羞!扒开字节码,我竟发现这个.....
作为一名安卓开发者,我们可以以多年单身的手速光速的撸一个java文件。但相信很多人对java的了解就像了解女神,只看到光鲜的外表。但往往有时候我们应该看看她卸了妆的样子,脱了....,咳咳。总之我们应该深入的了解,这样可以帮助我们做很多有意思的事情。
最近接触了asm这个框架,这个框架有多骚?他能够很方便的修改class字节码文件,在字节码中插入我们自己的代码。实现例如我们安卓的无痕埋点、字符串加密、方法时间统计等骚操作。
所以本文主要通过卸了java字节码的妆,看看虚拟机眼里最真实的class文件。本文内容较长,但相信大家耐心慢慢读,其实并不难,阅读起来也会比较流畅,当然收获也是慢慢。
卸了java文件的妆
java字节码文件以 .class 结尾,是java编译器编译我们平时写的 .java 文件生成的。我们可以通过命令:
//编译java文件为class文件 javac xxx.java 复制代码
通过命令行编译后,我们会得到一个8位字节的二进制文件,二进制流文件中各个部分以一定的规则紧密的前后排列,相邻项之间没有间隙。这样的好处是可以使class文件更加紧凑和小,方便在jvm虚拟机中加载和网络传输。
我们编写一个名为 Math.java 的java源文件,让我们先初识一下class文件。
//Math.java
package com.getui.test;
public class Math {
private int a = 1;
private int b = 2;
public int add(){
return a+b;
}
}
复制代码
执行命令:
javac Math.java 复制代码
编译后我们会得到一份 Math.class 文件,我们使用010Editor(一款十六进制文件查看和编辑神器)打开 Math.class 文件。
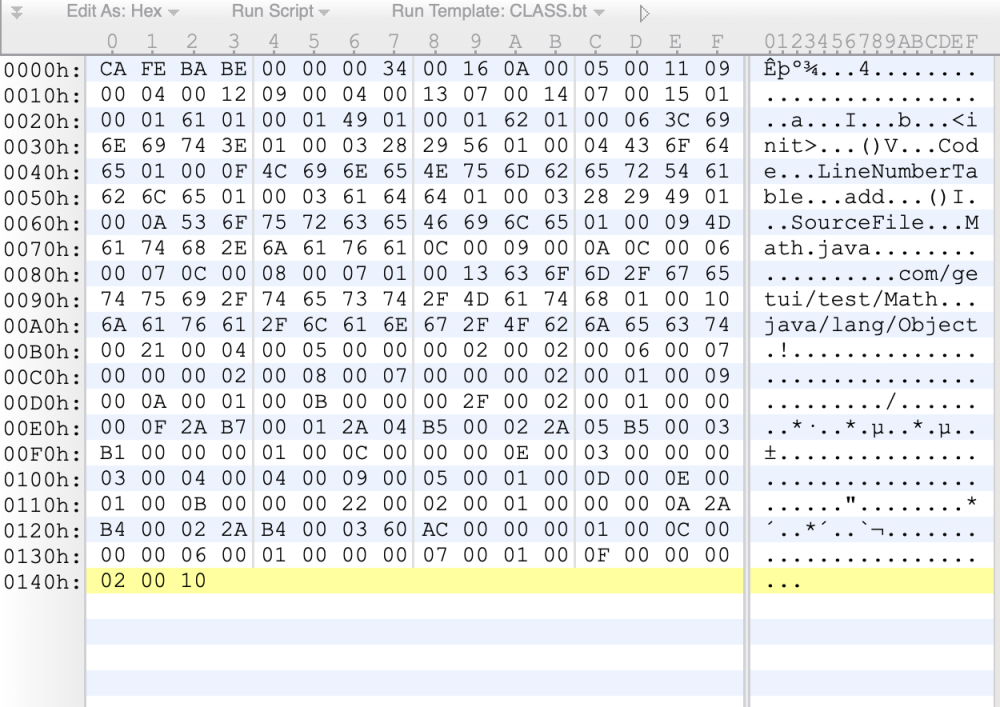
我们可以从上图看到class字节码的内容,这就是java卸了妆后的样子。是不是很美?
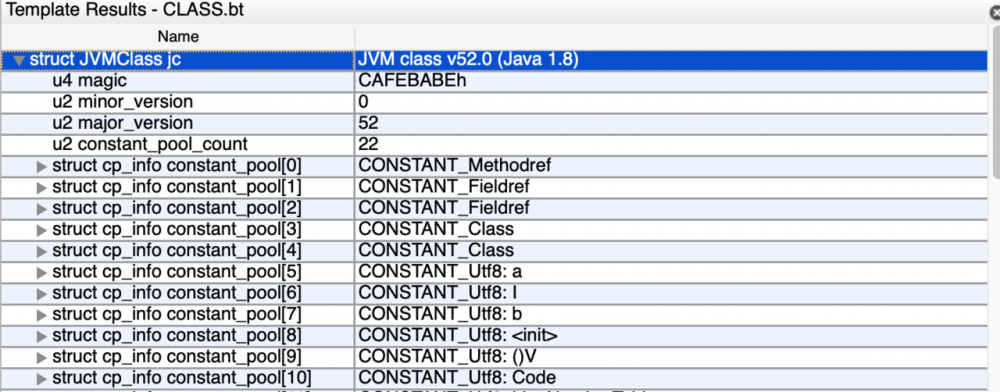
010Editor也将我们把class字节码文件按照一定的格式,依次解析成了不同的数据项。
整体审视class文件的结构
一个class文件包含以下数据项:
| 描述 | 类型 | 解释 |
|---|---|---|
| magic | u4 | 魔数,固定:0x CAFE BABE |
| minor_version | u2 | java次版本号 |
| major_version | u2 | java主版本号 |
| constant_pool_count | u2 | 常量池大小 |
| constant_pool[constant_pool_count-1] | cp_info(常量表) | 字符串池 |
| access_flags | u2 | 访问标志 |
| this_class | u2 | 类索引 |
| super_class | u2 | 父类索引 |
| interfaces_count | u2 | 接口计数器 |
| interfaces | u2 | 接口索引集合 |
| fields_count | u2 | 字段个数 |
| fields | field_info(字段表) | 字段集合 |
| methods_count | u2 | 方法计数器 |
| methods | method_info(方法表) | 方法集合 |
| attributes_count | u2 | 属性计数器 |
| attributes | attribute_info(属性表) | 属性集合 |
上面这个表格是一个字节码结构表,其中u1、u2、u4、u8是无符号数,它们分别代表1个字节、2个字节、4个字节、8个字节;其中cp_info、field_info、method_info、attribute_info分别代表了常量表、字段表、方法表和属性表。每一个表又具有自己独特的结构,这会在之后一一介绍。
有了整体的结构,我们就按这个class字节码的结构从头到脚开始一一介绍。
局部审视class文件结构
魔数(magic)

