protobuf那些事(一)
protobuf是什么
protobuf是Google创建的,是一种语言无关、平台无关、可扩展的序列化结构化数据的方法,可用于通信协议、数据存储等。
在序列化结构化数据的机制中,是灵活、高效、自动化的。相比于XML,更小、更快、更简单。
为什么不直接用XML
在序列化方面,protobuf具有以下优势:
- 更简单
- 数据体积小3-10倍
- 反序列化速度快20-100倍
- 生成更容易以编程方式使用的数据访问类
举个例子:咱们为一个具有 name 和 emai 的 person 建模。
在XML中,我们是这样写的:
<person>
<name>John Doe</name>
<email>jdoe@example.com</email>
</person>
在protocol buffers中,我们是这样写的:
# Textual representation of a protocol buffer.
# This is *not* the binary format used on the wire.
person {
name: "John Doe"
email: "jdoe@example.com"
}
从性能上看,protocol buffers经过编码后,用二进制的方式传输,只要可能有28个字节长,且需要大约100-200纳秒来解析。即便删除空白,那么XML至少是69字节长,解析大约需要5000-10000纳秒。
在编码方面,protocol buffers也是更简洁的。
protocol buffers读取是这样的:
cout << "Name: " << person.name() << endl; cout << "E-mail: " << person.email() << endl;
XML读取是这样的:
cout << "Name: "
<< person.getElementsByTagName("name")->item(0)->innerText()
<< endl;
cout << "E-mail: "
<< person.getElementsByTagName("email")->item(0)->innerText()
<< endl;
当然,相比于protobuf,XML依然也有自己的优势的,比如基于文本的使用标记(例如 HTML)建模。而且XML对于我们来说,是可读的,可编辑的,它具有自解释性。protobuf是二进制的形式,所以只有.proto定义,我们才可以进行解读。
准备工作
我ide是idea的,安装了两个插件,GenProtobuf是用来生成java文件的,Protobuf Support是用来高亮、语法检查等。
GEnProtobuf设置,打开菜单:
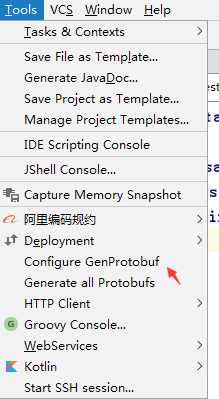
设置protoc.exe的路径,以及生成的文件路径
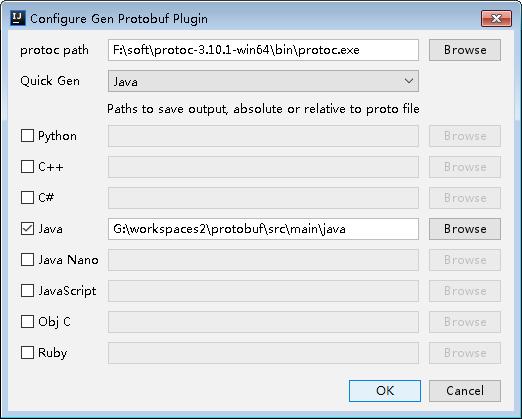
在idea点击.proto文件,右键,选择quick gen protobuf rules,就可以在我们指定的地方生成java文件,如果选择quick gen protobuf here就会在当前目录生成java文件。
pom文件如下:
<dependencies>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.9.1</version>
</dependency>
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java-util</artifactId>
<version>3.9.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.9</version>
<scope>test</scope>
</dependency>
</dependencies>
proto3
官方虽然将继续支持proto2,但鼓励新代码使用Proto3,因为它更容易使用,支持更多的语言。
一个简单的message
Person.proto:
syntax = "proto3";//指定了用的是proto3语法,不写默认proto2语法
package ch0;//定义proto的包名,可以通过package防止命名冲突。
/*
Person包含name和age两个属性
*/
message Person {
string name = 1;
int32 age =2;
}
跟我们java一样,用 // 和 /* ... */ 来注释单行和一段。
文件的第一个非空、非注释行,指定了使用了proto3语法,如果没指定,默认是proto2语法。
message Person{} 指定了这个Message的名称是Person,里面每一行都有三项,字段类型、字段名称、字段编号。
字段类型与各个语言的关系图如下:

