编译与反编译,让字节码说人话
提起编译,就不得不提起我们的计算机语言啦。计算机语言指用于人与计算机之间通讯的语言,是人与计算机之间传递信息的媒介。它包括以下三种类型 :
机器语言 :
机器语言是以二进制代码表示的,计算机能够直接识别和执行的一种机器指令的集合,具有灵活、直接执行和速度快的特点。
然而,不同型号计算机的机器语言是不相通的,这也就导致了按着一种计算机的机器指令编制的程序,无法在另一种计算机上运行。
汇编语言 :
汇编语言是机器语言的初步抽象,它采用助记符来代替和表示一些特定低级机器语言的操作。其中,助记符是一种便于人们记忆,并能描述指令功能和指令操作数的符号,一般由表明该种指令功能的英语单词或其缩写构成,如ADD表示加法,MOV表示传送,SUB表示减法等。
汇编语言只是让使用者,即程序员们更易记住和使用,并不被计算机所认识。所以,想要让计算机执行汇编代码,需要首先将汇编程序转换成对应的机器语言代码。这一过程被称为汇编过程。
高级语言 :
机器语言与汇编语言,两者是几乎很少或完全没有做任何语法抽象的,它们更接近硬件,且不可在不同的硬件中移植,我们通常称其为低级语言。而与之相对的,那些进行了高度封装了的编程语言,则被称为是高级语言。
高级语言是以人类的日常语言为基础的一种编程语言,使用一般人易于接受的文字来表示(如汉字、不规则英文,或其他外语),从而使程序的编写更加容易,亦具有较高的可读性。
那么,如何将程序员写出来的高级语言转换成计算机认识的低级语言,然后让计算机去执行它们呢?这个转换的过程,就是我们的编译啦!
编译是如何进行的?
以 Java 语言为例,Java 作为一种高级语言,想要被执行,就需要通过编译的手段将其转换为机器语言。而这个转换,一共要经过两个步骤 :
- 由前端编译器,将 Java 文件编译成中间代码,即 .class 文件,也称字节码文件
- 由后端编译器,将字节码文件编译成机器语言
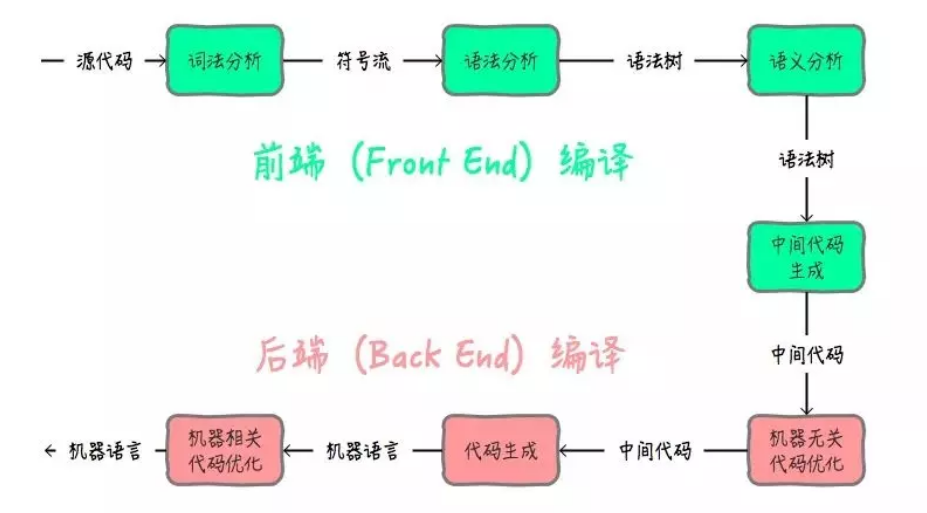
其中,前端编译器主要是 javac 等,后端编译器主要是由各大虚拟机实现的,如 HotSpot 中的 JIT 编译器。
反编译
什么是反编译?
既然通过编译器将高级语言转换为低级语言的过程称为编译,那么通过低级语言进行反向工程,获取源代码的过程自然就叫做反编译啦。
虽然将机器语言直接反编译为源代码是一个十分困难的过程,但是,如果将目标瞄准中间代码,这个过程就显得简单许多了。就像我们虽然不能把经过虚拟机编译后的机器语言进行反编译,但是将 javac 得到的 .class 文件进行反编译还是可行的。
而这个将字节码文件转换成 Java 文件的过程,就是我们常说的 Java 的反编译。
如何让字节码说人话?