魔数的类型为u4,所以占据class文件的4个字节。魔数是用来标识文件类型的一个标志,而class字节码文件的魔数固定是0xCAFE BABE。至于为什么是0xCAFE BABE开头?看下面这个图你就懂了。

版本号(minor_version+major_version)

minor_version的类型为u2,占据class文件的2个字节,所以0x00 00代表了编译.java文件的java次版本为0。
major_version的类型也为u2,占据class文件的2个字节,所以0x00 34,16进制的0x34转换为10进制为52,而JDK1.2版本对应着十进制是46,所以52代表的JDK版本就是1.8版本啦。
结合上面分析,我掐指再一算,当前的JDK版本为1.8.0版本。
我们可以通过命令行进行验证:
java -version java version "1.8.0_112" Java(TM) SE Runtime Environment (build 1.8.0_112-b16) Java HotSpot(TM) 64-Bit Server VM (build 25.112-b16, mixed mode) 复制代码
常量池大小(constant_pool_count)

常量池大小的类型也是u2,占据class文件的2个字节,0x00 16,16进制的0x16转换为10进制为22,则代表了我们常量池的大小为22-1=21个。常量池就像我们class字节码的仓库,存放了对这个类的信息描述,例如类名、字段名、方法名、常量值、字符串等。具体的内容我们会在下一个部分常量池中阐述。
我们可以通过命令行,更加简单的查看常量池中的内容:
javap -verbose ./Math.class 复制代码
输入命令后会输出很多关于Math.class字节码的内容,但我们目前就聚焦到Constant pool这一块:
Constant pool: #1 = Methodref #5.#17 // java/lang/Object."<init>":()V #2 = Fieldref #4.#18 // com/getui/test/Math.a:I #3 = Fieldref #4.#19 // com/getui/test/Math.b:I #4 = Class #20 // com/getui/test/Math #5 = Class #21 // java/lang/Object #6 = Utf8 a #7 = Utf8 I #8 = Utf8 b #9 = Utf8 <init> #10 = Utf8 ()V #11 = Utf8 Code #12 = Utf8 LineNumberTable #13 = Utf8 add #14 = Utf8 ()I #15 = Utf8 SourceFile #16 = Utf8 Math.java #17 = NameAndType #9:#10 // "<init>":()V #18 = NameAndType #6:#7 // a:I #19 = NameAndType #8:#7 // b:I #20 = Utf8 com/getui/test/Math #21 = Utf8 java/lang/Object 复制代码
这里我们可以看到,这里的Constant pool好像有点眼熟,都是我们java中写的部分代码,但又觉得怪怪的。这里先不管,之后在介绍cp_info的时候会具体介绍。我们先留一个大概印象就好了。

