Mybatis一二级缓存实现原理与使用指南
@TOC Mybatis 与 Hibernate 一样,支持一二级缓存。一级缓存指的是 Session 级别的缓存,即在一个会话中多次执行同一条 SQL 语句并且参数相同,则后面的查询将不会发送到数据库,直接从 Session 缓存中获取。二级缓存,指的是 SessionFactory 级别的缓存,即不同的会话可以共享。
缓存,通常涉及到缓存的写、读、过期(更新缓存)等几个方面,请带着这些问题一起来探究Mybatis关于缓存的实现原理吧。
提出问题:缓存的查询顺序,是先查一级缓存还是二级缓存?
本文以SQL查询与更新两个流程来揭开Mybatis缓存实现的细节。
温馨提示,建议在阅读本文之前先阅读笔者的另外几篇文章: 1) 源码分析Mybatis MapperProxy初始化之Mapper对象的扫描与构建 2) 源码分析Mybatis MappedStatement的创建流程 3) 源码分析Mybatis SQL执行流程 4) Mybatis执行SQL的4大基础组件详解
1、从 SQL 查询流程看一二级缓存
温馨提示,本文不会详细介绍详细的 SQL 执行流程,如果对其感兴趣,可以查阅笔者的另外一篇文章: 源码分析Mybatis SQL执行流程
1.1 创建Executor
Configuration#newExecutor
public Executor newExecutor(Transaction transaction, ExecutorType executorType) {
executorType = executorType == null ? defaultExecutorType : executorType;
executorType = executorType == null ? ExecutorType.SIMPLE : executorType;
Executor executor;
if (ExecutorType.BATCH == executorType) {
executor = new BatchExecutor(this, transaction);
} else if (ExecutorType.REUSE == executorType) {
executor = new ReuseExecutor(this, transaction);
} else {
executor = new SimpleExecutor(this, transaction);
}
if (cacheEnabled) { // @1
executor = new CachingExecutor(executor); // @2
}
executor = (Executor) interceptorChain.pluginAll(executor);
return executor;
}
复制代码
代码@1:如果 cacheEnabled 为 true,表示开启缓存机制,缓存的实现类为 CachingExecutor,这里使用了经典的装饰模式,处理了缓存的相关逻辑后,委托给的具体的 Executor 执行。
cacheEnable 在实际的使用中通过在 mybatis-config.xml 文件中指定,例如:
<configuration> <settings> <setting name="cacheEnabled" value="true"> </settings> </configuration> 复制代码
该值默认为true。
1.2 CachingExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler) throws SQLException {
BoundSql boundSql = ms.getBoundSql(parameterObject); // @1
CacheKey key = createCacheKey(ms, parameterObject, rowBounds, boundSql); // @2
return query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); // @3
}
复制代码
代码@1:根据参数生成SQL语句。
代码@2:根据 MappedStatement、参数、分页参数、SQL 生成缓存 Key。
代码@3:调用6个参数的 query 方法。
缓存 Key 的创建比较简单,本文就只贴出代码,大家一目了然,大家重点关注组成缓存Key的要素。 BaseExecute#createCacheKey
public CacheKey createCacheKey(MappedStatement ms, Object parameterObject, RowBounds rowBounds, BoundSql boundSql) {
if (closed) {
throw new ExecutorException("Executor was closed.");
}
CacheKey cacheKey = new CacheKey();
cacheKey.update(ms.getId());
cacheKey.update(rowBounds.getOffset());
cacheKey.update(rowBounds.getLimit());
cacheKey.update(boundSql.getSql());
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