第二个是字段名称,名称肯定要唯一,这个没什么好说的。
repeated关键字,重复的意思,类似于数组或List。
第三个是字段编号,每个字段都有一个惟一的编号。在上面例子中,假设name的值是张三,在转换二进制的时候,不会是name:张三这种形式的,而是用字段编号1:张三这种形式。在解析二进制的时候,也是获取1:张三,然后1跟上面Message对应取到name,再转为name,这样二进制字节就会变短了。
这些字段编号,考虑到需求变化导致多个版本字段可能变动,所以尽量不要修改字段编号,不然有可能1.0版本1对应的是name,1.1版本却对应着age,系统就混乱了。由于1到15的字段编号只需要一个字节进行编码,所以用的比较频繁的字段,建议都要这个范围。
字段编号的范围是1到2^29-1(536,870,911),中间19000到19999是作为保留的数字,我们不能够使用的,在编译的时候就会报错。而且,也不能使用之前的保留数字,这个后面会讲字段删除修改时要怎么处理。
通过GenProtobuf生成的java文件,这边没有指定文件夹和类名,具体的文件生成规则后面讲。为了方便,后面我都指定文件夹和类名。
我们可以用生成的java类,调用name和age的set和get方法。
@Test
public void test1(){
PersonOuterClass.Person.Builder person = PersonOuterClass.Person.newBuilder();
person.setAge(18);
person.setName("张三");
person.getAge();
person.getName();
}
多个Message
一个.proto文件中定义多个Message。比如多个有关联的Message,就可以添加到相同的.proto:
syntax = "proto3";
package ch2;
option java_package = "com.example.ch2";
option java_outer_classname = "Animo";
message Cat{
string name = 1;
int32 age =2;
}
message Dog{
string name = 1;
int32 age =2;
}
测试代码
@Test
public void test2(){
Animo.Cat.Builder cat = Animo.Cat.newBuilder();
cat.setAge(1);
cat.setName("kitty");
cat.getName();
cat.getAge();
Animo.Dog.Builder dog = Animo.Dog.newBuilder();
dog.setAge(2);
dog.setName("wangcai");
dog.getName();
dog.getAge();
}
合并后的java类其实是同一个,只是通过不同的Builder来获取。
保留字段
上面有提过,当我们需求变更时,可能有不用的字段,那要怎么处理呢?如果直接删掉或者注释掉,有可能其他版本的应用或其他应用会用到这个字段,那就会导致严重的问题,比如数据损坏、隐私bug等。因此,我们就好保留这些不用的字段名称和字段编号。
编译器会提示我们错误,比如2通过reserved标记为保留的字段编号,在age使用的时候,就会提示了:

注意,不能在同一个保留语句中混合字段名和字段号。需要分开填写。
枚举
syntax = "proto3";
package ch4;
option java_package = "com.example.ch4";
option java_outer_classname = "MyEnum";
message Goods {
string name = 1;
enum Colors {
red = 0;
green = 1;
blue = 2;
}
Goods.Colors color = 2;
Sizes size = 3;
}
enum Sizes {
option allow_alias = true;
X = 0;
XL = 1;
XXL = 1;
}
用枚举的时候,为了与proto2兼容,必须有一个0值,且0值必须是第一个元素。
在上面的例子中,定义了两个枚举,一个是在Message中,一个是Message外,如果在其他Message中,需要用Message的名称加枚举获取,我这里演示的是自己用自己的,所以可以把Goods.去掉也是可以的。枚举的常数,必须在32位整数范围内,不推荐使用负值。
可以看到,Sizes有两个值都是1,这个时候,需要设置allow_alias为true。我们看看测试代码和运行结果:
@Test
public void test4() {
MyEnum.Goods.Builder goods = MyEnum.Goods.newBuilder();
goods.setColorValue(1);
goods.setSizeValue(1);
System.out.println(goods.getColor());
System.out.println(goods.getColorValue());
System.out.println(goods.getSize());
System.out.println(goods.getSizeValue());
}

在反序列化期间,无法识别的enum值将保留在Message中,不同的语言有不同的处理。比如C和Go,未识别的enum值只是作为其基础整数表示形式存储。在Java中,未识别的enum值会标识无法识别的值。在任何一种情况下,如果消息被序列化,未被识别的值仍将与消息一起序列化。
枚举的保留值写法跟保留字段一样。
默认值
proto文件:
syntax = "proto3";
package ch5;
option java_package = "com.example.ch5";
option java_outer_classname = "MyDefault";
message DefaultValue {
string name = 1;
int32 age = 2;
bytes bt = 3;
bool bl = 4;
Sizes size = 5;
}
enum Sizes {
X = 0;
XL = 1;
}
测试代码:
@Test
public void test5() {
MyDefault.DefaultValue.Builder builder = MyDefault.DefaultValue.newBuilder();
System.out.println(builder.getName());
System.out.println(builder.getAge());
System.out.println(builder.getBt());
System.out.println(builder.getBl());
System.out.println(builder.getSize());
}
运行结果:

strings:空的字符串
bytes:长度为0的ByteString
bools:false
numeric:0
enums:默认第一个
使用其他Message
用其他的Message类型作为字段类型,就好像java的PO中引入了其他的PO。
syntax = "proto3";
package ch6;
option java_package = "com.example.ch6";
option java_outer_classname = "MyOtherMsg";
message MyMsg {
MyOther myOther = 1;
}
message MyOther {
string name = 1;
}
测试代码:
@Test
public void test6() {
MyOtherMsg.MyMsg.Builder builder = MyOtherMsg.MyMsg.newBuilder();
MyOtherMsg.MyOther.Builder myOther =MyOtherMsg.MyOther.newBuilder();
myOther.setName("张三");
builder.setMyOther(myOther);
MyOtherMsg.MyOther myOther2 = builder.getMyOther();
System.out.println(myOther2.getName());
}
运行结果:

导入其他文件
上面的例子中,如果MyMsg和MyOther不在一个文件中呢,那就需要用import引入。
MyMsg.proto
syntax = "proto3";
package ch7;
option java_package = "com.example.ch7";
option java_outer_classname = "MyMsg2";
import "MyOther.proto";
message MyMsg {
MyOther myOther = 1;
}
MyOther.proto
syntax = "proto3";
package ch7;
option java_package = "com.example.ch7";
option java_outer_classname = "MyOther2";
message MyOther {
string name = 1;
}
测试代码:
@Test
public void test7() {
MyMsg2.MyMsg.Builder builder = MyMsg2.MyMsg.newBuilder();
MyOther2.MyOther.Builder myOther =MyOther2.MyOther.newBuilder();
myOther.setName("张三");
builder.setMyOther(myOther);
MyOther2.MyOther myOther2 = builder.getMyOther();
System.out.println(myOther2.getName());
}
运行结果如下:

嵌套类型
也就是说在Message中定义了Message类型,比如下面在Nest中定义了Inner:
syntax = "proto3";
package ch8;
option java_package = "com.example.ch8";
option java_outer_classname = "NestType";
message Nest {
message Inner{
string name = 1;
}
Inner inner = 1;
}
测试代码,有点像内部类
@Test
public void test8() {
NestType.Nest.Builder builder = NestType.Nest.newBuilder();
NestType.Nest.Inner.Builder inner = NestType.Nest.Inner.newBuilder();
inner.setName("张三");
builder.setInner(inner);
NestType.Nest.Inner inner2 = builder.getInner();
System.out.println(inner2.getName());
}
运行结果:

更新Message
更新message,主要是不能更改任何现有字段的字段编号,以及字段类型的兼容。
比如int32、uint32、int64、uint64、bool兼容,sint32和sint64兼容,string和bytes(如果bytes是合法的UTF-8)兼容,fixed32与sfixed32兼容,fixed64与sfixed64兼容,enum和int32、uint32、int64、uint64兼容(值不适合会被截断)。
未知字段
未知字段是protobuf序列化数据,表示解析器无法识别的字段。例如,当旧的二进制代码解析带有新字段的新二进制代码发送的数据时,这些新字段将成为旧二进制代码中的未知字段。比如我们Message加了一个新的字段name,那这个name就是未知字段。
Any
Any字段直接用其他Message类型,类似于泛型,需要导入 google/protobuf/any.proto。
syntax = "proto3";
package ch9;
option java_package = "com.example.ch9";
option java_outer_classname = "MyAny";
import "google/protobuf/any.proto";
message Any {
string name = 1;
google.protobuf.Any any = 2;
}
测试代码,这个Person是第一个例子的。
@Test
public void test9() throws InvalidProtocolBufferException {
PersonOuterClass.Person.Builder person = PersonOuterClass.Person.newBuilder();
person.setAge(18);
person.setName("张三");
MyAny.Any.Builder builder = MyAny.Any.newBuilder();
builder.setAny(Any.pack(person.build()));
builder.setName("李四");
PersonOuterClass.Person person2 = builder.getAny().unpack(PersonOuterClass.Person.class);
System.out.println(person2.getName()+"-"+person2.getAge());
System.out.println(builder.getName());
}
运行结果如下:

