多线程编程(3)——synchronized原理以及使用
一、对象头
通常在java中一个对象主要包含三部分:
-
对象头 主要包含GC的状态、、类型、类的模板信息(地址)、synchronization状态等,在后面介绍。
-
实例数据:程序代码中定义的各种类型的字段内容。
-
对齐数据:对象的大小必须是 8 字节的整数倍,此项根据情况而定,若对象头和实例数据大小正好是8的倍数,则不需要对齐数据,否则大小就是8的差数。
先看下面的实例、程序的输出以及解释。
/*需提前引入jar包
<!-- https://mvnrepository.com/artifact/org.openjdk.jol/jol-core 解析java对象布局 -->
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
*/
//Java对象以8个字节对其,不够则使用对其数据
public class Student {
private int id; // 4字节
private boolean sex; // 1字节
public Student(int id, boolean sex){
this.id = id;
this.sex = sex;
}
}
public class Test01 {
public static void main(String[] args) {
Student stu = new Student(6, true);
//计算对象hash,底层是C++实现,不需要java去获取,如果此处不调用,则后面的hash值不会去计算
System.out.println("hashcode: " + stu.hashCode());
System.out.println(ClassLayout.parseInstance(stu).toPrintable());
}
}
/* output
hashcode: 523429237
com.thread.synchronizeDemo.Student object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 75 e5 32 (00000001 01110101 11100101 00110010) (853898497)
4 4 (object header) 1f 00 00 00 (00011111 00000000 00000000 00000000) (31)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 int Student.id 6
16 1 boolean Student.sex true
17 7 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 7 bytes external = 7 bytes total
备注:上述代码在64位的机器上运行,此时
对象头占 (4+4+4)*8 = 96 位(bit)
实例数据 (4+1)*8 = 40 位(bit)
对齐数据 7*8 = 56 位(bit) 因为Java对象以8个字节对其的方式,需补7byte去对齐
*/
下面主要陈述对对象头的解释,内容从hotspot官网摘抄下来的信息:
object header
Common structure at the beginning of every GC-managed heap object. (Every oop points to an object header.) Includes fundamental information about the heap object's layout, type, GC state, synchronization state, and identity hash code. Consists of two words. In arrays it is immediately followed by a length field. Note that both Java objects and VM-internal objects have a common object header format.
mark word
The first word of every object header. Usually a set of bitfields including synchronization state and identity hash code. May also be a pointer (with characteristic low bit encoding) to synchronization related information. During GC, may contain GC state bits.
klass pointer
The second word of every object header. Points to another object (a metaobject) which describes the layout and behavior of the original objec
由此可知,对象头主要包含GC的状态(用4位表示——表示范围0-15,用来记录GC年龄,这也就是为什么对象在survivor中从from区到to区来回转换15次后转入到老年代tenured区)、类型、类的模板信息(地址)、synchronization 状态等,由两个字组成mark word和klass pointer(类元素据信息地址,具体数据通常在堆的方法区中,即8字节,但有时候会有一些优化设置,会开启指针压缩,将代表klass pointer的8字节变成4字节大小, 这也是为什么在上述代码中对象头大小是(8+4)byte,而不是16byte。 )。本节最主要介绍对象头的mark word这部分。关于对象头中每部分bit所代表的意义可以查看hotspot源码中代码的注,这段注释是从openjdk中拷贝的。
