怎样写好业务代码——那些年领域建模教会我的东西
本文主要作为笔者阅读 Eric Evans的《Domain-Driven Design领域驱动设计》 一书,同时拜读了我司大神针对业务代码封装的一套业务框架后,对于如何编写复杂业务代码的一点粗浅理解和思考。
ps,如有错误及疏漏,欢迎探讨,知道自己错了才好成长么,我是这么认为的,哈哈~
背景介绍
忘记在哪里看到的句子了,有 “看花是花,看花不是花,看花还是花” 三种境界。这三个句子恰好代表了我从初入公司到现在,对于公司代码的看法的三重心路历程。
学习动机
“看花是花”
得益于我司十几年前一帮大神数据库表模型设计的优异,一开始刚进公司的时候,很是惊叹。通过客户端配配属性,一个查询页面和一个资源实体的属性控件页面就生成好了。
框架本身负责管理页面属性和查询页面的显示内容,以及右键菜单与 js 函数的绑定关系,同时当其他页面需要调用查询及属性页面时,将页面的实现和调用者页面做了隔离,仅通过预留的简单的调用模式及参数进行调用。这样复杂功能的实现则不受框架限制与影响,留给业务开发人员自己去实现,客观上满足了日常的开发需求。
我司将繁杂而同质化的查询及属性页面开发简化,确实客观上减轻了业务开发人员的工作压力,使其留出了更多精力进行业务代码的研究及开发工作。
这套开发机制的发现,对我来说收获是巨大的,具体的实现思路,与本文无关,这里就不作过多赘述了。
这种新奇感和惊叹感,就是刚开始说的 “看花是花” 的境界吧。
“看花不是花”
那么 “看花不是花” 又该从何说起呢?前面说了,框架完美的简化了大量重复基础页面的开发工作,同时,框架本身又十分的克制,并不干涉业务代码的开发工作。
但是从客观上而言,业务代码本身由于包含了业务领域的知识,复杂可以说是先天的属性。随着自己工作所负责业务的深入,接触更多的业务必然也不再是框架所能涵盖的资源查询与属性编辑页面。
同时考虑到业务编写人员本身相对于框架人员技术上的弱势,以及业务领域本身具有的复杂性的提升,我一开始所面对的,就是各种的长达几百行的函数,随处可见的判断语句,参差不齐的错误提示流程,混乱的数据库访问语句。在这个阶段,对业务代码开始感到失望,这也就是之后的 “看花不是花” 的境界吧
“看花还是花”
有一天,我突然发现面对纷繁而又杂乱的业务代码,总还有一个模块 “濯清涟而不妖”,其中规范了常用的常量对象,封装了前后端交互机制,约定了异常处理流程,统一了数据库访问方式,更重要的是,思考并实现了一套代码层面的业务模型,并最终实现了业务代码基本上都是几十行内解决战斗,常年没有 bug,即便有,也是改动三两行内就基本解决的神一般效果 (有所夸张,酌情理解:P) 。
这是一个宝库。原来业务代码也可以这么简洁而优雅。
唯一麻烦的就是该模块的业务复杂,相应的代码层面的业务模型的类层次结构也复杂,一开始看不太懂,直到我看了 Eric Evans的《Domain-Driven Design领域驱动设计》 才逐渐有所理解。
因为此内部业务框架做的事情很多,篇幅有限,这里仅对最具借鉴意义的领域建模思考作介绍。
业务场景
我主要负责传输网资源管理中的传输模块管理。这个部分涉及相对来说比较复杂的关联关系,所以如果代码组织不够严谨的话,极易绕晕和出错,下面以一张简单的概念图来描述一下部分实体对象间的关联关系。
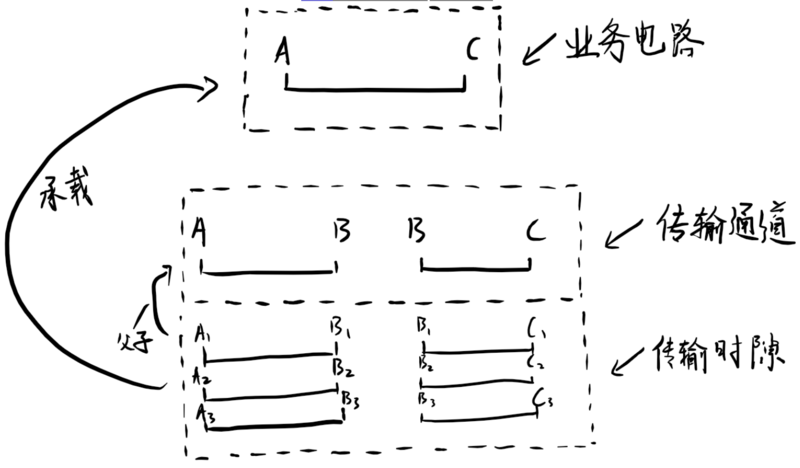
如图,简单来说时隙和通道是一对多的父子关系,同时业务电路和多段通道间的下级时隙,存在更复杂的一对多承载关系。
所以这个关系中复杂的地方在哪里呢?理解上经常会绕混,电路创建要选多段通道时隙,通道本身要管理多个时隙。这样时隙和通道以及电路同时存在了一对多的联系,如何去准确的理解和区分这种联系,并将之有效的梳理在代码层面就很需要一定技巧。
稍微拓展一下,改改资源类型,把业务电路换为传输通道,把传输通道换为传输段,这套关系同样成立。
另外,真实的业务场景中,业务电路的下层路由,不仅支持高阶通道,还支持段时隙,端口等资源。
整体设计
从业务场景中我们可以看到,资源实体间的模型关系其实有很多相类似的地方。比如大体上总是分为路由关系,和层级关系这么两种,那么如何才能高效的对这两种关系进行代码层面的建模以高效的进行复用,同时又保留有每个资源足够的拓展空间呢?