Oneof
map
需要键值对可以用map,其中key_type可以是init或string 类型(排除floate和byte)。key_type不能是枚举。
syntax = "proto3";
package ch11;
option java_package = "com.example.ch11";
option java_outer_classname = "MyMap";
message Map {
map<string, string> filedMap = 1;
}
测试代码:
@Test
public void test11() throws InvalidProtocolBufferException {
MyMap.Map.Builder builder = MyMap.Map.newBuilder();
builder.putFiledMap("name","张三");
builder.putFiledMap("age","18");
System.out.println(builder.getFiledMapMap().get("name"));
System.out.println(builder.getFiledMapMap().get("age"));
}
运行结果

map不能用repeated修饰。
JSON
Proto3支持JSON格式的规范编码。
proto文件就用第一个例子的。
测试代码:
@Test
public void test12() throws InvalidProtocolBufferException {
JsonFormat.Printer printer = JsonFormat.printer();
JsonFormat.Parser parser = JsonFormat.parser();
PersonOuterClass.Person.Builder builder = PersonOuterClass.Person.newBuilder();
builder.setAge(18);
builder.setName("lilei");
String jsonStr = printer.print(builder);
System.out.println(jsonStr);
PersonOuterClass.Person.Builder builder2 = PersonOuterClass.Person.newBuilder();
parser.merge(jsonStr,builder2);
PersonOuterClass.Person person = builder2.build();
System.out.println(person);
}
运行结果:

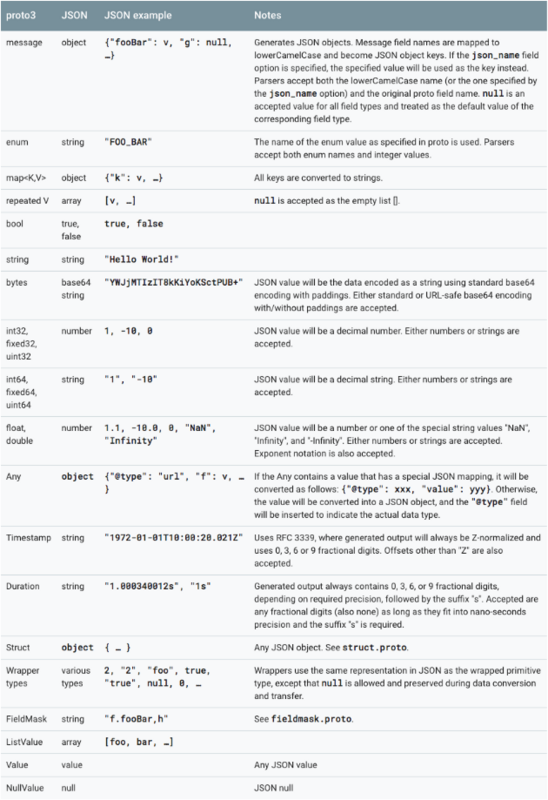
对应关系:
Services定义
如果要在RPC(远程过程调用)系统中使用Message,可以在.proto文件中定义 RPC 服务接口,protocol buffer编译器将根据所选语言生成服务接口代码和 stubs。如果我们定义一个RPC服务,入参是SearchRequest返回值是SearchResponse,就可以这样在.proto文件中定义它:
service SearchService {
rpc Search (SearchRequest) returns (SearchResponse);
}
与protocol buffer一起使用的最直接的RPC系统是gRPC:在谷歌开发的与语言和平台无关的开放源码RPC系统。gRPC在protocol buffer中工作得非常好,还可以允许我们使用特殊的protocol buffer编译插件,直接从.proto文件中生成 RPC 相关的代码。
Options
option用于对文件的声明,google/protobuf/descriptor.proto定义了option的完整列表。
我们看看上面的proto文件,第一个Person.proto,没有用option对文件进行声明,生成的目录结果如下:
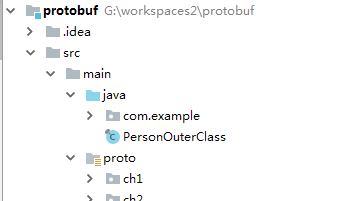
可以看到的是,java文件在根目录下,而且java类名是PersonOuterClass。
我们看看Map那个例子的proto文件,跟Person.proto不同是下面两个option定义:
option java_package = "com.example.ch11"; option java_outer_classname = "MyMap";
生成的目录结果如下:
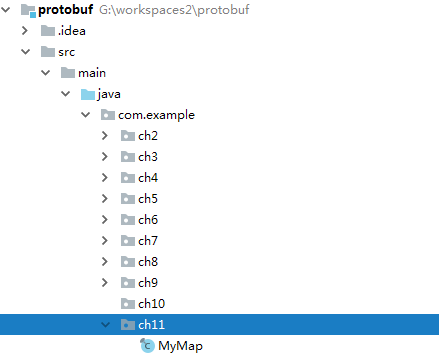
目录是由java_package指定的,类名是由java_outer_classname决定的。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

