灵魂拷问:Java 的 substring() 是如何工作的?
在逛 programcreek 的时候,我发现了一些小而精悍的主题。比如说:Java 的 substring() 方法是如何工作的?像这类灵魂拷问的主题,非常值得深入地研究一下。

另外,我想要告诉大家的是,研究的过程非常的有趣,就好像在迷宫里探宝一样,起初有些不知所措,但经过一番用心的摸索后,不但会找到宝藏,还会有一种茅塞顿开的感觉,非常棒。
对于绝大多数的初级程序员或者说不重视“内功”的老鸟来说,往往停留在“知其然不知其所以然”的层面上——会用,但要说底层的原理,可就只能挠挠头双手一摊一张问号脸了。
很长一段时间内,我也一直处于这种层面上。但我决定改变了,因为“内功”就好像是在打地基,只有把地基打好了,才能盖起经得住考验的高楼大厦。借此机会,我就和大家一起,对“Java 的 substring() 是如何工作的”进行一次深入地研究。注意了,准备打怪升级了!
1、substring() 是干嘛的
sub是 subtract 的缩写,因此 substring 的字面意思就是“把字符串做个减法”。这样一分析,是不是感觉方法的命名还是蛮有讲究的?
substring() 的完整写法是 substring(int beginIndex, int endIndex)。该方法返回一个新的字符串,介于原有字符串的起始下标 beginIndex 和结尾下标 endIndex-1 之间。
String cmower = "沉默王二,一枚有趣的程序员"; cmower = cmower.substring(0, 4); System.out.println(cmower);
程序输出的结果为:
沉默王二
为什么呢?我来简单解释一下。
Java 的下标都是从 0 开始编号的(我不确定有没有从 1 开始的编程语言),这和我们平常生活中从 1 开始编号的习惯不同。Java 这样做的原因如下:
Java 是基于 C 语言实现的,而 C 语言的下标是从 0 开始的——这听起来好像是一句废话。真正的原因是下标并不是下标,在指针(C)语言中,它实际上是一个偏移量,距离开始位置的一个偏移量。第一个元素在开头,因此它的偏移量就为 0。
此外,还有另外一种说法。早期的计算机资源比较匮乏,0 作为起始下标相比较于 1 作为起始下标,编译的效率更高。
知道了这层原因后,再来看上面这段代码,就会豁然开朗。对于“沉默王二,一枚有趣的程序员”这串字符来说,“沉”的下标为 0,“默”的下标为 1,“王”的下标为 2,“二”的下标为 3,所以 cmower.substring(0, 4) 返回的字符串是“沉默王二”——包括起始下标但不包括结尾下标。
2、substring() 在被调用的时候究竟发生了什么?
在此之前,我们已经了解到:字符串是不可变的,因此当调用 substring() 方法的时候,返回的其实是一个新的字符串。那么变量 cmower 的地址引用就会发生如下图所示的变化。

为了证明上图是完全正确的,我们来看一下 JDK 7 中 substring() 的源码。
public String(char value[], int offset, int count) {
//check boundary
this.value = Arrays.copyOfRange(value, offset, offset + count);
}
public String substring(int beginIndex, int endIndex) {
//check boundary
int subLen = endIndex - beginIndex;
return new String(value, beginIndex, subLen);
}
可以看得出,substring() 通过 new String() 返回了一个新的字符串对象,在创建新的对象时通过 Arrays.copyOfRange() 复制了一个新的字符数组。
但 JDK 6 就有所不同。说到 JDK 6,可能有些读者表示不服,JDK 6?什么年代了,JDK 13 都出来了好不好?但我想告诉大家的是,对比着剖析 JDK 的源码,对学习大有裨益。
不是有那么一句话嘛,要想了解一个成功人士,不能只关注他发迹以后的事,更要关注他之前做了什么。
就请随我来,看看 JDK 6 中的 substring() 的源码吧。
//JDK 6
String(int offset, int count, char value[]) {
this.value = value;
this.offset = offset;
this.count = count;
}
public String substring(int beginIndex, int endIndex) {
//check boundary
return new String(offset + beginIndex, endIndex - beginIndex, value);
}
substring() 方法本身和 JDK 7 并没有很大的差别,都通过 new String() 返回了一个新的字符串对象。但是 String() 这个构造函数有很大的差别,JDK 6 只是简单地更改了一下两个属性(offset 和 count)的值,value 并没有变。
PS:value 是真正存储字符的数组,offset 是数组中第一个元素的下标,count 是数组中字符的个数。
这意味着什么呢?
调用 substring() 的时候虽然创建了新的字符串,但字符串的值仍然指向的是内存中的同一个数组,如下图所示。
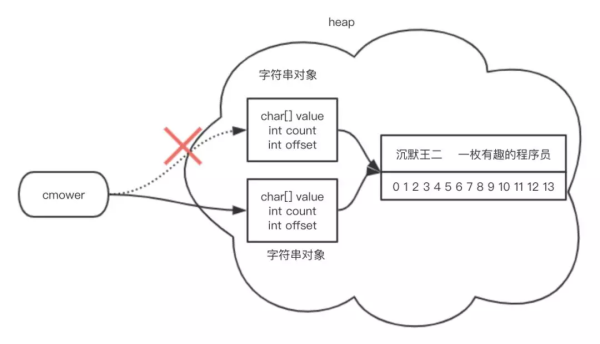
3、为什么 JDK 7 的构造函数发生了变化
看了 JDK 6 和 JDK 7 源码之后,大家可能产生这样一个疑惑:为什么 JDK 7 要做出改变呢?大家共用同一个字符串数组不是挺好的嘛,省得占用新的内存空间。事实上呢?
如果有一个很长很长的字符串,可以绕地球一周,当我们需要调用 substring() 截取其中很小一段字符串时,就有可能导致性能问题。由于这一小段字符串引用了整个很长很长的字符数组,就导致很长很长的这个字符数组无法被回收,内存一直被占用着,就有可能引发内存泄露。
PS:内存泄露是指由于疏忽或错误造成程序未能释放已经不再使用的内存。
那 JDK 7 出现之前,这个隐患怎么应对呢?答案如下。
cmower = cmower.substring(0, 4) + "";
为什么,为什么,为什么,多一个 “+ ""” 就能解决内存泄漏的问题?有些读者可能不太相信,我来带大家分析一下。
首先呢,我们通过 JAD 对字节码反编译一下,上面这行代码就变成了如下内容。
cmower = (new StringBuilder(String.valueOf(cmower.substring(0, 4)))).toString();
“+”号操作符就相当于一个语法糖,加上空的字符串后,会被 JDK 转化为 StringBuilder 对象,该对象在处理字符串的时候会生成新的字符数组,所以 cmower = cmower.substring(0, 4) + ""; 这行代码执行后,cmower 就指向了和 substring() 调用之前不同的字符数组。
PS:如果不明白“+”号操作符的工作原理,请查阅我之前写的文章 《羞,Java 字符串拼接竟然有这么多姿势》 ,这里就不再赘述,免得被老读者捶。
4、最后
总结一下,JDK 7 和 JDK 6 的 substring() 方法本身并没有多大的改变,但 String 类的构造函数有了很大的区别,JDK 7 会重新复制一份字符数组,而 JDK 6 不会,因此 JDK 6 在执行比较长的字符串 substring() 时可能会引发内存泄露的问题。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

