Ubuntu 18.04下搭建单机Hadoop和Spark集群环境
Hadoop在整个大数据技术体系中占有至关重要的地位,是大数据技术的基础和敲门砖,对Hadoop基础知识的掌握程度会在一定程度决定在大数据技术的道路上能走多远。
最近想要学习Spark,首先需要搭建Spark的环境,Spark的依赖环境比较多,需要Java JDK、Hadoop的支持。我们就分步骤依次介绍各个依赖的安装和配置。新安装了一个LinuxUbuntu 18.04系统,想在此系统上进行环境搭建,详细记录一下过程。
访问Spark的官网,阅读Spark的安装过程,发现Spark需要使用到hadoop,Java JDK等,当然官网也提供了Hadoop free的版本。本文还是从安装Java JDK开始,逐步完成Spark的单机安装。
1. Java JDK8的安装
前往Oracle官网下载JDK8,选择适合自己操作系统的版本,此处选择Linux 64
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
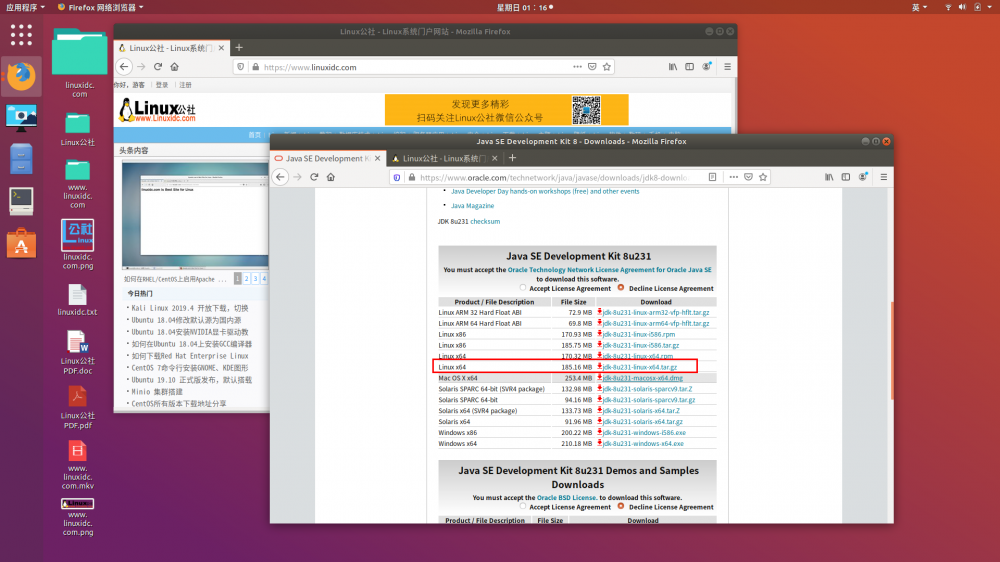
下载之后的包放到某个目录下,此处放在/opt/java目录
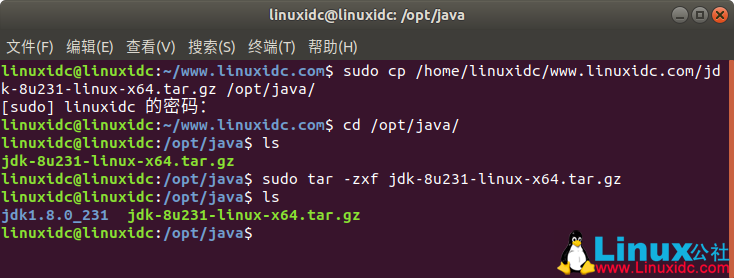
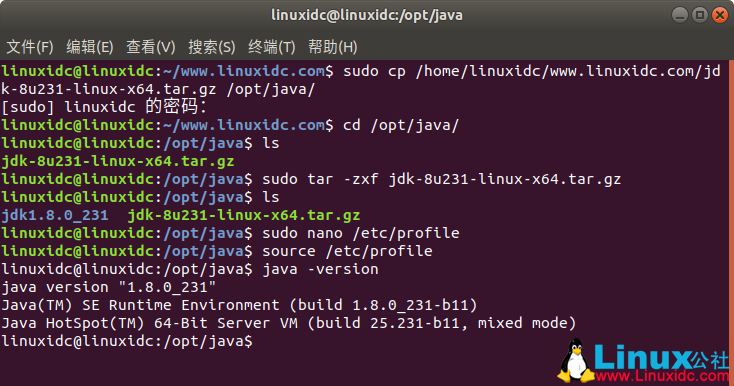
linuxidc@linuxidc:~/www.linuxidc.com$ sudo cp /home/linuxidc/www.linuxidc.com/jdk-8u231-linux-x64.tar.gz /opt/java/
[sudo] linuxidc 的密码:
linuxidc@linuxidc:~/www.linuxidc.com$ cd /opt/java/
linuxidc@linuxidc:/opt/java$ ls
jdk-8u231-linux-x64.tar.gz
使用命令:tar -zxvf jdk-8u231-linux-x64.tar.gz 解压缩
linuxidc@linuxidc:/opt/java$ sudo tar -zxf jdk-8u231-linux-x64.tar.gz
linuxidc@linuxidc:/opt/java$ ls
jdk1.8.0_231 jdk-8u231-linux-x64.tar.gz