哼哼,反编译工具来一把,.class从此讲Java。比如说我们有这样一个简单的 Demo :
package demo;
public class Demo {
public static void main(String[] args) {
Integer a = 1;
System.out.println(a);
}
}
复制代码
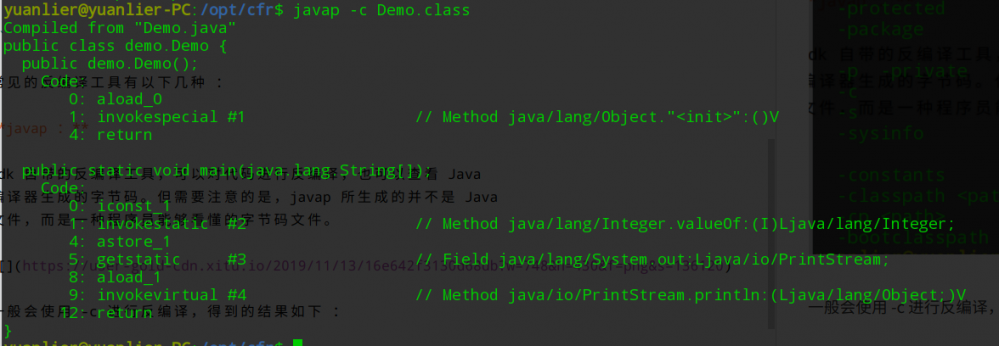
用 javac 对它进行编译,得到对应的字节码文件之后,就轮到我们常用的反编译工具登场了 :
javap :
jdk 自带的反编译工具,可以对代码进行反编译,也可以查看 Java 编译器生成的字节码。但需要注意的是,javap 所生成的并不是 .java 文件,而是一种程序员能够看懂的字节码文件。
一般会使用 -c 进行反编译,得到的结果如下 :
jad :
从 这里 下载对应系统的压缩包,将解压出的 jad 文件加入 jdk 的 bin 目录下,输入 jad 跳出如下帮助文档时,就说明可以用啦。
jad 的优势在于操作方便,且可以直接将 class 文件反编译为 Java 文件,对用户十分友好。比如相比起 javap,通过它进行的反编译就能让我们清晰看出这个从 int 到 Integer 的装箱过程,而这一过程能够帮助我们更好地理解一些编译器的中间操作。
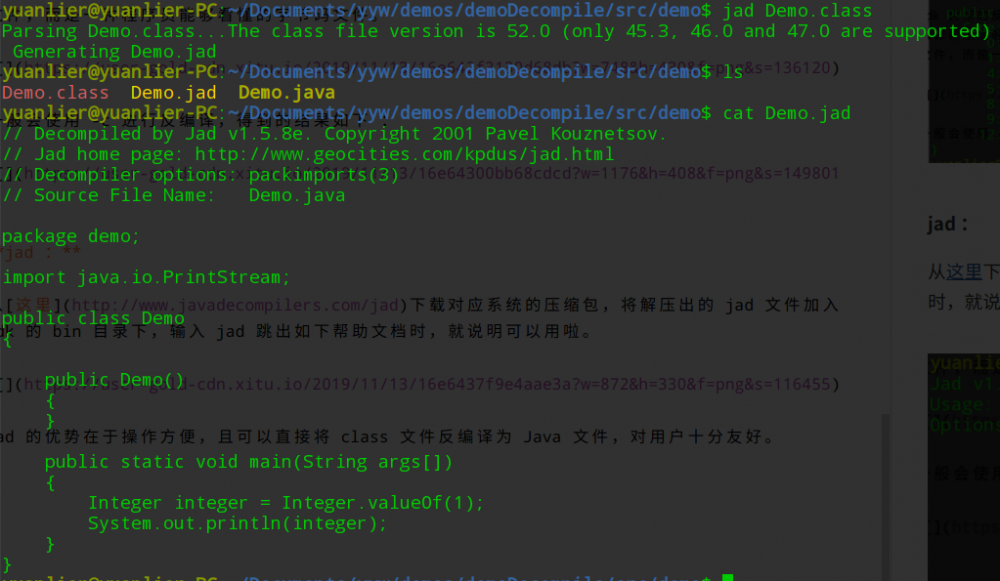
cfr :
