logback官方文档阅读笔记:Logger(记录器)组件
前言
本文主要关于logback帐下大将Logger——记录器。
正文
Logger的生成和组织
chapter 2
Every single logger is attached to a LoggerContext which is responsible for manufacturing loggers as well as arranging them in a tree like hierarchy.
类 LoggerContext 负责生成 Logger 并将这些 Logger 组织在一个树状的结构中。
记录器的树状层次结构
chapter 2
Loggers are named entities. Their names are case-sensitive and they follow the hierarchical naming rule:
A logger is said to be an ancestor of another logger if its name followed by a dot is a prefix of the descendant logger name. A logger is said to be a parent of a child logger if there are no ancestors between itself and the descendant logger.
For example, the logger named "com.foo" is a parent of the logger named "com.foo.Bar" . Similarly, "java" is a parent of "java.util" and an ancestor of "java.util.Vector" . This naming scheme should be familiar to most developers.
The root logger resides at the top of the logger hierarchy. It is exceptional in that it is part of every hierarchy at its inception. Like every logger, it can be retrieved by its name, as follows:
Logger rootLogger = LoggerFactory.getLogger(org.slf4j.Logger.ROOT/_LOGGER/_NAME); ( org.slf4j.Logger.ROOT_LOGGER_NAME )
All other loggers are also retrieved with the class static getLogger method found in the org.slf4j.LoggerFactory class. This method takes the name of the desired logger as a parameter.
这里首先强调了记录器是有名字的,然后进一步讲明了上一节提到的 LoggerContext 将记录器安排在一个树状的层次结构中是怎么根据名字去做的。最后说了一下根记录器如何得到。
记录器的级别
chapter 2
Loggers may be assigned levels. The set of possible levels (TRACE, DEBUG, INFO, WARN and ERROR) are defined in the
ch.qos.logback.classic.Level class. Note that in logback, the
Level class is final and cannot be sub-classed, as a much more flexible approach exists in the form of
Marker
objects.
If a given logger is not assigned a level, then it inherits one from its closest ancestor with an assigned level. More formally:
The effective level for a given logger L , is equal to the first non-null level in its hierarchy, starting at L itself and proceeding upwards in the hierarchy towards the root logger.
To ensure that all loggers can eventually inherit a level, the root logger always has an assigned level. By default, this level is DEBUG.
本段说明 logback 会对记录器( Logger 类的实例)划分级别。如果没有特别指定,则会让其不断向父辈询问,直至遇到一个 non-null 级别的记录器后继承它的。为了确保一个没有指定级别的记录器一定会有级别,根记录器默认有 DEBUG 的级别并且级别不能置为 null。
其实写到这里仔细一想会觉得奇怪,我们前面接触到的例子,不都是一个 Logger 类实例 L 通过 L.info(...) 或者 L.debug(...) 啥的来记录日志么。不应该对消息分级,怎么对记录器分级了呢?
另外,记录器的级别要怎么设置,这里怎么没说呢?
继续阅读文档,能够回答这些问题。
消息的级别
chapter 2
Printing methods and the basic selection rule
By definition, the printing method determines the level of a logging request. For example, if L is a logger instance, then the statement L.info("..") is a logging statement of level INFO.
A logging request is said to be enabled_if its level is higher than or equal to the effective level of its logger. Otherwise, the request is said to be_disabled . As described previously, a logger without an assigned level will inherit one from its nearest ancestor. This rule is summarized below.
Basic Selection Rule:
A log request of level p issued to a logger having an effective level q, is enabled if p >= q.
This rule is at the heart of logback. It assumes that levels are ordered as follows: TRACE < DEBUG < INFO < WARN < ERROR .
解决了在之前看到的例子中 L.info("...") 这样好像消息本身才是被分级的,为何上一节说记录器被分级的疑惑。级别为q的记录器只会批准级别大于等于q的记录请求。
最后给出了日志等级的先后大小关系为 TRACE < DEBUG < INFO < WARN < ERROR 。
取得一个日志记录器
chapter 2
Calling the LoggerFactory.getLogger method with the same name will always return a reference to the exact same logger object.
For example, in
Logger x = LoggerFactory.getLogger("wombat");
Logger y = LoggerFactory.getLogger("wombat");
x and y refer to exactly the same logger object.
Thus, it is possible to configure a logger and then to retrieve the same instance somewhere else in the code without passing around references.