这里还有一个问题,还没有解决,常量池的大小为什么需要减1,例如我们0x16的十六进制转换为十进制是22,为什么说常量池大小为22-1=21个?我们写代码时,数组下标都是从0开始,而我们看到上面命令行展示的内容,Constant pool是从1开始,它将第0项的常量空出来了。而这个第0项常量它具备着特殊的使命,就是当其他数据项引用第0项常量的时候,就代表着这个数据项不需要任何常量引用的意思。
cp_info(常量表)
cp_info主要存放字面量和符号引用。
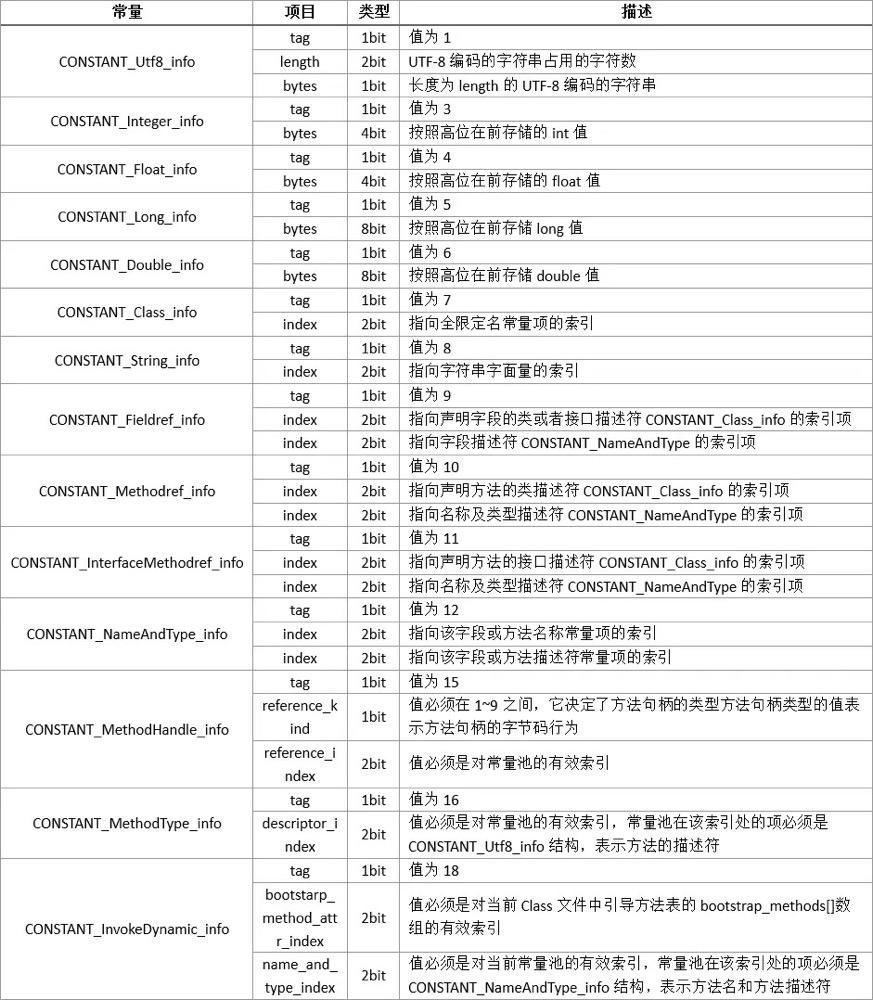
它主要包含以下14种类型:
| 类型 | 标志 | 描述 |
|---|---|---|
| CONSTANT_utf8_info | 1 | UTF-8编码的字符串 |
| CONSTANT_Integer_info | 3 | 整形字面量 |
| CONSTANT_Float_info | 4 | 浮点型字面量 |
| CONSTANT_Long_info | 5 | 长整型字面量 |
| CONSTANT_Double_info | 6 | 双精度浮点型字面量 |
| CONSTANT_Class_info | 7 | 类或接口的符号引用 |
| CONSTANT_String_info | 8 | 字符串类型字面量 |
| CONSTANT_Fieldref_info | 9 | 字段的符号引用 |
| CONSTANT_Methodref_info | 10 | 类中方法的符号引用 |
| CONSTANT_InterfaceMethodref_info | 11 | 接口中方法的符号引用 |
| CONSTANT_NameAndType_info | 12 | 字段或方法的符号引用 |
| CONSTANT_MethodHandle_info | 15 | 表示方法句柄 |
| CONSTANT_MothodType_info | 16 | 标志方法类型 |
| CONSTANT_InvokeDynamic_info | 18 | 表示一个动态方法调用点 |
其中每个类型的结构又不尽相同,大家可以查看下面这个表格:
接下来让我们开始解析字节码的常量部分:
CONSTANT_Methodref_info{
u1 tag;
u2 class_index;
u2 name_and_type_index;
}
复制代码
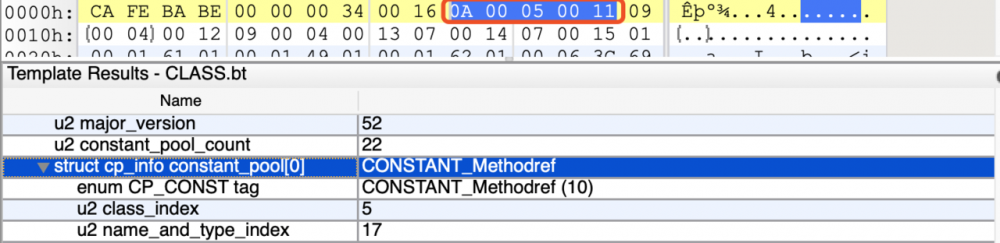
我们开始分析第1个常量,我们看到常量的 tag 的值等于0x0A,转换为十进制为10,对照上面的第一个表,我们可以得到这个常量类型为 CONSTANT_Methodref_info ,接着往下看,对照第二个表 CONSTANT_Methodref_info 还有2个部分的索引值,第一个是 Constant_Class_Info 的值,它占2个字节,所以它的值是0x00 05,转化为十进制为5。接下来我们看看第五个常量的16进制。

CONSTANT_Class_info{
u1 tag;
u2 name_index;
}
复制代码
第5个常量的 tag 为0x07,转换为十进制为7,对照第一个表,我们可以得到这个常量类型为 CONSTANT_Class_info ,接下来按照基本套路往下看,我们对照第二个表 CONSTANT_Class_info 剩下部分的2个直接指向全限定名常量项的索引0x00 14,转换为十进制为21。接下来我们继续看一下第21个常量卖的是什么瓜。

