反思|Android 列表分页组件Paging的设计与实现:架构设计与原理解析
本文是 Android Jetpack Paging 系列的第二篇文章; 强烈建议 读者将本系列作为学习 Paging 阅读优先级最高的文章 ,如果读者对 Paging 还没有系统性的认识,请参考:
- 反思|Android 列表分页组件Paging的设计与实现:系统概述
前言
Paging 是一个非常优秀的分页组件,与其它热门的分页相关库不同的是, Paging 更偏向注重服务于 业务 而非 UI 。——我们都知道业务类型的开源库的质量非常依赖代码 整体的架构设计 (比如 Retofit 和 OkHttp );那么,如何说服自己或者同事去尝试使用 Paging ?显然源码中蕴含的优秀思想更具有说服力。
反过来说,若从 Google 工程师们设计、研发和维护的源码中有所借鉴,即使不在项目中真正使用它,自己依然能受益匪浅。
本文章节如下:
架构设计与原理解析
1、通过建造者模式进行依赖注入
创建流程毫无疑问是架构设计中最重要的环节。
作为组件的门板,向外暴露的 API 对于开发者越简单友善方便调用越好,同时,作为 API 调用者的我们也希望框架越灵活,可配置选项越多越好。
这听起来似乎有点违反常理—— 如何才能保证既保证 简单干净的接口设计 易于开发者上手,同时又有 足够多的可配置项 保证框架的灵活呢?
Paging 的 API 设计中使用了经典的 建造者(Builder)模式 ,并通过依赖注入将依赖一层层向下传递,最终依次构建了各个层级的对象实例。
对于开发者而言,只需要配置自己关心的参数,而不关心(甚至可以是不知道)的参数配置,全交给 Builder 类使用默认参数:
// 你可以这样复杂地配置
val pagedListLiveData =
LivePagedListBuilder(
dataSourceFactory,
PagedList.Config.Builder()
.setPageSize(PAGE_SIZE) // 分页加载的数量
.setInitialLoadSizeHint(20) // 初始化加载的数量
.setPrefetchDistance(10) // 预加载距离
.setEnablePlaceholders(ENABLE_PLACEHOLDERS) // 是否启用占位符
.build()
).build()
// 也可以这样简单地配置
val pagedListLiveData =
LivePagedListBuilder(dataSourceFactory, PAGE_SIZE).build()
复制代码
需要注意的是, 分页相关功能配置对象的构建 和 可观察者对象的构建 是否是两个不同的职责?显然是有必要的,因为:
LiveData<PagedList> = DataSource + PagedList.Config (即 分页数据的可观察者 = 数据源 + 分页配置)
因此,这里 Paging 的配置使用到了2个 Builder 类,即使是决定使用 建造者模式 ,设计者也需要对 Builder 类的定义有一个清晰的认知,这里也是设计过程中 单一职责原则 的优秀体现。
最终, Builder 中的所有配置都通过依赖注入的方式对 PagedList 进行了实例化:
// PagedList.Builder.build()
public PagedList<Value> build() {
return PagedList.create(
mDataSource,
mNotifyExecutor,
mFetchExecutor,
mBoundaryCallback,
mConfig,
mInitialKey);
}
// PagedList.create()
static <K, T> PagedList<T> create(@NonNull DataSource<K, T> dataSource,
@NonNull Executor notifyExecutor,
@NonNull Executor fetchExecutor,
@Nullable BoundaryCallback<T> boundaryCallback,
@NonNull Config config,
@Nullable K key) {
// 这里我们仅以ContiguousPagedList为例
// 可以看到,所有PagedList都是将构造函数的依赖注入进行的实例化