说明 LoggerFactory.getLogger(param) 中,一样的 param,返回得到的对象总是那一个。
Configuration of the logback environment is typically done at application initialization. The preferred way is by reading a configuration file. This approach will be discussed shortly.
指明配置日志记录器时的顺序不需要像传统生物学一样先有祖先再有子代。在运行时,完全可以先实例化一个小辈日志记录器,再实例化一个祖辈的日志记录器。
为日志记录器起名的推荐方式
chapter 2
Nevertheless, naming loggers after the class where they are located seems to be the best general strategy known so far.
推荐方式是:在哪个类使用,就使用哪个类的全限定名作为 LoggerFactory.getLogger(param) 的 param。
仔细思考会发现这个命名范式是很诡异的。如果按照此范式命名,如果某个类的日志记录器名为"a.b",那么不可能存在“a.b.c”的日志记录器,因为一个类不可能像一个包一样,里面装一个类。这样的话 logback 里的祖辈子辈日志记录器的结构被完全破坏,所谓树形结构也不复存在。
这个疑惑随着继续阅读文档会被解决,这里简单说一下。因为记录器的配置实际上并不是通过代码,而是通过xml文件的。这里 LoggerFactory.getLogger(param) 的直接写代码的用法,其实是用而不是配置——设置记录器等级,添加记录器拥有的输出起之类的。而在配置文件中,常常会以一个包的全限定路径为名去配置记录器。logback在读取配置文件时会实例化这样的记录器,同时我们又可能通过 LoggerFactory.getLogger(param) 的方法得到这个包下的记录器,这样两个记录器就构成了父子关系。同时,就像我们说的, LoggerFactory.getLogger(param) 只是在用而没有配置,实际上这里得到的记录器并没有拥有输出器,也就等同于即使记录请求被批准了,实际上也没有可输出的地方。真正的输出其实是通过可加性将消息传递到父级的,在xml文件中配置的,以包全限定路径(当然,你也可以用这个类的全限定路径,或者用一个aabb,然后 LoggerFactory.getLogger("aabb") )为名字的记录器,因为这个记录器在配置中指定了拥有的记录器,所以才能产生输出。
记录器的可加性(additivity)
chapter 2
The rules governing appender additivity are summarized below.
Appender Additivity:
The output of a log statement of logger L will go to all the appenders in L and its ancestors. This is the meaning of the term "appender additivity".
However, if an ancestor of logger L , say P , has the additivity flag set to false, then L 's output will be directed to all the appenders in L and its ancestors up to and including P but not the appenders in any of the ancestors of P .
Loggers have their additivity flag set to true by default.
Since the root logger stands at the top of the logger hierarchy, the additivity flag does not apply to it.
可加性是 Appender 的,但是设置的时候是设置 Logger 的,文档编撰者,做个人好吗?所以我这里直接改为的了记录器的可加性。因为前两段是很好想到的,记录器会把一个被批准的 记录请求 传给自己的所有输出器。
而记录器的可加性在于,默认情况下,记录器将会上传被它批准的消息给自己的祖辈们。祖辈们 不做审查地 将这则消息交给自己的所有输出器。向上传递消息的过程直到遇到一个可加性为false的记录器才得以停止,而那个记录器本身仍接受改消息。
用占位符的方式编写消息:使之更可读并避免资源浪费。
chapter 2
Parameterized logging
Given that loggers in logback-classic implement the SLF4J's Logger interface , certain printing methods admit more than one parameter. These printing method variants are mainly intended to improve performance while minimizing the impact on the readability of the code.
这里说日志记录器 Logger 的打印(输出)方法(所谓'certain printing methods',在超链接过去的API文档中搜索print,根本没有。结合下文才能反应过来,其实在日志系统或者说slf4j或者说logback中,所谓的print就是指 info(..) , debug(...) 这样的方法。)实现了SLF4J要求的可以接收处理多个参数的能力。这一能力可以提高性能并尽可能不破坏可读性,怎么回事呢,继续往下看。
For some Logger logger, writing,
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
incurs the cost of constructing the message parameter, that is converting both integer i and entry[i] to a String, and concatenating intermediate strings. This is regardless of whether the message will be logged or not.
