一文彻底搞懂 CAS 实现原理
点击 Java爱好者社区 关注我们吧!
本文导读:
-
前言
-
如何保障线程安全
-
CAS原理剖析
-
CPU如何保证原子操作
-
解密CAS底层指令
-
小结
1
前言
日常编码过程中,基本不会直接用到 CAS 操作,都是通过一些JDK 封装好的并发工具类来使用的,在 java.util.concurrent 包下。
但是面试时 CAS 还是个高频考点,所以呀,你还不得不硬着头皮去死磕一下这块的技能点,总比一问三不知强吧?
一般都是先针对一些简单的并发知识问起,还有的面试官,比较直接:
面试官:Java并发工具类中的 CAS 机制讲一讲?
小东:额?大脑中问自己「啥是 CAS?」我听过的,容我想一想...
一分钟过去了...
小东:嘿嘿~,这块我看过的,记不大清楚了。
面试官:好的,今天先到这吧~
小东:在路上

当然 CAS 你若真不懂,你可以引导面试官到你擅长的技术点上,用你的其他技能亮点扳回一局。
接下来,我们通过一个示例代码来说:
// 类的成员变量
static int data = 0;
// main方法内代码
IntStream.range(0, 2).forEach((i) -> {
new Thread(() -> {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
IntStream.range(0, 100).forEach(y -> {
data++;
});
}).start();
});
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(data);
}
结合图示理解:
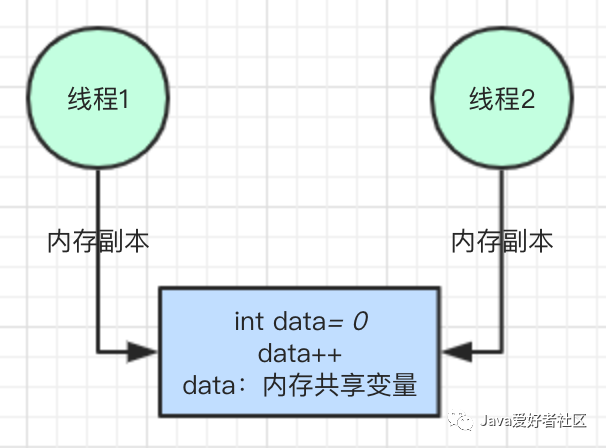
上述代码,问题很明显,data 是类中的成员变量,int 类型,即共享的资源。当多个线程同时 执行 data++ 操作时,结果可能不等于 200,为了模拟出效果,线程中 sleep 了 20 毫秒,让线程就绪,代码运行多次,结果都不是 200 。
2
如何保障线程安全
示例代码执行结果表明了,多个线程同时操作共享变量导致了结果不准确,线程是不安全的。如何解决呢?
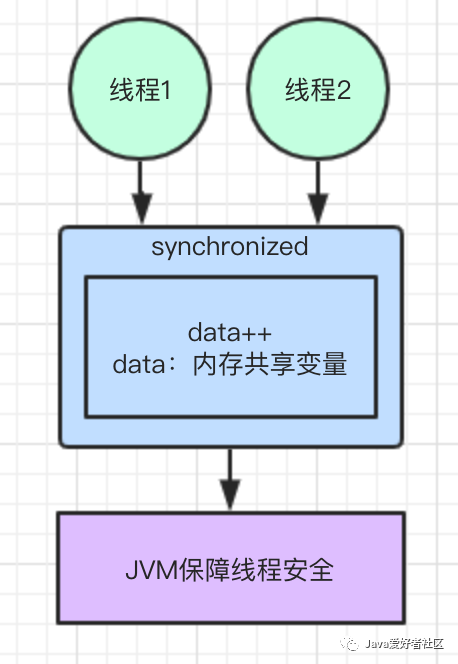
方案一:使用 synchronized 关键字
使用 synchronized 关键字,线程内使用同步代码块,由JVM自身的机制来保障线程的安全性。
synchronized 关键代码:
// 类中定义的Object锁对象