return new ContiguousPagedList<>(contigDataSource,
notifyExecutor,
fetchExecutor,
boundaryCallback,
config,
key,
lastLoad);
}
复制代码
依赖注入是一个非常简单而又朴实的编码技巧, Paging 的设计中,几乎没有用到单例模式,也几乎没有太多的静态成员——所有对象中除了自身的状态,其它所有通过依赖注入的配置项都是 final (不可变)的:
// PagedList.java
public abstract class PagedList<T> {
final Executor mMainThreadExecutor;
final Executor mBackgroundThreadExecutor;
final BoundaryCallback<T> mBoundaryCallback;
final Config mConfig;
final PagedStorage<T> mStorage;
}
// ItemKeyedDataSource.LoadInitialParams.java
public static class LoadInitialParams<Key> {
public final Key requestedInitialKey;
public final int requestedLoadSize;
public final boolean placeholdersEnabled;
}
复制代码
上文说到 几乎没有用到单例模式 ,实际上线程切换的设计有些许例外,但其本身依然可以通过 Builder 进行依赖注入以覆盖默认的线程获取逻辑。
通过 依赖注入 保证了对象的实例所需依赖有迹可循,类与类之间的依赖关系非常清晰,而实例化的对象内部 成员的不可变 也极大保证了 PagedList 分页数据的线程安全。
2、构建懒加载的LiveData
对于被观察者而言,只有当真正被订阅的时候,其数据的更新才有意义。换句话说,当开发者构建出一个 LiveData<PagedList> 时候,这时立即通过后台线程开始异步请求分页数据是没有意义的。
反过来理解,若没有订阅就请求数据,当真正订阅的时候, DataSource 中的数据已经过时了,这时还需要重新请求拉取最新数据,这样之前的一系列行为就没有意义了。
真正的请求应该放在 LiveData.observe() 的时候,即被订阅时才去执行,笔者这里更偏向于称其为“懒加载”——如果读者对 RxJava 比较熟悉的话,会发现这和 Observable.defer() 操作符概念比较相似:
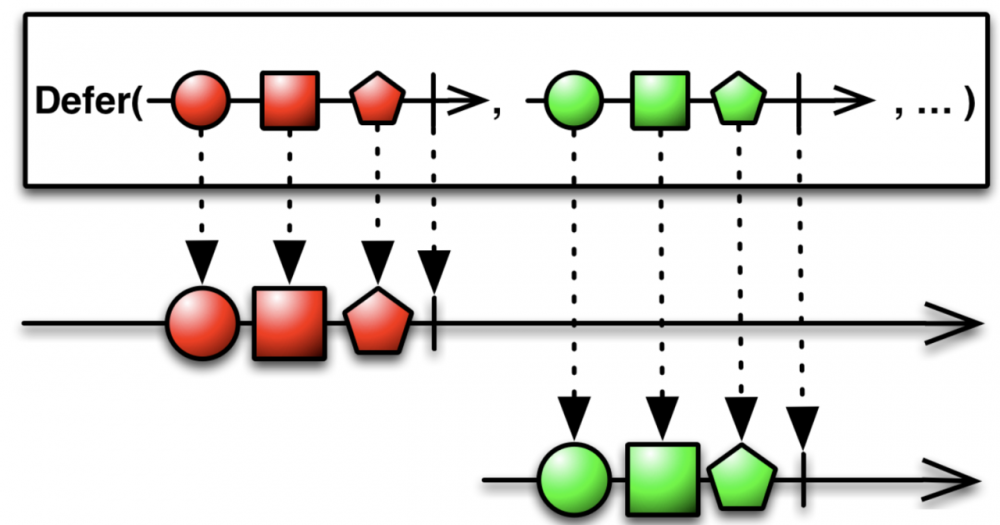
那么,如何构建“懒加载”的 LiveData<PagedList> 呢? Google 的设计者使用了 ComputableLiveData 类对 LiveData 的数据发射行为进行了包装:
// @hide
public abstract class ComputableLiveData<T> {}
复制代码
这是一个隐藏的类,开发者一般不能直接使用它,但它被应用的地方可不少, Room 组件生成的源码中也经常可以看到它的身影。
用一句话描述 ComputableLiveData 的定义,笔者觉得 LiveData的数据源 比较适合,感兴趣的读者可以仔细研究一下它的源码,笔者有机会会为它单独开一篇文章,这里不继续展开。
总之,通过 ComputableLiveData 类, Paging 实现了订阅时才执行异步任务的功能,更大程度上减少了做无用功的情况。
3、为分页数据赋予生命周期
分页数据 PagedList 理应也有属于自己的生命周期。
正常的生命周期内, PagedList 不断从 DataSource 中尝试加载分页数据,并展示出来;但数据源中的数据总有过期失效的时候,这意味着 PagedList 生命周期走到了尽头。
Paging 需要响应式地创建一个新的 DataSource 数据快照以及新的 PagedList ,然后交给 PagedListAdapter 更新在UI上。
为此, PagedList 类中增加了对应的一个 mDetached 字段:
public abstract class PagedList<T> extends AbstractList<T> {
//...