jad 虽然好用又方便,但遗憾的是已经很久没有更新了。在对于 Java7 生成的字节码进行反编译时,偶尔会出现不支持的问题,在对 Java8 的 lambda 表达式进行反编译时则彻底失败(指连 .jad 文件都不会生成)。
而作为它的替代方案,cfr 将是一个不错的选择。从 这里 下载对应系统的 jar 包就可以使用啦,反编译时需要将 .class 文件和 jar 包放在同一目录下。
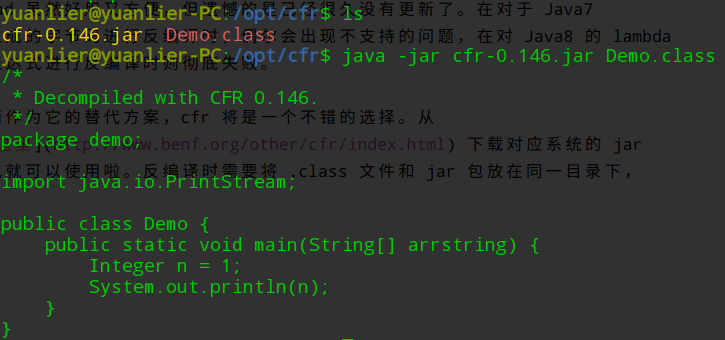
它的优势在于支持包括 lambda 在内的 Java 众多新增语法特性,且依然在保持更新。一般来说使用它进行反编译的时候是需要带参数的,具体的参数信息可以参考帮助文档 :
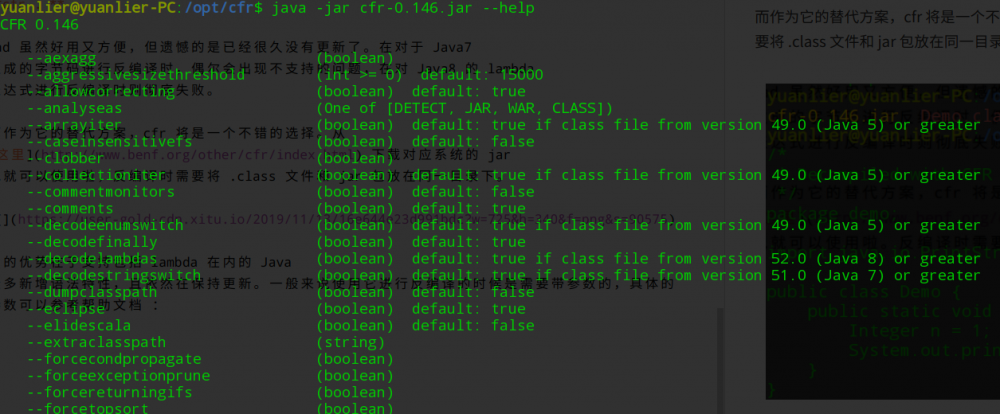
总体来讲功能相当齐全,就是用起来感觉太麻烦了QAQ
idea 下的 cfr 插件 :
idea 下的 cfr 插件,超级好用,强烈安利!
不需要手动编译生成 .class 文件,直接选中 .java 文件,然后右键选择 Show Bytecode outline ,最终反编译出来的效果如下 :
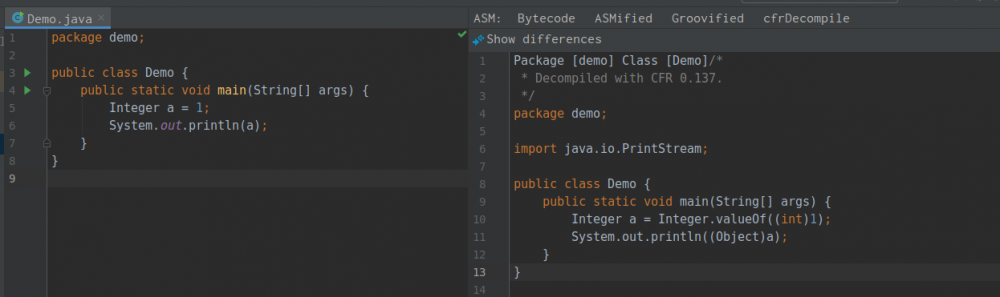
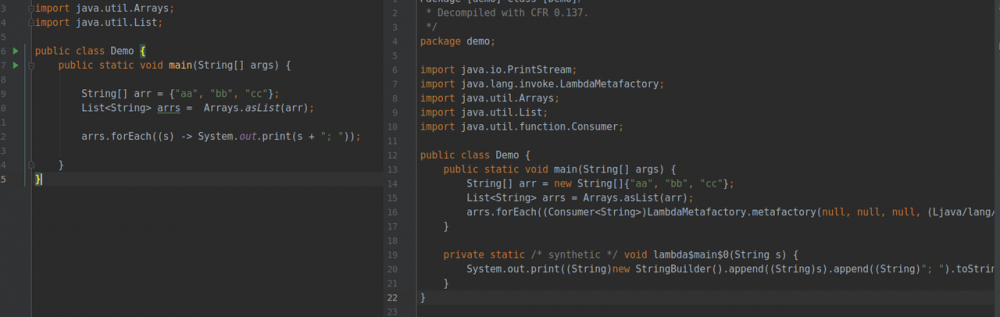
和 cfr 一样,它也是支持 lambda 等语法的,比如这样 :
字节码
什么是字节码?