Object lock = new Object();
// synchronized 同步块 () 中使用 lock 对象锁定资源
IntStream.range(0, 100).forEach(y -> {
synchronized (lock.getClass()) {
data++;
}
});
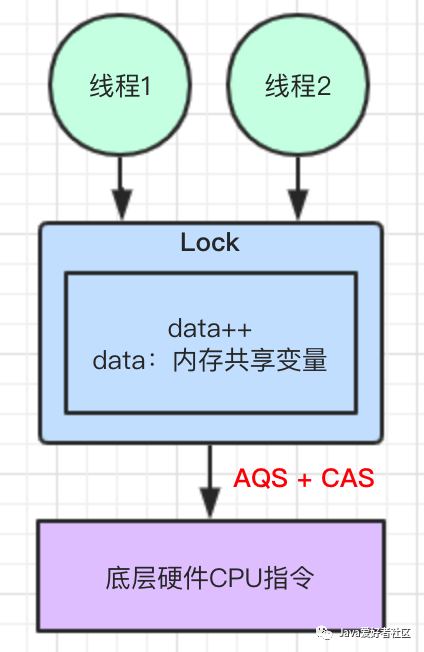
方案二:使用 Lock 锁
高并发场景下,使用 Lock 锁要比使用 synchronized 关键字,在性能上得到极大的提高。因为 Lock 底层是通过 AQS + CAS 机制来实现的。关于 AQS 机制可以参见往期文章 <<通过通过一个生活中的案例场景,揭开并发包底层AQS的神秘面纱>> 。CAS 机制会在文章中下面讲到。
使用 Lock 的关键代码:
// 类中定义成员变量
Lock lock = new ReentrantLock();
// 执行 lock() 方法加锁,执行 unlock() 方法解锁
IntStream.range(0, 100).forEach(y -> {
lock.lock();
data++;
lock.unlock();
});
结合图示理解:
方案三:使用 Atomic 原子类
除上面两种方案还有没有更为优雅的方案?synchronized 的使用在 JDK1.6 版本以后做了很多优化,如果并发量不大,相比 Lock 更为安全,性能也能接受,因其得益于 JVM 底层机制来保障,自动释放锁,无需硬编码方式释放锁。而使用 Lock 方式,一旦 unlock() 方法使用不规范,可能导致死锁。
JDK 并发包所有的原子类如下所示:
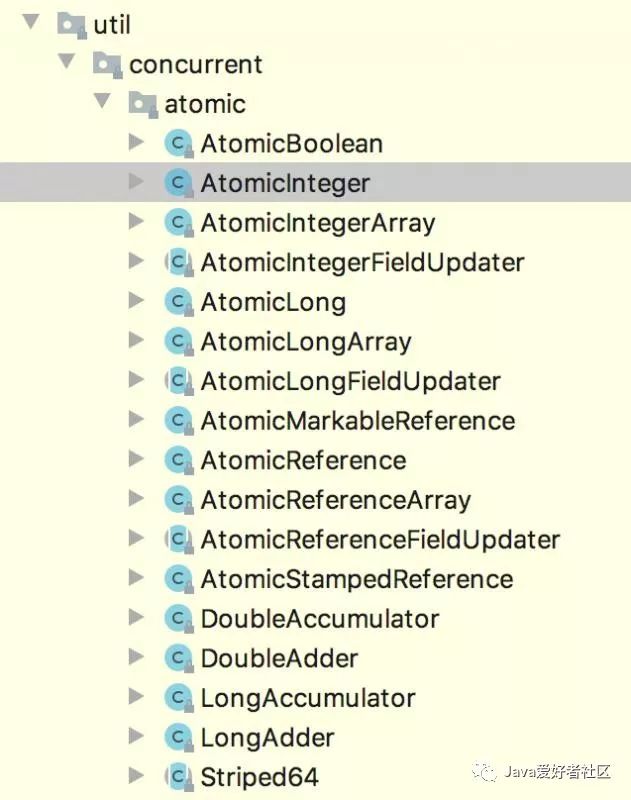
使用 AtomicInteger 工具类实现代码:
// 类中成员变量定义原子类
AtomicInteger atomicData = new AtomicInteger();
// 代码中原子类的使用方式
IntStream.range(0, 2).forEach((i) -> {
new Thread(() -> {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
IntStream.range(0, 100).forEach(y -> {
// 原子类自增
atomicData.incrementAndGet();
});
}).start();
});
