain(int start, int end) {
LinkedList<T> result = new LinkedList<T>();
// 将 start~end 之间的元素返回,消费者消费这个result集合就行了
for (int i = start; i < end; i++) {
if (buffer[i] != null) {
result.add((T)buffer[i]);
buffer[i] = null;
}
}
return result;
}
Channels 是另一个比较基础的类,它底层封装了多个 Buffer 实例以及一个分区选择器,字段如下所示:
// 底层封装的多个环形缓冲区
private final Buffer<T>[] bufferChannels;
// 分区选择器,由它确定数据到底写入哪个缓冲区
private IDataPartitioner<T> dataPartitioner;
// 缓冲区满时的写入策略
private BufferStrategy strategy;
// 整个Channels的总大小,实际就是所有底层Buffer的和
private final long size;
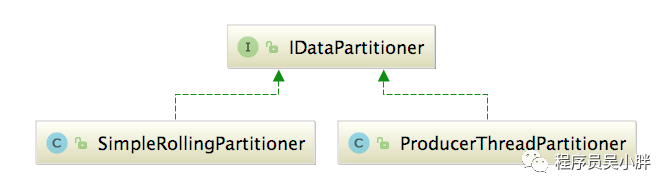
IDataPartitioner 提供了类似于 Kafka 的分区功能,当数据并行写入的时候,由分区选择器定将数据写入哪个分区,这样就可以有效降低并发导致的锁(或CAS)竞争,降低写入压力,可提高效率。IDataPartitioner 接口有两个实现,如下下图所示:
-
ProducerThreadPartitioner会根据写入线程的ID进行选择,这样可以保证相同的线程号写入的数据都在一个分区中。
-
SimpleRollingPartitioner简单循环自增选择器,使用无锁整型(volatile修饰)的自增,顺序选择线程号,在高负载时,会产生批量连续写入一个分区的效果,在中等负载情况下,提供较好性能。
下面来看 IConsumer 接口, DataCarrier 的消费者逻辑需要封装在其中。IConsumer 接口定义了消费者的基本行为:
public interface IConsumer<T> {
void init(); // 初始化消费者。
void consume(List<T> data); // 批量消费消息
void onError(List<T> data, Throwable t); // 处理当消费发生异常。
void onExit(); // 处理当消费结束,关闭ConsumerThread
}
后面即将介绍的 TraceSegmentServiceClient 类就实现了 IConsumer 接口,后面展开说。
ConsumerThread 继承了Thread,表示的是消费者线程,其核心字段如下:
private volatile boolean running; // 当前线程运行状态
private IConsumer<T> consumer; // 消费者逻辑
// 对Buffer的封装,负责从Buffer取数据
// 一个 ConsumerThread可以消费多个 Buffer
private List<DataSource> dataSources;
private long consumeCycle; // 两次执行 IConsumer.consume()方法的时间间隔
ConsumerThread.run() 方法会循环 consume() 方法:
public void run() {
running = true;
while (running) { // 判断当前线程的状态
boolean hasData = consume(); // 消费数据
if (!hasData) {
Thread.sleep(consumeCycle); // 没数据的话,等一下再消费
}
}
consume();
consumer.onExit(); // 退出前的处理
}
ConsumerThread.consume() 方法是消费的核心:
private boolean consume() {
boolean hasData = false;
LinkedList<T> consumeList = new LinkedList<T>();
for (DataSource dataSource : dataSources) {
// DataSource.obtain()方法是对Buffer.obtain()方法的封装
LinkedList<T> data = dataSource.obtain();
if (data.size() == 0) { continue; }
consumeList.addAll(data); // 将所有待消费的数据转存到consumeList
hasData = true; // 标记此次消费是否有数据
}
if (consumeList.size() > 0) {
try {
// 消费
consumer.consume(consumeList);
} catch (Throwable t) {// 消费过程中出现异常的时候
consumer.onError(consumeList, t);
}
}
return hasData;
}