JVM和hotspot、openjdk的区别 JVM是一种产品的规范定义,hotspot(Oracle公司)是对该规范实现的产品,还有遵循这些规范的其他产品,比如J9(IBM开发的一个高度模块化的JVM)、Zing VM等。 openjdk是一个hotspot项目的大部分源代码(可以通过编译后变成.exe文件),hotspot小部分代码Oracle并未公布
// openjdk-8-src-b132-03_mar_2014/openjdk/hotspot/src/share/vm/oops/markOop.hpp
/*
Bit-format of an object header (most significant first, big endian layout below):
32 bits:
--------
hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object)
size:32 ------------------------------------------>| (CMS free block)
PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)
64 bits:
--------
unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object)
JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object)
PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object)
size:64 ----------------------------------------------------->| (CMS free block)
*/
可以看到在32位机器和64位机器中,对象的布局的差异还是很大的,本文主要 叙述64位机器下的布局,其实两者无非是位数不同而已,大同小异。在64位机器用64位(8byte)表示Mark Word,首先前25位(0-25)是未被使用,接下来31位表示hash值,然后是对象分代年龄大小,最后Synchronized的锁信息,分为两部分,共3bit,如下表,锁的严格性依次是锁、偏向锁、轻量级锁、重量级锁。 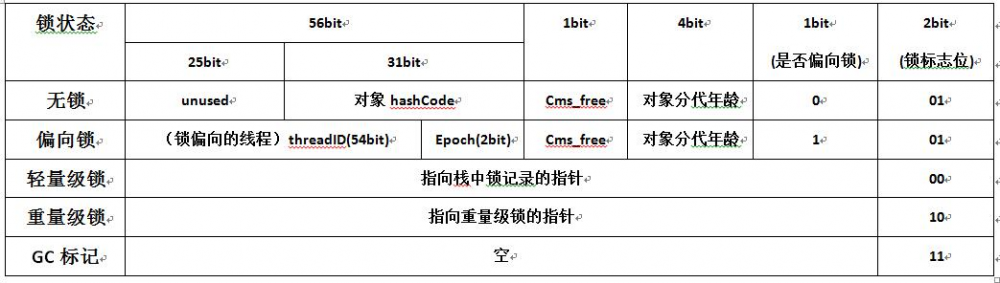
| 锁状态 | 解释 |
|---|---|
| 轻量级锁 | 当锁是偏向锁的时候,被另外的线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,从而提高性能。轻量级锁所适应的场景是线程交替执行同步块的情况,如果存在同一时间访问同一锁的情况,就会导致轻量级锁膨胀为重量级锁。 |
| 重量级锁 | 依赖于操作系统Mutex Lock所实现的锁,JDK中对Synchronized做的种种优化,其核心都是为了减少这种重量级锁的使用。。JDK1.6以后,为了减少获得锁和释放锁所带来的性能消耗,提高性能,引入了“轻量级锁”和“偏向锁”。 |
| GC标记 | 等待GC回收。 |
| 偏向锁 | 引入偏向锁是为了在无多线程竞争的情况下,一段同步代码一直被一个线程所访问因为轻量级锁的获取及释放依赖多次CAS原子指令,而偏向锁只需要在置换ThreadID的时候依赖一次CAS原子指令,当由另外的线程所访问,偏向锁就会升级为轻量级锁, |
| 无锁 | 无锁没有对资源进行锁定,所有的线程都能访问并修改同一个资源,但同时只有一个线程能修改成功。 |
现在开始分析前面程序的对象头的布局信息,在此之前需要知道的是,在windows中对于数据的存储采用的是小端存储,所以要反过来读
大端模式——是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中,这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;这和我们的阅读习惯一致。
小端模式——是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中,这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低。 一般在网络中用的大端;本地用的小端;
运行程序如下,可以看到对应的hashcode值被打印出来:
public static void main(String[] args) {
Student stu = new Student(6, true);
//Integer.toHexString()此方法返回的字符串表示的无符号整数参数所表示的值以十六进制
System.out.println("hashcode: " + Integer.toHexString(stu.hashCode()));
System.out.println(ClassLayout.parseInstance(stu).toPrintable());
}
/*
hashcode: 1f32e575
com.thread.synchronizeDemo.Student object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 75 e5 32 (00000001 01110101 11100101 00110010) (853898497)
4 4 (object header) 1f 00 00 00 (00011111 00000000 00000000 00000000) (31)
8 4 (object header) 43 c1 00 20 (01000011 11000001 00000000 00100000) (536920387)
12 4 int Student.id 6
16 1 boolean Student.sex true
17 7 (loss due to the next object alignment)
Instance size: 24 bytes
Space losses: 0 bytes internal + 7 bytes external = 7 bytes total
*/
二、Monitor
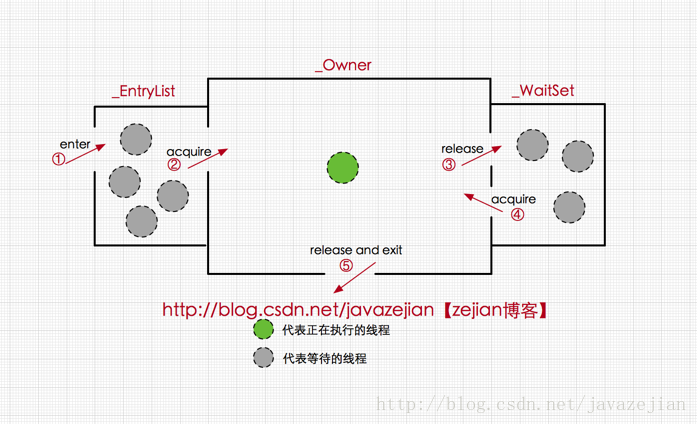