修改配置文件/etc/profile,使用命令:sudo nano /etc/profile
linuxidc@linuxidc:/opt/java$ sudo nano /etc/profile
在文件末尾增加以下内容(具体路径依据环境而定):
export JAVA_HOME=/opt/java/jdk1.8.0_231
export JRE_HOME=/opt/java/jdk1.8.0_231/jre
export PATH=${JAVA_HOME}/bin:$PATH
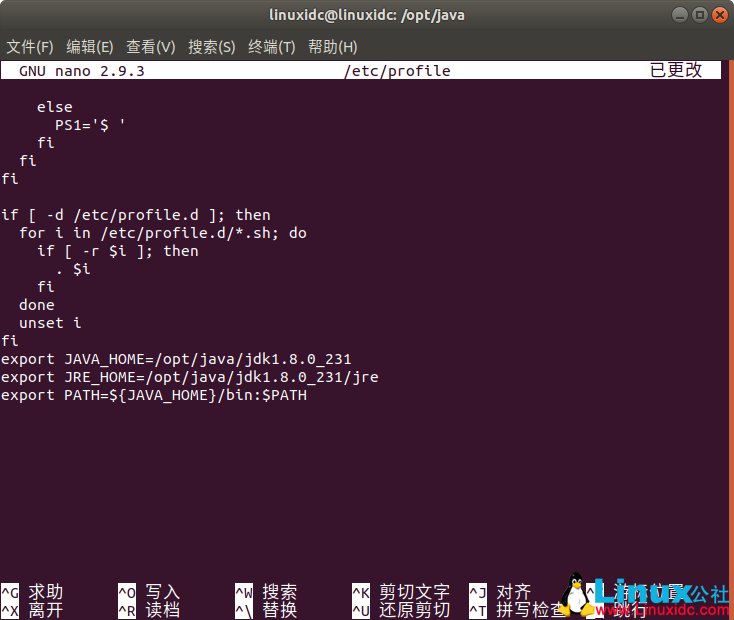
保存退出,在终端界面使用命令: source /etc/profile 使配置文件生效。
linuxidc@linuxidc:/opt/java$ source /etc/profile
使用java -version验证安装是否成功,以下回显表明安装成功了。
linuxidc@linuxidc:/opt/java$ java -version
java version "1.8.0_231"
Java(TM) SE Runtime Environment (build 1.8.0_231-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.231-b11, mixed mode)
linuxidc@linuxidc:/opt/java$
2. 安装Hadoop
前往官网https://hadoop.apache.org/releases.html下载hadoop,此处选择版本2.7.7
http://www.apache.org/dist/hadoop/core/hadoop-2.7.7/hadoop-2.7.7.tar.gz
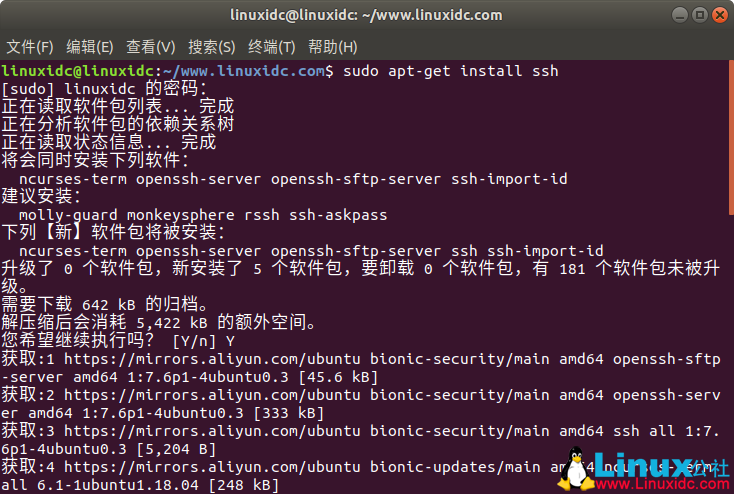
hadoop需要ssh免密登陆等功能,因此先安装ssh。
使用命令:
linuxidc@linuxidc:~/www.linuxidc.com$ sudo apt-get install ssh
linuxidc@linuxidc:~/www.linuxidc.com$ sudo apt-get install rsync
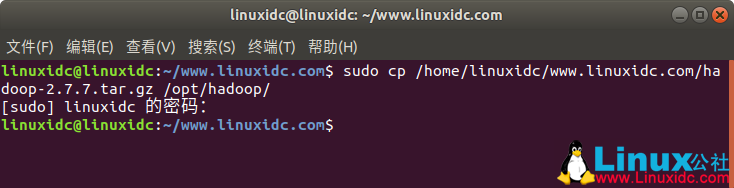
将下载的包放到某个目录下,此处放在/opt/hadoop