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 通过 get () 方法获取结果
System.out.println(atomicData.get());
结合图示理解:
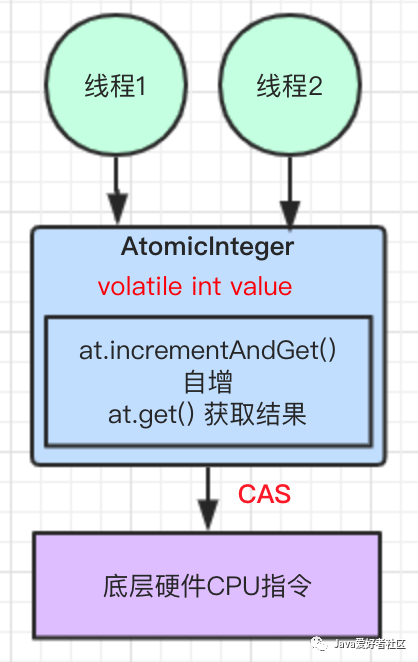
之所以推荐使用 Atomic 原子类,因为其底层基于 CAS 乐观锁来实现的,下文会详细分析。
方案四:使用 LongAdder 原子类
LongAdder 原子类在 JDK1.8 中新增的类, 跟方案三中提到的 AtomicInteger 类似,都是在 java.util.concurrent.atomic 并发包下的。
LongAdder 适合于高并发场景下,特别是写大于读的场景,相较于 AtomicInteger、AtomicLong 性能更好,代价是消耗更多的空间,以空间换时间。
使用 LongAdder 工具类实现代码:
// 类中成员变量定义的LongAdder
LongAdder longAdderData = new LongAdder();
// 代码中原子类的使用方式
IntStream.range(0, 2).forEach((i) -> {
new Thread(() -> {
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
IntStream.range(0, 100).forEach(y -> {
// 使用 increment() 方法自增
longAdderData.increment();
});
}).start();
});
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 使用 sum() 获取结果
System.out.println(longAdderData.sum());
结合图示理解:
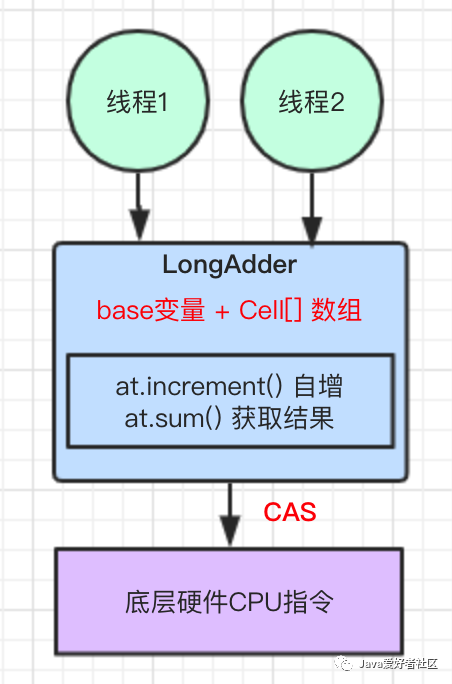
但是,如果使用了 LongAdder 原子类,当然其底层也是基于 CAS 机制实现的。LongAdder 内部维护了 base 变量和 Cell[] 数组,当多线程并发写的情况下,各个线程都在写入自己的 Cell 中,LongAdder 操作后返回的是个近似准确的值,最终也会返回一个准确的值。
换句话说,使用了 LongAdder 后获取的结果并不是实时的,对实时性要求高的还是建议使用其他的原子类,如 AtomicInteger 等。
volatile 关键字方案?