字节码是一种包含执行程序,由一系列 op 代码 / 数据对 组成的二进制文件,是一种中间码。
如何查看字节码?
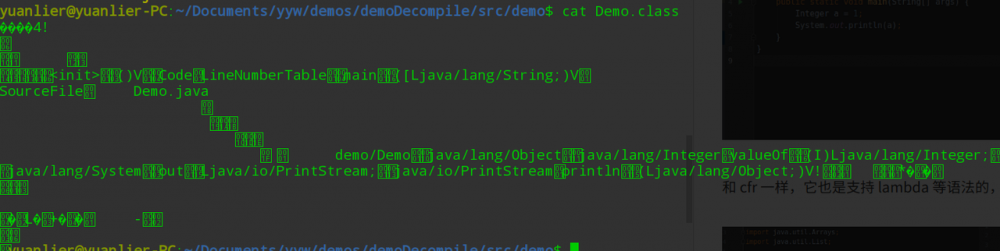
Java 中的字节码文件,即 .class 文件,直接打开是打不开的,强行查看时会出现这样的乱码 :
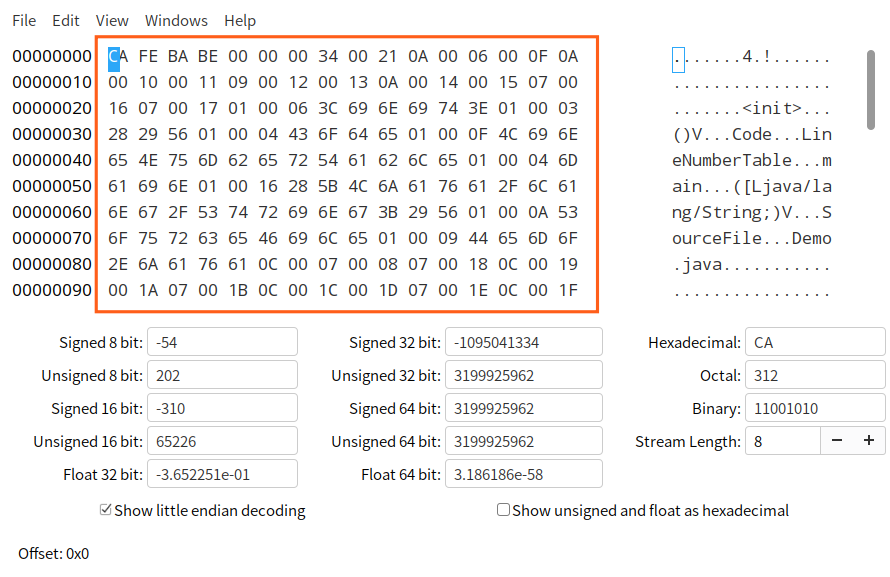
所以我们需要借助一点工具。这里是使用了 GHex,直接将 .class 文件拖入其中就可以打开了 :
如何让人说字节码话?