linuxidc@linuxidc:~/www.linuxidc.com$ sudo cp /home/linuxidc/www.linuxidc.com/hadoop-2.7.7.tar.gz /opt/hadoop/

使用命令:tar -zxvf hadoop-2.7.7.tar.gz 进行解压缩
此处选择伪分布式的安装方式(Pseudo-Distributed)
修改解压后的目录下的子目录文件 etc/hadoop/hadoop-env.sh,将JAVA_HOME路径修改为本机JAVA_HOME的路径,如下图:
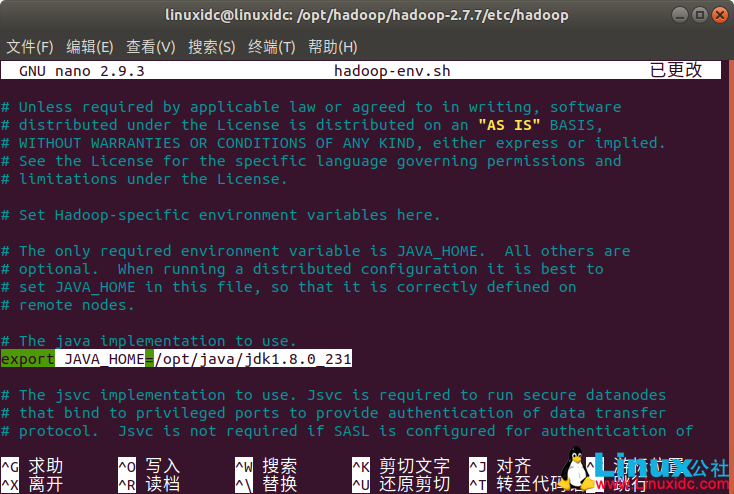
配置Hadoop的环境变量
使用命令:
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7/etc/hadoop$ sudo nano /etc/profile
添加以下内容:
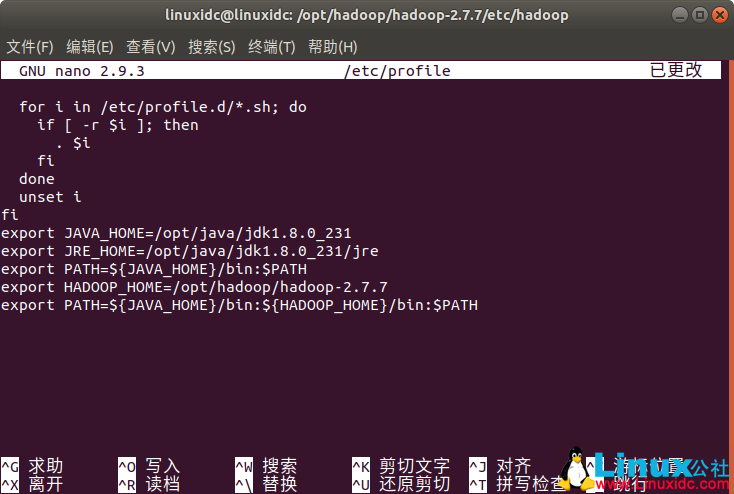
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
修改PATH变量,添加hadoop的bin目录进去
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH
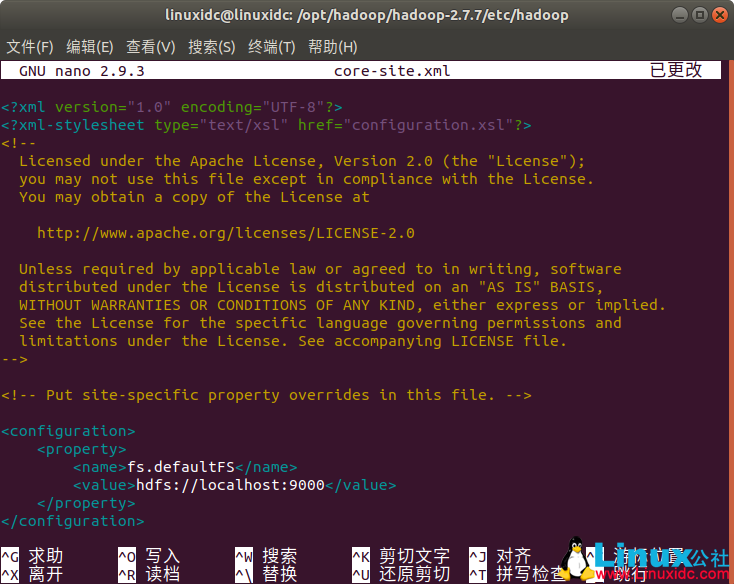
修改解压后的目录下的子目录文件 etc/hadoop/core-site.xml
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7/etc/hadoop$ sudo nano core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
如下图:
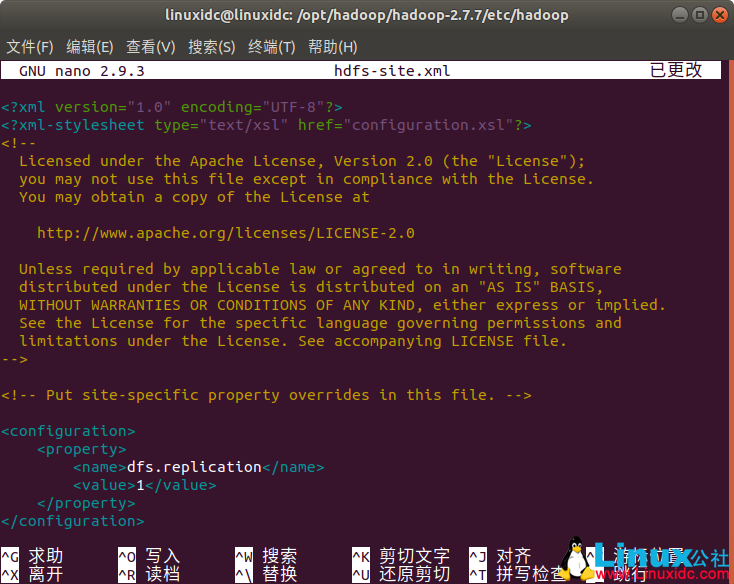
修改解压后的目录下的子目录文件 etc/hadoop/hdfs-site.xml
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7/etc/hadoop$ sudo nano hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
如下图:
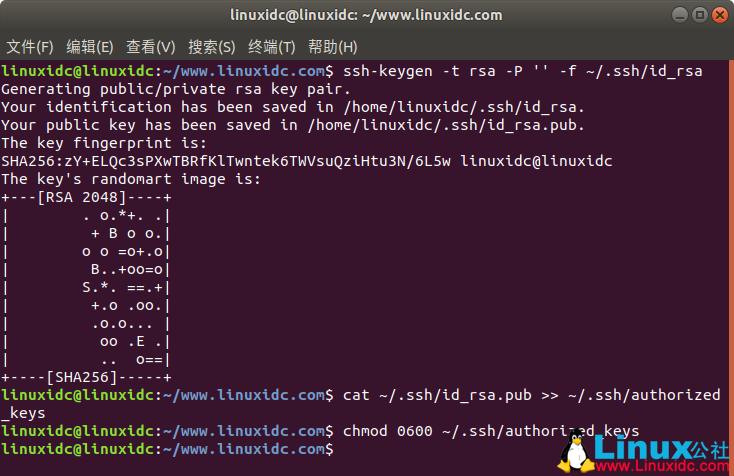
设置免密登陆
linuxidc@linuxidc:~/www.linuxidc.com$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
Generating public/private rsa key pair.
Your identification has been saved in /home/linuxidc/.ssh/id_rsa.
Your public key has been saved in /home/linuxidc/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:zY+ELQc3sPXwTBRfKlTwntek6TWVsuQziHtu3N/6L5w linuxidc@linuxidc
The key's randomart image is:
+---[RSA 2048]----+
| . o.*+. .|
| + B o o.|
| o o =o+.o|
| B..+oo=o|
| S.*. ==.+|
| +.o .oo.|
| .o.o... |
| oo .E .|
| .. o==|
+----[SHA256]-----+
linuxidc@linuxidc:~/www.linuxidc.com$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
linuxidc@linuxidc:~/www.linuxidc.com$ chmod 0600 ~/.ssh/authorized_keys
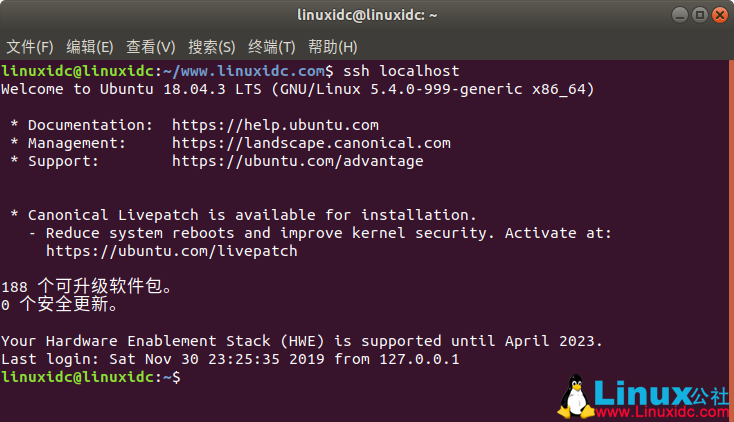
使用命令:ssh localhost 验证是否成功,如果不需要输入密码即可登陆说明成功了。
linuxidc@linuxidc:~/www.linuxidc.com$ ssh localhost
Welcome to Ubuntu 18.04.3 LTS (GNU/Linux 5.4.0-999-generic x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
* Canonical Livepatch is available for installation.