CONSTANT_utf8_info{
u1 tag;
u2 length;
length bytes[];
}
复制代码
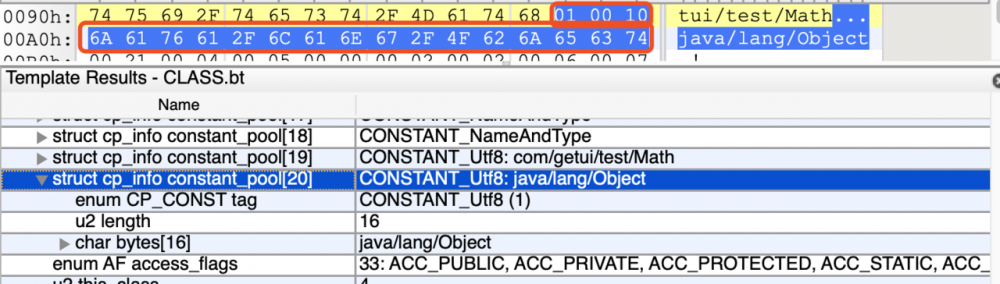
我们可以看到第21个常量的 tag 为0x01,转换为十进制为1,对照第一个表,我们可以得到这个常量类型为 CONSTANT_utf8_info ,接下来按照国际惯例和基本套路,我们继续对照第二个表,我们可以知道 CONSTANT_utf8_info 的第二个部分占2个字节,即0x00 10,转换为十进制为16,则代表着接下来有长度为16的UTF-8编码字符串;接下来第三部分为长度为16个字节,即0x6A 61 76 61 2F 6C 61 6E 67 2F 4F 62 6A 65 63 74,代表着字符串为java/lang/Object。这个java/lang/Object就是一个 全限定名 ,全限定名就是基本类型除外的类,将它的包名中的 . 换成 / 。
很好,我们的革命成功了一半,还记得我们分析第一个常量的时候,我们只分析到第二部分吗?第三部分占两个字节,指向名称及类型描述符 CONSTANT_NameAndType 的索引,它的值是0x00 11(忘记了的朋友可以往上翻看第1个常量解析的图片),转换为十进制为17,所以我们查看第17个常量。
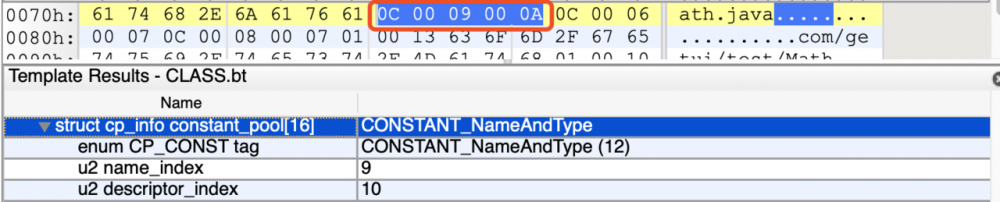
我们查看前一个字节 tag 为0C,转换为十进制为12,代表了 CONSTANT_NameAndType_info 类型,废话不多说,查看第二个表格,第二个部分占2个字节,指向该方法或字段名称常量项的索引,其值为0x00 09,转换为十进制为9,我们直接查看第9个常量。
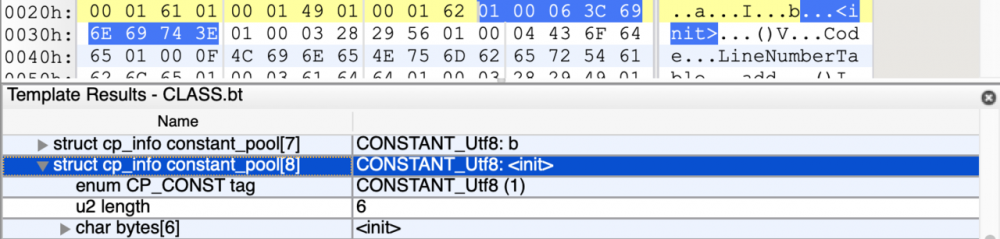
依旧是一个 CONSTANT_utf8_info 类型,其结构我就不再多述,小伙伴自己尝试着分析试试。
经过解析我们可以知道它是一个长度为6的UTF-8编码字符串,其值为 <init> 。
接着分析 CONSTANT_NameAndType 的第三部分,占用两个字节,指向其字段或方法描述符的常量索引,其值为0x00 0A,转换为十进制为10;查看第10个常量。

