源码解惑-Picasso:在 synchronized 保证可见性的情况下为什么要加 volatile ?
有这样一些知识,它们在日常的工作中很少派上用场,但是又频繁出现在面试题中,这些知识被称为基础知识。为了提高自身水平或者通过面试,我们就会搜索一些阐明基础知识的文章来学习这些知识。看完后你可能也可以说得头头世道,但如果不在实践中把这些知识纳入思考,如果不写出货真价实心知肚明的代码,很难说真的学会了。
阐明基础知识的文章由于篇幅限制和为了阐述简单,通常只能举一些简单的例子,看完后会让人觉得似懂非懂。我认为在阐明基础知识的文章之外,还需要一种文章。这种文章不仅可以提供一个真实的应用场景让我们思考,还可以让我们看到这些知识如何在思考后变成实实在在的代码。我想到的是分析开源框架,不是分析框架的整体架构,而是基于框架的某个应用场景,分析代码细节。
基础知识
这篇文章涉及的是 Java 多线程的基础知识:synchronized 和 volatile 。多线程涉及到对 Java 运行机制的了解,还和人类习惯的过程式思维冲突,所以比较难。如果对 synchronized 和 volatile 还没有一个基础了解,可以先去搜索相关的介绍文章,再回来看下文。
下面直接开始本文的应用场景。
应用场景
这段代码位于 Picasso 1.0.0 的 UrlConnectionLoader。Picasso 是 android 的一个图片加载框架。
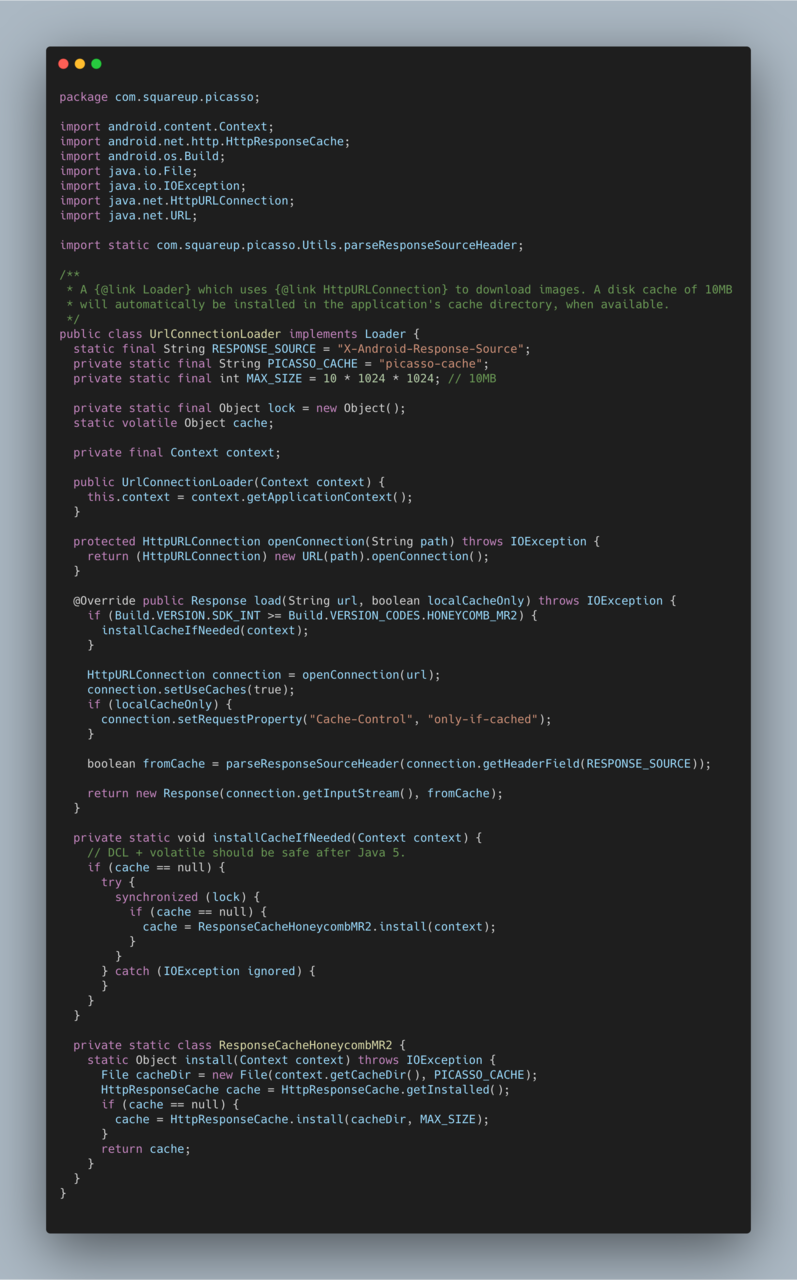
UrlConnectionLoader 的功能主要是根据图片的网络链接下载图片资源,所使用的网络库是 android 自带的 HttpURLConnection。
和 Glide 一样,一开始 Picasso 也是利用 DiskLruCache 来做图片的硬盘缓存的,后来它可能觉得利用网络库的 http 响应缓存做硬盘缓存更加简单方便,就把 DiskLruCache 去掉了。要给 HttpURLConnection 设置响应缓存需要调用 HttpResponseCache.intall 。
static Object install(Context context) throws IOException {
File cacheDir = new File(context.getCacheDir(), PICASSO_CACHE);
HttpResponseCache cache = HttpResponseCache.getInstalled();
if (cache == null) {
cache = HttpResponseCache.install(cacheDir, MAX_SIZE);
}
return cache;
}
复制代码
这步操作涉及到磁盘 I/O ,所以最好把这步操作放到后台线程进行。Picasso 把这一步操作放到每个网络请求之前。
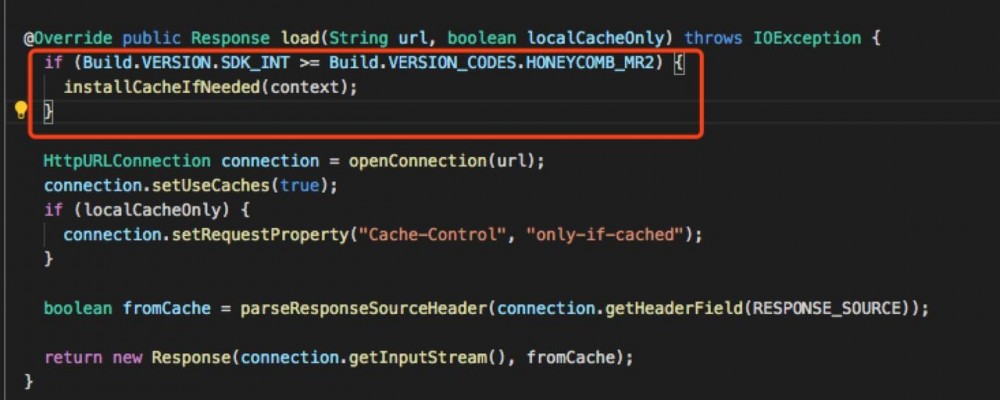
这样一来可以实现懒加载,在第一次请求的时候,才安装 HttpResponseCache ;二来可以利用网络请求的后台线程,不需要单独创建一个后台线程。每个网络请求都是不同的线程,而 HttpResponseCache 是一个单例对象,这样就涉及到如何在多线程下创建单例对象了。
如何在多线程下创建单例对象
为了保证 HttpResponseCache 只有一个,所以当 cache 为空的才创建。
if (cache == null) {
cache = ResponseCacheHoneycombMR2.install(context);
