Java最全锁剖析:独享锁/共享锁+公平锁/非公平锁+乐观锁/悲观锁
乐观锁 VS 悲观锁
乐观锁与悲观锁是一种广义上的概念,体现了看待线程同步的不同角度,在Java和数据库中都有此概念对应的实际应用。
1.乐观锁
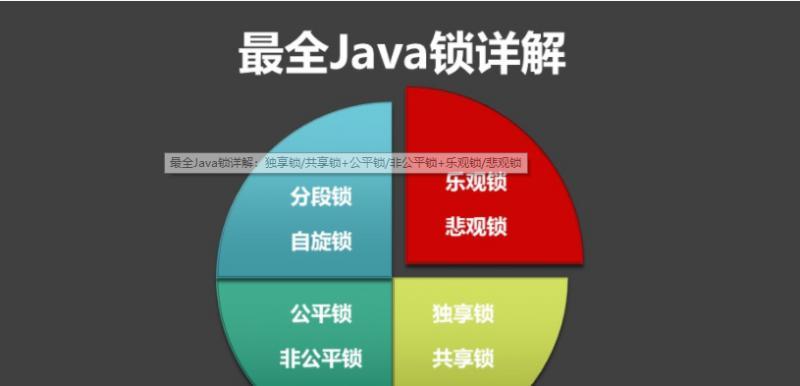
顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。
乐观锁适用于多读的应用类型,乐观锁在Java中是通过使用无锁编程来实现,最常采用的是CAS算法,Java原子类中的递增操作就通过CAS自旋实现的。
CAS全称 Compare And Swap(比较与交换),是一种无锁算法。在不使用锁(没有线程被阻塞)的情况下实现多线程之间的变量同步。java.util.concurrent包中的原子类就是通过CAS来实现了乐观锁。
简单来说,CAS算法有3个三个操作数:
- 需要读写的内存值 V。
- 进行比较的值 A。
- 要写入的新值 B。
当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则返回V。这是一种乐观锁的思路,它相信在它修改之前,没有其它线程去修改它;而 Synchronized是一种悲观锁,它认为在它修改之前,一定会有其它线程去修改它,悲观锁效率很低 。

2.悲观锁
总是假设最坏的情况,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会阻塞直到它拿到锁。
传统的MySQL关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
再比如上面提到的Java的同步synchronized关键字的实现就是典型的悲观锁。
3.总之:
- 悲观锁适合写操作多的场景 ,先加锁可以保证写操作时数据正确。
- 乐观锁适合读操作多的场景 ,不加锁的特点能够使其读操作的性能大幅提升。
公平锁 VS 非公平锁
1.公平锁
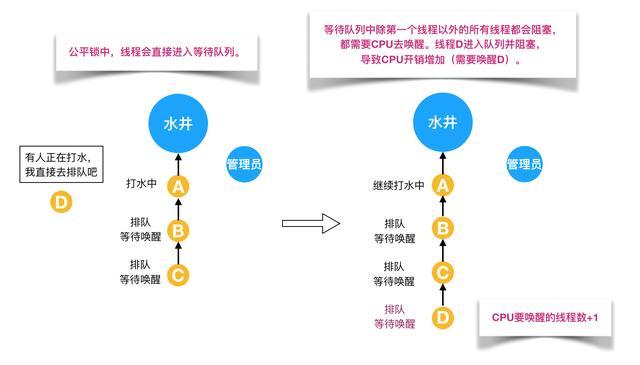
就是很公平,在并发环境中,每个线程在获取锁时会先查看此锁维护的等待队列,如果为空,或者当前线程是等待队列的第一个,就占有锁,否则就会加入到等待队列中,以后会按照FIFO的规则从队列中取到自己。
公平锁的优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
2.非公平锁
上来就直接尝试占有锁,如果尝试失败,就再采用类似公平锁那种方式。
非公平锁的优点是可以减少唤起线程的开销,整体的吞吐效率高,因为线程有几率不阻塞直接获得锁,CPU不必唤醒所有线程。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
3.典型应用:
java jdk并发包中的ReentrantLock可以指定构造函数的boolean类型来创建公平锁和非公平锁(默认),比如:公平锁可以使用new ReentrantLock(true)实现。
独享锁 VS 共享锁
1.独享锁
是指该锁一次只能被一个线程所持有。
2.共享锁
是指该锁可被多个线程所持有。
3.比较
对于Java ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。
读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。
独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。
4.AQS
抽象队列同步器(AbstractQueuedSynchronizer,简称AQS)是用来构建锁或者其他同步组件的基础框架,它使用一个整型的volatile变量(命名为state)来维护同步状态,通过内置的FIFO队列来完成资源获取线程的排队工作。

concurrent包的实现结构如上图所示,AQS、非阻塞数据结构和原子变量类等基础类都是基于volatile变量的读/写和CAS实现,而像Lock、同步器、阻塞队列、Executor和并发容器等高层类又是基于基础类实现。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。
我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。
当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。
但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。
分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