private final AtomicBoolean mDetached = new AtomicBoolean(false);
public boolean isDetached() {
return mDetached.get();
}
public void detach() {
mDetached.set(true);
}
}
复制代码
这个 AtomicBoolean 类型的字段是有意义的:我们知道 PagedList 对分页数据的加载是异步的,因此尝试加载下一页数据时,若此时 mDetached.get() 为 true ,意味着此时的分页数据已经失效,因此异步的分页请求任务不再需要被执行:
class ContiguousPagedList<K, V> extends PagedList<V> {
//...
public void onPagePlaceholderInserted(final int pageIndex) {
mBackgroundThreadExecutor.execute(new Runnable() {
@Override
public void run() {
// 不再异步加载分页数据
if (isDetached()) {
return;
}
// 若数据源失效,则将mDetached.set(true)
if (mDataSource.isInvalid()) {
detach();
} else {
// ... 加载下页数据
}
}
});
}
}
复制代码
通过上述代码片段读者也可以看到, PagedList 的生命周期是否失效,则依赖 DataSource 的 isInvalid() 函数,这个函数表示当前的 DataSource 数据源是否失效:
public abstract class DataSource<Key, Value> {
private AtomicBoolean mInvalid = new AtomicBoolean(false);
private CopyOnWriteArrayList<InvalidatedCallback> mOnInvalidatedCallbacks =
new CopyOnWriteArrayList<>();
// 通知数据源失效
public void invalidate() {
if (mInvalid.compareAndSet(false, true)) {
for (InvalidatedCallback callback : mOnInvalidatedCallbacks) {
// 数据源失效的回调函数,通知上层创建新的PagedList
callback.onInvalidated();
}
}
}
// 数据源是否失效
public boolean isInvalid() {
return mInvalid.get();
}
}
复制代码
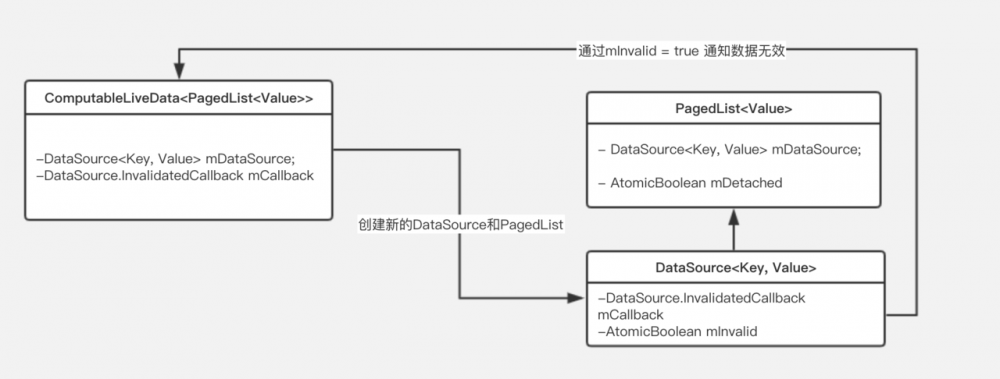
当数据源 DataSource 失效时,则会通过回调函数,通知上文我们提到的 ComputableLiveData<T> 创建新的 PagedList ,并通知给 LiveData 的观察者更新在 UI 上。
因此, PagedList 作为分页数据, DataSource 作为数据源, ComputableLiveData<T> 作为 PagedList 的创建和分发者三者形成了一个闭环:
4、提供 Room 的响应式支持
我们知道 Paging 原生提供了对 Room 组件的响应式支持,当数据库数据发生了更新, Paging 能够响应到并自动构建新的 PagedList ,然后更新到 UI 上。
