初识爬虫的那天,我选择了Java

本科时,毕业论文需要不少网络上用户的问答数据。那时,我还没有搞过网络爬虫,只能利用关键词搜索的方式,找到相关数据,然后一条一条复制。我也觉得这样很傻,但不得不承认这确实我最初的操作方式,很艰难,累的手疼。

后来,读研究生时,做项目的同时还要搞科研。项目和科研,都需要采集大量的网络数据。领头做项目的师兄,指定了一系列国内外网站,并把采集任务分配给我。对于当时啥都不咋会的我,内心“啥?这该咋弄啊?这咋弄啊?……”可是没办法,即便瑟瑟发抖,硬着头皮还是要上。
好在有着师兄指点,让我去学习网路爬虫,说网路爬虫可以搞定“我想要的数据”。为了“活”下去,我决定放手一搏,但在学习准备阶段我就遇到了我的第一个“爬虫难题”。


决定要用网络爬虫去采集数据,面临一个选择就是:是用Java还是Python写网络爬虫呢?对于一个新手,我翻阅了网上各种对比的帖子,各有各的观点,其中不少说Python上手容易,写起来方便。但最终我还是选择了Java,有以下几点原因:
1.Java火了很多年,而且依旧很火,其生态也比较完善。目前,很多大公司的系统皆采用Java设计,足以说明其强大之处。把Java学好了,足够让我找一份不错的工作,即入职大厂。
2.Java严谨规范,对于大型工程、大型程序,如果不规范不严谨维护岂不容易出问题。
3.对网络爬虫而言,JAVA中也有很多简单易用的类库(如Jsoup、Httpclient等),同时还存在不少易于二次开发的网络爬虫框架(Crawler4J、WebMagic等)。
4.曾在一个帖子中看到,“世界上99%的人都会选择一条容易走的大路,因为人都喜欢安逸。这也是人的大脑的思维方式决定的,因为大脑的使命是为了让你生存,而不是求知。但成功是总是属于那1%的人,这类人是坚持让大脑做不愿意做的事的人——求知”。哎,这在我看来,还真有一定的道理。如果励志想成为一名真正的程序员,建议先学习Java。在此基础上,如果你对Python感兴趣,也是可以快速上手的。

1 网络爬虫流程
学习网络爬虫之前,先看了普通网络爬虫大致流程,如下图所示:
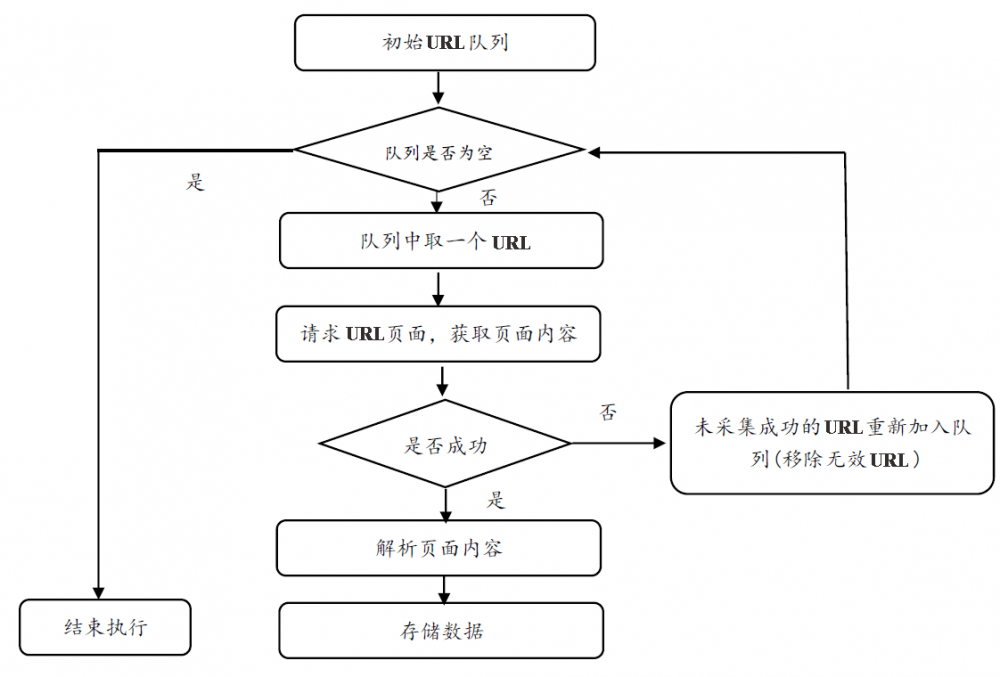
主要包括5个步骤:
1.选取部分种子URL(或初始URL),将其放入待采集的队列中。如在Java中,可以放入List、LinkedList以及Queue中。
2.判断URL队列是否为空,如果为空则结束程序的执行,否则执行步骤3。
3.从待采集的URL队列中取出一个URL,获取URL对应的网页内容。在此步骤需要使用HTTP响应状态码(如200和403等)判断是否成功获取到了数据,如响应成功则执行解析操作;如响应不成功,则将其重新放入待采集URL队列(注意这里需要过滤掉无效URL)。
4.针对响应成功后获取到的数据,执行页面解析操作。此步骤根据用户需求获取网页内容中的部分字段,如汽车论坛帖子的id、标题和发表时间等。
5.针对步骤4解析的数据,执行数据存储操作。
2 需要掌握的Java基础知识
在使用Java构建网络爬虫时,需要掌握很多Java方面的基础知识。例如,Java中基本的数据类型、Java中的数组操作、判断语句的使用、集合操作、对象和类的使用、String类的使用、日期和时间的处理、正则表达式的使用、Maven工程的创建、多线程操作、日志的使用等。