- Reduce system reboots and improve kernel security. Activate at:
https://ubuntu.com/livepatch
188 个可升级软件包。
0 个安全更新。
Your Hardware Enablement Stack (HWE) is supported until April 2023.
Last login: Sat Nov 30 23:25:35 2019 from 127.0.0.1
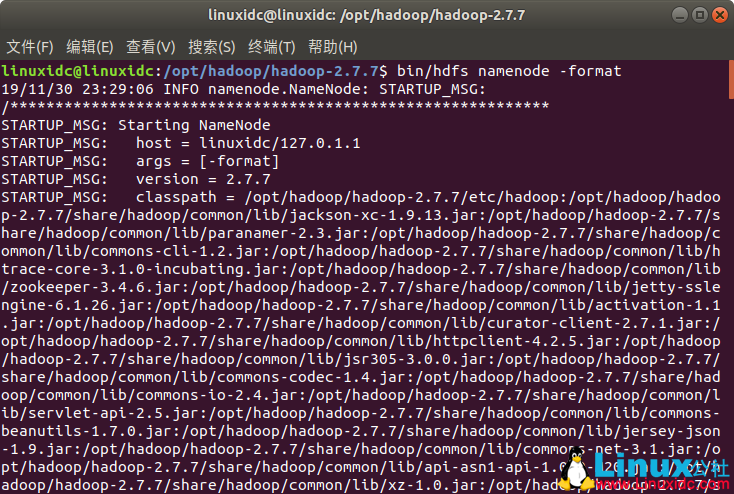
接下来需要验证Hadoop的安装
a. 格式化文件系统
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7$ bin/hdfs namenode -format
19/11/30 23:29:06 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = linuxidc/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.7
......
b. 启动Namenode和Datanode
linuxidc@linuxidc:/opt/hadoop/hadoop-2.7.7$ sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: starting namenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-linuxidc-namenode-linuxidc.out
localhost: starting datanode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-linuxidc-datanode-linuxidc.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:OSXsQK3E9ReBQ8c5to2wvpcS6UGrP8tQki0IInUXcG0.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
0.0.0.0: starting secondarynamenode, logging to /opt/hadoop/hadoop-2.7.7/logs/hadoop-linuxidc-secondarynamenode-linuxidc.out
