面试官:为什么《阿里巴巴Java开发手册》上要禁止使用Executors来创建线程池
扫描下方二维码或者微信搜索公众号 菜鸟飞呀飞 ,即可关注微信公众号,阅读更多 Spring源码分析 和 Java并发编程 文章。

前言
在《阿里巴巴Java开发手册》第一章第6讲 并发处理 中,强制规定了线程池不允许使用Executors去创建。那么为什么呢?这就得从线程池和Executors这个类的本质上说起了。
线程池ThreadPoolExecutor
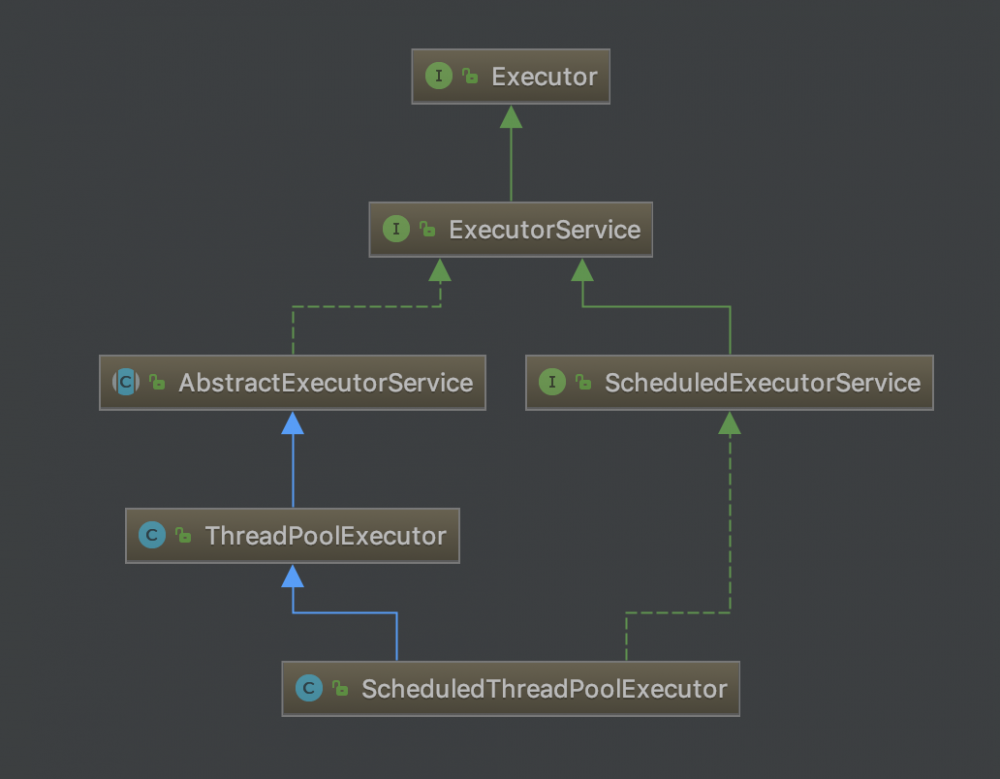
在Java中提供了两种类型的线程池来供开发人员使用,分别是 ThreadPoolExecutor 和 ScheduledThreadPoolExecutor 。其中ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,类的UML图如下所示。ScheduledThreadPoolExecutor的功能和Java中的Timer类似,它提供了定时的去执行任务或者固定时延的去执行任务的功能,其功能比Timer更加强大。(关于线程池的原理及详细的源码分析,可以参考这篇文章: 线程池ThreadPoolExecutor的实现原理 )
线程池有7个非常重要的参数,其描述和功能如下表所示。
| 参数 | 功能 |
|---|---|
| int corePoolSize | 线程池的核心线程数 |
| int maximumPoolSize | 线程池的最大线程数 |
| long keepAliveTime | 空闲线程的最大空闲时间 |
| TimeUnit unit | 空闲时间的单位, TimeUnit 是一个枚举值,它可以是纳秒、微妙、毫秒、秒、分、小时、天 |
| BlockingQueue workQueue | 存放任务的阻塞队列,常用的阻塞队列有ArrayBolckingQueue、LinkedBlockingQueue、SynchronousQueue、PriorityQueue |
| ThreadFactory threadFactory | 创建线程的工厂,通常利用线程工厂创建线程时,赋予线程具有业务含义的名称 |
| RejectedExecutionHandler handler | 拒绝策略。当线程池线程数超过最大线程数时,线程池无法再接收任务了,这个时候需要执行拒绝策略 |
为什么说这7个参数十分重要呢?因为线程池ThreadPoolExecutor的实现原理就是依靠这几个参数来实现的。当主线程提交一个任务到线程池后,线程池的执行流程如下:
-
1.先判断线程池中线程的数量是否小于核心线程数,即:是否小于corePoolSize,如果小于corePoolSize,就创建新的线程去执行任务;否则就进入到下面流程。 -
2.判断任务队列是否已经满了,即:判断workQueue有没有满,如果没有满,就将任务添加到任务队列中;如果已经满了,就进入到下面的流程。 -