可能还有朋友会说,还想到另外一种方案:使用 volatile 关键字啊。
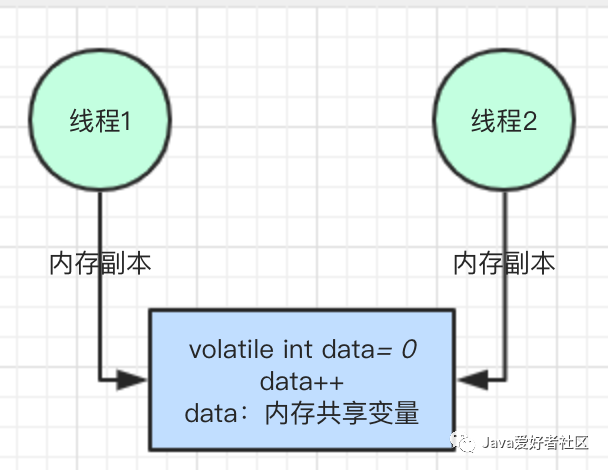
经过验证,是不可行的,大家可以试试,就本文给出的示例代码直接执行,结果都不等于 200,说明线程仍然是不安全的。
data++ 自增赋值并不是原子的,跟 Java内存模型有关。
在非线程安全的图示中有标注执行线程本地,会有个内存副本,即本地的工作内存,实际执行过程会经过如下几个步骤:
(1)执行线程从本地工作内存读取 data,如果有值直接获取,如果没有值,会从主内存读取,然后将其放到本地工作内存当中。
(2)执行线程在本地工作内存中执行 +1 操作。
(3)将 data 的值写入主内存。
结论:请记住!
一个变量简单的读取和赋值操作是原子性的,将一个变量赋值给另外一个变量不是原子性的。
Java内存模型(JMM)仅仅保障了变量的基本读取和赋值操作是原子性的,其他均不会保证的。如果想要使某段代码块要求具备原子性,就需要使用 synchronized 关键字、并发包中的 Lock 锁、并发包中 Atomic 各种类型的原子类来实现,即上面我们提到的 四种方案都是可行的 。
而 volatile 关键字修饰的变量,恰恰是不能保障原子性的,仅能保障可见性和有序性。
3
CAS原理剖析
CAS 被认为是一种乐观锁,有乐观锁,相对应的是悲观锁。
在上述示例中,我们使用了 synchronized,如果在线程竞争压力大的情况下,synchronized 内部会升级为重量级锁,此时仅能有一个线程进入代码块执行,如果这把锁始终不能释放,其他线程会一直阻塞等待下去。此时,可以认为是悲观锁。
悲观锁会因线程一直阻塞导致系统上下文切换,系统的性能开销大。
那么,我们可以用乐观锁来解决,所谓的乐观锁,其实就是一种思想。
乐观锁,会以一种更加乐观的态度对待事情,认为自己可以操作成功。当多个线程操作同一个共享资源时,仅能有一个线程同一时间获得锁成功,在乐观锁中,其他线程发现自己无法成功获得锁,并不会像悲观锁那样阻塞线程,而是直接返回,可以去选择再次重试获得锁,也可以直接退出。
CAS 正是乐观锁的核心算法实现。
在示例代码的方案中都提到了 AtomicInteger、LongAdder、Lock锁底层,此外,当然还包括 java.util.concurrent.atomic 并发包下的所有原子类都是基于 CAS 来实现的。
以 AtomicInteger 原子整型类为例,一起来分析下 CAS 底层实现机制。
atomicData.incrementAndGet()
源码如下所示:
// 提供自增易用的方法,返回增加1后的值
public final int incrementAndGet() {
return unsafe.getAndAddInt(this, valueOffset, 1) + 1;
}
// 额外提供的compareAndSet方法
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
// Unsafe 类的提供的方法
public final int getAndAddInt (Object o,long offset, int delta){
int v;
do {
v = getIntVolatile(o, offset);
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
return v;
}
我们看到了 AtomicInteger 内部方法都是基于 Unsafe 类实现的,Unsafe 类是个跟底层硬件CPU指令通讯的复制工具类。
由这段代码看到:
unsafe.compareAndSwapInt(this, valueOffset, expect, update)