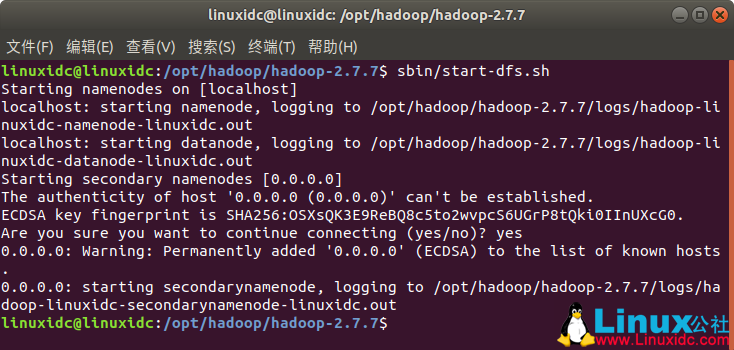
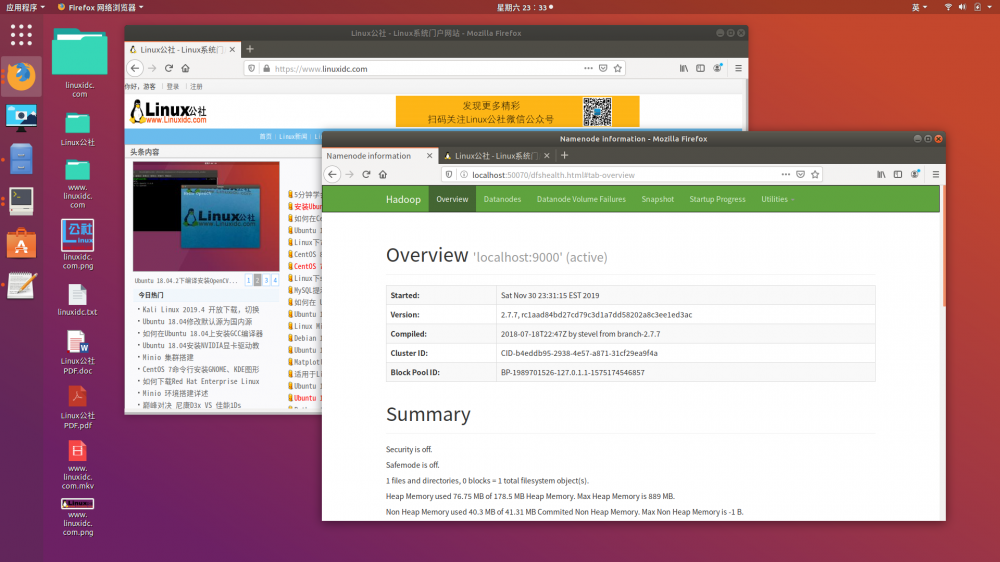
c.浏览器访问http://localhost:50070
Scala安装:
下载地址:https://www.scala-lang.org/download/2.11.8.html
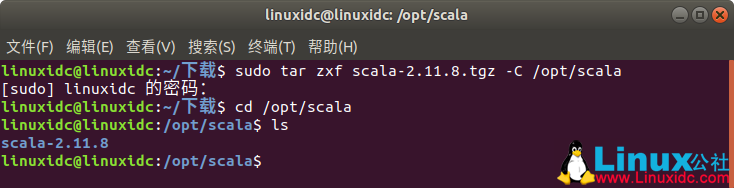
下载好后解压到:/opt/scala
linuxidc@linuxidc:~/下载$ sudo tar zxf scala-2.11.8.tgz -C /opt/scala
[sudo] linuxidc 的密码:
linuxidc@linuxidc:~/下载$ cd /opt/scala
linuxidc@linuxidc:/opt/scala$ ls
scala-2.11.8
配置环境变量:
linuxidc@linuxidc:/opt/scala$ sudo nano /etc/profile
添加:
export SCALA_HOME=/opt/scala/scala-2.11.8
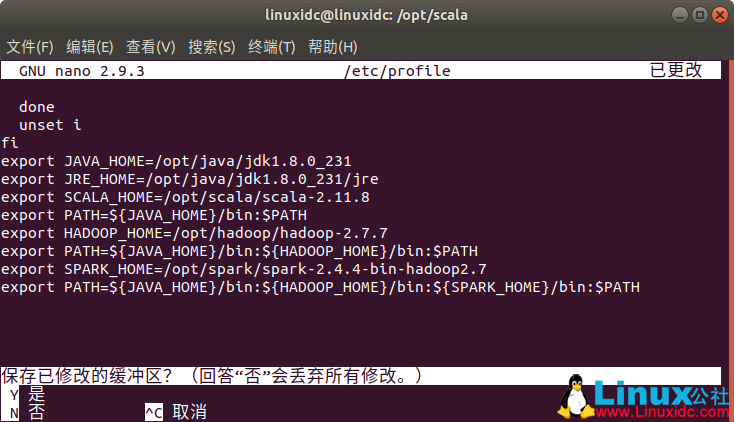
source /etc/profile
3. 安装spark
前往spark官网下载spark
https://spark.apache.org/downloads.html
此处选择版本如下:
spark-2.4.4-bin-hadoop2.7
将spark放到某个目录下,此处放在/opt/spark
使用命令:tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz 解压缩即可
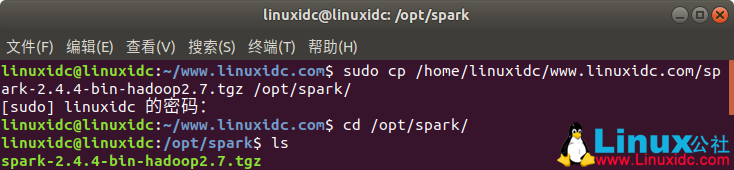
linuxidc@linuxidc:~/www.linuxidc.com$ sudo cp /home/linuxidc/www.linuxidc.com/spark-2.4.4-bin-hadoop2.7.tgz /opt/spark/
[sudo] linuxidc 的密码:
linuxidc@linuxidc:~/www.linuxidc.com$ cd /opt/spark/
linuxidc@linuxidc:/opt/spark$ ls
spark-2.4.4-bin-hadoop2.7.tgz
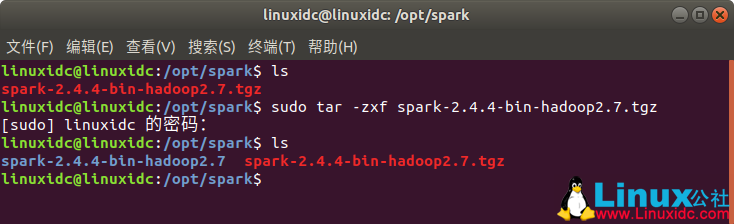