传统思路
我们先来考虑一下,按照传统的贫血模型去处理传输通道这个资源,针对传输通道的需求,它是如何处理的呢?

最粗陋的常规模型,其实就是依据不同类型的资源对需求进行简单分流,然后按照管理划分 Controller 层,Service 层,Dao 层。各层之间的交互,搞得好一点的会通过抽象出的一个薄薄的 domain 域对象,搞的不好的直接就是 List,Map,Object 对象的粗陋组合。
代码示例
/**
* 删除通道 不调用ejb了
* 业务逻辑:
* 判断是否被用,被用不能删除
* 判断是否是高阶通道且已被拆分,被拆不能删除
* 逻辑删除通道路由表
* 清空关联时隙、波道的channel_id字段
* 将端口的状态置为空闲
* 逻辑删除通道表
* @param paramLists 被删除通道,<b>必填属性:channelID</b>
* @return 是否删除成功
* @throws BOException 业务逻辑判断不满足删除条件引发的删除失败<br>
* <b>通道非空闲状态</b><br>
* <b>高阶通道已被拆分</b><br>
* <b>删除通道数据库操作失败</b><br>
* <b>删除HDSL系统失败</b><br>
* @return 成功与否
*/
public String deleteChannel(String channelId){
String returnResult = "true:删除成功";
Map<String,String> condition = new HashMap<String, String>();
condition.put("channelID",channelId);
condition.put("min_index","0");
condition.put("max_index","1");
boolean flag=true;
List<Map<String,Object>> channel = this.channelJdbcDao.queryChannel(condition);
if(channel==null||channel.size()==0){
return "false:未查询到通道信息";
}
//判断是否被用,被用不能删除
String oprStateId = channel.get(0).get("OPR_STATE_ID").toString();
if(!"170001".equals(oprStateId)){
return "false:通道状态非空闲,不能删除";
}
//判断是否是高阶通道且已被拆分,被拆不能删除
flag=this.channelJdbcDao.isSplited(channelId);
if(!flag){
return "false:高阶通道已被拆分,不能删除";
}
//逻辑删除通道路由表 并且清空关联时隙、波道的channel_id字段
this.channelJdbcDao.deleteChannelRoute(channelId,oprStateId);
//将通道端口的端口状态置为空闲
this.channelJdbcDao.occupyPort(String.valueOf(channel.get(0).get("A_PORT_ID")),"170001");
this.channelJdbcDao.occupyPort(String.valueOf(channel.get(0).get("Z_PORT_ID")),"170001");
//逻辑删除通道表
this.channelJdbcDao.delete(channelId);
//如果通道走了HDSL时隙则删除HDSL系统及下属资源 ,这里重新调用了传输系统的删除的ejb。
List<Map<String,Object>> syss=this.channelJdbcDao.findSysByChannel(channelId);
for(int i=0;i<syss.size();i++){
if("56".equals(syss.get(i).get("SYS_TYPE").toString())){
List<Map<String,String>> paramLists = new ArrayList<Map<String,String>>();
List paramList = new ArrayList();
Map map = new HashMap();
map.put("res_type_id", "1001");
map.put("type", "MAIN");
paramList.add(map);
map = new HashMap();
map.put("sys_id", syss.get(i).get("SYS_ID"));
paramList.add(map);
//EJB里面从第二个数据开始读取要删除的系统id,所以下面又加了一层 。
map = new HashMap();
map.put("res_type_id", "1001");
map.put("type", "SUB");
paramList.add(map);
map = new HashMap();
map.put("sys_id", syss.get(i).get("SYS_ID"));
paramLists.add(map);
String inputXml = this.createInputXML("1001", "deleteTrsSys",
"TrsSysService", paramLists);