所谓的 CAS,其实是个简称,全称是 Compare And Swap,对比之后交换数据。上面的方法,有几个重要的参数:
(1)this,Unsafe 对象本身,需要通过这个类来获取 value 的内存偏移地址。
(2)valueOffset,value 变量的内存偏移地址。
(3)expect,期望更新的值。
(4)update,要更新的最新值。
如果原子变量中的 value 值等于 expect,则使用 update 值更新该值并返回 true,否则返回 false。
再看如何获得 valueOffset的:
// Unsafe实例
private static final Unsafe unsafe = Unsafe.getUnsafe();
private static final long valueOffset;
static {
try {
// 获得value在AtomicInteger中的偏移量
valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
// 实际变量的值
private volatile int value;
这里看到了 value 实际的变量,是由 volatile 关键字修饰的,为了保证在多线程下的 内存可见性 。
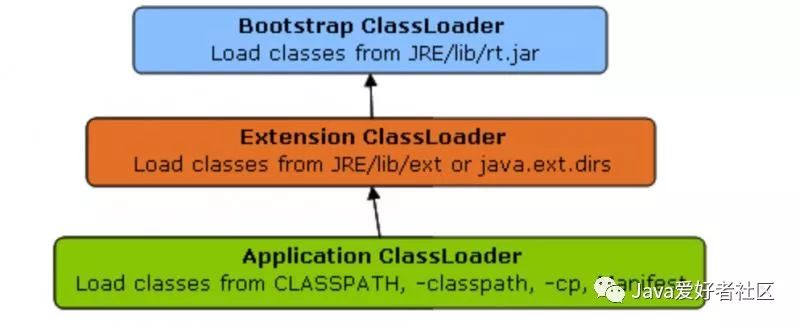
为何能通过 Unsafe.getUnsafe() 方法能获得 Unsafe 类的实例?其实因为 AtomicInteger 类也在 rt.jar 包下面的,所以 AtomicInteger 类就是通过 Bootstrap 根类加载器 进行加载的。
源码如下所示:
@CallerSensitive
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
// Bootstrap 类加载器是C++的,正常返回null,否则就抛异常。
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
类加载器委托关系:
4
CPU如何实现原子操作
CPU 处理器速度远远大于在主内存中的,为了解决速度差异,在他们之间架设了多级缓存,如 L1、L2、L3 级别的缓存,这些缓存离CPU越近就越快,将频繁操作的数据缓存到这里,加快访问速度 ,如下图所示:
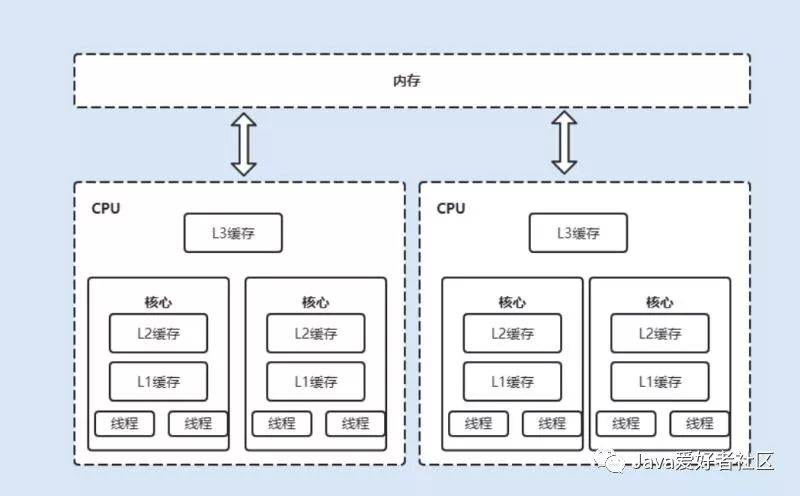
现在都是多核 CPU 处理器,每个 CPU 处理器内维护了一块字节的内存,每个内核内部维护着一块字节的缓存,当多线程并发读写时,就会出现缓存数据不一致的情况。
此时,处理器提供:
-
总线锁定
当一个处理器要操作共享变量时,在 BUS 总线上发出一个 Lock 信号,其他处理就无法操作这个共享变量了。
缺点很明显,总线锁定在阻塞其它处理器获取该共享变量的操作请求时,也可能会导致大量阻塞,从而增加系统的性能开销。
-
缓存锁定
后来的处理器都提供了缓存锁定机制,也就说当某个处理器对缓存中的共享变量进行了操作,其他处理器会有个嗅探机制,将其他处理器的该共享变量的缓存失效,待其他线程读取时会重新从主内存中读取最新的数据,基于 MESI 缓存一致性协议来实现的。
现代的处理器基本都支持和使用的缓存锁定机制。
注意:
有如下两种情况处理器不会使用缓存锁定:
(1)当操作的数据跨多个缓存行,或没被缓存在处理器内部,则处理器会使用总线锁定。
(2)有些处理器不支持缓存锁定,比如:Intel 486 和 Pentium 处理器也会调用总线锁定。
5
解密CAS底层指令
其实,掌握以上内容,对于 CAS 机制的理解相对来说算是比较清楚了。
当然,如果感兴趣,也可以继续深入学习用到了哪些硬件 CPU 指令。