TypeHandlerRegistry typeHandlerRegistry = ms.getConfiguration().getTypeHandlerRegistry();
// mimic DefaultParameterHandler logic
for (ParameterMapping parameterMapping : parameterMappings) {
if (parameterMapping.getMode() != ParameterMode.OUT) {
Object value;
String propertyName = parameterMapping.getProperty();
if (boundSql.hasAdditionalParameter(propertyName)) {
value = boundSql.getAdditionalParameter(propertyName);
} else if (parameterObject == null) {
value = null;
} else if (typeHandlerRegistry.hasTypeHandler(parameterObject.getClass())) {
value = parameterObject;
} else {
MetaObject metaObject = configuration.newMetaObject(parameterObject);
value = metaObject.getValue(propertyName);
}
cacheKey.update(value);
}
}
if (configuration.getEnvironment() != null) {
// issue #176
cacheKey.update(configuration.getEnvironment().getId());
}
return cacheKey;
}
复制代码
接下来重点看CachingExecutor的另外一个query方法。
CachingExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache(); // @1
if (cache != null) {
flushCacheIfRequired(ms); // @2
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key); // @3
if (list == null) { // @4
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); //@5
tcm.putObject(cache, key, list); // issue #578 and #116 // @6
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); //@7
}
复制代码
代码@1:获取 MappedStatement 中的 Cache cache 属性。 代码@2:如果不为空,则尝试从缓存中获取,否则直接委托给具体的执行器执行,例如 SimpleExecutor (@7)。 代码@3:尝试从缓存中根据缓存 Key 查找。 代码@4:如果从缓存中获取的值不为空,则直接返回缓存中的值,否则先从数据库查询@5,将查询结果更新到缓存中。
这里的缓存即 MappedStatement 中的 Cache 对象是一级缓存还是二级缓存?通常在 ORM 类框架中,Session 级别的缓存为一级缓存,即会话结束后就会失效,显然这里不会随着 Session 的失效而失效,因为 Cache 对象是存储在于 MappedStatement 对象中的,每一个 MappedStatement 对象代表一个 Dao(Mapper) 中的一个方法,即代表一条对应的 SQL 语句,是一个全局的概念。
相信大家也会觉得,想继续深入了解 CachingExecutor 中使用的 Cache 是一级缓存还是二级缓存,了解 Cache 对象的创建至关重要。关于 MappedStatement 的创建流程,建议查阅笔者的另外一篇博文: 源码分析Mybatis MappedStatement的创建流程 。
本文只会关注 MappedStatement 对象流程中关于于缓存相关的部分。
接下来将按照先二级缓存,再一级缓存的思路进行讲解。
1.2.1 二级缓存
1.2.1.1 MappedStatement#cache属性创建机制
从上面看,如果 cacheEnable 为 true 并且 MappedStatement 对象的 cache 属性不为空,则能使用二级缓存。
我们可以看到 MappedStatement 对象的 cache 属性赋值的地方为:MapperBuilderAssistant#addMappedStatement,从该方法的调用链可以得知是在解析 Mapper 定义的时候就会创建。
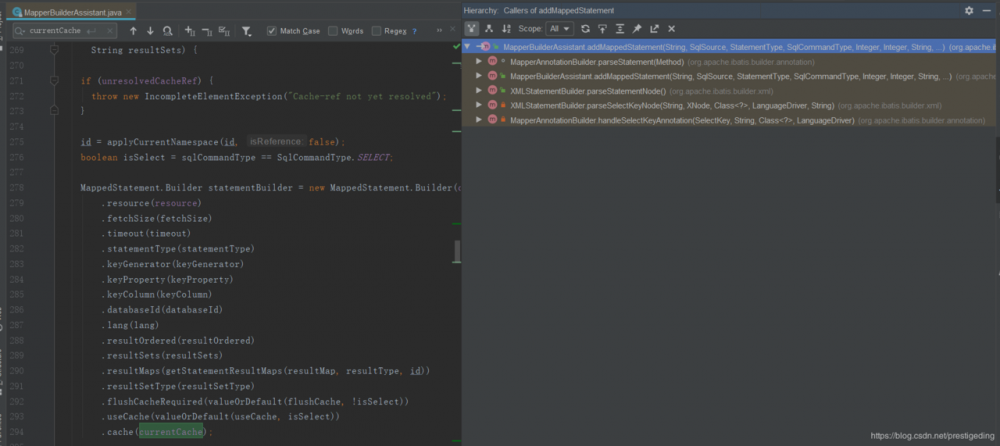
使用的 cache 属性为 MapperBuilderAssistant 的 currentCache,我们跟踪一下该属性的赋值方法:
public Cache useCacheRef(String namespace) 复制代码
其调用链如下:

可以看出是在解析 cacheRef 标签,即在解析 Mapper.xml 文件中的 cacheRef 标签时,即二级缓存的使用和 cacheRef 标签离不开关系,并且特别注意一点,其参数为 namespace,即每一个 namespace 对应一个 Cache 对象,在 Mybatis 的方法中,通常namespace 对一个 Mapper.java 对象,对应对数据库一张表的更新、新增操作。