这就需要从 Class 文件的结构讲起啦。
一个典型的 class 文件分为 魔数、版本号、常量池、访问标志、类索引、父索引、接口索引、字段表、方法表、属性表 这十个部分,用一个数据结构可以表示如下:
| 类型 | 名称 | 干嘛的 |
|---|---|---|
| u4 | magic | 魔数 |
| u2 | minor_version | 次版本号 |
| u2 | major_version | 主版本号 |
| u2 | constant_pool_count | 常量池入口,该值代表常量池容量计数值 |
| cp_info | constaont_pool | 常量池,其中的每一个常量都是一个表 |
| u2 | access_flags | 访问标志 |
| u2 | this_class | 类索引 |
| u2 | super_class | 父索引 |
| u2 | interfaces_count | 接口索引入口,该值代表索引表的容量,下同 |
| u2 | interfaces | 接口索引集合,若该类没有实现接口,则不占用任何字节 |
| u2 | fileds_count | 字段表入口 |
| field_info | fileds | 字段表集合,用于描述接口或者类中声明的变量 |
| u2 | methods_count | 方法表入口 |
| method_info | methods | 方法表集合 |
| u2 | attributes_count | 属性表入口 |
| attribute_info | attributes | 属性表集合 |
用 javap -v 输出详细附加信息看一下反编译出的代码 :

那就试试看如果自己跟着字节码走一遍,能不能得出相同的结果吧!
首先需要了解两个概念 :
- 无符号数属于基本的数据类型,以 u1、u2、u4、u8 来分别代表 1、2、4、8 个字节的无符号数。无符号数可以用来描述数字、索引引用、数量值或者按照 UTF-8 编码构成的字符串值。
- 表是由多个无符号数或者其他表作为数据项构成的符合数据结构,所有表都习惯以 " _info " 结尾。表用于描述有层次关系的复合结构的数据,整个 Class 文件本质上就是一张表。
