细数那些年遇到过Mybatis的这些坑!案例+解决方案
作者:似水的流年
原文链接:
https://yq.aliyun.com/roundtable/49835
大多数开发者应该都使用过Hibernate或者Mybatis的框架,或多或少都踩过一些坑!
如在MyBatis/Ibatis中#和$的区别,#方式能够很大程度防止sql注入,$方式无法防止Sql注入。 所以,老司机 对新手说,最好用#。 简单的说#{}是经过预编译的,是安全的,而是未经过预编译的,仅仅是取变量的值,是非安全的,存在sql注入。有些特例是需要关注的,有的时候需要用 解决解决一些实际问题。
如在执行sql语句时你有时并不希望让变量进行处理,而是直接赋值执行,这时就要用到(${a})了,在使用时还要这样赋值 @Param(value="a") String a
如日期问题:
可能会遇到日期格式的时间段问题,当数据库的时间为DATE类型时,MyBatis的jdbcType应该使用DATE
jdbcType=DATE,
而不是使用
jdbcType=TIMESTAMP
如在使用resultMap的时候,要把ID写在第一行,否则的话,就会报错。
又如最近在做的项目,遇到myBatis的大坑, Mybatis一直报异常:
Java.lang.ArrayIndexOutOfBoundsException,
于是开始代码查错,代码中有存储过程,然后开发使用ROOT用户执行SQL跑出来的数据结果集是正常的,在测试环境程序运行也正常,但是在正式环境就其他用户不行,最后发现是因为数据库没有给该用户授权出了问题。
案例一:
作为新手,在此记下刚踩的一个坑,(踩踩更健康= =踩过痛过才不会再次错),写了一个sql语句用到两张表,两张表中有两个字段名字是一样的都是Time和Content,然后要查询这两张表的这两个字段都要查出来放到一个dto中,dto如下图所示,
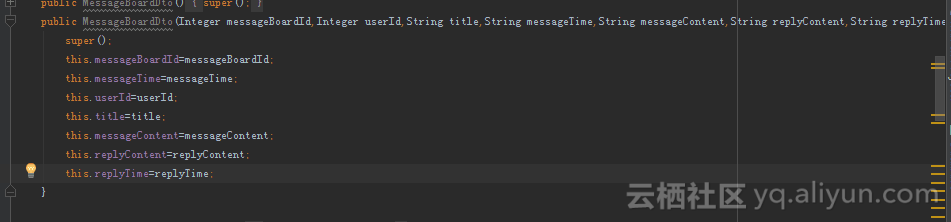
sql语句如下,

然而运行后却发现后几个在数据库表里同名的字段取出来都是null,

但是放到数据库那边执行是没有取出空数据的,
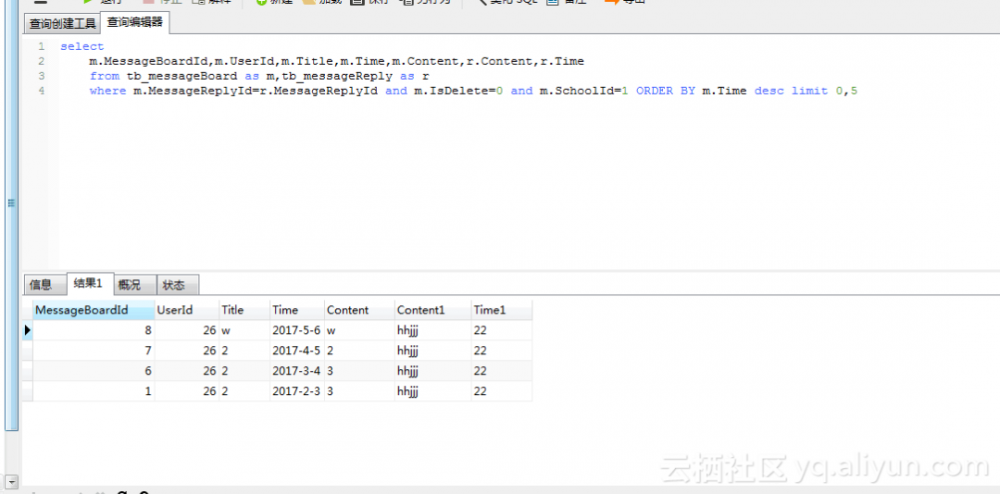
真是苦恼= =,后来经大神指点,sql语句查询出来的这个字段名必须和dto的参数名一致,改成这样就通过了,

数据都取出来了。 。 。 。 。 。 。 。 。 。 还记得在hibernate里用hql时放到dto里,select new dto名()参数顺序和类型一致就可以取出来。 。 。 这应该算一个不同点吧,,感觉还是hql用起来舒服,,,求大神科普两者的差别优缺点
当实体类中的属性名和表中的字段名不一致时,使用MyBatis进行查询操作时无法查询出相应的结果的问题,当时上网查了很多才知道,看到的一个解决方法分享给大家,通过来映射字段名和实体类属性名的一一对应关系。 这种方式是使用MyBatis提供的解决方式来解决字段名和属性名的映射关系的!