public Cache useNewCache 复制代码
其调用链如下图所示:

在解析 Mapper.xml 文件中的 cache 标签时被调用。
1.2.1.2 cache标签解析
接下来我们根据 cache 标签简单看一下 cache 标签的解析,下面以 xml 配置方式为例展开,基于注解的解析,其原理类似,其代码 XMLMapperBuilder 的 cacheElement 方法。
private void cacheElement(XNode context) throws Exception {
if (context != null) {
String type = context.getStringAttribute("type", "PERPETUAL");
Class<? extends Cache> typeClass = typeAliasRegistry.resolveAlias(type);
String eviction = context.getStringAttribute("eviction", "LRU");
Class<? extends Cache> evictionClass = typeAliasRegistry.resolveAlias(eviction);
Long flushInterval = context.getLongAttribute("flushInterval");
Integer size = context.getIntAttribute("size");
boolean readWrite = !context.getBooleanAttribute("readOnly", false);
boolean blocking = context.getBooleanAttribute("blocking", false);
Properties props = context.getChildrenAsProperties();
builderAssistant.useNewCache(typeClass, evictionClass, flushInterval, size, readWrite, blocking, props);
}
}
复制代码
从上面 cache 标签的核心属性如下:
- type 缓存实现类,可选择值:PERPETUAL、LRU 等,Mybatis 中所有的缓存实现类如下:
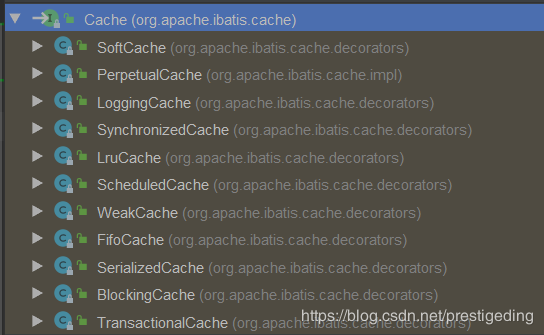
- eviction 移除算法,默认为 LRU。
- flushInterval 缓存过期时间。
- size 缓存在内存中的缓存个数。
- readOnly 是否是只读。
- blocking 是否阻塞,具体实现请看 BlockingCache。
1.2.1.3 cacheRef

cacheRef 只有一个属性,就是 namespace,就是引用其他 namespace 中的 cache。
Cache 的创建流程就讲解到这里,同一个 Namespace 只会定义一个 Cache。二级缓存的创建是在 *Mapper.xml 文件中使用了< cache/>、< cacheRef/>标签时创建,并且会按 NameSpace 为维度,为各个 MapperStatement 传入它所属的 Namespace 的二级缓存对象。
二级缓存的查询逻辑就介绍到这里了,我们再次回成 CacheingExecutor 的查询方法: CachingExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameterObject, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql)
throws SQLException {
Cache cache = ms.getCache(); // @1
if (cache != null) {
flushCacheIfRequired(ms); // @2
if (ms.isUseCache() && resultHandler == null) {
ensureNoOutParams(ms, boundSql);
@SuppressWarnings("unchecked")
List<E> list = (List<E>) tcm.getObject(cache, key); // @3
if (list == null) { // @4
list = delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); //@5
tcm.putObject(cache, key, list); // issue #578 and #116 // @6
}
return list;
}
}
return delegate.<E> query(ms, parameterObject, rowBounds, resultHandler, key, boundSql); //@7
}
复制代码
如果 MappedStatement 的 cache 属性为空,则直接调用内部的 Executor 的查询方法。也就时如果在 *.Mapper.xm l文件中未定义< cache/>或< cacheRef/>,则 cache 属性会为空。
1.2.2 一级缓存