3.再判断如果新创建一个线程后,线程数是否会大于最大线程数,即:是否大于maximumPoolSize,如果大于maximumPoolSize,则进入到下面的流程;否则就创建一个新的线程来执行任务。 -
4.执行拒绝策略,即执行handler的rejectedExecution()方法
Executors
由于 ThreadPoolExecutor 类的构造方法的参数太多了,创建起来比较麻烦,而且ThreadPoolExecutor又可以细分为三种类型的线程池,这样创建起来不太方便。这个时候,工厂设计模式就派上用场了,Executors就是这样的一个静态工厂类,它里面提供了静态方法,调用这些静态方法,传入较少的参数或者不传参数,我们就可以很轻松地创建出线程池。Executors其实就是一个工具类,专门用来创建线程池。 上面提到ThreadPoolExecutor有7个非常重要的参数,我们在给这些参数传入特殊的值的时候,创建出来的ThreadPoolExecutor线程池又可以细分为三类: FixedThreadPool (线程数量固定的线程池)、 SingleThreadExecutor (单线程的线程池)、 CachedThreadPool (线程数大小无界的线程池)。( 注意:这里的FixedThreadPool、SingleThreadExecutor、CachedThreadPool不是实际的类名,而是根据线程池的特殊性来取的别名 )。下面来具体看下这三种线程池。
FixedThreadPool
FixedThreadPool是 线程数量固定的线程池 ,即 核心线程数与最大线程数相等 。Executors工厂类提供了如下两个方法去创建FixedThreadPool。
// 指定线程数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
// 指定线程数和线程工厂
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
复制代码
可以发现,在Executors工厂类中,是直接调用了ThreadPoolExecutor的构造方法,而且令核心线程数和最大线程数均等于传入的参数nThreads,当线程数量达到核心线程数后,线程数就不会在变化了,始终维持在核心线程数这个数值,因此这种方法创建出来的线程池称之为线程数量固定的线程池。 同时我们还发现,参数keepAliveTime参数的值被设置为0,这是因为当coolPoolSize等于maximumPoolSize时,线程池中始终是不会存在空闲线程的,而keepAliveTime参数的含义是空闲线程存活的最大时间,都不可能出现空闲线程了,设置keepAliveTime的值大于0也就没有任何意义了,因此这里将其设置为0。 此时任务队列使用的是 LinkedBlockingQueue ,由于LinkedBlockingQueue在初始化时,如果不显示指定大小,就会默认队列的大小为 Integer.MAX_VALUE ,这个数值非常大了,因此通常称它是一个无界队列。 当使用无界队列时,会造成以下问题:
1. 2. 3.
