一只爬虫(一)
免责的废话
本篇无标题,都说爬虫写得好,牢饭吃到饱,本来不想写爬虫的,毕竟风险有点高,但是作为一个搞搜索的人,怎么能不了解一下爬虫呢,怎么能不自己深入了解一下爬虫的原理呢,而且,知道了爬虫的一般性原理和一些开源的爬虫框架以后,写出一个自己的小爬虫并不是一件很难的事情,而一个自己的小爬虫,有时候还是很有用的,比如....又比如....,只要发挥你的想象,爬虫也能做很多事情。
当今的互联网世界,本质上是个数据的世界,谁掌握了数据谁就能独步天下,但是,对于我们这种互联网上小喽啰,数据肯定是不会来主动找我们为我们所用的,那么,如何更高效的获取你需要的数据,就变成了一门独立的职业---爬虫工程师(又称看守所预科班),接下来几篇文章,我们抛开这些商业行为,从纯技术的角度来说一说爬虫,这门和互联网一起诞生的古老技艺。
对于爬虫的历史,我们不做太多的介绍了,毕竟这些东西在网上一搜一大把,而且 这个系列文章也没有太多的爬虫技巧 ,毕竟我也不是来教你如何吃牢饭的,懂得太多的爬虫技巧,容易误入歧途走向万劫不复的深渊,这并不是我写这篇文章的初衷,同时,最重要的是, 因为我也不会爬虫的技巧,所以也没办法教你 。
为了让你有个对爬虫的整体了解,整个系列文章大概分为几个方面吧,一是爬虫的原理,这里会介绍一些爬虫最底层的数据结构和原理,然后第二部分是一个简单爬虫的架构和模块,这一篇会主要介绍一下要实现一个完整的爬虫需要哪些个模块,最后第三部分,我会基于Elasticsearch的插件实现一个简单的爬虫框架(放心,安全得狠,你拿去也没用),另外,我想安利一下Elasticsearch这个搜索引擎,如果你把他的搜索属性抛开,你会发现他可以做很多事情,比如这里就可以用来做爬虫,我还拿他做了缓存,消息队列等等。。
好了,闲话少说(MD已经说了这么多了),我们开始爬虫之旅吧。
基础的基础
说起爬虫的基础,其实只有两点:网页的下载和链接的遍历,几乎所有的资料跟你说的都是,一个爬虫都是从一批种子网页开始爬取,然后分析页面中的链接,再将链接再爬取一遍,如此反复,直到把整个互联网爬完,好像很简单,写代码出来不就是一个for循环里面一堆curl么。
我们从一个最简单的爬虫开始,一步一步升级我们的爬虫,通过一个一个的点,让他进化成一个分布式的,可自由扩展的爬虫。
丐中丐版
丐中丐版本没啥好说的,直接上代码:
import requests
content=requests.get("http://www.baidu.com")
print content
上面这三行做为丐中丐没问题吧,三行代码爬下百度,丐中丐版本没啥好说的,但这也是一个爬虫最核心的需求,就是爬下一个网页。从丐中丐版出发,我们解决一些问题以后,就可以变成一个比较强大的爬虫了,首先需要解决的就是如何遍历页面。
页面遍历
上面的丐中丐版本,只是一个页面,对于一个爬虫,我们需要解决的问题是,让爬虫可以一直运行下去,也就是可以获取到网页中的链接,这里就涉及到第一个爬虫相关的知识点,广度优先搜索和深度优先搜索。广度优先和深度优先是大学数据结构的基础内容,类似于树结构中的前序遍历,一般在搜索一个图的数据结构中使用这两种搜索算法,首先,我们简单介绍一下这两种搜索算法,整体上来说,深度优先就是压栈,弹栈,广度优先就是入队,出队。
深度优先搜索(DFS)
DFS就是尽可能的往深处遍历,直到遍历到没有节点了或者遇到已经遍历过的节点了,再返回到上一级,找到下一个节点,继续上面的过程。
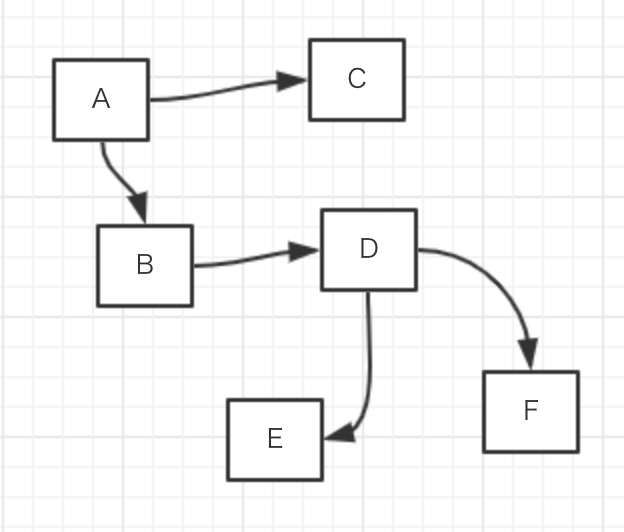
