web爬虫系列(一)- 爬取电影天堂迅雷地址
一、爬虫介绍
目前爬虫框架层出不穷,当然很多公司也会根据自己的业务做二次开发,Java的有WebMagic和WebCollector等,Python的有PySpider和Scrapy等。不能说孰好孰坏,只能说根据自己的业务场景选择不同框架,Python作为爬虫的开发语言已经火的一塌糊涂,但是我为什么选择Java语言呢?因为我不会Python,也不想劳神费力再学一门语言,那就从Java的WebMagic玩起吧。
爬虫的应用场景也各色各异,比如有好玩的同学喜欢爬取网易云音乐的热门评论、还有人爬各种招聘网站的在招职位。商业用途也有很多,比如竞品分析、全球POI更新等等。
二、 入门示例–爬去电影天堂的下载
1、简单分析页面
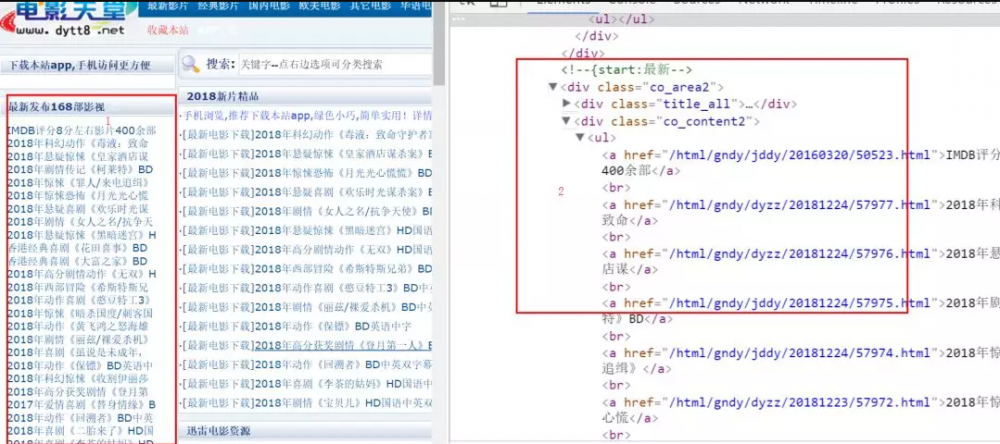
红色1是我们要的内容,红色2是对应的html结构。
2、maven导入如下jar包
<dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-core</artifactId> <version>0.7.3</version> </dependency> <dependency> <groupId>us.codecraft</groupId> <artifactId>webmagic-extension</artifactId> <version>0.7.3</version> </dependency> 复制代码
3、解析dom,获取到电影名称及其对应的详情页链接
package com.daervin.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import java.util.List;
public class FilmProcessor implements PageProcessor {
public static final String URL = "http://www.dytt8.net";
@Override
public void process(Page page) {
Html html = page.getHtml();
//解析列表页
List<Selectable> contentNodes = html.xpath("//div[@class='co_content2']/ul/a").nodes();
for (int i = 1; i < contentNodes.size(); i++) {
//第一条过滤,从第二条开始遍历
Selectable linkNode = contentNodes.get(i);
if (linkNode == null) {
continue;
}
String linkTmp = linkNode.links().get();
if (linkTmp != null && linkTmp.length() > 0) {
//将找到的链接放到addTargetRequest里面,会自动发起请求
page.addTargetRequest(linkTmp);
//输出到控制台
System.out.println(linkTmp);
}
}
}
@Override
public Site getSite() {
return Site.me().setTimeOut(10000);
}
}
复制代码
4、执行爬虫并打印结果
package com.daervin.demo;
import us.codecraft.webmagic.Spider;
public class FilmTest {
public static void main(String[] args) {
Spider.create(new FilmProcessor()).addUrl(FilmProcessor.URL).run();
}
}
复制代码
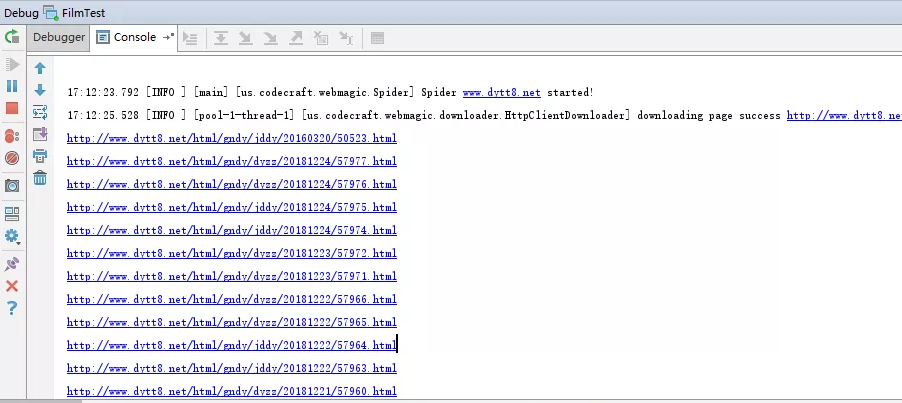
只是拿到了列表对应的详情页地址,没达到获取下载地址的目的!继续...