One possible way to avoid the cost of parameter construction is by surrounding the log statement with a test. Here is an example.
if(logger.isDebugEnabled()) {
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));
}
This way you will not incur the cost of parameter construction if debugging is disabled for logger. On the other hand, if the logger is enabled for the DEBUG level, you will incur the cost of evaluating whether the logger is enabled or not, twice: once in debugEnabled and once in debug. In practice, this overhead is insignificant because evaluating a logger takes less than 1% of the time it takes to actually log a request.
Better alternative
There exists a convenient alternative based on message formats. Assuming entry is an object, you can write:
Object entry = new SomeObject();
logger.debug("The entry is {}.", entry);
Only after evaluating whether to log or not, and only if the decision is positive, will the logger implementation format the message and replace the '{}' pair with the string value of entry. In other words, this form does not incur the cost of parameter construction when the log statement is disabled.
The following two lines will yield the exact same output. However, in case of a disabled logging statement, the second variant will outperform the first variant by a factor of at least 30.
logger.debug("The new entry is "+entry+".");
logger.debug("The new entry is {}.", entry);
A two argument variant is also available. For example, you can write:
logger.debug("The new entry is {}. It replaces {}.", entry, oldEntry);
If three or more arguments need to be passed, an Object[] variant is also available. For example, you can write:
Object[] paramArray = {newVal, below, above};
logger.debug("Value {} was inserted between {} and {}.", paramArray);
实现方法就是采用占位符形式的输出: logger.debug("The new entry is {}.", entry) 。类比于C语言的 printf("the new try is %s",s) ,其中 {} 便与 %s `%d 这样的C语言中占位符功效相同。可以使用多个 {}`以对应要传入的多个参数,即“实现了SLF4J要求的可以接收处理多个参数的能力”,并且确实提高了可读性。
另外,我们已经讲过,一些记录请求的级别不够,会被记录器拒绝。而通过这种方式定义的消息,其会首先自查自己是否会被允许记录,只有在被允许的情况下才会进一步格式化组织为目标字符串。否则不会组织,这节省了资源。
注意,从这里往后所涉及的内容对应的官方文档内容,均是在已经引入了配置文件这一概念之后的内容了。即从现在开始,我们将在配置文件(一般为 logback.xml )中配置组件。而之后的内容也大多数是配置文件中对应 logger 的元素标签里该如何写的内容了。
配置 logger 的 appender
chapter 3
The <logger> element may contain zero or more <appender-ref> elements; each appender thus referenced is added to the named logger. Note that unlike log4j, logback-classic does not close nor remove any previously referenced appenders when configuring a given logger.
<appender-ref>怎么写其实没说明白。通过在文档中以'appender-ref'为关键词搜索,就得到的例子,可以推测其使用方式如图:
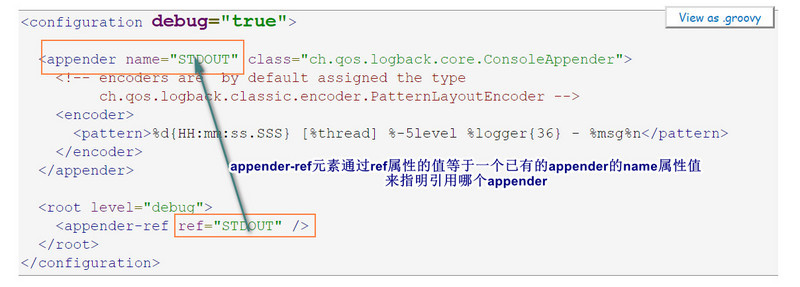
再过几节有几段文字再度谈及了logger引用appender。
配置根记录器
chapter 3
对应标题为“Configuring the root logger, or the <root> element”的整个小节。
The <root> element configures the root logger. It supports a single attribute, namely the level attribute. It does not allow any other attributes because the additivity flag does not apply to the root logger. Moreover, since the root logger is already named as "ROOT", it does not allow a name attribute either. The value of the level attribute can be one of the case-insensitive strings TRACE, DEBUG, INFO, WARN, ERROR, ALL or OFF. Note that the level of the root logger cannot be set to INHERITED or NULL.
注意 logback.xml 的基本结构, <root> 元素标签并不放在任一 <logger> 元素标签里,而是单独一个。
这里说 <root> 配置对应根记录器配置。这个元素标签只有唯一一个可配置的属性 level 。
记录请求是否被允许只由被直接调用的Logger审查
chapter 3
Logback will first determine whether a logging statement is enabled or not, and if enabled, it will invoke the appenders found in the logger hierarchy, regardless of their level.