看着知识点很多,但如果将其放入到具体的网络爬虫实战项目中去学习,会发现很简单。下面,我举两个例子。
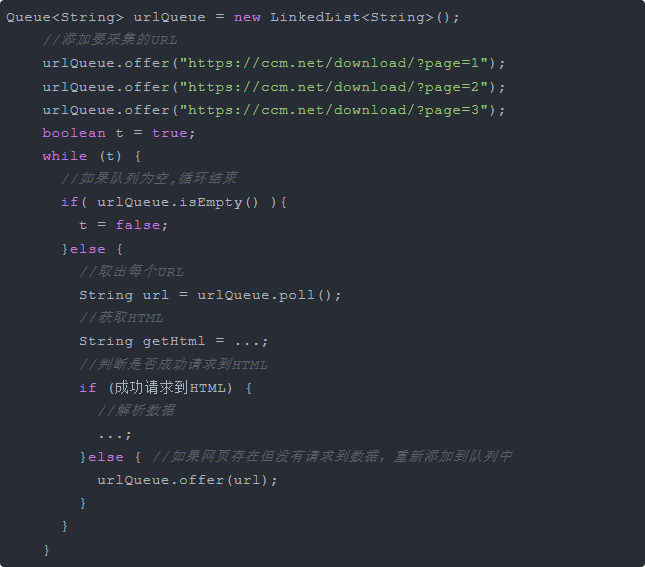
在网络爬虫中,我们经常需要将待采集的URL放到集合中,然后循环遍历集合中的每个URL去采集数据。比如,我们使用Queue集合操作:
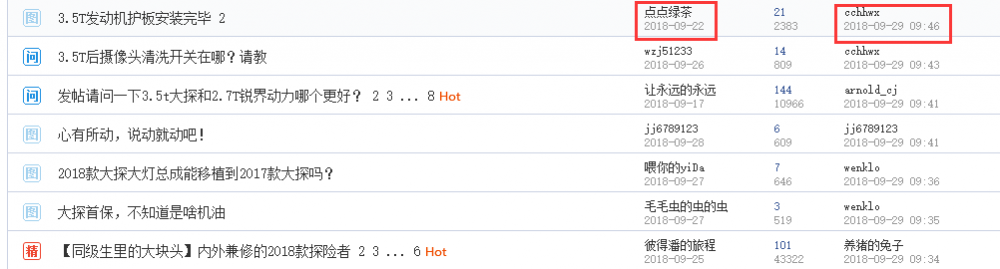
另外,在采集数据时,不同网站的时间使用格式可能不同。而不同的时间格式,会为数据存储以及数据处理带来一定的困难。例如,下图为某汽车论坛中时间使用的格式,即“yyyy-MM-dd”和“yyyy-MM-dd HH:mm”两种类型。
下图为某新闻网站中的时间使用格式“yyyy-MM-dd HH  ss”。
ss”。
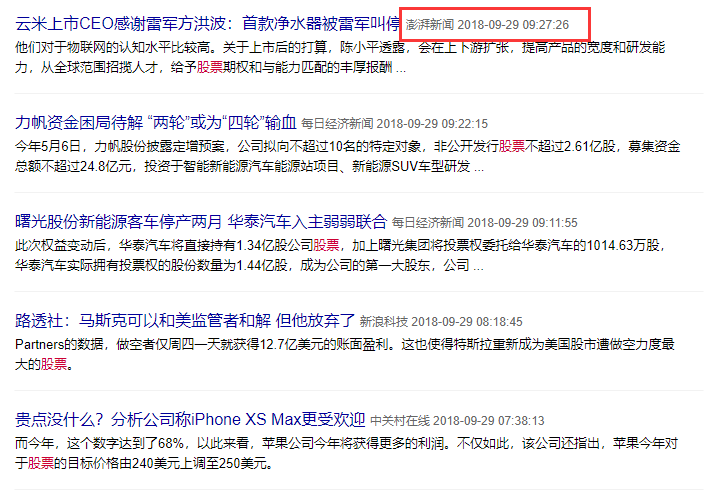
再如,艺术品网站deviantart的时间使用的是UNIX时间戳的形式。