可以把它理解为一个同步工具(数据结构),也可以描述为一种同步机制,通常被描述为一个对象。每个对象都存在着一个 monitor 与之关联,对象与其 monitor 之间的关系有存在多种实现方式,如monitor可以与对象一起创建销毁或当线程试图获取对象锁时自动生成,但当一个 monitor 被某个线程持有后,它便处于锁定状态(每一个线程都有一个可用 monitor record 列表)[ 具体可以看参考资料5]。需要注意的是这种监视器锁是发生在对象的内部锁已经变成重量级锁的时候。
/* openjdk-8-src-b132-03_mar_2014/openjdk/hotspot/src/share/vm/runtime/ObjectMonitor.hpp
// initialize the monitor, exception the semaphore, all other fields
// are simple integers or pointers
ObjectMonitor() {
_header = NULL;
_count = 0; //记录个数
_waiters = 0,
_recursions = 0;
_object = NULL;
_owner = NULL;
_WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet
_WaitSetLock = 0 ;
_Responsible = NULL ;
_succ = NULL ;
_cxq = NULL ;
FreeNext = NULL ;
_EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表
_SpinFreq = 0 ;
_SpinClock = 0 ;
OwnerIsThread = 0 ;
_previous_owner_tid = 0;
}
*/
Monitor的实现主要借助三个结构去完成多线程的并发操作——_owner、_WaitSet 、_EntryList。当多个线程同时访问由synchronized修饰的对象、类或一段同步代码时,首先会进入_EntryList 集合,如果某个线程取得了_owner的所有权,该线程就可以去执行,如果该线程调用了wait()方法,就会放弃_owner的所有权,进入等待状态,等下一次唤醒。如下图(图片摘自参考资料5)。
三、synchronized的用法
synchronized修饰方法和修饰一个代码块类似,只是作用范围不一样,修饰代码块是大括号括起来的范围,而修饰方法范围是整个函数。其中 synchronized(this) 与synchronized(class) 之间的区别 有以下五点要注意:
1、对于静态方法,由于此时对象还未生成,所以只能采用类锁;
2、只要采用类锁,就会拦截所有线程,只能让一个线程访问。
3、对于对象锁(this),如果是同一个实例,就会按顺序访问,但是如果是不同实例,就可以同时访问。
4、如果对象锁跟访问的对象没有关系,那么就会都同时访问。
5、当一个线程访问object的一个synchronized(this)同步代码块时,另一个线程仍然可以访问该object中的非synchronized(this)同步代码块。
当然,Synchronized也可修饰一个静态方法,而静态方法是属于类的而不属于对象的,所以synchronized修饰的静态方法锁定的是这个类的所有对象。关于如下synchronized的用法,我们经常会碰到的案例:
public class Thread5 implements Runnable {
private static int count = 0;
public synchronized static void add() {
count++;
}
@Override
public void run() {
for (int i = 0; i < 1000000; i++) {
synchronized (Thread5.class){
count++;
}
}
}
public static void main(String[] args) throws InterruptedException {
ExecutorService es = Executors.newFixedThreadPool(10);
for (int i = 0; i < 20; i++) {
es.execute(new Thread5());
}
es.shutdown();
es.awaitTermination(6, TimeUnit.SECONDS);
System.out.println(count);
}
}
/* 类锁
20000000
*/
而一旦换成对象锁,不同实例,就可以同时访问。则会出错:
public void run() {
for (int i = 0; i < 1000000; i++) {
synchronized (this){
count++;
}
}
}
/* 对象锁
10746948
*/
这是因为静态变量并不属于某个实例对象,而是属于类所有,所以对某个实例加锁,并不会改变count变量脏读和脏写的情况,还是造成结果不正确。
参考资料
-
目前主流的 Java 虚拟机有哪些?
-
对象布局的各部分介绍—— HotSpot Glossary of Terms
-
不可不说的Java“锁”事
-
Synchronized的一些东西
- 深入理解Java并发之synchronized实现原理
正文到此结束
- 本文标签: IO ssl struct map HTML 操作系统 Word 图片 java ip 产品 注释 参数 http executor Semaphore rmi mina 线程 时间 list core 自动生成 并发 windows Oracle 代码 value entity ORM synchronized IBM description 多线程 实例 src 静态方法 tab tar IDE parse 同步 Service JVM 源码 数据 解析 锁 1111 id 编译 https UI 优化设置 开发 ACE
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

