《领域驱动设计之PHP实现》 - 架构风格
架构风格
对于构建复杂应用,一个关键点就是得有一个适合应用需求的架构设计。领域驱动设计的一个优势就是不必绑定到任何特定的架构风格之上。相反的,我们可以根据每个核心域内的限界上下文自由选择最佳的架构,限界上下文同时为每个特定领域问题提供了丰富多彩的架构选择。
例如,一个订单系统可以使用事件源(Event Sourcing)来追踪所有不同订单的操作;一个产品目录服务可以使用 CQRS 来暴露产品细节给不同客户端;一个内容管理系统可以使用一般的六边形架构来暴露如博客(blogs),静态页等服务。
从传统守旧派的 PHP 代码到更复杂先进的架构,本章将跟随这些历史来对 PHP 圈子内每个相关的架构风格做一些介绍。请注意尽管已经有许多其它存在的架构风格,例如数据网络架构(Data Fabric)或者面向服务架构(SOA),但我们发现从 PHP 的视角介绍它们还是有一些复杂的。
美好的旧时光
在 PHP4 发布之前 ,PHP 还没有拥抱面向对象模式。那时候,写应用的普遍方法就是用面向过程和全局状态。像关注点分离(SoC)和模型-视图-控制器(MVC)的概念是与当时的 PHP 社区相抵触的。
下面的例子就是用传统方式写的一个由许多混合了 HTML 代码前端控制器构成的应用。在那个时代,基础设施层,表现层,UI,及领域层代码都交织在一起:
<?php
include __DIR__ . '/bootstrap.php';
$link = mysql_connect('localhost', 'a_username', '4_p4ssw0rd');
if (!$link) {
die('Could not connect: ' . mysql_error());
}
mysql_set_charset('utf8', $link);
mysql_select_db('my_database', $link);
$errormsg = null;
if (isset($_POST['submit'] && isValid($_POST['post'])) {
$post = getFrom($_POST['post']);
mysql_query('START TRANSACTION', $link);
$sql = sprintf(
"INSERT INTO posts (title, content) VALUES ('%s','%s')",
mysql_real_escape_string($post['title']),
mysql_real_escape_string($post['content']
));
$result = mysql_query($sql, $link);
if ($result) {
mysql_query('COMMIT', $link);
} else {
mysql_query('ROLLBACK', $link);
$errormsg = 'Post could not be created! :(';
}
}
$result = mysql_query('SELECT id, title, content FROM posts', $link);
?>
<html>
<head></head>
<body>
<?php if (null !== $errormsg) : ?>
<div class="alert error"><?php echo $errormsg; ?></div>
<?php else: ?>
<div class="alert success">
Bravo! Post was created successfully!
</div>
<?php endif; ?>
<table>
<thead>
<tr>
<th>ID</th>
<th>TITLE</th>
<th>ACTIONS</th>
</tr>
</thead>
<tbody>
<?php while ($post = mysql_fetch_assoc($result)) : ?>
<tr>
<td><?php echo $post['id']; ?></td>
<td><?php echo $post['title']; ?></td>
<td><?php editPostUrl($post['id']); ?></td>
</tr>
<?php endwhile; ?>
</tbody>
</table>
</body>
</html>
<?php mysql_close($link); ?>
这种风格的代码就是我们常说的 大泥球 ,在第一章我们也提及过。下面的代码就做一些改进,然而仅仅是通过封装 header 和 footer 到单独的文件内,就可以避免重复及有利于重用:
<?php
include __DIR__ . '/bootstrap.php';
$link = mysql_connect('localhost', 'a_username', '4_p4ssw0rd');
if (!$link) {
die('Could not connect: ' . mysql_error());
}
mysql_set_charset('utf8', $link);
mysql_select_db('my_database', $link);
$errormsg = null;
if (isset($_POST['submit'] && isValid($_POST['post'])) {
$post = getFrom($_POST['post']);
mysql_query('START TRANSACTION', $link);
$sql = sprintf(
"INSERT INTO posts(title, content) VALUES('%s','%s')",
mysql_real_escape_string($post['title']),
mysql_real_escape_string($post['content'])
);
$result = mysql_query($sql, $link);
if ($result) {
mysql_query('COMMIT', $link);
} else {
mysql_query('ROLLBACK', $link);
$errormsg = 'Post could not be created! :(';
}
}
$result = mysql_query('SELECT id, title, content FROM posts', $link);
?>
<?php include __DIR__ . '/header.php'; ?>
<?php if (null !== $errormsg) : ?>
<div class="alert error"><?php echo $errormsg; ?></div>
<?php else: ?>
<div class="alert success">
Bravo! Post was created successfully!