这似乎是一个神奇的操作,但原理却十分简单,上一小节我们知道, DataSource 调用了 invalidate() 函数时,意味着数据源失效, DataSource 会通过回调函数重新构建新的 PagedList 。
Room 组件也是根据这个特性额外封装了一个新的 DataSource :
public abstract class LimitOffsetDataSource<T> extends PositionalDataSource<T> {
protected LimitOffsetDataSource(...) {
// 1.定义一个"命令数据源失效"的回调函数
mObserver = new InvalidationTracker.Observer(tables) {
@Override
public void onInvalidated(@NonNull Set<String> tables) {
invalidate();
}
};
// 2.为数据库的失效跟踪器(InvalidationTracker)配置观察者
db.getInvalidationTracker().addWeakObserver(mObserver);
}
}
复制代码
这之后,每当数据库中数据失效,都会自动执行 DataSource.invalidate() 函数。
现在读者回顾最初学习 Paging 的时候, Room 中开发者定义的 Dao 类,返回的 DataSource.Factory 到底是怎样的一个对象?
@Dao
interface RedditPostDao {
@Query("SELECT * FROM posts WHERE subreddit = :subreddit ORDER BY indexInResponse ASC")
fun postsBySubreddit(subreddit : String) : DataSource.Factory<Int, RedditPost>
}
复制代码
答案不言而喻,正是 LimitOffsetDataSource 的工厂类:
@Override
public DataSource.Factory<Integer, RedditPost> postsBySubreddit(final String subreddit) {
return new DataSource.Factory<Integer, RedditPost>() {
// 返回能够响应数据库数据失效的 LimitOffsetDataSource
@Override
public LimitOffsetDataSource<RedditPost> create() {
return new LimitOffsetDataSource<RedditPost>(__db, _statement, false , "posts") {
// ....
}
}
复制代码
原理上讲,这些代码平淡无奇,但设计者通过注解的一层封装,大幅简化了开发者的代码量。对于开发者而言,只需要配置一个接口,而无需去了解内部的代码实现细节。
中场:更多的困惑
上一篇文章 中对 DataSource 进行了简单的介绍,很多朋友反应 DataSource 这一部分的源码过于晦涩,对于 DataSource 的选择也是懵懵懂懂。
复杂问题的解决依赖于问题的切割细分,本文将其细分成以下2个小问题,并进行一一探讨:
DataSource PagedList
5、数据源的连续性与分页加载策略
为什么设计出这么多的 DataSource 和其子类,它们的使用场景各是什么?