针对汽车论坛中的“yyyy-MM-dd”和“yyyy-MM-dd HH:mm”格式,可以统一转化成“yyyy-MM-dd HH  ss”格式,以方便数据存储以及后期数据处理。此时,可以写个方法将将字符串类型的时间标准化成指定格式的时间。如下程序:
ss”格式,以方便数据存储以及后期数据处理。此时,可以写个方法将将字符串类型的时间标准化成指定格式的时间。如下程序:
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
public class TimeTest {
public static void main(String[] args) {
System.out.println(parseStringTime("2016-05-19 19:17",
"yyyy-MM-dd HH:mm","yyyy-MM-dd HH:mm:ss"));
System.out.println(parseStringTime("2018-06-19",
"yyyy-MM-dd","yyyy-MM-dd HH:mm:ss"));
}
/**
* 字符型时间格式标准化方法
* @param inputTime(输入的字符串时间),inputTimeFormat(输入的格式),outTimeFormat(输出的格式).
* @return 转化后的时间(字符串)
*/
public static String parseStringTime(String inputTime,String inputTimeFormat,
String outTimeFormat){
String outputDate = null;
try {
//日期格式化及解析时间
Date inputDate = new SimpleDateFormat(inputTimeFormat).parse(inputTime);
//转化成新的形式的字符串
outputDate = new SimpleDateFormat(outTimeFormat).format(inputDate);
} catch (ParseException e) {
e.printStackTrace();
}
return outputDate;
}
}
针对UNIX时间戳,可以通过如下方法处理:
//将unix时间戳转化成指定形式的时间
public static String TimeStampToDate(String timestampString, String formats) {
Long timestamp = Long.parseLong(timestampString) * 1000;
String date = new SimpleDateFormat(formats,
Locale.CHINA).format(new Date(timestamp));
return date;
}
3 HTTP协议基础与网络抓包
做网络爬虫,还需要了解HTTP协议相关的内容,即要清楚数据是怎么在服务器和客户端传输的。

具体需要了解的内容包括:
1.URL的组成:如协议、域名、端口、路径、参数等。
2.报文:分为请求报文和响应报文。其中,请求报文包括请求方法、请求的URL、版本协议以及请求头信息。响应报文包括请求协议、响应状态码、响应头信息和响应内容。响应报文包括请求协议、响应状态码、响应头信息和响应内容。
3.HTTP请求方法:在客户端向服务器发送请求时,需要确定使用的请求方法(也称为动作)。请求方法表明了对URL指定资源的操作方式,服务器会根据不同的请求方法做不同的响应。网络爬虫中常用的两种请求方法为GET和POST。
4.HTTP状态码:HTTP状态码由3位数字组成,描述了客户端向服务器请求过程中发生的状况。常使用200判断网络是否请求成功。
5.HTTP信息头:HTTP信息头,也称头字段或首部,是构成HTTP报文的要素之一,起到传递额外重要信息的作用。在网络爬虫中,我们常使用多个User-Agent和多个referer等请求头来模拟人的行为,进而绕过一些网站的防爬措施。
6.HTTP响应正文:HTTP响应正文(或HTTP响应实体主体),指服务器返回的一定格式的数据。网络爬虫中常遇到需要解析的几种数据包括:HTML/XML/JSON。