SingleThreadExecutor
SingleThreadExecutor ,线程数为1的线程池,即核心线程数与最大线程数均为1。Executors工厂类提供了如下两个方法去创建SingleThreadExecutor。
// 不需要传递任何参数,在ThreadPoolExecutor的构造方法中,直接令核心线程数和最大线程数为1
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
// 指定一个线程创建工厂即可,然后在ThreadPoolExecutor的构造方法中,令核心线程数和最大线程数为1
public static ExecutorService newSingleThreadExecutor(ThreadFactory threadFactory) {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory));
}
复制代码
从上面代码中,可以发现,在ThreadPoolExecutor的构造方法中,直接令maximunPoolSize和corePoolSize的值均为1,这样线程池中就会一直只存在一个线程,即单线程的线程池。同样,因为不会出现存在空闲线程的情况,因此将keepAliveTime设置为0。任务队列依然使用的是LinekdBlockingQueue,即无界队列。由于使用无界队列,因此仍然可能会造成OOM异常,以及keepAliveTime、maximunPoolSize、handler等参数失效。 对于需要保证任务顺序执行的场景,可以使用SingleThreadExecutor。
CachedThreadPool
CachedThreadPool ,线程数大小无界的线程池。核心线程数等于0,最大线程数等于 Integer.MAX_VALUE ,这个值已经非常大了,因此称之为线程数大小无界的线程池。Executors工厂类提供了如下两个方法去创建CachedThreadPool。
// 不要传任何参数,在ThreadPoolExecutor的构造方法中,令核心线程数为0,最大线程数为Integer.MAX_VALUE
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
// 指定线程创建工厂,然后在ThreadPoolExecutor的构造方法中,令核心线程数为0,最大线程数为Integer.MAX_VALUE
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
复制代码
从上面的代码中可以发现,在ThreadPoolExecutor的构造方法中,令核心线程数为0,最大线程数为 Integer.MAX_VALUE ,由于Integer.MAX_VALUE的值非常大,因此通常也称CachedThreadPool为线程数大小无界的线程池。令keepAliveTime等于60,单位为秒,这说明空闲线程最多存活60秒。 在CachedPoolPool中,使用的阻塞队列不再是LinkedBlockingQueue,而是 SynchronousQueue ,这是一个 不存储元素的阻塞队列 。它的特点是,当前线程向队列中put元素时,必须要等另外一个线程从队列中取出元素后,当前线程才会返回;如果没有线程从队列中取出元素,那么当前线程就会一直阻塞,直到元素被取出。因此称SynchronousQueue是一个不存储元素的队列。(注意:这里说的是put操作会阻塞,而offer操作是不阻塞的) 由于核心线程数为0,所以当有任务提交到线程池时,第一层判断不成立(即当前线程数小于核心线程数判断不成立,此时均为0)。因此会调用阻塞队列的 offer() 方法尝试将任务添加到任务队列中,由于此时的阻塞队列是SynchronousQueue,它不存储元素,因此offer()方法会返回false,这样就表示第二层判断不成立(任务无法添加到队列)。就接着判断当前线程数是否大于最大线程数,显然此时没有,因为最大线程数为Integer.MAX_VALUE,所以此时会创建新的线程去处理任务。这样只要当有新的任务进入到池中时,就会创建新的线程去处理任务,因此称CachedThreadPool是一个线程数无界的线程池。 池中的线程最多空闲60秒,当60秒内没有从阻塞队列中获取到任务后,线程就会被销毁 。当主线程提交任务的速度大于线程池处理任务的速度时,线程池就会一直创建线程,因此最终有可能造成OOM异常。 当任务较多,但任务执行时间较短时,适合使用CacheThreadPool这种线程池来处理任务。
JUC包下还提供了一种很常用的线程池,它就是 ScheduledThreadPoolExecutor 。ScheduledThreadPoolExecutor是ThreadPoolExecutor的子类,它的功能是定期执行任务或者在给定的延时之后执行任务。将线程池的核心参数设置为特殊的值,就会创建出两种类型的ScheduledThreadPoolExecutor。分别是包含多个线程的ScheduledThreadPoolExecutor和只包含一个线程的SingleScheduledThreadExecutor。(注意:SingleScheduledThreadExecutor不是一个类名,而是根据线程池的特性来取的一个名称)。 同样,Executors静态工厂类也为ScheduledThreadPoolExecutor的创建提供了相关的静态方法。下面结合代码示例来分别分析两种类型的ScheduledThreadPoolExecutor。
多个线程的ScheduledThreadPoolExecutor
当ScheduledThreadPoolExecutor的核心线程数指定为多个时(大于1),ScheduledThreadPoolExecutor就是多线程的线程池。Executors工厂类提供了如下两个方法去创建多个线程的ScheduledThreadPoolExecutor。
// 指定核心线程数的数量
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
// 指定核心线程数的数量和线程工厂
public static ScheduledExecutorService newScheduledThreadPool(
int corePoolSize, ThreadFactory threadFactory) {
return new ScheduledThreadPoolExecutor(corePoolSize, threadFactory);
}
复制代码
当传入的参数corePoolSize大于1时,就是多线程的ScheduledThreadPoolExecutor,当传入的数值等于1时,就变成了单线程的SingleThreadScheduledExecutor。下面来看下ScheduledThreadPoolExecutor带有一个参数的构造方法。源码如下:
public ScheduledThreadPoolExecutor(int corePoolSize) {
// 核心线程数为传入的线程数,即1
// 最大线程数为Integer.MAX_VALUE
// 使用的阻塞队列是DelayedWorkQueue,这是一个无界队列
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
复制代码
可以发现,ScheduledThreadPoolExecutor的最大线程数为 Integer.MAX_VALUE ,使用的是 DelayedWorkQueue 队列,这是一个无界队列。由于是无界队列,那么就会是最大线程数maximumPoolSize这个参数无效,所以即使将最大线程数为Integer.MAX_VALUE也没有什么用处。 DelayedWorkQueue又是一个什么队列呢?它是ScheduledThreadPoolExecutor定义的一个静态内部类,它的本质就是一个延时队列,其功能和DelayQueue类似。在DelayQueue中,包含了一个PriorityQueue(具有优先级的队列)类型的属性,而DelayedWorkQueue是 DelayQueue和PriorityQueue的结合体 ,它会将提交到线程池的任务封装成一个 RunnableScheduledFuture 对象,然后将这些对象 按照一定规则排好序 。 RunnableScheduledFuture 是ScheduledThreadPoolExecutor的一个私有内部类,继承了 FutureTask 。它包含三个非常重要的属性:
1. 2. 3.