Paging 分页组件的设计中, DataSource 是一个非常重要的模块。顾名思义, DataSource<Key, Value> 中的 Key 对应数据加载的条件, Value 对应数据集的实际类型, 针对不同场景, Paging 的设计者提供了几种不同类型的 DataSource 实现类:
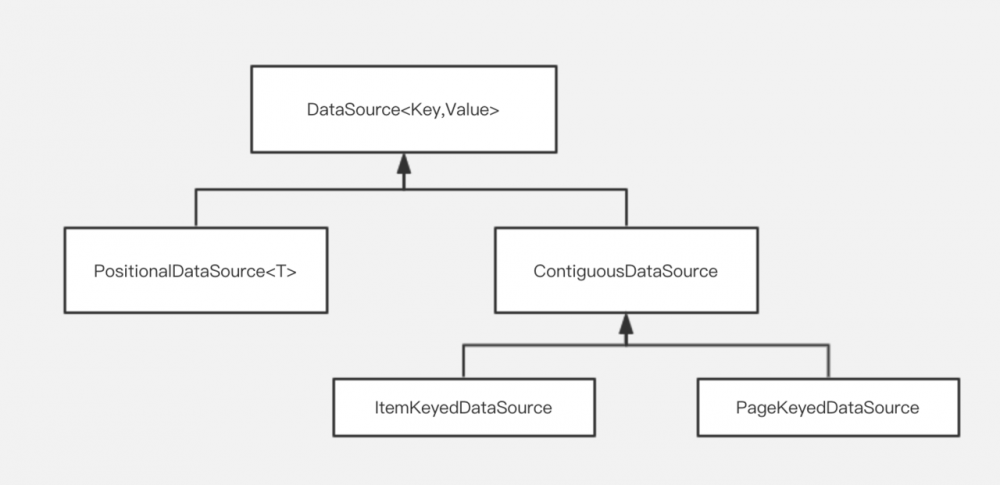
关于这些 DataSource 的介绍,请参考上一篇文章的这一小节,本文不再赘述。
第一次阅读这一部分源码时,笔者最困惑的是, ContiguousDataSource 和 PositionalDataSource 的区别到底是什么呢?
翻阅过源码的读者也许曾经注意到, DataSource 有这样一个抽象函数:
public abstract class DataSource<Key, Value> {
// 数据源是否是连续的
abstract boolean isContiguous();
}
class ContiguousDataSource<Key, Value> extends DataSource<Key, Value> {
// ContiguousDataSource 是连续的
boolean isContiguous() { return true; }
}
class PositionalDataSource<T> extends DataSource<Integer, T> {
// PositionalDataSource 是非连续的
boolean isContiguous() { return false; }
}
复制代码
那么, 数据源的连续性 到底是什么概念?
对于一般的网络分页加载请求而言,下一页的数据总是需要依赖上一页的加载,这种时候,我们通常称之为 数据源是连续的 —— 这似乎毫无疑问,这也是 ItemKeyedDataSource 和 PageKeyedDataSource 被广泛使用的原因。
但有趣的是,在 以本地缓存作为分页数据源 的业务模型下,这种 分页数据源应该是连续的 常识性的认知被打破了。
每个手机都有通讯录,因此本文以通讯录 APP 为例,对于通讯录而言,所有数据取自于本地持久层,而考虑到手机内也许会有成千上万的通讯录数据, APP 本身列表数据也应该进行分页加载。
这种情况下,分页数据源是连续的吗?