这一段和我们之前的“记录器的可加性(additivity)”一节有呼应关系,在那一节的笔记里我们谈到:“记录器将会上传被它批准的消息给自己的祖辈们。祖辈们 不做审查地 将这则消息交给自己的所有输出器。“
这段官方文档则直接表明了这一规则。
logger使用示例:全部消息输出到控制台,特定的消息输出到文件。
chapter 3
Appender additivity is not intended as a trap for new users. It is quite a convenient logback feature. For instance, you can configure logging such that log messages appear on the console (for all loggers in the system) while messages only from some specific set of loggers flow into a specific appender.
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>myApp.log</file>
<encoder>
<pattern>%date %level [%thread] %logger{10} [%file:%line] %msg%n</pattern>
</encoder>
</appender>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<logger name="chapters.configuration">
<appender-ref ref="FILE" />
</logger>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>
In this example, the console appender will log all the messages (for all loggers in the system) whereas only logging requests originating from the chapters.configuration logger and its children will go into the myApp.log file.
这一段都不讲一下这个配置和什么样的代码连用,真实服气。不过连着读文档的话推测用文档中的 MyApp2 是比较合适的。
package chapters.configuration;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import ch.qos.logback.classic.LoggerContext;
import ch.qos.logback.core.util.StatusPrinter;
public class MyApp2 {
final static Logger logger = LoggerFactory.getLogger(MyApp2.class);
public static void main(String[] args) {
// assume SLF4J is bound to logback in the current environment
LoggerContext lc = (LoggerContext) LoggerFactory.getILoggerFactory();
// print logback's internal status
StatusPrinter.print(lc);
logger.info("Entering application.");
Foo foo = new Foo();
foo.doIt();
logger.info("Exiting application.");
}
}
package chapters.configuration;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class Foo {
static final Logger logger = LoggerFactory.getLogger(Foo.class);
public void doIt() {
logger.debug("Did it again!");
}
}
main 函数打头四行用来输出内部状态信息的不用管它。倒数四行应该就是对应本节 logback.xml 配置的实际动作了。 final static Logger logger = LoggerFactory.getLogger(MyApp2.class); 得到的 logger 的 name 应该是 chapters.configuration.MyApp2 。这个 logger 并没有配置任何输出器,所以它不会有任何输出。但因为记录器的累加性,在配置文件中被配置的 <logger name="chapters.configuration"> 生成的对应 logger 为它的父记录器,收到了它批准的记录请求,并交给了自己的输出器去完成,于是消息变成记录后保存到了文件。并且因为可加性继续向上传, <root level="debug"> 对应的根记录器也收到记录请求,而将其交给自己的输出器,于是记录被输出到控制台。与此同时,如果一个不在 chapters.configuration 包下的类调用了自己的 logger ,那么它只会有根元素的控制台输出的记录,而不会产生存储到文件里的记录。这就是引文第一句——Appender additivity is not intended as a trap for new users. It is quite a convenient logback feature. ——记录器的累加性并不是坑害开发者的陷阱,而是一个可以被好好利用的特性。
关闭累加性,创造输出器子树,即创造另一条输出路径
chapter 3
对应标题为”Overriding the default cumulative behaviour“的一整个小节。
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>foo.log</file>
<encoder>
<pattern>%date %level [%thread] %logger{10} [%file : %line] %msg%n</pattern>
</encoder>
</appender>
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%msg%n</pattern>
</encoder>
</appender>
<logger name="chapters.configuration.Foo" additivity="false">
<appender-ref ref="FILE" />
</logger>
<root level="debug">
<appender-ref ref="STDOUT" />
</root>
</configuration>
通过这样的设置,记录器的累加性在 chapters.configuration.Foo 处停止,相当于这个节点(以及它的子节点,虽然它只是一个类不会有子节点,但我们可以将这种用法放在一个以包为名的记录器上啊)从最终链接到以 root 为根的树上脱离了。因此这个节点(以及它的子节点)创造了一颗新的树,这颗新的树中的消息的最终输出和它脱离分裂出来的 root 为根的树不一样了。
这种分离出来,变成新树,消息的最终结果因此不同的想法是很有意义的。这能帮助我们思考更复杂的输出配置管理。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