String result = this.getEJBResult(inputXml);
if(result==null||"".equals(result)){//如果ejb处理失败是以抛异常形式,被底层捕获而未抛出,导致返回结果为空
return "false:删除HDSL系统失败";
}
Document document = XMLUtils.createDocumentFromXmlString(result);
Element rootElement = XMLUtils.getRootElement(document);
if (!TransferUtil.getResultSign(rootElement).equals("success")){
result =rootElement.attribute("description").getValue();
return "false:删除HDSL系统失败"+result;
}
}
}
return returnResult;
}
上面这些代码,是我司n年前的一段已废弃代码。其实也是很典型的一种业务代码编写方式。
可以看到,比较关键的几个流程是 :
空闲不能删除(状态验证)—>路由删除->端口置为空闲(路由资源置为空闲)->资源实体删除
其中各个步骤的具体实现,基本上都是通过调用 dao 层的方法,同时配合若干行 service 层代码来实现的。这就带来了第一个弊端,方法实现和 dao 层实现过于紧密,而 dao 层的实现又是和各个资源所属的表紧密耦合的。因此即便电路的删除逻辑和通道的删除逻辑有很相似的逻辑,也必然不可能进行代码复用了。
如果非要将不同资源删除方法统一起来,那也必然是充斥着各种的 if/else 语句的硬性判断,总代码量却甚至没有减少反而增加了,得不偿失。
拓展思考
笔者曾经看过前人写的一段传输资源的保存方法的代码。
方法目的是支持传输通道/段/电路三个资源的保存,方法参数是一些复杂的 List,Map 结构组合。由于一次支持了三种资源,每种资源又有自己独特的业务判断规则,多情况组合以后复杂度直接爆炸,再外原本方法的编写人员没有定期重构的习惯,所以到了笔者接手的时候,是一个长达500多行的方法,其间充斥着各式各样的 if 跳转,循环处理,以及业务逻辑验证。
解决办法
面对如此棘手的情况,笔者先是参考《重构·改善既有代码设计》一书中的一些简单套路,拆解重构了部分代码。将原本的 500 行变成了十来个几十行左右的小方法,重新组合。
方案局限
- 重构难度及时间成本巨大。
- 有大量的
if/else跳转根本没法缩减,因为代码直接调用dao层方法,必然要有一些if/else方法用来验证资源类型然后调用不同的dao方法 - 也因为上一点,重构仅是小修小补,化简了一些辅助性代码的调用(参数提取,错误处理等),对于业务逻辑调用的核心代码却无法进行简化。
service层代码量还是爆炸
小结
站在分层的角度思考下,上述流程按照技术特点将需求处理逻辑分为了三个层次,可是为什么只有 Service 层会出现上述复杂度爆炸的情况呢?
看到这样的代码,不由让我想到了小学时候老师教写文章,讲文章要凤头,猪肚,豹尾。还真是贴切呢 :-)
换做学生时代的我,可能也就接受了,但是见识过高手的代码后,才发现写代码并不应该是简单的行数堆砌。
业务情景再分析
对于一个具体的传输通道A的对象而言,其内部都要管理哪些数据呢?
-
资源对象层面
- 自身属性信息
-
路由层面
- 下级路由对象列表
-
层次关系层面
- 上级资源对象
- 下级资源对象列表
可以看到,所有这些数据其实分为了三个层面:
- 作为普通资源,传输通道需要管理自身的属性信息,比如速率,两端网元,两端端口,通道类型等。
- 作为带有路由的资源,传输通道需要管理关联的路由信息,比如承载自己的下层传输段,下层传输通道等。
- 作为带有层次关系的资源,传输通道需要管理关联的上下级资源信息,比如自己拆分出来的时隙列表。
更进一步,将传输通道的这几种职责的适用范围关系进行全业务对象级别汇总整理,如下所示:
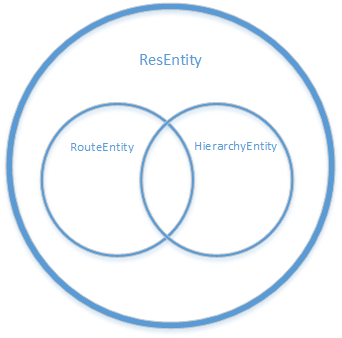
各种职责对应的业务对象范围如下:
-
同时具有路由和层次关系的实体:
- 传输时隙、传输通道、传输段、传输电路
-
具有路由关系的实体:
- 文本路由
-
具有层次结构关系的对象:
- 设备、机房、端口
-
仅作为资源的实体:
- 传输网管、传输子网、传输系统
拓展思考
微观层面
以传输通道这样一个具体的业务对象来看,传统的贫血模型基本不会考虑到传输通道本身的这三个层次的职责。但是对象的职责并不设计者没意识到而变得不存在。如前所述的保存方法,因为要兼顾对象属性的保存,对象路由数据的保存,对象层次结构数据的保存,再乘上通道,段,电路三种资源,很容易导致复杂度的飙升和耦合的严重。
因此,500行的函数出现某种程度上也是一种必然。因为原本业务的领域知识就是如此复杂,将这种复杂性简单映射在 Service 层中必然导致逻辑的复杂和代码维护成本的上升。
宏观层面
以各个资源的职责分类来看,具备路由或层次关系的资源并不在少数。也就是说,贫血模型中,承担类似路由管理职责的代码总是平均的分散在通道,段,电路的相关 Service 层中。
每种资源都不同程度的实现了一遍,而并没有有效的进行抽象。这是在业务对象的代码模型角度来说,是个败笔。
在这种情况下就算使用重构的小技巧,所能做的也只是对于各资源的部分重复代码进行抽取,很难自然而然的在路由的业务层面进行概念抽象。
既然传统的贫血模型没法应对复杂的业务逻辑,那么我们又该怎么办呢?