linuxidc@linuxidc:/opt/spark$ sudo tar -zxf spark-2.4.4-bin-hadoop2.7.tgz
[sudo] linuxidc 的密码:
linuxidc@linuxidc:/opt/spark$ ls
spark-2.4.4-bin-hadoop2.7 spark-2.4.4-bin-hadoop2.7.tgz
使用命令: ./bin/run-example SparkPi 10 测试spark的安装
配置环境变量SPARK_HOME
linuxidc@linuxidc:/opt/spark/spark-2.4.4-bin-hadoop2.7$ sudo nano /etc/profile
export SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SPARK_HOME}/bin:$PATH
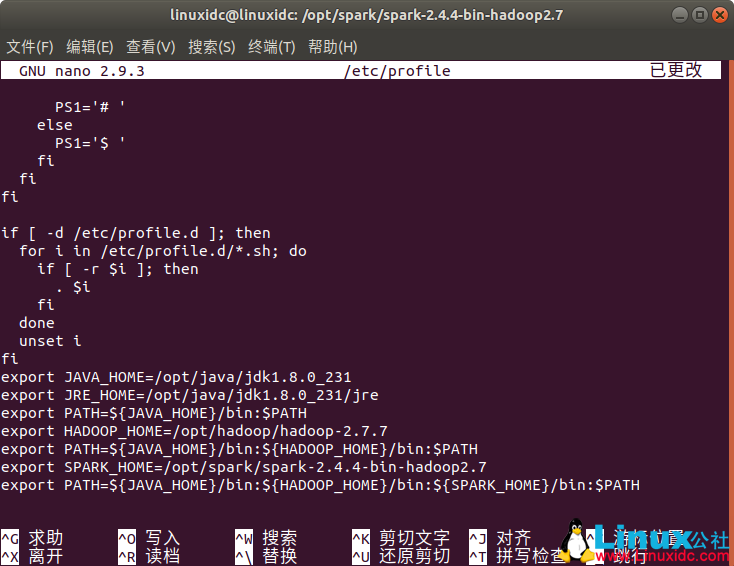
source /etc/profile
配置配置spark-env.sh
进入到spark/conf/
sudo cp /opt/spark/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh.template /opt/spark/spark-2.4.4-bin-hadoop2.7/conf/spark-env.sh
linuxidc@linuxidc:/opt/spark/spark-2.4.4-bin-hadoop2.7/conf$ sudo nano spark-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_231
export HADOOP_HOME=/opt/hadoop/hadoop-2.7.7
export HADOOP_CONF_DIR=/opt/hadoop/hadoop-2.7.7/etc/hadoop
export SPARK_HOME=/opt/spark/spark-2.4.4-bin-hadoop2.7
export SCALA_HOME=/opt/scala/scala-2.11.8
export SPARK_MASTER_IP=127.0.0.1
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_WEBUI_PORT=8099
export SPARK_WORKER_CORES=3
export SPARK_WORKER_INSTANCES=1