另一个消费者线程是 MultipleChannelsConsumer,与 ConsumerThread 的区别在于:
-
ConsumerThread 处理的是一个确定的 IConsumer 消费一个 Channel 中的多个 Buffer。
-
MultipleChannelsConsumer 可以处理多组 Group,每个 Group 都是一个IConsumer+一个 Channels。
先来看 MultipleChannelsConsumer 的核心字段:
private volatile boolean running; // 线程状态
// 一个Channels以及其对应的IConsumer封装成一个Group实例
private volatile ArrayList<Group> consumeTargets;
MultipleChannelsConsumer.consume()方法消费的依然是单个IConsumer,这里不再展开分析。在 MultipleChannelsConsumer.run()方法中会循环每个 Group:
public void run() {
running = true;
while (running) {
boolean hasData = false;
for (Group target : consumeTargets) {
// 调用consume()方法,处理单个 Group
hasData = hasData || consume(target);
}
if (!hasData) { // 没数据,则等待一会儿
Thread.sleep(consumeCycle);
}
}
// MultipleChannelsConsumer线程关闭之前,再清理一下
for (Group target : consumeTargets) {
consume(target);
target.consumer.onExit();
}
}
在 MultipleChannelsConsumer.addNewTarget() 方法中会添加新的 Group。这里用了 Copy-on-Write,因为在添加的过程中,MultipleChannelsConsumer线程可能正在循环处理 consumeTargets 集合(这也是为什么 consumeTargets 用 volatile 修饰的原因):
public void addNewTarget(Channels channels, IConsumer consumer) {
Group group = new Group(channels, consumer);
ArrayList<Group> newList = new ArrayList<Group>();
for (Group target : consumeTargets) {
newList.add(target);
}
newList.add(group);
consumeTargets = newList;
size += channels.size();
}
IDriver 负责将 ConsumerThread 和 IConsumer 集成到一起,其实现类如下:
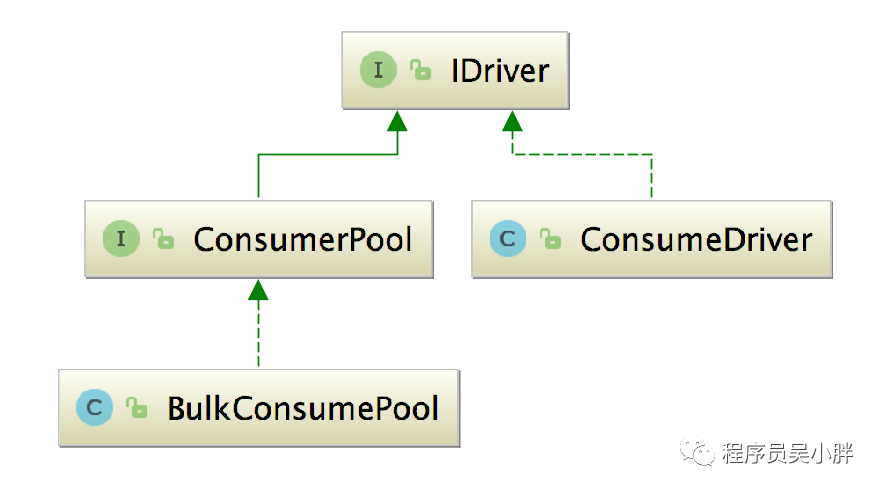
先来看 ConsumeDriver,核心字段如下:
private ConsumerThread[] consumerThreads; // 消费线程
private Channels<T> channels; // 被消费的缓冲区
在 ConsumeDriver 的构造方法中,会初始化上述两个集合:
private ConsumeDriver(String name, Channels<T> channels, Class<? extends IConsumer<T>> consumerClass, int num,
long consumeCycle) {
running = false;
this.channels = channels; // 初始化channels集合和consumerThreads集合
consumerThreads = new ConsumerThread[num];
lock = new ReentrantLock();
for (int i = 0; i < num; i++) {
consumerThreads[i] = new ConsumerThread("DataCarrier." + name + ".Consumser." + i + ".Thread",
// 反射方式实例化 IConsumer对象
getNewConsumerInstance(consumerClass),
consumeCycle);
consumerThreads[i].setDaemon(true);
}
}
完成初始化之后,要调用 ConsumeDriver.begin() 方法,其中会根据 Buffer 的数量以及ConsumerThread 线程数进行分配:
-
如果 Buffer 个数较多,则一个 ConsumerThread 线程需要处理多个 Buffer。
-
如果 ConsumerThread 线程数较多,则一个 Buffer 被多个 ConsumerThread 线程处理(每个 ConsumerThread 线程负责消费这个 Buffer 的一段)。