读者仔细思考可以得知,这时分页数据源 一定不能是连续的 。诚然,对于滑动操作而言,数据的连续分页请求没有问题,但是当用户从通讯录页面的侧边点击 Z 字母,尝试快速跳转 Z 开头的用户时,分页数据请求的连续性被打破了:
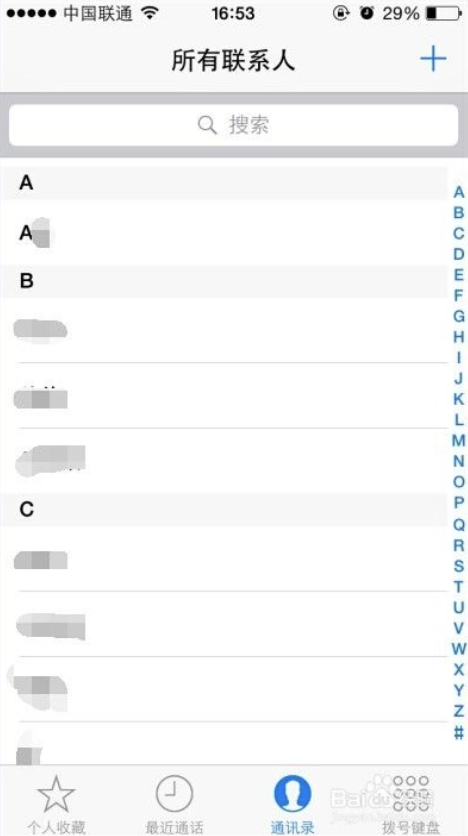
这便是 PositionalDataSource 的使用场景:通过特定的位置加载数据,这里 Key 是 Integer 类型的位置信息,每一条分页数据并不依赖上一条分页数据,而是依赖数据所处数据源本身的位置( Position )。
分页数据的连续性是一个十分重要的概念,理解了这个概念,读者也就能理解 DataSource 各个子类的意义了:
无论是 PositionalDataSource 、 ItemKeyedDataSource 还是 PageKeyedDataSource ,这些类都是不同的 分页加载策略 。开发者只需要根据不同业务的场景(比如 数据的连续性 ),选择不同的 分页加载策略 即可。
6、分页数据模型与分页数据副本
为什么设计出这么多的 PagedList 和其子类?
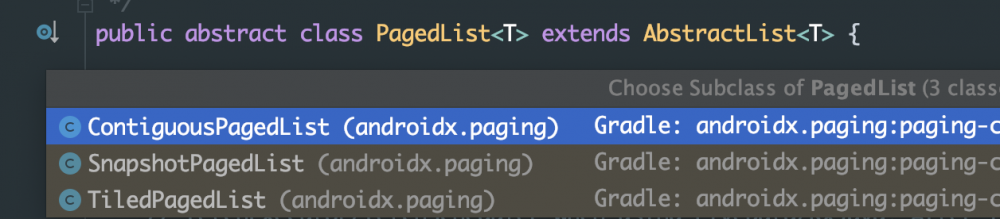
和 DataSource 相似, PagedList 同样拥有一个 isContiguous() 接口:
public abstract class PagedList<T> extends AbstractList<T> {
abstract boolean isContiguous();
}
class ContiguousPagedList<K, V> extends PagedList<V> {
// ContiguousPagedList 内部持有 ContiguousDataSource
final ContiguousDataSource<K, V> mDataSource;
boolean isContiguous() { return true; }
}
class TiledPagedList<T> extends PagedList<T> {
// TiledPagedList 内部持有 PositionalDataSource
final PositionalDataSource<T> mDataSource;
boolean isContiguous() { return false; }
}
复制代码
读者应该理解, PagedList 内部持有一个 DataSource ,而 分页数据加载 的行为本质上是从 DataSource 中异步获取数据—— 在分页数据请求的过程中,不同的 DataSource 也会有不同的参数需求,从而导致 PagedList 内部的行为也不尽相同;因此 PagedList 向下导出了 ContiguousPagedList 和 TiledPagedList 类,用于不同业务情况的分页请求处理。
那么 SnapshotPagedList 又是一个什么类呢?