案例二:
数据库表使用了联合主键,逆向生成的时候生成了两个实体类。 看起来别扭。 但还是可以用。 后来就先取消主键,生成完后再将主键加上。 还有就是,tinyint本来以为用来表示比较小的整数,结果生成了布尔型的属性。 后来就表示是和否才用tinyint了。 逆向生成的sql语句绝对不能人为改动,否则再次生成的时候会重复生成。 但是,尽管踩过坑,我还是觉得mybatis超级好用,比hibernate好多了。 虽然hibernate我只试过一点之后就完全转向了mybatis了。
案例三:
sum()和count()使用场景不对导致出错:
count()、count(1)、count(0)就是指绝对的行数,哪怕某行所有字段全部为null也会计算在内。 count(1)和count()相比,innodb来说count(*)效率低。
如果count(列名)查询出来的结果就是查出列名中不为null的行数;
sum(列名)对指定列名进行求和
MyBatis把int类型的0处理成空串’’和mysql处理空串’’为0的问题,在Mybatis的Mapper中整数类型条件该如何判断?
当数据库字段类型是整数,如果参数变量为空字符串或者NULL,Mybatis会自动将参数赋值0,所以如果要判断整数参数的多种状态在传递数值到Mapper之前就要判断是否为空字符串和NULL并将相应的状态数值赋值给该参数,否则参数值等于空字符串、NULL和0得到的结果是一样的。
一般情况下,涉及到int类型的操作的时候,在Service中会统一把数字类型先变成字符串类型,然后再传递到Mapper中操作。
时间戳的使用
在创建新记录的时候把这个字段设置为当前时间,但以后修改时,不再刷新它(可以给createtime使用这个):
TIMESTAMP DEFAULT CURRENT_TIMESTAMP
在创建新记录和修改现有记录的时候都对这个数据列刷新(可以给update使用这个):
TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
在使用resultMap的时候,要把ID写在第一行,否则的话,就会报错。
案例四:
XML转义字符,如果直接写就会报错,需要用左边一列的转义字符
< < 小于号 > > 大于号
& & 和
' ' 单引号
" " 双引号
案例五:
前几天在项目中碰到,来说下吧。 大神可绕道。 在使用selectOne查询个数时,
如果你写了resultType为Integer,然后在业务代码中很自然的用一个变量int去接当前这个方法的返回,如果按照你传入的条件在数据库中没有找到相关的值,此时selectOne方法的返回值会是一个null,当你使用Java的自动拆箱机制的时候会报出一个无情的NPE。
原因: Java在自动拆箱的时候会调用Integer类中的intValue方法,如果当前对象为null,则抛出NPE。
因此,在接受的时候要判空,否则可能异常。
案例六:
多参数的使用
MyBatis的查询或者更新中,如果需要多个参数有如下几种办法:
对象映射,建立一个Java对象,并作为接口的参数,对象的属性可以直接使用#{属性名}的方式访问;
Map, 参数为一个Map, key对于属性名,value对于参数值,这个方法就是传参数是需要建立一个Map的临时对象;
@param参数注解,在接口方法参数前加入参数名称注解,这样就可以直接在Mapper中通过参数名访问;
通过序号访问,第一个参数#{0}或#{param1}, 第二个参数#{1}, #{param2}
MyBatis中时间字段的使用–返回;
时间字段的返回目前笔者采用放回字符串的方式:
date_format(update_time, ‘%Y-%c-%d %H:%i:%s’) updatetime
采用MySQL的时间格式化方法。
或者放回Timestamp类型的数据,要求放回对象属性参数为Timestamp.