底层硬件通过将 CAS 里的多个操作在硬件层面语义实现上,通过一条处理器指令保证了原子性操作。这些指令如下所示:
(1)测试并设置(Tetst-and-Set)
(2)获取并增加(Fetch-and-Increment)
(3)交换(Swap)
(4)比较并交换(Compare-and-Swap)
(5)加载链接/条件存储(Load-Linked/Store-Conditional)
前面三条大部分处理器已经实现,后面的两条是现代处理器当中新增加的。而且根据不同的体系结构,指令存在着明显差异。
在IA64,x86 指令集中有 cmpxchg 指令完成 CAS 功能,在 sparc-TSO 也有 casa 指令实现,而在 ARM 和 PowerPC 架构下,则需要使用一对 ldrex/strex 指令来完成 LL/SC 的功能。在精简指令集的体系架构中,则通常是靠一对儿指令,如: load and reserve 和 store conditional 实现的,在大多数处理器上 CAS 都是个非常轻量级的操作,这也是其优势所在。
sun.misc.Unsafe 中 CAS 的核心方法:
public final native boolean compareAndSwapObject(Object var1, long var2, Object var4, Object var5); public final native boolean compareAndSwapInt(Object var1, long var2, int var4, int var5); public final native boolean compareAndSwapLong(Object var1, long var2, long var4, long var6);
这三个方法可以对应去查看 openjdk 的 hotspot 源码:
源码位置: hotspot/src/share/vm/prims/unsafe.cpp
#define FN_PTR(f) CAST_FROM_FN_PTR(void*, &f)
{CC"compareAndSwapObject", CC"("OBJ"J"OBJ""OBJ")Z", FN_PTR(Unsafe_CompareAndSwapObject)},
{CC"compareAndSwapInt", CC"("OBJ"J""I""I"")Z", FN_PTR(Unsafe_CompareAndSwapInt)},
{CC"compareAndSwapLong", CC"("OBJ"J""J""J"")Z", FN_PTR(Unsafe_CompareAndSwapLong)},
上述三个方法,最终在 hotspot 源码实现中都会调用统一的 cmpxchg 函数,可以在 hotspot 源码中找到核心代码。
源码地址: hotspot/src/share/vm/runtime/Atomic.cpp
cmpxchg 函数源码:
jbyte Atomic::cmpxchg(jbyte exchange_value, volatile jbyte*dest, jbyte compare_value) {
assert (sizeof(jbyte) == 1,"assumption.");
uintptr_t dest_addr = (uintptr_t) dest;
uintptr_t offset = dest_addr % sizeof(jint);
volatile jint*dest_int = ( volatile jint*)(dest_addr - offset);
// 对象当前值
jint cur = *dest_int;
// 当前值cur的地址
jbyte * cur_as_bytes = (jbyte *) ( & cur);