还是一个 CONSTANT_utf8_info 类型,其结构的意义是长度为3的UTF编码字符串,其值为 ()V 。
哎,这个值好像看着有点怪怪的。 ()V 是啥东东。
这里就要介绍一下描述符的含义了。描述符的作用是用来描述字段的数据类型、方法的参数列表(包括数量、类型以及顺序)和返回值。根据描述符规则,基本数据类型(byte、char、double、float、int、long、short、boolean)以及代表无返回值的void类型都用一个大写字符来表示,而对象类型则用字符L加对象的全限定名来表示,参考下表:
| 标志符 | 含义 |
|---|---|
| B | 基本数据类型byte |
| C | 基本数据类型char |
| D | 基本数据类型double |
| F | 基本数据类型float |
| I | 基本数据类型int |
| J | 基本数据类型long |
| S | 基本数据类型short |
| Z | 基本数据类型boolean |
| V | 基本数据类型void |
| L | 对象类型,如Ljava/lang/Object |
对于数组来说,我们对每一维度通过在类型前加 [ 来表示,例如一个 int[] 数组,我们会通过 [I 表示,比如一个二位数组 java.lang.Object[][] ,则用 [[Ljava/lang/Object; 表示。
对于 ()V 中的 () 则表示方法的参数列表,其中的 V 代表返回值Void,我们知道我们java中定义一个类,没有定义构造函数的时候,Java会自动帮我们生成一个无参构造函数。由于是无参构造函数,且返回值是Void,所以表示为 ()V 。
例如我们 public void add(int a, int b) ,则表示为 (II)V 。在例如 public String getContent(int type) 则表示为 (I)Ljava/lang/Object 。
好的,介绍了这么久,我们其实直接介绍了常量池中的一个常量。
Constant pool: //我们只介绍了下面#1这个常量 #1 = Methodref #5.#17 // java/lang/Object."<init>":()V #2 = Fieldref #4.#18 // com/getui/test/Math.a:I #3 = Fieldref #4.#19 // com/getui/test/Math.b:I #4 = Class #20 // com/getui/test/Math #5 = Class #21 // java/lang/Object #6 = Utf8 a #7 = Utf8 I #8 = Utf8 b #9 = Utf8 <init> #10 = Utf8 ()V #11 = Utf8 Code #12 = Utf8 LineNumberTable #13 = Utf8 add #14 = Utf8 ()I #15 = Utf8 SourceFile #16 = Utf8 Math.java #17 = NameAndType #9:#10 // "<init>":()V #18 = NameAndType #6:#7 // a:I #19 = NameAndType #8:#7 // b:I #20 = Utf8 com/getui/test/Math #21 = Utf8 java/lang/Object 复制代码

为了把一个常量说明白,不知不觉说了这么多。剩余的常量我相信小伙伴们应该具备举一反三的能力了。其实更多的时间我们不需要这样一个一个解析字节码,之所以这样带着大家解析,只是为了让大家感受字节码的魅力和常量的结构。更多时候,我们通过之前说的命令,一行搞定。
javap -verbose ./Math.class 复制代码
访问标示

访问标示占据2个字节,访问标示表示类或者接口的访问信息。标示信息对应如下:
| 标志名称 | 十六进制标志值 | 二进制 标记值 | 含义 |
|---|---|---|---|
| ACC_PUBLIC | 0x0001 | 1 | 是否为Public类型 |
| ACC_FINAL | 0x0010 | 10000 | 是否被声明为final,只有类可以设置 |
| ACC_SUPER | 0x0020 | 100000 | 是否允许使用invokespecial字节码指令的新语义,JDK1.0.2之后编译出来的类的这个标志默认为真 |
| ACC_INTERFACE | 0x0200 | 1000000000 | 标志这是一个接口 |
| ACC_ABSTRACT | 0x0400 | 10000000000 | 是否为abstract类型,对于接口或者抽象类来说,此标志值为真,其他类型为假 |
| ACC_SYNTHETIC | 0x1000 | 1000000000000 | 标志这个类并非由用户代码产生 |
| ACC_ANNOTATION | 0x2000 | 10000000000000 | 标志这是一个注解 |
| ACC_ENUM | 0x4000 | 100000000000000 | 标志这是一个枚举 |
我们知道我们的类是一个 public 修饰的类,其十六进制值为0x00 21,所以我们可以参照十六进制的表格,得出其为 ACC_SUPER + ACC_PUBLIC 。
但是如果我们只想判断这个类是不是存在某个标示,我们应该如何判断呢,比如我们只想判断是否这个类是否被 ACC_PUBLIC 修饰,通过二进制的列我们可以看出,每个标识符在某一位的值为1,我们可以通过这个标识符的二进制与要判断的这个标识符取与操作即可判断这个标识符是否被某标示符修饰。例如:
0x21的二进制为:100001,ACC_PUBLIC的二进制为:1,100001&1的结果为1。所以我们可以判断这个类包含 ACC_PUBLIC 访问标识符。
类索引

类索引占用2个字节,指向该类的 CONSTANT_Class 常量,其值为0x00 04,转换为十进制为4,及第四个常量。
#4 = Class #20 // com/getui/test/Math 复制代码
我们可以看到类索引指向了该类的全限定名。
父类索引

父类索引占有2个字节,指向该类的父类,其值为0x00 05,转换为十进制为5,及第五个常量。
#5 = Class #21 // java/lang/Object 复制代码
我们的Math类没有继承任何类,所以其默认的父类是Object类。
接口计数器

接口计数器表示该类实现了几个接口,即 implements 了几个接口。由于我们的Math没有实现接口,其值为0x00 00,转换为十进制也为0。
接口索引集合
接口索引集合是一个集合,包含了所有实现的接口的索引,每个接口索引占用2个字节,指向常量中的接口。
由于Math.java没有实现任何接口,所以不存在这部分的值。需要验证的小伙伴可以自己自定义一个类,实现几个接口进行验证。也是非常简单的。