}
复制代码
为了避免多线程同时创建多个 HttpResponseCache 对象,所以利用 synchronized 来锁住这个代码块,让这个代码块一次只能由一个线程进入。
synchronized (lock) {
if (cache == null) {
cache = ResponseCacheHoneycombMR2.install(context);
}
}
复制代码
为了不让每个线程遇到 synchronized 都阻塞等待获取锁,这样会让程序变慢,所以在 synchronized 之前增加一个判断,如果 cache 不为空,就不进入同步代码块。
if(cache == null)
synchronized (lock) {
if (cache == null) {
cache = ResponseCacheHoneycombMR2.install(context);
}
}
}
复制代码
这样的写法就叫 DCL(double checked locking) 。
惑从何来
上面所说的还是比较容易理解的,但是在上图的代码中,我还注意到一句注释
// DCL + volatile should be safe after Java 5. 复制代码
这句注释表明单单 DCL 是不能保证 cache 的创建在多线程下是安全的,还需要给 cache 加 volatile。
static volatile Object cache; 复制代码
如果不是有这句注释,如果不是对 volatile 很熟悉的话(例如我)是很容易把 cache 变量声明前的 volatile 关键字给忽略掉的。
在我之前的学习中,我知道 volatile 是一种轻量多线程数据同步机制:可以让某个变量的值在操作前从系统内存读取到线程缓存中,在操作后马上从线程缓存写回系统内存,这样就保证了数据在多线程的可见性。一开始我以为加 volatile 就是保证 cache 的可见性,保证 cache 在一个线程创建赋值后,写回内存,这样其他线程就可以看到 cache 已经被创建了。本来以为这部分代码就这样过去了,但是后来我又想起了 synchronized 除了保证线程互斥访问,也保证了数据的可见性(这个知识点本文不涉及)。
那么 synchronized 不就是和 volatile 的作用重复了吗?为什么还要加 volatile ?可见 volatile 在这里不是为了数据的可见性,volatile 还有什么作用呢?答案是避免指令重排。
指令重排
什么是指令重排?简单来说是为了优化代码运行效率,在实际运行中的代码顺序和我们写的代码顺序不一样。
在这里可能会发生什么指令重排?在 new 一个对象的时候可以简单分成三个步骤
- 申请内存空间
- 对象初始化
- 引用变量指向内存空间地址
由于步骤 2 可能比较耗时,经过指令重排后可能变成 1,3,2。
回到我们的场景,如果经过这样的重排,那么考虑这样的一种情况:一开始 cache 为空,此时线程 A 发起网络请求,拿到锁后,对 cache 进行了步骤 1 和 3 ,此时 cache 已经被赋值,而且假设被更新回内存。又假设这时候线程 B 也发起网络请求,那么它在 DCL 的第一个判断看到 cache 不为空,就会执行下面的网络请求,直接使用 cache 。而这时候假设线程 A 还没执行完步骤 2,那么线程 B 就会由于使用一个未初始化完成的 cache 而发生错误。
如果加了 volatile ,就可以保证指令不会被重排,这样就不会发生上面的情况。
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