新的架构
代码示例
@Transactional
public int deleteResRoute(ResIdentify operationRes) {
int result = ResCommConst.ZERO;
//1:获得需要保存对象的Entity
OperationRouteResEntity resEntity = context.getResEntity(operationRes,OperationRouteResEntity.class);
//2:获得路由对象
List<OperationResEntity> entityRoutes = resEntity.loadRouteData();
//3:删除路由
result = resEntity.delRoute();
//4:释放删除的路由资源状态为空闲
this.updateEntitysOprState(entityRoutes, ResDictValueConst.OPR_STATE_FREE);
//日志记录
resEntity.loadPropertys();
String resName = resEntity.getResName();
String resNo = resEntity.getResCode();
String eport = "删除[" + ResSpecConst.getResSpecName(operationRes.getResSpcId()) + ": " + resNo + "]路由成功!";
ResEntityUtil.recordOprateLog(operationRes, resName, resNo, ResEntityUtil.LOGTYPE_DELETE, eport);
return result;
}
上述代码是我们传输业务模块的删除功能的 service 层代码片段,可以看到相较先前介绍的代码示例而言,最大的不同,就是多出来了个 entity 对象,路由资源的获取是通过这个对象,路由资源的删除也是通过这个对象。所有操作都只需要一行代码即可完成。对电路如此,对通道也是如此。
当然,别的 service 层代码也可以很方便的获取这个 entity 对象,调用相关的方法组合实现自己的业务逻辑以实现复用。
那么这种效果又是如何实现的呢?
概念揭示
首先我们得思考一下,作为一个类而言,最重要的本质是什么?
答案是数据和行为。
照这个思路,对于一个业务对象,比如传输通道而言,进行分析:
- 在数据层面,每个通道记录了自身属性信息及其关联的传输时隙、传输段、传输电路等信息数据。
- 在行为层面,每个通道都应该有增删改查自身属性、路由、下级资源、绑定/解绑上级资源等行为。
那么在具体的业务建模时又该如何理解这两点呢?
答案就是这张图:
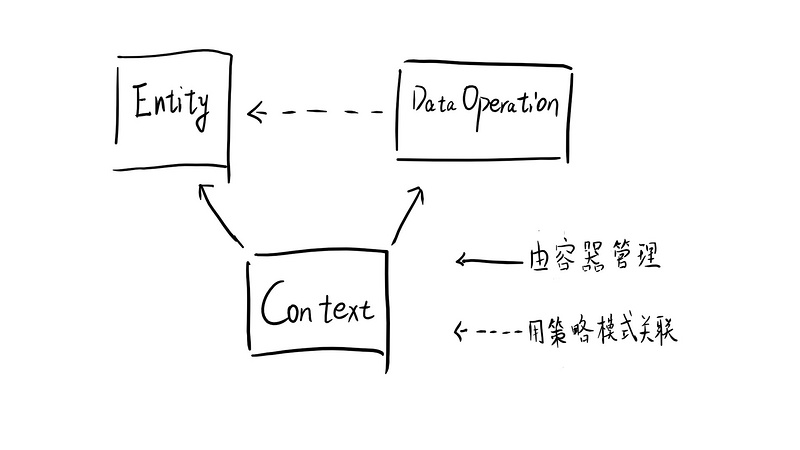
可以看到大体分为了三种类型的元素,
-
Context(上下文容器):
- 程序启动时,开始持有各个 DataOperation 对象
- 程序运行时,负责创建 Entity 对象,并将相应的 DataOperation 对象装配进 Entity 对象实例中
- Entity(实体对象):每个用到的资源对象都生成一个 Entity 实例,以存放这个对象特有的实例数据。
- DataOperation(数据操作对象):不同于 Entity,每类用到的资源对象对应一个相应的 DataOperation 子类型,用以封装该类对象特有的数据操作行为
ps,虽然我这里画的 Entity&DataOperation 对象只是一个方框,但实际上 Entity&DataOperation 都有属于他们自己的 N 多个适用与不同场景的接口和模板类
数据管理
笔者是个宅男,因为并木有女朋友,又不喜欢逛街,所以买东西都是网购。这就产生了一个很有意思的影响——隔三差五就要取快递。
可是快递点大妈不认识我,我也不是每天出门带身份证。这就很尴尬,因为我每次总是需要和大妈围绕 “Thehope 就是我” 解释半天。
所以每次解释的时候,我都在想,如果我带了身份证或者其他类似的证件,该有多方便。
什么是 Entity
我们一般认为,一个人有一个标识,这个标识会陪伴他走完一生(甚至死后)。这个人的物理属性会发生变化,最后消失。他的名字可能改变,财务关系也会发生变化,没有哪个属性是一生不变的。然而,标识却是永久的。我跟我5岁时是同一个人吗?这种听上去像是纯哲学的问题在探索有效的领域模型时非常重要。
稍微变换一下问题的角度:应用程序的用户是否 关心 现在的我和5岁的我是不是同一个人?