PagedList 额外有一个 snapshot() 接口,以返回当前分页数据的快照:
public abstract class PagedList<T> extends AbstractList<T> {
public List<T> snapshot() {
return new SnapshotPagedList<>(this);
}
}
复制代码
这个 snapshot() 函数非常重要,其用于保存分页数据的前一个状态,并且用于 AsyncPagedListDiffer 进行数据集的差异性计算,新的 PagedList 到来时(通过 PagedListAdapter.submitList() ),并未直接进行数据的覆盖和差异性计算,而是先对之前 PagedList 中的数据集进行拷贝。
篇幅原因不详细展示,有兴趣的读者可以自行阅读 PagedListAdapter.submitList() 相关源码。
接下来简单了解下 SnapshotPagedList 内部的实现:
class SnapshotPagedList<T> extends PagedList<T> {
SnapshotPagedList(@NonNull PagedList<T> pagedList) {
// 1.这里我们看到,其它对象都没有改变堆内地址的引用
// 除了 pagedList.mStorage.snapshot(),最终执行 -> 2
super(pagedList.mStorage.snapshot(),
pagedList.mMainThreadExecutor,
pagedList.mBackgroundThreadExecutor,
null,
pagedList.mConfig);
mDataSource = pagedList.getDataSource();
mContiguous = pagedList.isContiguous();
mLastLoad = pagedList.mLastLoad;
mLastKey = pagedList.getLastKey();
}
}
final class PagedStorage<T> extends AbstractList<T> {
PagedStorage(PagedStorage<T> other) {
// 2.对当前分页数据进行了一次拷贝
mPages = new ArrayList<>(other.mPages);
}
}
复制代码
此外, mSnapshot 还用于状态的保存,当差异性计算未执行完毕时,若此时开发者调用 getCurrentList() 函数,则会尝试将 mSnapshot ——即之前数据集的副本进行返回,有兴趣的读者可以研究一下。
7、线程切换与Paging设计中的"Bug"
Google 的工程师们设计 Paging 的初衷就希望能够让开发者 无感知地进行线程切换 ,因此大部分线程切换的代码都封装在内部:
public class ArchTaskExecutor extends TaskExecutor {
// 主线程的Executor
private static final Executor sMainThreadExecutor = new Executor() {
@Override
public void execute(Runnable command) {
getInstance().postToMainThread(command);
}
};
// IO线程的Executor
private static final Executor sIOThreadExecutor = new Executor() {
@Override
public void execute(Runnable command) {
getInstance().executeOnDiskIO(command);
}
};
}
复制代码
有兴趣的读者可以研究 ArchTaskExecutor 内部的源码,其内部 sMainThreadExecutor 原理依然是通过 Looper.getMainLooper() 创建对应的 Handler 并向主线程发送消息,本文不赘述。
源码的设计者希望,使用 Paging 的开发者能够在执行数据的分页加载任务时,内部切换到 IO 线程,而分页数据加载成功后,则内部切换回到主线程更新UI。
从设计上讲,这是一个非常优秀的设计,但是开发者真正使用时,却很难注意到 DataSource 中对数据加载的回调方法,本身就是执行在 IO 线程的:
public abstract class PositionalDataSource<T> extends DataSource<Integer, T>{
// 通过注解提醒开发者回调在子线程
@WorkerThread
public abstract void loadInitial(...);
@WorkerThread
public abstract void loadRange(...);
}
复制代码
回调本身在子线程执行,意味着,开发者对分页数据的加载最好不要使用异步方法,否则很可能出问题。
对于 OkHttp 的使用者而言,开发者应该使用 execute() 同步方法:
override fun loadInitial(..., callback: LoadInitialCallback<RedditPost>) {
// 使用同步方法
val response = request.execute()
callback.onResult(...)