MyBatis中时间字段的使用–参数
如果需要查询一段时间范围的数据时,可以通过以下动态SQL的方式查询数据:
and lbr.update_time > #{startTime}
and lbr.update_time < #{endTime, javaType=Date, jdbcType=TIMESTAMP}
对于的接口方法名称如下:
… Date startTime, Date endTime…
我想这个方法会比通过格式转换的效率要高一些
MyBatis中时间字段的使用–写入
写入可是直接写入Timestamp的数据,需要描述一些写入的jdbcType,如下:
{installTime, jdbcType=TIMESTAMP}
Mapper层参数为Map,由Service层负责重载。
Mapper由于机制的问题,不能重载,参数一般设置成Map,但这样会使参数变得模糊,如果想要使代码变得清晰,可以通过service层来实现重载的目的,对外提供的Service层是重载的,但这些重载的Service方法其实是调同一个Mapper,只不过相应的参数并不一致。
也许有人会想,为什么不在Service层也设置成Map呢? 我个人是不推荐这么做的,虽然为了方便,我在之前的项目中也大量采用了这种方式,但很明显会给日后的维护工作带来麻烦。 因为这么做会使你整个MVC都依赖于Map模型,这个模型其实是很不错的,方便搭框架,但存在一个问题: 仅仅看方法签名,你不清楚Map中所拥有的参数个数、类型、每个参数代表的含义。
试想,你只对Service层变更,或者DAO层变更,你需要清楚整个流程中Map传递过来的参数,除非你注释或者文档良好,否则必须把每一层的代码都了解清楚,你才知道传递了哪些参数。 针对于简单MVC,那倒也还好,但如果层次复杂之后,代码会变得异常复杂,而且如果我增加一个参数,需要把每一个层的注释都添加上。 相对于注释,使用方法签名来保证这种代码可控性会来得更可行一些,因为注释有可能是过时的,但方法签名一般不太可能是陈旧的。
尽量少用if choose等语句,降低维护的难度。
Mybatis的配置SQL时,尽量少用if choose 等标签,能用SQL实现判断的尽量用SQL来判断(CASE WHEN ,DECODE等),以便后期维护。 否则,一旦SQL膨胀,超级恶心,如果需要调试Mybatis中的SQL,需要去除大量的判断语句,非常麻烦。 另一方面,大量的if判断,会使生成的SQL中包含大量的空格,增加网络传输的时间,也不可取。
而且大量的if choose语句,不可避免地,每次生成的SQL会不太一致,会导致ORACLE大量的硬解析,也不可取。
我们来看看这样的SQL:

这样的if判断,其实是完全没有必要的,我们可以很简单的采用DECODE来解决默认值问题:

当然有人会想,引入CASE WHEN,DECODE会导致需要ORACLE函数解析,会拖慢SQL执行时间,有兴趣的同学可以回去做一下测试,看看是否会有大的影响。就个人经验而言,在我的开发过程,没有发现因为函数解析导致SQL变慢的情形。影响SQL执行效率的一般情况下是JOIN、ORDER BY、DISTINCT、PARTITATION BY等这些操作,这些操作一般与表结构设计有很大的关联。相对于这些的效率影响程度,函数解析对于SQL执行速度影响应该是可以忽略不计的。
另外一点,对于一些默认值的赋值,像上面那条SQL,默认成当前日期什么的,其实可以完全提到Service层或Controller层做处理,在Mybatis中应该要少用这些判断。 因为,这样的话,很难做缓存处理。 如果startdate为空,在SQL上使用动态的SYSDATE,就无法确定缓存startdate日期的key应该是什么了。 所以参数最好在传递至Mybatis之前都处理好,这样Mybatis层也能减少部分if choose语句,同时也方便做缓存处理。
当然不使用if choose也并不是绝对的,有时候为了优化SQL,不得不使用if来解决,比如说LIKE语句,当然一般不推荐使用LIKE,但如果存在使用的场景,尽可能在不需要使用时候去除LIKE,比如查询文章标题,以提高查询效率。 最好的方式是使用lucence等搜索引擎来解决这种全文索引的问题。
总的来说,if与choose判断分支是不可能完全去除的,但是推荐使用SQL原生的方式来解决一些动态问题,而不应该完全依赖Mybatis来完成动态分支的判断,因为判断分支过于复杂,而且难以维护。
用XML注释取代SQL注释。
Mybatis中原SQL的注释尽量不要保留,注释会引发一些问题,如果需要使用注释,可以在XML中用来注释,保证在生成的SQL中不会存在SQL注释,从而降低问题出现的可能性。 这样做还有一个好处,就是在IDE中可以很清楚的区分注释与SQL。
现在来谈谈注释引发的问题,我做的一个项目中,分页组件是基于Mybatis的,它会在你写的SQL脚本外面再套一层SELECT COUNT(*) ROWNUM_ FROM (….) 计算总记录数,同时有另一个嵌套SELECT * FROM(…) WHERE ROWNUM > 10 AND RONNUM < 10 * 2这种方式生成分页信息,如果你的脚本中最后一行出现了注释,则添加的部分会成为注释的一部分,执行就会报错。 除此之外,某些情况下也可能导致部分条件被忽略,如下面的情况:
SELECT * FROM TEST
WHERE COL1 > 1 -- 这里是注释AND COL2 = #{a}
即使传入的参数中存在对应的参数,实际也不会产生效果,因为后面的内容实际上是被完全注释了。 这种错误,如果不经过严格的测试,是很难发现的。 一般情况下,XML注释完全可以替代SQL注释,因此这种行为应该可以禁止掉。
尽可能使用`#{}`,而不是`${}`.