字段个数
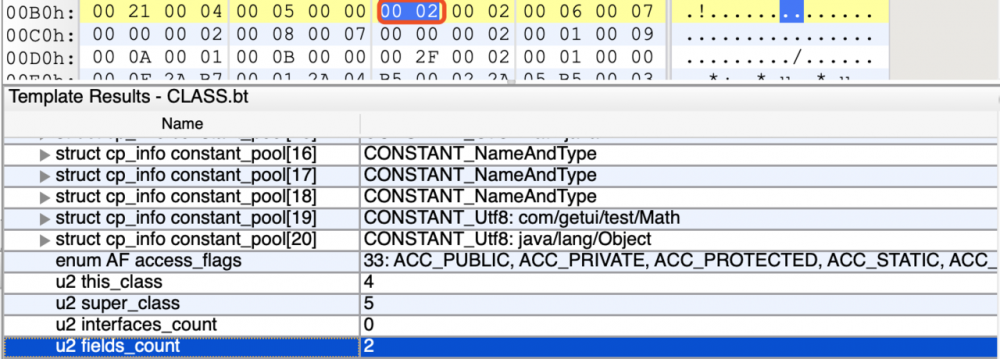
字段个数占2个字节,表示之后有多少个字段,字段主要用来描述类或者接口中声明的变量。这里的字段包含了类级别变量以及实例变量,但是不包括方法内部声明的局部变量。
我们看到字段个数的值为0x00 02,转换为十进制为2,即之后有2个字段。
field_info(字段表)
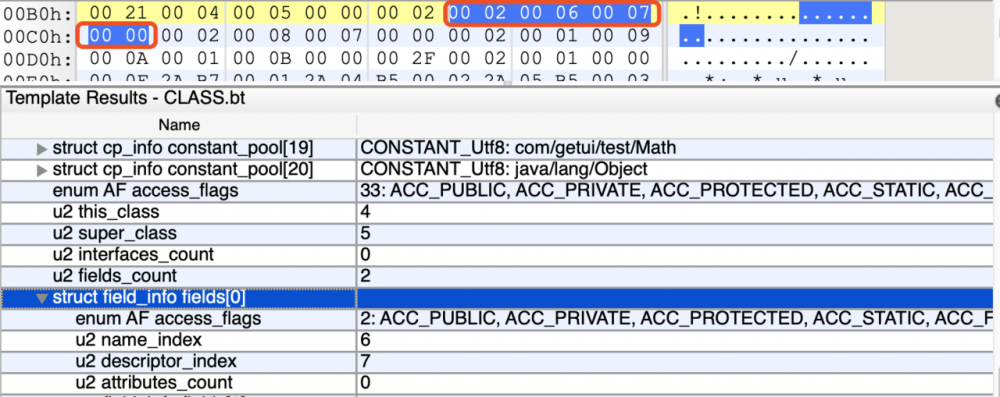
field_info{
u2 access_flags;//访问标志
u2 name_index;//字段名索引
u2 descriptor_index;//描述符索引
u2 attributes_count;//属性计数器
attribute_info attributes;//属性集合
}
复制代码
由于我们Math.java有两个字段,即 private int a = 1; 和 private int b = 2; ,我们这里只分析int a的字段。
| 标志名称 | 十六进制标志值 | 二进制标记值 | 含义 |
|---|---|---|---|
| ACC_PUBLIC | 0x0001 | 1 | 字段是否为public |
| ACC_PRIVATE | 0x0002 | 10 | 字段是否为private |
| ACC_PROTECTED | 0x0004 | 100 | 字段是否为protected |
| ACC_STATIC | 0x0008 | 1000 | 字段是否为static |
| ACC_FINAL | 0x0010 | 10000 | 字段是否为final |
| ACC_VOLATILE | 0x0040 | 1000000 | 字段是否为volatile |
| ACC_TRANSTENT | 0x0080 | 10000000 | 字段是否为transient |
| ACC_SYNCHETIC | 0x1000 | 1000000000000 | 字段是否为由编译器自动产生 |
| ACC_ENUM | 0x4000 | 100000000000000 | 字段是否为enum |
第一部分access_flags占2个字节,其值为0x00 02,转换为十进制为2,转化为二进制为10,我们可以对照上表,可以知道该字段的访问标志为 ACC_PRIVATE 即 private 。
第二部分name_index占2个字节,其值为0x 00 06,转换为十进制为6,我们直接在常量池中找到第6个常量
#6 = Utf8 a 复制代码
我们可以看到name_index的索引指向的就是a这个变量名。
第三部分descriptor_index占2个字节,其值为0x 00 07,转换为十进制为7,我们直接在常量池中找到第7个常量
#7 = Utf8 I 复制代码
我们可以看到descriptor_index的索引指向的就是a变量的类型, I 代表了int类型。
第四部分attributes_count占两个字节,其值为0x00 00,转换为十进制为0,则代表 private a =1; 没有属性集合。
如果第四部分的值不为0,则会存在attributes集合属性,有兴趣的小伙伴可以自行研究。
方法计数器
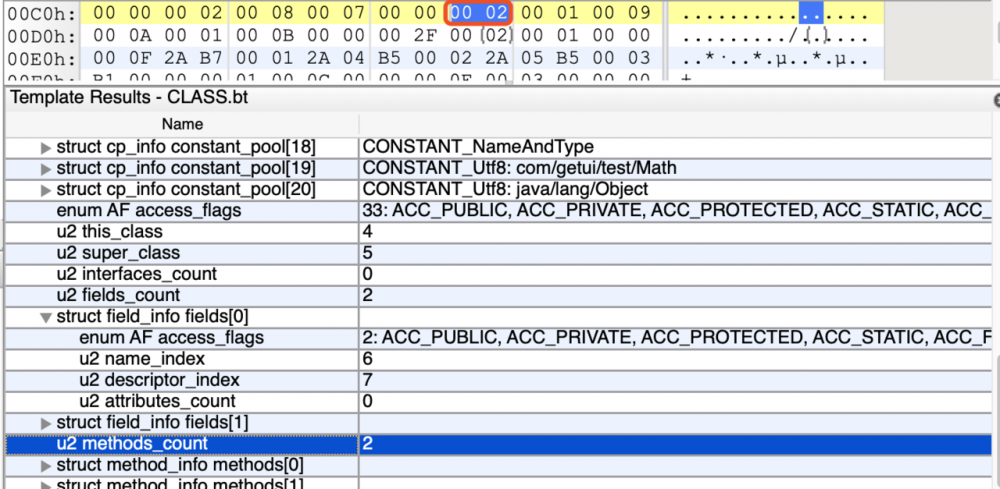
方法计数器占2个字节,表示后面有多少个方法。在这里我们的方法计数器的值为0x00 02,转换为十进制为2。
有的小伙伴可能会问,你不是只定义了一个 add 方法,为啥这边方法数为2?还记得吗?java在我们自定义类的时候,即使我们不实现任何一个构造函数的时候,java会默认替我们增加一个无参的构造函数。所以Math这个类具有 无参构造函数 和 add 这两个方法,所以方法计数器的值为2。
method_info(方法表)
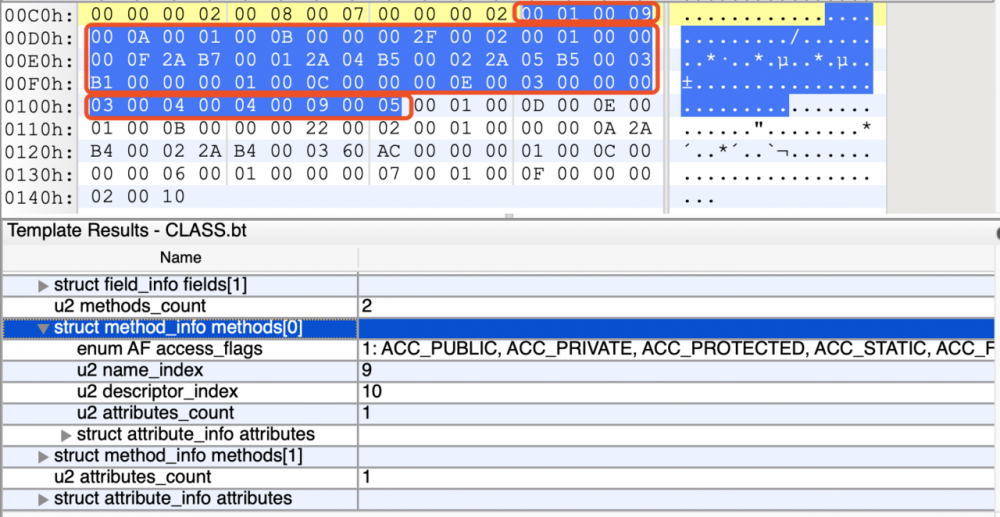
method_info{
u2 access_flags; //方法访问标志
u2 name_index; //方法名称索引
u2 descriptor_index; //方法描述符索引
u2 attributes_count; //属性计数器