}
复制代码
对于 RxJava 而言,则应该使用 blocking 相关的方法进行阻塞操作。
如果说 PositionalDataSource 还有 @WorkerThread 提醒,那么另外的 ItemKeyedDataSource 和 PageKeyedDataSource 干脆就没有 @WorkerThread 注解:
public abstract class ItemKeyedDataSource<Key, Value> extends ContiguousDataSource<Key, Value> {
public abstract void loadInitial(...);
public abstract void loadAfter(...);
}
// PageKeyedDataSource也没有`WorkerThread`注解,不赘述
复制代码
因此如果没有注意到这些细节,开发者很可能误入歧途,从而导致未知的一些问题,对此,开发者可以尝试参考 Google 这个 示例代码 。
奇怪的是,即使是 Google 官方的代码示例中,对于 loadInitial 和 loadAfter 两个函数,也只有 loadInitial 中使用了同步方法进行请求,而 loadAfter 中依然是使用 enqueue() 进行异步请求。尽管注释中明确声明了这点,但笔者还是无法理解这种行为,因为这的确有可能令一些开发者误入歧途。
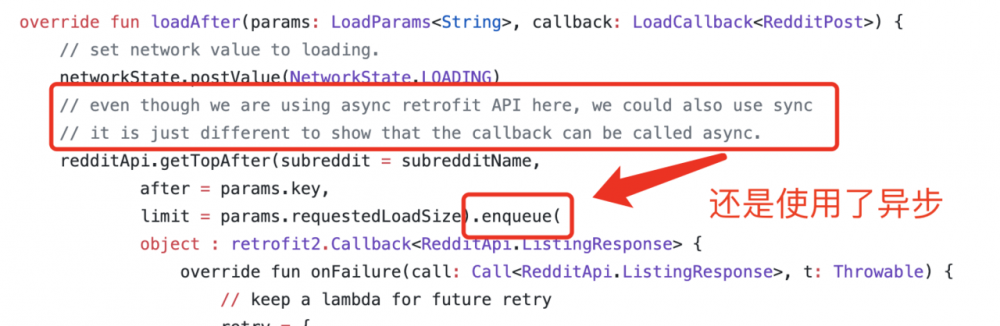
总之, Paging 的设计中,其初衷将线程切换的实现细节进行隐藏是好的,但是结果的确没有达到很好的效果,相反还有可能导致错误的理解和使用(笔者踩坑了)。
也许线程切换不交给内部的默认参数去实现(尤其是不要交给Builder模式去配置,这太容易被忽视了),而是强制要求交给开发者去指定更好?
欢迎有想法的朋友在本文下方留言,思想的交流会更容易让人进步。
总结
本文对 Paging 的原理实现进行了系统性的讲解,那么, Paging 的架构设计上,到底有哪些优点值得我们学习?
首先, 依赖注入 。 Paging 内部所有对象的依赖,包括配置参数、内部回调、线程切换,绝大多数都是通过依赖注入进行的, 简单 且 朴实 ,类与类之间的依赖关系皆有迹可循。
其次,类的抽象和将不同业务的下沉, DataSource 和 PagedList 分工明确,并向上抽象为一个抽象类,并将不同业务情况下的分页逻辑下沉到各自的子类中去。
最后,明确对象的边界:设计分页数据的生命周期,当数据源无效时,避免执行无效的异步分页任务;使用 懒加载的LiveData ,保证未订阅时不执行分页逻辑。
参考 & 更多
如果对 Paging 感兴趣,欢迎阅读笔者更多相关的文章,并与我一起讨论:
-
反思|Android 列表分页组件Paging的设计与实现:系统概述
-
Android官方架构组件Paging:分页库的设计美学
-
Android官方架构组件Paging-Ex:为分页列表添加Header和Footer
-
Android官方架构组件Paging-Ex:列表状态的响应式管理
关于我
Hello,我是 却把清梅嗅 ,如果您觉得文章对您有价值,欢迎 :heart:,也欢迎关注我的博客 或者 Github 。
如果您觉得文章还差了那么点东西,也请通过 关注 督促我写出更好的文章——万一哪天我进步了呢?
正文到此结束
- 本文标签: git 开发者 代码 Select final src queue 工程师 质量 UI GitHub 解析 开发 dist 文章 bug 分页逻辑 db 配置 Google Android 参数 build 数据模型 模型 tk tab 安全 FIT App 分页 dataSource ACE id 缓存 源码 线程 API CTO list 同步 生命 希望 Statement java 数据库 管理 注释 value 博客 IO ArrayList IDE 响应式 key 开源 http executor 架构设计 https 数据 需求 实例 总结 ask Atom 本质
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