Mybatis中尽量不要使用${},尽量这样做很方便开发,但是有一个问题,就是大量使用会导致ORACLE的硬解析,拖慢数据库性能,运行越久,数据库性能会越差。
对于一般多个字符串IN的处理,可以参考如下的解决方案:http://www.myexception.cn/sql/849573.html,基本可以解决大部分${}.
关于${},另一个误用的地方就是LIKE。
我这边还有个案例: 比如一些树型菜单,节点会设计成'01','0101',用两位节点来区分层级,这时候,如果需要查询01节点下所有的节点,最简单的SQL便是:SELECT * FROM TREE WHERE ID LIKE '01%',这种SQL其实无可厚非,因为它也能用到索引,所以不需要特别的处理,直接使用就行了。
但如果是文章标题,则需要额外注意了: SELECT * FROM T_NEWS_TEXT WHERE TITLE LIKE '%OSC%',这是怎么也不会用到索引的,上面说了,最好采用全文检索。 但如果离不开LIKE,就需要注意使用的方式: ID LIKE #{ID} || '%'而不是ID LIKE '
有人觉得使用||会增加ORACLE处理的时间,我觉得不要把ORACLE看得太傻,虽然有时候确实非常傻,有空可以再总结ORACLE傻不垃圾的地方,但是稍加测试便知: 这种串联方式,对于整个SQL的解析执行,应该是微乎其微的。
当然还有一些特殊情况是没有办法处理的,比如说动态注入列名、表名等。 对于这些情况,则比较棘手,没有找到比较方便的手段。
由于这种情况出现的可能性会比较少,所以使用ID有人觉得使用∣∣会增加ORACLE处理的时间,我觉得不要把ORACLE看得太傻,虽然有时候确实非常傻,有空可以再总结ORACLE傻不垃圾的地方,但是稍加测试便知: 这种串联方式,对于整个SQL的解析执行,应该是微乎其微的。
当然还有一些特殊情况是没有办法处理的,比如说动态注入列名、表名等。 对于这些情况,则比较棘手,没有找到比较方便的手段。
由于这种情况出现的可能性会比较少,所以使用{}倒也不至于有什么太大的影响。 当然你如果有代码洁癖的话,可以使用ORACLE的动态执行SQL的机制Execute immediate,这样就可以完全避免${}出现的可能性了。 这样会引入比较复杂的模型,这个时候,你就需要取舍了。
针对于以上动态SQL所导致的问题,最激进的方式是全部采用存储过程,用数据库原生的方式来解决,方便开发调试,当然也会带来问题: 对开发人员会有更高的要求、存储过程的管理等等,我这边项目没有采用过这种方式,这里不做更多的展开。
简单使用Mybatis。
Mybatis的功能相对而言还是比较弱的,缺少了好多必要的辅助库,字符串处理等等,扩展也比较困难,一般也就可能对返回值进行一些处理。 因此最好仅仅把它作为单纯的SQL配置文件,以及简单的ORM框架。 不要尝试在Mybatis中做过多的动态SQL,否则会导致后续的维护非常恶心。
几点技巧总结:
1、查询很多字段时可以提出来再引入到sql语句
提取:
id, type, shopCouId, Path, fromDate, toDate, insDate, insUserId, updDate, updUserId, delFlg
引入:
select
from adinfo
where id = #{id,jdbcType=INTEGER}
2、如果sql语句中需要使用<, >, "" 符号时,需要使用< > " 或者
CDATA内部所有东西都会被解析器忽略
select type, shopCouId, Path
from adinfo
WHERE delFlg ='0'
and fromDate < #{date} and toDate >= #{date}
3、缓存使用
在增删查改时,可以使用缓存属性控制数据缓存
4、可以判断传进来的参数,再进行操作
and langCd = #{langCd,jdbcType=VARCHAR}
5、可以在sql语句中直接进行加减乘除计算,模糊查询时,需要注意使用方式
SELECT sum(b.netCnt) + #{netCnt,jdbcType=INTEGER}
FROM collectcnt b
WHERE b.shopId = #{shopId,jdbcType=INTEGER}
AND b.delflg = '0'
newCnt = newCnt + 1,
netCnt = netCnt +1,
sumCnt = sumCnt + 1,
AND o.oTime LIKE CONCAT('%',#{sdate},'%')