Mybatis 根据 SQL 的类型共有如下3种 Executor类型,分别是 SIMPLE, REUSE, BATCH,本文将以 SimpleExecutor为 例来对一级缓存的介绍。
BaseExecutor#query
public <E> List<E> query(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing a query").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
if (queryStack == 0 && ms.isFlushCacheRequired()) { // @1
clearLocalCache();
}
List<E> list;
try {
queryStack++;
list = resultHandler == null ? (List<E>) localCache.getObject(key) : null; // @2
if (list != null) {
handleLocallyCachedOutputParameters(ms, key, parameter, boundSql);
} else {
list = queryFromDatabase(ms, parameter, rowBounds, resultHandler, key, boundSql); // @3
}
} finally {
queryStack--;
}
if (queryStack == 0) {
for (DeferredLoad deferredLoad : deferredLoads) {
deferredLoad.load();
}
// issue #601
deferredLoads.clear();
if (configuration.getLocalCacheScope() == LocalCacheScope.STATEMENT) {
// issue #482
clearLocalCache();
}
}
return list;
}
复制代码
代码@1:queryStack:查询栈,每次查询之前,加一,查询返回结果后减一,如果为1,表示整个会会话中没有执行的查询语句,并根据 MappedStatement 是否需要执行清除缓存,如果是查询类的请求,无需清除缓存,如果是更新类操作的MappedStatemt,每次执行之前都需要清除缓存。 代码@2:如果缓存中存在,直接返回缓存中的数据。 代码@3:如果缓存未命中,则调用 queryFromDatabase 从数据中查询。
我们顺便看一下 queryFromDatabase 方法,再来看一下一级缓存的实现类。
private <E> List<E> queryFromDatabase(MappedStatement ms, Object parameter, RowBounds rowBounds, ResultHandler resultHandler, CacheKey key, BoundSql boundSql) throws SQLException {
List<E> list;
localCache.putObject(key, EXECUTION_PLACEHOLDER); //@!
try {
list = doQuery(ms, parameter, rowBounds, resultHandler, boundSql); // @2
} finally {
localCache.removeObject(key); // @3
}
localCache.putObject(key, list); // @4
if (ms.getStatementType() == StatementType.CALLABLE) {
localOutputParameterCache.putObject(key, parameter);
}
return list;
}
复制代码
代码@1:先往本地遍历存储一个厂里,表示正在执行中。 代码@2:从数据中查询数据。 代码@3:先移除正在执行中的标记。 代码@4:将数据库中的值存储到一级缓存中。
可以看出一级缓存的属性为 localCache,为 Executor 的属性。如果大家看过笔者发布的这个 Mybatis 系列就能轻易得出一个结论,每一个 SQL 会话对应一个 SqlSession 对象,每一个 SqlSession 会对应一个 Executor 对象,故 Executor 级别的缓存即为Session 级别的缓存,即为 Mybatis 的一级缓存。
上面已经介绍了一二级缓存的查找与添加,在查询的时候,首先查询缓存,如果缓存未命中,则查询数据库,然后将查询到的结果存入缓存中。
下面我们来简单看看缓存的更新。
2、从SQL更新流程看一二级缓存
从更新的角度,更加的是关注缓存的更新,即当数据发生变化后,如果清除对应的缓存。
2.1 二级缓存
CachingExecutor#update
public int update(MappedStatement ms, Object parameterObject) throws SQLException {
flushCacheIfRequired(ms); // @1
return delegate.update(ms, parameterObject); // @2
}
复制代码
代码@1:如果有必要则刷新缓存。 代码@2:调用内部的 Executor,例如 SimpleExecutor。
接下来重点看一下 flushCacheIfRequired 方法。
private void flushCacheIfRequired(MappedStatement ms) {