DelayedWorkQueue会将队列中所有的RunnableScheduledFuture按照每个RunnableScheduledFuture的 time按照从小到大排序 ,时间最小的应该最先被执行,所以排在最前面,当出现多个任务的时间相同时,就按照 sequenceNumber 这个序号从小到大排序,这样线程池中就能定时的执行这些任务了。
ScheduledThreadPoolExecutor执行任务的详细步骤如下:
1. 2. 3. 4.
SingleScheduledThreadExecutor
SingleThreadScheduledExecutor 指的是线程池只有一个线程的ScheduledThreadPoolExecutor,此时核心线程数为1。 Executors工厂类提供了如下两个方法去创建SingleScheduledThreadExecutor。
// 不需要传任何参数,直接指定核心线程数为1
public static ScheduledExecutorService newSingleThreadScheduledExecutor() {
// 将ScheduledThreadPoolExecutor包装成了DelegatedScheduledExecutorService
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1));
}
// 传入线程工厂,然后指定核心线程数为1
public static ScheduledExecutorService newSingleThreadScheduledExecutor(ThreadFactory threadFactory) {
return new DelegatedScheduledExecutorService
(new ScheduledThreadPoolExecutor(1, threadFactory));
}
复制代码
SingleScheduledThreadExecutor执行任务的逻辑和多线程的ScheduledThreadPoolExecutor一样。唯一的区别就是它只有一个线程来执行任务,因此它能保证任务的执行顺序,适用于需要保证任务按照顺序执行的场景。
总结
- 本文详细介绍了线程池的几种类型,普通线程池ThreadPoolExecutor根据设置的核心参数的不同,可以细分为三类线程池:固定线程的线程池(FixedThreadPool)、单线程的线程池(SingleThreadExecutor)、线程数无界的线程池(CachedThreadPool);对于定时任务类型的线程池ScheduledThreadPoolExecutor也可以根据核心参数的不同设置,可以细分为两类:多线程的ScheduledThreadPoolExecutor和单线程的SingleThreadScheduledExecutor,两者唯一的区别就是线程池中的线程数量不一样。
- 同时介绍了静态工厂类Executors的使用,以及如何利用它来创建文中提到的几种线程池。
- 最后,回到本文的开头,为什么《阿里巴巴Java开发手册》上要禁止使用Executors来创建线程池?Executors这个静态工厂类这么好用,创建线程池的时候特别方便,我们不用指定很多参数,就能创建出一个线程池,为什么要禁止呢?答案就是Executors创建出来的线程池使用的全都是无界队列,而使用无界队列会带来很多弊端,最重要的就是,它可以无限保存任务,因此很有可能造成OOM异常。同时在某些类型的线程池里面,使用无界队列还会导致maxinumPoolSize、keepAliveTime、handler等参数失效。因此目前在大厂的开发规范中会强调禁止使用Executors来创建线程池。
- 这个问题的答案其实很简单,关键之处在于掌握线程池的7个重要的核心参数,以及明白线程池的原理以及每一个参数的意义。了解了它们的原理,无论是对于面试,还是平时工作中的使用,以及排查问题都有很大的帮助。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