—— Eric Evans《领域驱动设计》
简单的取快递或许使你觉得带有标识的对象概念并没有什么了不起。但是我们把场景拓展下,你不光要完成取快递的场景,如果你需要买火车票呢?如果还要去考试呢?
伴随着业务场景的复杂化,你会越来越发现,有个统一而清晰的标识概念的对象是多么的方便。
再来看看 Eric Evans 在《领域驱动设计》如何介绍 Entity 这个概念的:
一些对象主要不是由它们的属性定义的。它们实际上表示了一条“标识线”(A Thread of Identity),这条线经过了一个时间跨度,而且对象在这条线上通常经历了多种不同的表示。
这种主要由标识定义的对象被称作 Entity。它们的类定义、职责、属性和关联必须围绕标识来变化,而不会随着特殊属性来变化。即使对于哪些不发生根本变化或者生命周期不太复杂的 Entity ,也应该在语义上把它们作为 Entity 来对待,这样可以得到更清晰的模型和更健壮的实现。
确定标识
得益于我司数据库模型管理的细致,对于每条资源数据都可以通过他的规格类型id,以及数据库主键id,获得一个唯一确定标识特征。
如图:
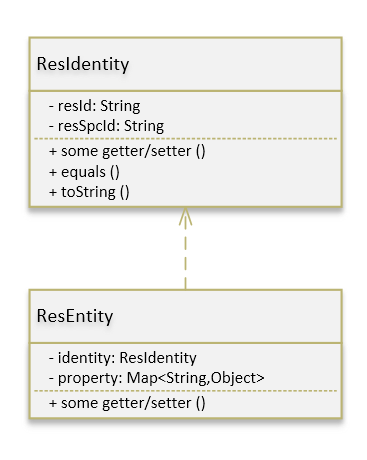
这里举出的 Entity 的属性及方法仅仅是最简单的一个示例,实际业务代码中的 Entity,还包括许多具备各种能力的子接口。
引入Entity
如图:
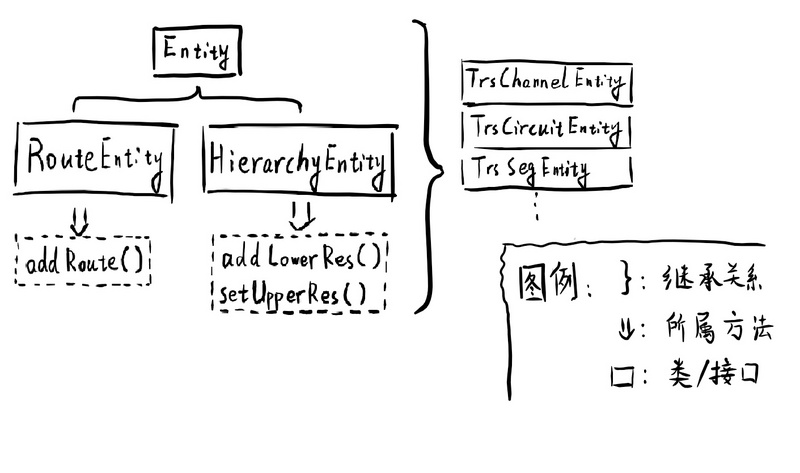
可以看到 entity 对象实际上分为了两个主要的接口,RouteEntity 和 HierarchyEntity。
其中 RouteEntity 主要规定要实现的方法是 addRoute(), 即添加路由方法
其中 HierarchyEntity 主要规定要实现的方法是 addLowerRes() 与 setUpperRes() ,即添加子资源对象和设置父资源两种方法。
那么这两个接口是如何抽象建模得到的呢?