对于上面这个图来说,深度优先搜索的路径就是:A -- B -- D -- E -- F -- C
对于DFS来说,实现起来比较简单,每遍历到一个节点,就把这个节点压栈,然后再在这个节点上找一条路径继续遍历下一个节点,遍历到以后,再压栈,直到遍历到的节点没有路径可走了,这时候弹栈,找另外一条路径继续遍历,如此反复,这样的实现方式,如果图很复杂的话,栈很容易爆掉,而互联网这张用超链接连接起来的图,复杂性就不用多说了吧,所以对于爬虫来说,如果采用这样的方式进行遍历,一般会设置一个搜索深度,到达这个深度就不在搜索了,免得内存给爆了。
广度优先搜索(BFS)
BFS和深度优先不同的在于,每遍历到一个新的节点,先把和这个新节点相邻的节点遍历完,然后一个一个依次深入到下一个层级,继续上面的过程。

对于上图来说,广度优先搜索的路径就是: A -- B -- C -- D -- E -- F
对于BFS来说,实现起来也不是很复杂,一般都是使用队列的方式来实现,每遍历到一个节点,就把这个节点上的一级路径走一遍,找到相邻的所有节点,然后把这些节点压到队列里面去,每次从队列的头部取出节点出来,重复上面的过程,BFS比较好进行异步化和多线程的操作,通过设置队列的长度,也可以很好的控制内存,并且不会出现遍历不到的情况,所以一般使用这种搜索方法来爬取数据也比较常见。
页面优先级
在一个爬虫系统中,单使用广度优先算法或者单使用深度优先算法,实际上都不能达到很好的效果,因为有些网站是比较重要的,有些网站是一些歪瓜裂枣的网站,把流量耗费在这些歪瓜裂枣上,获取的数据也没什么价值,所以一般都会在把网页塞到队列的时候给一个优先级,优先级高的页面先爬取,带优先级的队列实现起来比较容易,因为这里的优先级并没有非常细的粒度,所以给几个不同优先级的队列,根据给定的不同优先级放入到不同的队列中,取数据的时候优先取最高优先级的那个队列就行了。
优先级队列和实现方法都有了,那优先级如何判定呢,这就是一个开放性的问题了,方法有很多种,比如,获取到一个待爬取的网页后,看一下这个网站的alax排名,排名高的优先级高,比如前100名的放到最高优先级里面,1000名的放到次优先级队列中,依次类推;又比如,通过自己的分析,如果是详情页面,优先级高,如果是列表类的页面,优先级低,这种在爬取某些特定的网站的时候可以用,比如你爬某些电商的搜索列表页,翻页的链接优先级可以低一点,各个详情页面可以高一点;总之,优先级的这一块和你爬取的实际情况是强相关的,具体如何打分就仁者见仁智者见智了。
总结
这一篇简单的介绍了一下爬虫的知识,爬虫涉及的方面非常广,任何一个小的方向都可以深挖不少,比如代理服务器部分就可以做不少东西出来,另外,现在内容都在各种阿啪啪上,如何优雅的模拟出手机去阿啪啪爬数据也是一个复杂的问题,有时候为了爬取出阿啪啪中的广告信息,还需要模拟出地理位置信息,不然广告出不来,而所有的这些,被爬取人也是知道的,他会用各种办法来防止你爬取他的数据,所以这也是一个斗智斗勇的工程,另外,特别需要注意的是,有些数据是不允许爬取的,比如涉及个人隐私的数据,有版权申明的数据,或者你把你爬取的数据拿出去卖,这些都得考虑法律问题。总之,从纯技术的角度上来说,爬虫还是很有意思也很有技术深度的,但使用爬虫的时候请想清楚,这些能爬吗?
如果你觉得不错,欢迎转发给更多人看到,也欢迎关注我的公众号,主要聊聊搜索,推荐,广告技术,还有瞎扯。。文章会在这里首先发出来:)扫描或者搜索微信号XJJ267或者搜索西加加语言就行

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