-
如果两者数量正好相同,则是一对一关系。
逻辑虽然很简单,但是具体的分配代码比较长,这里就不粘贴了。
BulkConsumePool 是 IDriver 接口的另一个实现,其中的 allConsumers 字段(List<MultipleChannelsConsumer>类型)记录了当前启动的 MultipleChannelsConsumer 线程,在 BulkConsumePool 的构造方法中会根据配置初始化该集合:
public BulkConsumePool(String name, int size, long consumeCycle) {
size = EnvUtil.getInt(name + "_THREAD", size); // 配置的线程个数
allConsumers = new ArrayList<MultipleChannelsConsumer>(size);
for (int i = 0; i < size; i++) {
// 创建 MultipleChannelsConsumer对象
MultipleChannelsConsumer multipleChannelsConsumer = new MultipleChannelsConsumer("...", consumeCycle);
multipleChannelsConsumer.setDaemon(true); // 后台线程
allConsumers.add(multipleChannelsConsumer);
}
}
BulkConsumePool.add() 方法提供了添加新 Group的功能:
synchronized public void add(String name, Channels channels, IConsumer consumer) {
// 查找负载最低的 MultipleChannelsConsumer线程,其实就是负责的 Group个数最少的线程
MultipleChannelsConsumer multipleChannelsConsumer = getLowestPayload();
// 添加新的 Group,Copy-on-Write
multipleChannelsConsumer.addNewTarget(channels, consumer);
}
最后来看 DataCarrier ,它是整个 DataCarrier 库的入口和门面,其核心字段如下:
private String name; // 当前 DataCarrier实例的名称
private final int bufferSize; // Buffer大小
private final int channelSize;// Buffer的个数
private Channels<T> channels; // Channels对象
private IDriver driver; // ConsumeDriver对象
在 DataCarrier 的构造方法中会初始化 Channels 对象,默认使用 SimpleRollingPartitioner 以及 BLOCKING 策略,太简单,不展开了。
DataCarrier.produce() 方法实际上是调用 Channels.save()方法,实现数据写入,太简单,不展开了。
在 DataCarrier.consume()方法中,会初始化 ConsumeDriver 对象并调用 begin() 方法,启动 ConsumeThread 线程:
public DataCarrier consume(Class<? extends IConsumer<T>> consumerClass, int num, long consumeCycle) {
// 初始化 ConsumeDriver
driver = new ConsumeDriver<T>(this.name, this.channels, consumerClass, num, consumeCycle);
// 启动 ConsumerThread线程
driver.begin(channels);
return this;
}
总结

本节主要介绍了 Da taCarrier 这个轻量级的生产者-消费者模式的实现库,也没啥可总结的,后面继续介绍 Skywalking 的 Trace 收集以及发送实现。
扫描下图二维码,关注【程序员吴小胖】
从底部 ”源码分析“菜单 即可获取
《Skywalking源码分析指北》全部文章哟~

看懂看不懂,都点个赞吧:+1:
正文到此结束
- 本文标签: cat HTML final mmm 服务端 并发 源码 压力 程序员 锁 http IO Agent 线程 时间 volatile src Service 缓存 tar 代码 插件 client Atom synchronized IDE 二维码 dataSource queue 构造方法 https 数据 list consumer producer ArrayList ip UI value dubbo 文章 LinkedList 配置 实例 总结 ACE id tomcat
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