确定功能的边界
从微观的实例对象层面来看,因为每个实例都可能拥有完全不一样的路由和层级关系,所以我们建模时候,用抽象出的 Entity 概念,表示哪些每个需要维护自己的属性/路由/层次关联数据的对象实例。
从高一层的类的层次去分析,我们可以发现,对路由的管理,对层次结构的管理,贯穿了传输电路,传输通道,传输段,传输时隙等很多业务类型。所以这个时候就需要我们在接口层面,根据业务特征,抽象出管理不同类型数据的 Entity 类型,以实现内在关联关系的复用。
因此我们对 Entity 接口进行细化而建立了的 RouteEntity 和 HierarchyEntity 两个子接口,比如
- Entity 需要维护自己的 id 标识,属性信息。
- RouteEntity 就需要内部维护一个路由数据列表。
- HierarchyEntity 就需要维护一个父对象和子资源列表。
这样通过对不同的 Entity 管理的数据的职责与类型的进一步明确,保证在不同场景下,做到使用不同的 Entity 就可以满足相应需求。。。。的数据前提 :P
拓展思考
既然 Entity 概念的引入是为了解决各资源对象具体实例的实例数据的存储问题。那么各个资源对象特有的行为操作怎么满足呢?比如传输通道和传输电路都有自己的表,起码在dao层的操作就肯定不一样,再加上各个资源自己独特的增删改查验证逻辑,如果这些行为都放在 Entity 中。。。妥妥的类型爆炸啊~
另外,将数据与行为的职责耦合在一起,从领域建模的思想上就是一个容易混淆而不明智的决定。
站在微观角度来说,每个 Entity 实例所管理的实例数据是不同的,而同一类资源的行为操作(它的方法)却是无状态的。
站在宏观角度来说,具有路由特征的或者具有层次特征一簇实体,有抽象共性的价值(比如都需要管理路由列表或者父子对象信息),而涉及具体的行为实现,每种具体的资源又天然不完全相同。
小结
这里我们可以再思考下前文贴的两段代码,当我们没有 Entity 对象时,许多应该由 Entity 进行存储和管理的数据,就不得不通过 map/list 去实现,比如上文的第一段代码。这就带来第一个弊端,不到运行时,你根本不知道这个容器内存放的是哪种业务规格的资源。
第二个弊端就是,当你使用 map/list 来代替本应存在的 Entity 对象时,你也拒绝了将对象的行为和数据整合在一起的可能(即不可能写出 resEntity.loadRouteData() 这样清晰的代码,实现类似的逻辑只能是放在 Service 层中去实现,不过放在 Service 又增加了与具体资源逻辑的耦合)
所以,以数据和行为分离的视角,将业务对象以策略模式进行解耦,抽离成专职数据管理的 Entity 对象,以及专职行为实现的 DataOperation 簇对象,就显得非常有价值了。
行为管理
引入 DataOperation
接下来有请出我们的 DataOperation 元素登场~
以传输通道为例,对于传输通道的所属路由而言,常用的功能无非就是的增删改查这几个动作。
确定变化的边界
还是从微观的实例对象层面先进行分析
业务行为逻辑会因为操作的实体数据是传输通道A,或者传输通道B 而变得不同吗?答案是不会。
正如数据库行记录的变化不引起表结构的变化一样,本质上一类资源所拥有的行为和对象实例的关系,应该是一对多的。
所以只要都是传输通道,那么其路由增删改查的行为逻辑总是一致的。
结合某一著名设计原则:
找出应用中可能需要变化之处,把它们独立出来,不要和那些不需要变化的代码混在一起
所以我们应该将资源不变的行为逻辑抽离出来,以保证 Entity 可以专注于自己对数据的管理义务,达到更高级的一种复用。
这也就是为什么需要抽象 DataOperation 概念的原因之一。
进一步从类的层次去分析
不同种类的资源,其具体的数据操作行为必然是存在差别的(比如与数据库交互时,不同资源对应的表就不同)。
所以不同种类的业务对象都必然会有自己的 DataOperation 子类,比如 TrsChannelDataOperation、TrsSegDataOperation 等,以确保每类业务对象独特的数据操作逻辑的灵活性。
再进一步去分析
在更高的层级上去分析,灵活性我们因为实现类的细化已经具备了,那么复用的需求又该怎么去满足呢?
与 Entity 对象一样,我们可以在具体的 TrsChannelDataOperation、TrsSegDataOperation 等实体类之上,抽象出 RouteResDataOperation、HierarchyResDataOperation 等接口,规定好应该具备的方法。
Entity 对象面对需要调用 DataOperation 的场景,就以这些接口作为引用,从而使路由或者层次处理的业务代码从细节的实现中解放出来。
拓展思考
这里可以仔细思考一下,Entity 和 DataOperation 应该在什么时候建立好二者之间的联系呢?
小结
我们已经分析好了对象的数据和行为该如何建模,那么,我们又该如何将这二者统一起来呢?
有请我们的第三类元素,Context 登场~
组装
先来看看这样一个例子:
汽车发动机是一种复杂的机械装置,它由数十个零件共同协作来侣行发动机的职责 — 使轴转动。我们可以试着设计一种发动机组,让它自己抓取一组活塞并塞到气缸中,火花塞也可以自己找到插孔并把自己拧进去。但这样组装的复杂机器可能没有我们常见的发动机那样可靠或高效。相反,我们用其他东西来装配发动机。或许是一个机械师,或者是一个工业机器人。无论是机器还是人,实际上都比二者要装配的发动机复杂。装配零件的工作与使轴旋转的工作完全无关。装配者的功能只是在生产汽车时才需要,我们驾驶时并不需要机器人或机械师。由于汽车的装配和驾驶永远不会同事发生。因此将这两种功能合并到同一个机制中是毫无意义的。同理,装配复杂的复合对象的工作也最好与对象要执行的工作分开。
——Eric Evans《领域驱动设计》
与发动机小栗子相类似,代码中我们当然可以通过构造器的方式用到哪个对象再组装哪个对象。不过比较一下这样两段代码:
没有 Context 元素的代码:
@Transactional
public int deleteResRoute(ResIdentify operationRes, boolean protectFlag) {
...