// new_val地址
jint new_val = cur;
jbyte * new_val_as_bytes = (jbyte *) ( & new_val);
// new_val存exchange_value,后面修改则直接从new_val中取值
new_val_as_bytes[offset] = exchange_value;
// 比较当前值与期望值,如果相同则更新,不同则直接返回
while (cur_as_bytes[offset] == compare_value) {
// 调用汇编指令cmpxchg执行CAS操作,期望值为cur,更新值为new_val
jint res = cmpxchg(new_val, dest_int, cur);
if (res == cur) break;
cur = res;
new_val = cur;
new_val_as_bytes[offset] = exchange_value;
}
// 返回当前值
return cur_as_bytes[offset];
}
源码中具体变量添加了注释,因为都是 C++ 代码,所以作为了解即可 ~
jint res = cmpxchg(new_val, dest_int, cur);
这里就是调用了汇编指令 cmpxchg 了,其中也是包含了三个参数,跟CAS上的参数能对应上。
6
总结
任何技术都要找到适合的场景,都不是万能的,CAS 机制也一样,也有副作用。
问题1:
作为乐观锁的一种实现,当多线程竞争资源激烈的情况下,而且锁定的资源处理耗时,那么其他线程就要考虑自旋的次数限制,避免过度的消耗 CPU。
另外,可以考虑上文示例代码中提到的 LongAdder 来解决,LongAdder 以空间换时间的方式,来解决 CAS 大量失败后长时间占用 CPU 资源,加大了系统性能开销的问题。
问题2:
A-->B--->A 问题,假设有一个变量 A ,修改为B,然后又修改为了 A,实际已经修改过了,但 CAS 可能无法感知,造成了不合理的值修改操作。
整数类型还好,如果是对象引用类型,包含了多个变量,那怎么办?加个版本号或时间戳呗,没问题!
JDK 中 java.util.concurrent.atomic 并发包下,提供了 AtomicStampedReference ,通过为引用建立个 Stamp 类似版本号的方式,确保 CAS 操作的正确性。
希望此文大家收藏消化,CAS 在JDK并发包底层实现中是个非常重要的算法。
撰文不易,文章中有什么问题还请指正! 顺便给个「在看」?
往期精选
作为一名程序员,你真正了解CDN技术吗?
分布式理论之ZAB一致性协议图解
MySQL性能优化-常见SQL错误用法
通过一个生活中的案例场景,揭开并发包底层AQS的神秘面纱
由一次线上故障来理解下TCP三握、四挥 & Java堆栈分析到源码的探秘
扫描下方二维码关注,原创干货及时推送

嗨,我就知道你在看!
正文到此结束
- 本文标签: 缓存 https 安全 内存模型 实例 总结 Atom 模型 类加载器 源码 cat 多线程 DOM final Security 高并发 测试 压力 API 程序员 锁 文章 分布式 原子类 协议 线程 NSA 空间 volatile ACE id synchronized CST ssl swap Bootstrap TCP Java内存模型 http 希望 JVM 并发 update tar 数据 注释 参数 src IO bus stream java UI 时间 二维码 详细分析 数据缓存 性能优化 zab mysql CDN sql 代码 value 同步 处理器 一致性
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