5、分析详情页 - 深入爬取详情页
获取到电影名称和迅雷下载地址
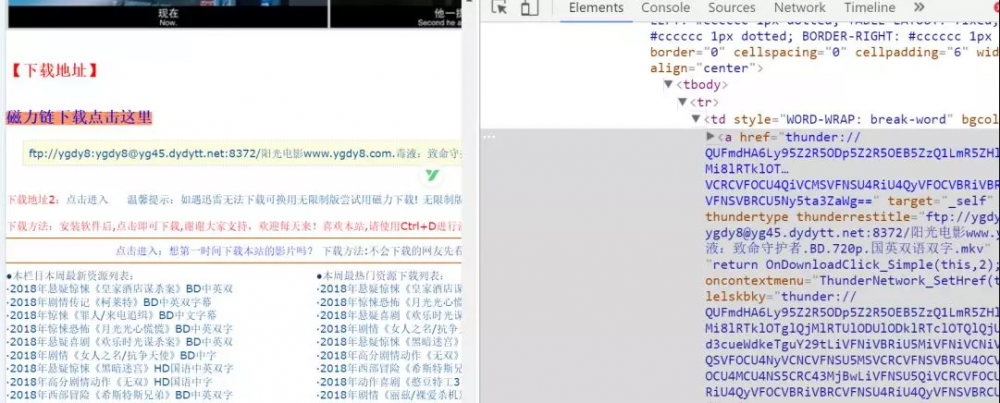
package com.daervin.demo;
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.processor.PageProcessor;
import us.codecraft.webmagic.selector.Html;
import us.codecraft.webmagic.selector.Selectable;
import java.util.List;
public class FilmProcessor implements PageProcessor {
public static final String URL = "http://www.dytt8.net";
@Override
public void process(Page page) {
Html html = page.getHtml();
//解析列表页
if (URL.equals(page.getUrl().toString())) {
//抽取结果
List<Selectable> contentNodes = html.xpath("//div[@class='co_content2']/ul/a").nodes();
for (int i = 1; i < contentNodes.size(); i++) {
//第一条过滤,从第二条开始遍历
Selectable linkNode = contentNodes.get(i);
if (linkNode == null) {
continue;
}
String linkTmp = linkNode.links().get();
if (linkTmp != null && linkTmp.length() > 0) {
//将找到的链接放到addTargetRequest里面,会自动发起请求
page.addTargetRequest(linkTmp);
//输出到控制台
System.out.println(linkTmp);
}
}
} else {//解析电影详情页面
//获取html
Selectable movieNameS = html.xpath("//title/text()");
Selectable movieDownloadS = html.xpath("//a[starts-with(@href,'ftp')]/text()");
System.out.println("movieName:" + movieNameS.get());
System.out.println("downloadURL:" + movieDownloadS.get());
System.out.println("-----------------------------------");
}
}
@Override
public Site getSite() {
return Site.me().setTimeOut(10000);
}
}
复制代码

三、 乱弹琴
菜鸟一只,欢迎交流。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