//1.获取需要保存对象的Entity
OperationRouteResEntity resEntity = new TrsChannelResEntity();
if(ResSpecConst.isChannelEntity(operationRes.getResSpcId())){
ComponentsDefined component = new TrsChannelDataOperation();
resEntity.initResEntityComponent(conponent);
}
...
}
有了 Context 元素以后
@Transactional
public int deleteResRoute(ResIdentify operationRes, boolean protectFlag) {
...
//1.获取需要保存对象的Entity
OperationRouteResEntity resEntity = context.getResEntity(operationRes,OperationRouteResEntity.class);
...
}
是不是立竿见影的效果!
为什么需要 Context
事实上前文对 Entity 和 DataOperation 只是领域建模的第一步,只是个雏形。而这里的 context 对象,才是画龙点睛的那一笔。
为什么这么说呢?在此之前,我也见过公司内许多其他的模块对业务逻辑做过的复杂抽象,但是因为调用的时候需要调用者亲自调用构造器生成实例,导致使用成本太高。尤其是人员流动比较大的模块,新人天然不懂复杂的业务对象关系,这就使的业务开发人员很难持续使用业务模型对象,最终导致代码模型形同虚设。
对象的功能主要体现在其复杂的内部配置以及关联方面。我们应该一直对一个对象进行提炼,直到所有与其意义或在交互中的角色无关的内容已经完全被剔除为止,一个对象在它的生命周期中要承担大量的职责。如果再让复杂对象负责其自身的创建,那么职责的过载将会导致问题产生。——Eric Evans《领域驱动设计》
为了避免这样的问题,我们有必要对 Entity 等实体对象的装配与运行进行解耦实现,这也即是我们的 Context 元素的主要职责之一。比如上述两段代码,在其他元素不做改变的情况下,仅仅出于对职责的明确而引入的 Context 元素,对业务代码编写却有了质的提升。
但实际上,正如一开始的小栗子说的,“无论是装配机还是装配师,都比要装配的发动机要复杂”,我们的 context 所执行的逻辑其实也是相当复杂的,但只要对客户(这里的客户指的是使用 context 的业务代码,下文同)帮助更大,即便再复杂也构不成不去做的理由,下面我们就来聊聊这个实质上的复杂工厂是如何运作的。
引入 Context
OperationResEntity resEntity = context.getResEntity(resIdentify);
在 Context 中,加载操作仅有一行,看起来是不是非常清晰,非常简单?可惜背后所需思考的问题可一点都不简单:)
首先,我们先来思考下 Context 在这行代码中都完成了哪些事情吧:
public OperationResEntity getResEntity(ResIdentify identify) {
OperationResEntity entity = getResEntity(identify.getResSpcId());
entity.setIdentify(identify);
return entity;
}
public OperationResEntity getResEntity(String resSpcId) {
ResEntity entity = factory.getResEntity(resSpcId);
if(entity instanceof OperationResEntity){
ResComponentHolder holder = componentSource.getComponent(resSpcId);
if(entity instanceof ContextComponentInit){
((ContextComponentInit)entity).initResEntityComponent(holder);
}
}else{
throw new ResEntityContextException("资源规格:"+resSpcId+",实体类:"+entity.getClass().getName()+"未实现OperationResEntity接口");
}
return (OperationResEntity)entity;
}
上面就是 context 在获取目标 entity 对象时所做的一些具体操作,可以看到,主要完成了这么三件事:
- 获取 Entity 实例
- 获取 DataOpeartion 实例(持有于上述方法中的 hoder 对象中)
- 将 Entity 和 DataOperation 装配起来
那接下来我们就仔细分析下这三个步骤应该怎么实现吧~
获取 Entity
在本节的一开始,我们就举了两个例子,对比了有 context 帮我们封装 Entity 与 DataOperation 组合关系,与缺少 context 帮我们封装组合关系时的区别。具体来说,优势在与这么两点:
- 简化了业务开发人员使用 Entity 对象的成本,使其天然倾向于调用框架模型,便于保证后期业务领域模型的统一性
- 减少了客户代码(service)中类似
new TrsChannelDataOperation()这样的硬编码,客观上便于service层构建更为通用而健壮的实现
转过头来再思考下,我们的 Entity 对象与 DataOperation 对象又是否天然存在一种非常复杂多变的动态组合关系呢?