简言之,如果将诸如 "CA"、"FE" 的部分称为 "一个字节",当我们对着 Class 的文件结构看字节码文件的时候,当看见类型为 ux,就将 x 个字节视为一个整体;当看见类型为 xxx_info,就需要另外去 xxx_info 这张表中查看具体的对应关系。
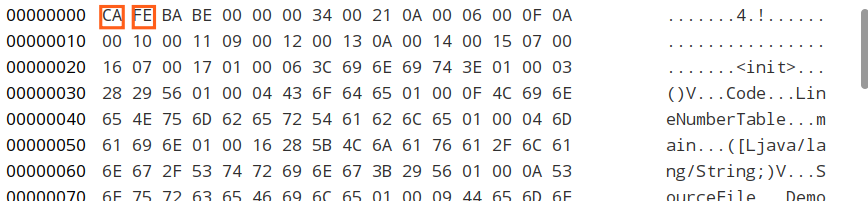
魔数
根据 u4,取最前面四个字节,0X CA FE BA BE。
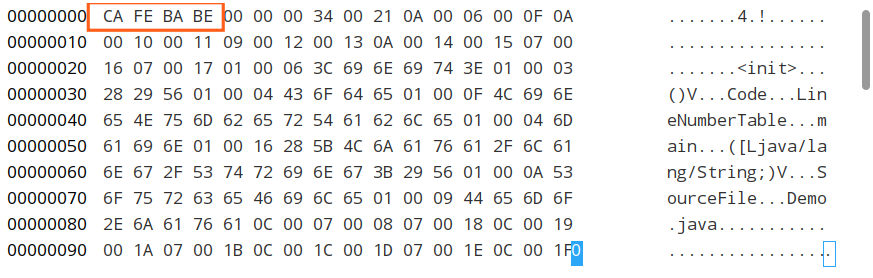
直译过来叫“咖啡宝贝”的这个东西,就是我们所谓的“魔数”啦。它相当于一个文件类型标识,代表这个文件的类型是 class 文件。
版本号
根据 u2,向后取两个字节,0X 00 00,代表次版本号;
根据 u2,向后取两个字节,0X 00 34,代表主版本号。
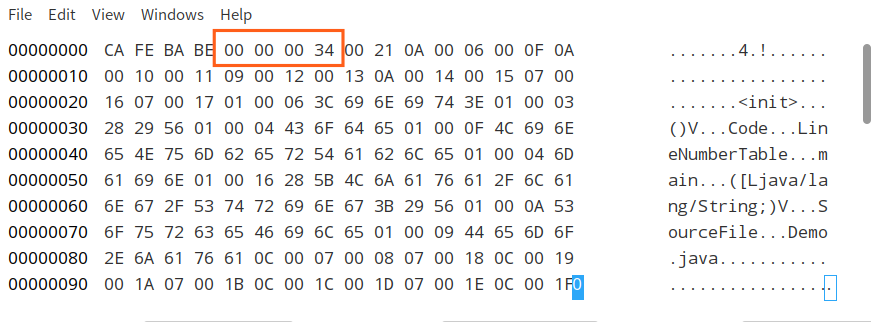
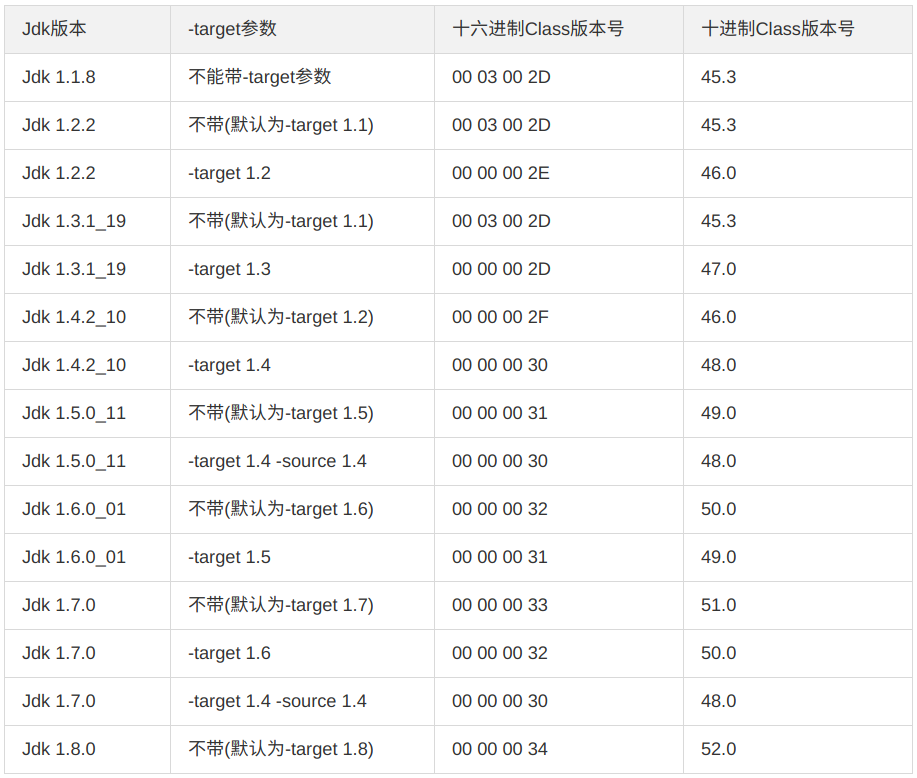
查表可得,这表示当前编译器版本为 JDK1.8.0
常量池
根据 u2,向后取两个字节,0X 00 21,代表常量池容量计数值。
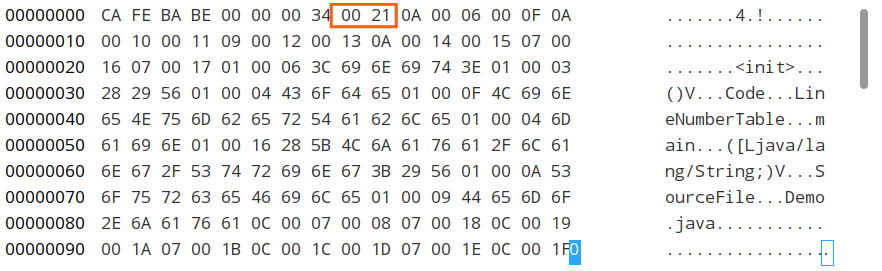
需要注意的是,这个容量计数是从 1 而不是 0 开始的。比如这里的值为 0X21,对应的十进制为 33,那么常量池中的常量总数其实是 33 - 1 = 32 个的。
根据 cp_info,接下来我们需要去查另一张表了!首先看到紧跟其后的第一个字节为 0X 0A,对应十进制为 10,对应表中类型为 CONSTANT_Methodref_info,即 类中方法的符号引用。
TODO 明天把它撸完 该回去了啦现在!
参考文章 :
编译与反编译 : juejin.im/post/5ceb4d…
字节码 : www.jianshu.com/p/252f381a6…
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