Cache cache = ms.getCache();
if (cache != null && ms.isFlushCacheRequired()) {
tcm.clear(cache);
}
}
TransactionalCacheManager#clear
public void clear(Cache cache) {
getTransactionalCache(cache).clear();
}
复制代码
TransactionalCacheManager 事务缓存管理器,其实就是对 MappedStatement 的 cache 属性进行装饰,最终调用的还是MappedStatement 的 getCache 方法得到其缓存对象然后调用 clear 方法,清空所有的缓存,即缓存的更新策略是只要namespace 的任何一条插入或更新语句执行,整个 namespace 的缓存数据将全部清空。
2.2 一级缓存的更新
public int update(MappedStatement ms, Object parameter) throws SQLException {
ErrorContext.instance().resource(ms.getResource()).activity("executing an update").object(ms.getId());
if (closed) {
throw new ExecutorException("Executor was closed.");
}
clearLocalCache();
return doUpdate(ms, parameter);
}
复制代码
其更新策略与二级缓存维护的一样。
一二级缓存的的新增、查询、更新就介绍到这里了,接下来对其进行一个总结。
3、总结
3.1 一二级缓存作用序列图
Mybatis 一二级缓存时序图如下:

3.2 如何使用二级缓存
1、在mybatis-config.xml中将cacheEnable设置为true。例如:
<configuration> <settings> <setting name="cacheEnabled" value="true"> </settings> </configuration> 复制代码
不过该值默认为true。
2、在需要缓存的表操作,对应的 Dao 的配置文件中,例如 *Mapper.xml 文件中使用 cache、或 cacheRef 标签来定义缓存。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.winterchen.dao.UserDao" >
<insert id="insert" parameterType="com.winterchen.model.UserDomain">
//省略
</insert>
<select id="selectUsers" resultType="com.winterchen.model.UserDomain">
//省略
</select>
<cache type="lru" readOnly="true" flushInterval="3600000"></cache>
</mapper>
复制代码
这样就定义了一个 Cache,其 namespace 为 com.winterchen.dao.UserDao。其中 flushInterval 定义该 cache 定时清除的时间间隔,单位为 ms。
如果一个表的更新操作、新增操作位于不同的 Mapper.xml 文件中,如果对一个表的操作的 Cache 定义在不同的文件,则缓存数据则会出现不一致的情况,因为 Cache 的更新逻辑是,在一个 Namespace 中,如果有更新、插入语句的执行,则会清除该 namespace 对应的 cache 里面的所有缓存。那怎么来处理这种场景呢?cacheRef 闪亮登场。
如果一个 Mapper.xml 文件需要引入定义在别的 Mapper.xml 文件中定义的 cache,则使用 cacheRef,示例如下:
<cacheRef "namespace" = "com.winterchen.dao.UserDao"/> 复制代码
一级缓存默认是开启的,也无法关闭。
缓存的介绍就介绍到这里。如果本文对您有所帮助,麻烦点一下赞,谢谢。
作者介绍:《RocketMQ技术内幕》作者,维护公众号: 中间件兴趣圈 ,目前主要发表了源码阅读java集合、JUC(java并发包)、Netty、ElasticJob、Mycat、Dubbo、RocketMQ、mybaits等系列源码。

如果期望加入高质量的技术交流圈,可以加入 知识兴趣:一个高质量交流社群 。
正文到此结束
- 本文标签: http 管理 sqlsession Select id 源码 final map Property CTO 二级缓存 list Proxy https src NSA SQL执行 DOM Java集合 update mybatis缓存 sql Job 时间 executor value Statement 质量 build 数据 mapper 遍历 MQ 参数 java cat 文章 代码 cache key session node dubbo UI ORM 解析 IO 分页 并发 数据库 ACE Netty plugin XML RocketMQ tab 总结 配置 Action App 一级缓存 mybatis 缓存
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