通常,我们在实际运行时才能确定 service 中某个 Enity 的具体规格及其应该持有的 DataOperation 对象。如果由业务代码开发人员在调用处手动初始化,未免太过复杂,也不可避免的需要通过许多 If/ELSE 判断来调整运行分支,这样看代码复杂度还是居高不下,那我们前面洋洋洒洒分析那么多又还有什么意义呢。
实际上,类似 Entity 与 DataOperation 之类的动态 (调用处才知道具体的组合关系) 组合关系在很多优秀的代码中都有应用,比如我们熟知的 Spring。
或许我们也需要 借鉴 一波 Spring 的处理思路 ^_^
从 Spring 延伸开来
我们都知道 Spring 最著名的一个卖点就是 IOC,也就是我们俗称的控制反转/依赖注入。
它将 Bean 对象中域的声明和实例化过程解耦,将对象域实例的管理与注入责任,从开发人员移交至 Spring 容器。也正因如此, 这种设计从源头上即减少了开发人员在域实例化过程中的硬编码,为对象间的组合提供了更为清晰便捷的实现。 ——TheHope:P
先明确了 IOC 的最大功用之一就是将对象间如何组合的责任从开发者肩上卸下 ,我们再继续分析这个过程的实现中的两个要点。
- 首先容器必须具有创建各个对象的能力
- 其次容器必须知道各个对象间的关联关系是怎样的
来,我们看看 Spring 加载 Bean 的步骤:
- bean工厂初始化时期: 加载配置文件 --> 初始化 bean 工厂 --> 初始化 bean 关联关系解析器 --> 加载并缓存 beanDefinition
- bean工厂初始化完成之后: 获取 beanDefinition --> 根据 beanDefinition 生成相应的 bean 实例 --> 初始化 bean 实例中的属性信息 --> 调用 bean 的生命周期函数
可以看到 bean 工厂初始化时,便解析好了所有 bean 的 beanDefinition ,同时维护好了一个 beanName 与 beanDefinition 的 map 映射关系,而 beanDefinition 内部存储好了 bean 对象实例化所需的所有信息。同时也解析好了 bean 之间的注入关系。
因此,当 beanFacory 初始化完备的时候,实际上,Spring 就已经具备获取任意一个的 Bean 实例对象的所有基础信息了。
拓展思考
看到这里你有没有发现,Spring 加载 bean 的第二步操作,根据某种标识获取目标对象实例的过程,不就是常规情况下一个工厂的目标作用吗,那 Spring 在流程上要加一步初始化工厂的操作呢?Spring 的工厂与普通的工厂模式又有什么异同呢?
为了屏蔽代码中 new 一个构造器之类的硬编码,我们都学习过工厂模式,当类型变化不是很多的时候,可以使用工厂模式进行封装,当变化再多些的时候我们可以借助抽象类,用个抽象工厂进行封装,将这种组合变换关系的复杂度分散到组合关系与继承关系中去。
只是 Spring 中的 bean 比较特别,其属性信息变化的情况实在是太多了,甚至 bean 之间的组合关系都是不固定的,很有可能出现 A 关联了 B ,B 又关联了 C,C 又...这时候如果还使用抽象工厂,业务上为了支持自己需要的组合情况,每多一层组合关系,那就需要我们动态继承抽象类,相比XML,这显然太过复杂了。
所以 Spring 为了支持这样的变化,也是为了职责的清晰,将 BeanFactory 生成一个具体的 bean 时所需的信息专门抽象出来,用 XML 去由框架使用者自行维护,XML 内的信息在 Spring 内部即转化为一簇 BeanDefinition 对象来管理,BeanFactory 的职责,则围绕 BeanDefinition 划分为了两个阶段:
- 读取并缓存 beanDefinition 信息的 beanFactory 初始化阶段
- 使用 beanDefinition 信息动态生成 bean 实例的后 beanFactory 初始化阶段
小结
如此这般,ABC问题中最为灵活且复杂的关联关系,即由工厂/抽象工厂中预先设计转化为了框架使用者自行维护。嘿,好一招腾笼换鸟~
组装Entity
一不小心就讲多了,我们的 Entity 与 DataOperation 的关联关系远没有那么复杂,不过我们可以仿照 Spring 建立 BeanName 与 BeanDefinition 映射关系的思想,在容器启动时将我们的 Entity 与 DataOperation 组合关系加载好,实现后续使用时,获取确定的 Entity 同时容器自己帮我们注入好需要的 DataOperation 。
待续
小结
待续。。。
参考资料
Eric Evans的《Domain-Driven Design领域驱动设计》
联系作者
正文到此结束
- 本文标签: HashMap spring js UI 时间 实例 src BeanDefinition AOP https 配置 需求 DOM 开发 文章 IO 数据库访问 ip map 代码 Document 一对多 汽车 业务层 本质 压力 管理 解析 参数 生命 ioc bug 缓存 db 学生 NSA CTO 组织 删除 bean 专注 JDBC 端口 数据库 IDE CEO list http Service 模型 equals root description 数据 空间 value DDL Action id ArrayList update find 开发者 火车票 XML entity Property MQ
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