MyBatis把int类型的0处理成空串’’和mysql处理空串’’为0的问题
当数据库字段类型是整数,如果参数变量为空字符串或者NULL,Mybatis会自动将参数赋值0,所以如果要判断整数参数的多种状态在传递数值到Mapper之前就要判断是否为空字符串和NULL并将相应的状态数值赋值给该参数,否则参数值等于空字符串、NULL和0得到的结果是一样的。
一般情况下,涉及到int类型的操作的时候,在Service中会统一把数字类型先变成字符串类型,然后再传递到Mapper中操作。
案例七:
使用mybatis 进行批量insert的时候 会自动封装成一个map key是list 要存的数据变成了数组 需要注意在xml里面如果使用自己定义的collection要在传参时定义一个mapkey是自己定义的变量名哦。
在使用resultMap的时候,要把ID写在第一行,否则的话,就会报错。
优缺点
总结下mybatis的优缺点,以便大家对于mybatis的了解能更全面些。 但我所说的优缺点,仅是我个人总结并结合使用体验后得出的结果,并不能代表大众想法,因此才以“浅谈”作为文章标题。 如果大家的见解与我不同,欢迎积极提出来一块讨论,我也借以弥补自己认识的不足和短见。
优点:
-
易于上手和掌握。
-
sql写在xml里,便于统一管理和优化。
-
解除sql与程序代码的耦合。
-
提供映射标签,支持对象与数据库的orm字段关系映射
-
提供对象关系映射标签,支持对象关系组建维护
-
提供xml标签,支持编写动态sql。
缺点:
-
sql工作量很大,尤其是字段多、关联表多时,更是如此。
-
sql依赖于数据库,导致数据库移植性差。
-
由于xml里标签id必须唯一,导致DAO中方法不支持方法重载。
-
字段映射标签和对象关系映射标签仅仅是对映射关系的描述,具体实现仍然依赖于sql。 (比如配置了一对多Collection标签,如果sql里没有join子表或查询子表的话,查询后返回的对象是不具备对象关系的,即Collection的对象为null)
-
DAO层过于简单,对象组装的工作量较大。
-
不支持级联更新、级联删除。
-
编写动态sql时,不方便调试,尤其逻辑复杂时。
8 提供的写动态sql的xml标签功能简单(连struts都比不上),编写动态sql仍然受限,且可读性低。
-
若不查询主键字段,容易造成查询出的对象有“覆盖”现象。
-
参数的数据类型支持不完善。 (如参数为Date类型时,容易报没有get、set方法,需在参数上加@param)
-
多参数时,使用不方便,功能不够强大。 (目前支持的方法有map、对象、注解@param以及默认采用012索引位的方式)
-
缓存使用不当,容易产生脏数据。
总结:
mybatis的优点其实也是mybatis的缺点,正因为mybatis使用简单,数据的可靠性、完整性的瓶颈便更多依赖于程序员对sql的使用水平上了。 sql写在xml里,虽然方便了修改、优化和统一浏览,但可读性很低,调试也非常困难,也非常受限,无法像jdbc那样在代码里根据逻辑实现复杂动态sql拼接。 mybatis简单看就是提供了字段映射和对象关系映射的jdbc,省去了数据赋值到对象的步骤而已,除此以外并无太多作为,不要把它想象成hibernate那样强大,简单小巧易用上手,方便浏览修改sql就是它最大的优点了。
mybatis适用于小型且程序员能力较低的项目和人群使用,对于中大型项目来说我并不推荐使用,如果觉得hibernate效率低的话(实际上也是使用不当所致,hibernate是实际上是不适用于拥有高负载的工程项目),还不如直接用spring提供的jdbc简单框架(Template),同样支持对象映射。
正文到此结束
- 本文标签: 解决方法 Service iBATIS 测试环境 编译 数据库 UI 时间 XML 一对多 文章 Collection 缓存 root Oracle 配置 代码 Select 参数 删除 IO JDBC update tar map 可控性 解析 http 数据缓存 索引 java sql 管理 HTML 分页 src SQL执行 模型 spring https 安全 IDE 程序员 mybatis dist 动态SQL id mysql db 搜索引擎 数据 App list 总结 mapper 希望 tab 标题 调试 CTO value 开发 ORM MQ 测试 cat 开发者 注释 key
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