在开发网络爬虫时,给定 URL,开发者必须清楚客户端是怎么向服务器发送请求的,以及客户端请求后服务器返回的数据是什么。只有了解这些内容,开发者才能在程序中拼接URL,针对服务返回的数据类型设计具体的解析策略。因此,网络抓包是实现网络爬虫必不可少的技能之一,也是网络爬虫开发的起点。
本文作者钱洋博士所著新书《网络数据采集技术:Java网络爬虫实战》现已上市。系统地介绍了网络爬虫的理论知识和基础工具,并且选取典型网站,采用案例讲解的方式介绍网络爬虫中涉及的问题,以增强大家的动手实践能力。
本书时候国内少见的Java爬虫宝典。与Python语言相比,使用Java语言进行网络数据采集,具有采集效率更高、框架性能更好、敏捷易用等优点,而且针对大型搜索引擎系统的数据采集工作更多使用Java语言,故本书值得大家学习。
█ 关 于 作 者
钱洋
合肥工业大学管理科学与工程系博士、CSDN博客专家。作为技术人员参与过多个横向、纵向学术课题,负责数据采集系统的设计与开发工作。在CSDN(博客名称:HFUT_qianyang)上撰写了多篇关于数据采集、自然语言处理、编程语言等领域的原创博客。
姜元春
合肥工业大学教授、博士生导师。长期从事电子商务、商务智能、数据采集与挖掘等方面的理论研究与教学工作。先后主持过国家自然科学基金优秀青年科学基金项目、国家自然科学基金重大研究计划培育项目、国家自然科学基金青年科学基金项目、教育部人文社科青年基金项目、阿里巴巴青年学者支持计划、CCF-腾讯犀牛鸟基金项目等课题的研究工作。
█ 大 咖 推 荐
•陈国青 / 清华大学教授、博士生导师
•程学旗 / 中国科学院计算技术研究所研究员、博士生导师
•卓训方 / 上海数据交易中心项目总监
•刘业政 / 合肥工业大学教授博士生导师
█ 本书内容结构
第 1 ~3 章
这3 章重点介绍与网络爬虫开发相关的基础知识,其中包括网络爬虫的原理、Java 基础知识和HTTP 协议等内容。
第 4~6 章
这3 章分别从网页内容获取、网页内容解析和网络爬虫数据存储3 个方面介绍网络爬虫开发过程中所涉及的一系列技术。在这3 章中,涉及很多开源工具的使用,如Jsoup、HttpClient、HtmlCleaner、Fastjson、POI3 等。
第 7 章
本章利用具体的实战案例,讲解网络爬虫开发的流程。通过对本章的学习,读者可以轻松开发Java 网络爬虫。
第 8 章
针对一些复杂的页面,如动态加载的页面(执行JavaScript 脚本),本章介绍了一款实用的工具——Selenium WebDriver。
第 9 章
本章重点介绍了3 种比较流行的Java 网络爬虫开源框架,即Crawler4j、WebCollector 和WebMagic。读者可根据数据采集需求,自行开发支持多线程采集、断点采集、代理切换等功能的网络爬虫项目。
正文到此结束
- 本文标签: list http ORM web js 标题 多线程 程序员 XML src JavaScript Agent java https 网站 管理 智能 json client queue LinkedList 正则表达式 ip cat 数据 CTO parse java基础 汽车 索引 maven 线程 开发者 域名 遍历 开源 python id 端口 教育 UI 时间 解析 开发 ACE MQ unix tar 基金 需求 jsoup 参数 关键词 HTTP协议 协议 阿里巴巴 电子商务 敏捷 博客 IO 服务器 励志 搜索引擎 SDN HTML
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