struct attribute_info{
u2 attribute_name_index; //属性名的索引
u4 attribute_length; //属性的长度
attribute_length info[]
}
}
复制代码
| 标志名称 | 十六进制标志值 | 二进制标志值 | 含义 |
|---|---|---|---|
| ACC_PUBLIC | 0x0001 | 1 | 方法是否为public |
| ACC_PRIVATE | 0x0002 | 10 | 方法是否为private |
| ACC_PROTECTED | 0x0004 | 100 | 方法是否为protected |
| ACC_STATIC | 0x0008 | 1000 | 方法是否为static |
| ACC_FINAL | 0x0010 | 10000 | 方法是否为final |
| ACC_SYHCHRONRIZED | 0x0020 | 100000 | 方法是否为synchronized |
| ACC_BRIDGE | 0x0040 | 1000000 | 方法是否是有编译器产生的方法 |
| ACC_VARARGS | 0x0080 | 10000000 | 方法是否接受参数 |
| ACC_NATIVE | 0x0100 | 100000000 | 方法是否为native |
| ACC_ABSTRACT | 0x0400 | 10000000000 | 方法是否为abstract |
| ACC_STRICTFP | 0x0800 | 100000000000 | 方法是否为strictfp |
| ACC_SYNTHETIC | 0x1000 | 1000000000000 | 方法是否是有编译器自动产生的 |
我们来分析一下无参构造函数,首先我们先看第一部分,access_flags占2个字节,其值为0x00 01,转换为十进制为1,转换为二进制为1,参照上表,我们可以知道无参构造函数是被 ACC_PUBLIC 修饰,即 public 修饰。
第三部分descriptor_index占2个字节,其值为0x00 0A,转换为十进制为10,我们继续看常量池中第10个常量
#10 = Utf8 ()V 复制代码
descriptor_index代表了这个方法的描述,在前面已经解析过 ()V 的含义,它代表了该方法没有参数列表,并且返回值为Void。
第四部分attributes_count占2个字节,代表属性计数器,记录着该方法有几个属性。其值为0x00 01,转换为十进制为1,代表该方法具有一个属性,接着往下看。
该方法只有一个属性,所以只有一个attribute_info类型的属性。属性的结构第一部分attribute_name_index占用两个字节,其值为0x00 0B,转换为十进制为11。继续查找查找常量池
#11 = Utf8 Code 复制代码
这个方法名为code,代表着这个属性符合code属性表。
struct attribute_info{
u2 attribute_name_index; //属性名的索引
u4 attribute_length; //属性的长度
u2 max_stack;//操作数栈深度的最大值
u2 max_locals;//局部变量表所需的存续空间
u4 code_length;//字节码指令的长度
u1 code; //code_length个code,存储字节码指令
u2 exception_table_length;//异常表长度
exception_info exception_table;//exception_length个exception_info,组成异常表
u2 attributes_count;//属性集合计数器
attribute_info attributes;//attributes_count个attribute_info,组成属性表
}
复制代码
我们把code属性的十六进制字节码提取出来方便查看:
00 02 00 01 00 00 00 0A 2A B4 00 02 2A B4 00 03 60 AC 00 00 00 01 00 0C 00 00 00 06 00 01 00 00 00 07 复制代码
我们按照上面这个表格开读:

attribute_name_index的值0x00 0B我们已经分析过。
attribute_length占4个字符,其值为0x00 00 00 22,转换为十进制为34,代表后面的34个字节都是code属性部分。
max_stack占2个字节,其值为0x00 02,代表操作数栈最大深度为2。关于操作数栈相关的知识,读者可以手动谷歌。
max_locals占2个字节,其值0x00 01,代表局部变量表所需的连续空间为1。
code_length占4个字节,其值为0x00 00 00 0A,转换为十进制为10,代表后面的10个字节属于字节码指令集部分。
code占10个字节,0x2A B4 00 02 2A B4 00 03 60 AC,这可不是转换为十进制去看了,我们可以参考 这篇博客 对照其表格,把对应的十六进制转换为指令集。转换为指令集如下
2A->aload_0 B4->getfield 00->nop 02->对应常量池第二项 Field a:I 2A->aload_0 B4->getfield 00->nop 03->对应常量池第三项 Field b:I 60->iadd AC->ireturn 复制代码
对应的意思指令集意思可以对照上面的博客进行参考,有机会我也会整理一篇相关的博客。

有同学可能会说,你上面扯了一大堆,你怎么证明你解读就是对的,我不信,我不听,我不看。
好好好,其实我们通过命令行就可以得到验证:
javap -verbose ./Math.class
public int add();
descriptor: ()I
flags: ACC_PUBLIC
Code:
stack=2, locals=1, args_size=1
0: aload_0
1: getfield #2 // Field a:I
4: aload_0
5: getfield #3 // Field b:I
8: iadd
9: ireturn
LineNumberTable:
line 7: 0
复制代码
接下来我们继续分析(扯淡)
exception_table_length占2个字节,其值为0x00 00,转换为十进制为0;这里存放的是处理异常的信息。 每个exception_table表项由start_pc,end_pc,handler_pc,catch_type组成。start_pc和end_pc表示在code数组中的从start_pc到end_pc处(包含start_pc,不包含end_pc)的指令抛出的异常会由这个表项来处理;handler_pc表示处理异常的代码的开始处。catch_type表示会被处理的异常类型,它指向常量池里的一个异常类。当catch_type为0时,表示处理所有的异常,这个可以用来实现finally的功能。
由于我们这里的值是0,也就不展开介绍了,大家可以自行研究。
attributes_count占2个字节,其值为0x00 01,转化为十进制为1;表示有一个附加属性。
attribute_name_index占2个字节,其值为0x00 0C,转换为十进制为12;其含义是附加属性在常量池的位置,指向常量池的第12项,它的类型是LineNumberTable。其结构为:
LineNumberTable_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 line_number_table_length;
struct line_number_table{
u2 start_pc;
u2 line_number;
}
}
复制代码
attribute_length占4个字节,其值为0x00 00 00 06,表示后面长度6个字节为attribute。
line_number_table_length占2个字节,其值为0x00 01,转换为十进制为1,代表LineNumberTable有一项值。
start_pc占2个字节,其值0x00 00,转换为十进制为0,代表字节码行号。
line_number占2个字节,其值0x00 07,转换为十进制为7,代表java源码的行号为第7行。

附加属性
属性个数(attribute_count)
attribute_length占2个字节,其值为0x00 01,转换为十进制为1,代表后面有一项附加属性值。
属性结构(attribute_info_attributes)
SourceFile_attribute {
u2 attribute_name_index;
u4 attribute_length;
u2 sourcefile_index;
}
复制代码
attribute_name_index占2个字节,其值为0x 00 0F,转换为十进制为15,代表在常量池中第15项,查看15项可以得到是SourceFile,说明这个属性是Source。
attribute_length占4个字节,其值为0x00 00 00 02,转换为十进制为2,代表后面有2个字节为attribute的内容部分。
sourcefile_index占2个字节,其值为0x00 10,转换为十进制为16,代表在常量池中第16项,查看16项可以得到Math.java的值,代表着个class字节码文件的源码名为 Math.java 。
总结

javap
命令行就能够自动转换字节码的结构。
写这篇字节码,只是为了让大家对字节码有更深刻的印象和理解,也帮助我们以后能够更自信和熟练的使用类似ASM等字节码插桩框架。
熟练使用ASM字节码插桩框架,我们能够配合Gradle插件和注解开发出很多骚操作,例如无痕埋点统计、Java层字符串加密,再熟悉一点自己手撸一个类似Butterknife的框架等。
最后为大家奉献上010Editor的Mac破解版
链接: pan.baidu.com/s/1vTxPTSfJ… 提取码: pa8d
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

