Spring源码阅读-IOC循环依赖问题(三)
本篇文章主要讲解下spring中的循环依赖,主要说明什么是循环依赖和spring怎么解决循环依赖。 复制代码
什么是循环依赖?
首先我们先明确,循环依赖分为两种: 复制代码
- 构造循环依赖:构造循环依赖是指在创建对象A的过程中需要一个B对象,而B对象的创建过程又需要A对象,这种的循环依赖是没办法解决的。
- set方法的循环依赖:就是A对象中依赖的B对象可以通过set方法进行注入而不是在创建A的过程中需要,同理B也是这样。这种依赖是可以解决的,spring中出现的就是这种循环依赖 接着,我们看看spring中是如何产生循环依赖的,首先先看下面两个对象
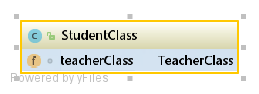
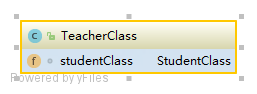
我们看到这两类分别都需要对方的实例,当Spring在创建StudentClass这个类的过程中需要对StudentClass进行属性注入,这时就会调用工厂的getBean()方法去获取TeacherClass实例,此时也会进入TeacherClass的创建过程,在属性注入的时候也需要StudentClass对象的实例,结果就会出现两者相互循环依赖导致程序崩溃。
spring是怎么解决循环依赖的问题的
在spring中是通过三级缓存来解决循环依赖问题,我们先来看下这三级缓存: 复制代码
- 这三个缓存都是map集合,我们可以来看下他在spring中的位置,三个缓存都在DefaultSingletonBeanRegistry这个类中
/** Cache of singleton objects: bean name --> bean instance */ // 一级缓存 private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256); /** Cache of singleton factories: bean name --> ObjectFactory */ // 三级缓存 private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16); /** Cache of early singleton objects: bean name --> bean instance */ // 二级缓存 private final Map<String, Object> earlySingletonObjects = new HashMap<>(16); 复制代码
然后我们看下这三级缓存各自的作用
- 一级缓存:singletonObjects,存放的是已经初始化完成的bean,可以直接使用的bean对象,也就是spring容器。
- 二级缓存:earlySingletonObjects,存储的是需要提早暴露的且未完成初始化的bean实例的引用。
- 三级缓存:singletonFactories,存储的是需要提早暴露的bean的工厂对象ObjectFactory,如果我们需要获取真正的bean实例引用,需要通过调用工厂的getObject方法去获取。 在这里,我们注意到三级缓存为什么不是直接存放bean引用呢。因为BeanPostProcessor有可能需要对这个bean进行一些初始化操作,比如有的代理对象就是在这里产生后添加到容器中。
知道了什么是三级缓存之后,我们来看下spring是怎么通过这三个缓存解决循环依赖问题的。 要知道spring怎么通过这三级缓存解决循环依赖问题,我们就需要明确这三级缓存在什么时候被添加,在什么时候被删除。我们从后面往前讲,也就是先说下三级缓存是在什么时候添加和删除的。
- 三级缓存的添加时机:完成bean创建bean的第一个步骤,创建bean实例对象之后,下面看下具体的代码,这段代码在AbstractAutowireCapableBeanFactory的doCreateBean中
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
//判断是否需要提起暴露bean实例
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// 如果需要提前暴露单例Bean,则将该Bean放入三级缓存中
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 把创建的bean实例放入三级缓存singleFactories中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
复制代码
从这里我们就可以清晰的看到,在bean实例化之后如果需要提前暴露就会被放在三级缓存中。
- 三级缓存的删除时机:在第一次调用三级缓存的get方法之后,就会把三级缓存中缓存的内容删除,并添加到二级缓存中。下面看下具体的代码,下面这段代码在DefaultSingletonBeanRegistry的getSingleton的方法中
// 从一级缓存中获取单例对象
Object singletonObject = this.singletonObjects.get(beanName);
// isSingletonCurrentlyInCreation :
//当A对象依赖B对象,然后再等待属性注入时,这是A对象就是再创建中isSingletonCurrentlyInCreation,方法就是true
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
// 从二级缓存中获取提前暴露的单例bean
singletonObject = this.earlySingletonObjects.get(beanName);
// allowEarlyReference
if (singletonObject == null && allowEarlyReference) {
// 在三级缓存中获取单例bean
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
// 通过工厂获取单例bean
singletonObject = singletonFactory.getObject();
// 把bean实例从三级缓存移动到了二级缓存
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
复制代码
-
这段代码我们就清楚的spring首先是从一级缓存中获取bean实例对象,然后逐层获取,当从三级缓存中获取到bean对象之后,就会删除三级缓存,并且添加到二级缓存中。 因此,二级缓存的创建时机也是在这段代码中。
-
最后,我们看下bean实例什么时候从二级缓存中删除并且添加到一级缓存中。我们来看下DefaultSingletonBeanRegistry的getSingleton方法的最后
if (newSingleton) {
addSingleton(beanName, singletonObject);
}
复制代码
这里就是把单例bean添加到一级缓存中,我们跟进去看下
synchronized (this.singletonObjects) {
//添加 一级缓存
this.singletonObjects.put(beanName, singletonObject);
// 删除三级缓存
this.singletonFactories.remove(beanName);
// 删除
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
复制代码
从这里我们就很清楚了,在把初始化完成的bean添加到容器之后就会把二级和三级缓存中的内容全部删除,所以spring中的bean只会存在在一种缓存里面,同时在最后都会被添加到容器里面删除其他缓存中的内容。
结语
至此,我们就把spring中的循环依赖问题讲清楚了,也清楚的知道了spring里面还有二级和三级缓存是用来解决循环依赖的问题。接下去我们会开始讲springAOP相关的源码阅读,希望大家继续关注,一起成长。 复制代码
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