export SPARK_WORKER_MEMORY=5G
export SPARK_WORKER_WEBUI_PORT=8081
export SPARK_EXECUTOR_CORES=1
export SPARK_EXECUTOR_MEMORY=1G
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:$HADOOP_HOME/lib/native
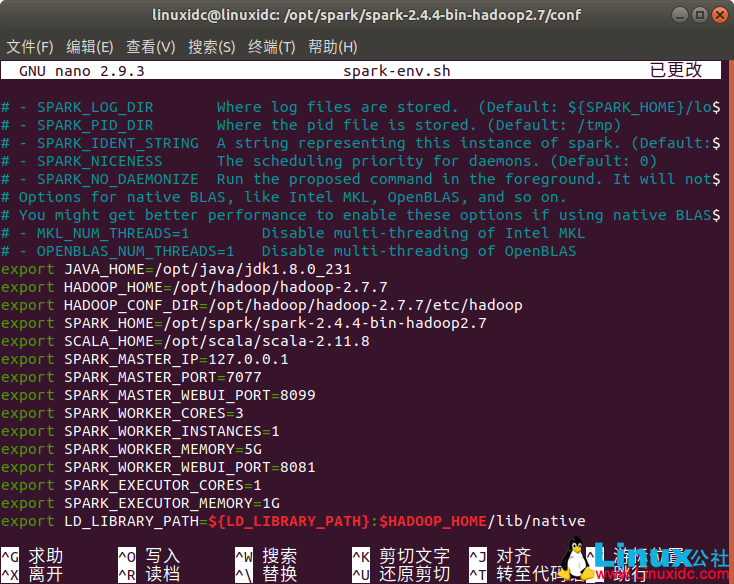
Java,Hadoop等具体路径根据自己实际环境设置。
启动bin目录下的spark-shell
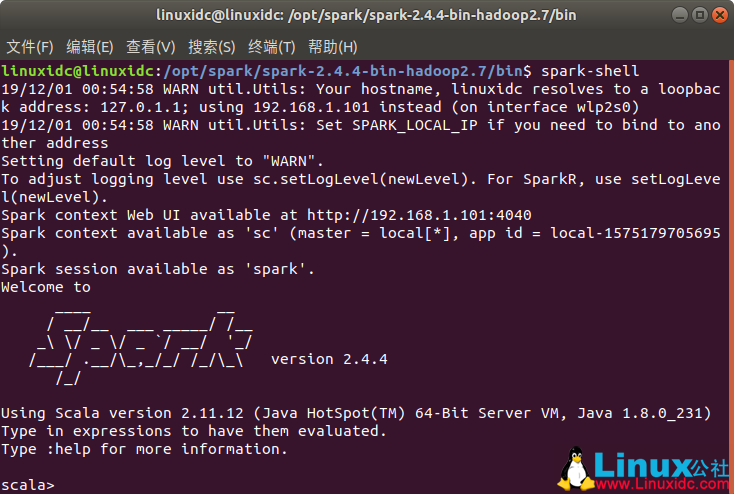
可以看到已经进入到scala环境,此时就可以编写代码啦。
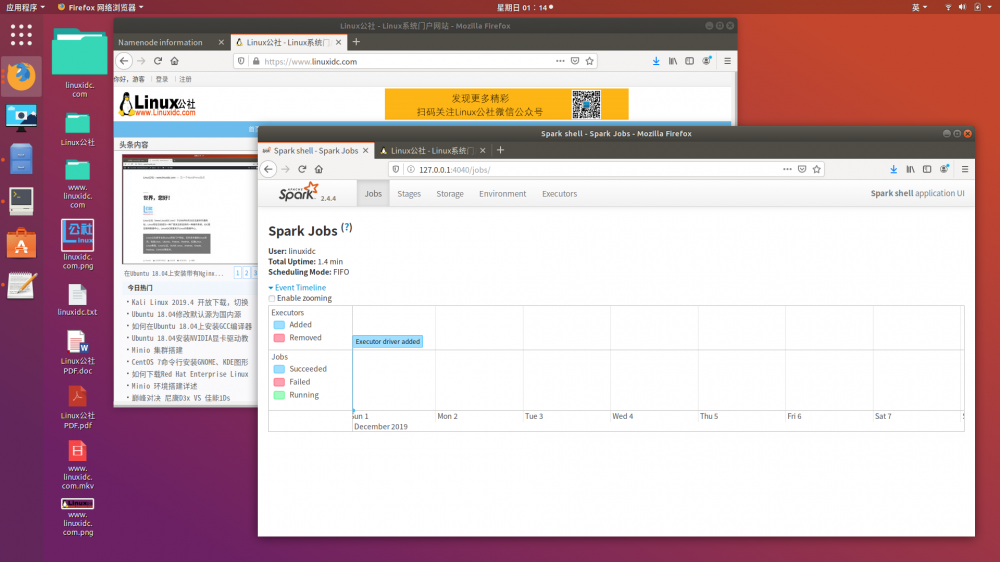
spark-shell的web界面http://127.0.0.1:4040
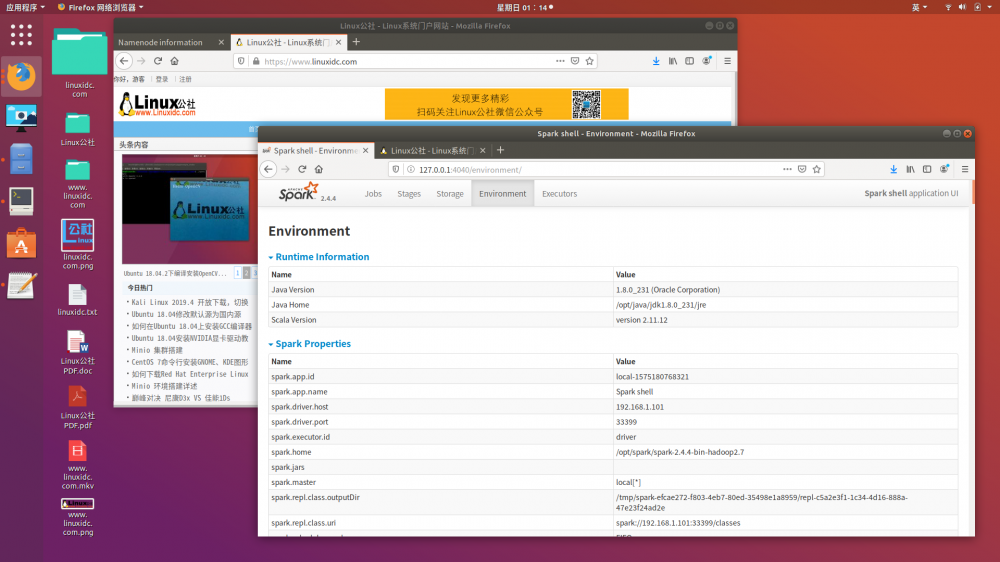
暂时先这样,如有什么疑问,请在Linux公社下面的评论栏里提出。
更多Hadoop相关信息见 Hadoop 专题页面 https://www.linuxidc.com/topicnews.aspx?tid=13
Linux公社的RSS地址 : https://www.linuxidc.com/rssFeed.aspx
本文永久更新链接地址: https://www.linuxidc.com/Linux/2019-12/161628.htm
正文到此结束
- 本文标签: apr IO HTML Ubuntu node example HDFS Security UI 分布式 apache key src secondarynamenode executor 代码 目录 tab 操作系统 集群 Logging 配置 id XML rsync https lib Secondary Namenode ORM 大数据 2019 linux Hadoop 软件 cat 下载 安装 Master DOM ssh ip dist Datanode Property IDE rand 测试 list Oracle http 安全 文件系统 Document java shell build Namenode scala 数据 tag web value tar core
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