</div>
<?php endif; ?>
<table>
<thead>
<tr>
<th>ID</th>
<th>TITLE</th>
<th>ACTIONS</th>
</tr>
</thead>
<tbody>
<?php while ($post = mysql_fetch_assoc($result)): ?>
<tr>
<td><?php echo $post['id']; ?></td>
<td><?php echo $post['title']; ?></td>
<td><?php editPostUrl($post['id']); ?></td>
</tr>
<?php endwhile; ?>
</tbody>
</table>
<?php include __DIR__ . '/footer.php'; ?>
现今,尽管这种方式令人沮丧,但仍有大量应用使用这种方式编写代码。这种风格的架构主要坏处是没有做到真正的关注点分离 - 维护和开发这样一个应用的持续成本与其它已知和已验证的架构相比急剧增长。
分层架构
从代码的可维护性和可重用性角度来看,使代码更容易维护的最好方式就是拆分的思想,即为每个不同的关注点分层。在我们之前的例子中,非常容易形成不同层次:一个是封装数据访问和操作,另一个是处理基础设施的关注点,最后一个即是封装前两者的编排。分层架构的一个基本原则就是-每一层都必须与其下一层紧密相连,如下图所示:
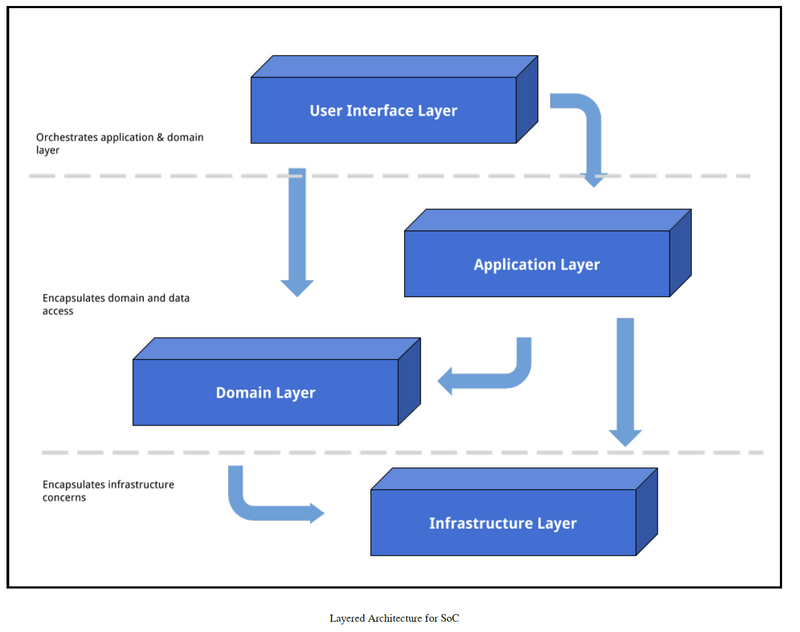
分层架构真正寻求的是对应用的不同组件进行分离。例如,在前面的例子当中,一个博客帖子的表示必须完全地独立于实体概念的博客帖子。一个博客帖子实体可以与一个或多个表示相关联。这就是通常所说的关注点分离。
另一种寻求相同目的的架构模式就是模型-视图-控制器模式。它最初被认为和广泛用于创建桌面 GUI 应用。现在主要应用于 web 应用。这得益于像 Symfony , Zend Framework 和 CodeIgniter 这些的流行框架。
模型-视图-控制器(MVC)
模型-视图-控制器模式将应用划分为三个主要层次,要点描述如下:
- 模型层 :提取和集中所有领域模型的行为。这一层独立管理表现层的所有数据,逻辑及业务规则。所有说模型层是每个 MVC 应用程序的心脏和灵魂。
- 控制层 :即其他两层之间的抽象编排,主要是触发模型的行为来更新其状态,以及刷新与模型关联的表现层。除此之外,控制层还能发送消息给视图层来改变特定的领域表现形式。
- 视图层 :暴露模型层的不同表现形式,同时提供改变模型状态的一些触发动作。
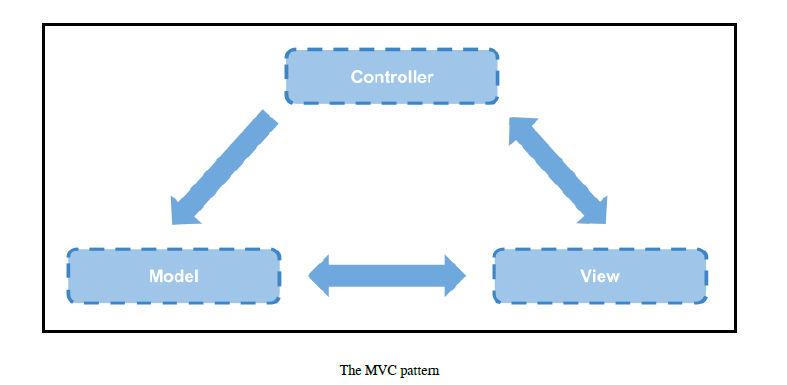
分层架构的示例
模型层
继续之前的例子,我们注意到不同的关注点需要被分离。为了达到这一点,所有层次都必须从我们这些原始的混乱代码中识别出来。在这个过程中,我们需要特别注意与模型层有关的代码,即应用的核心代码:
class Post
{
private $title;
private $content;
public static function writeNewFrom($title, $content)
{
return new static($title, $content);
}
private function __construct($title, $content)
{
$this->setTitle($title);
$this->setContent($content);
}
private function setTitle($title)
{
if (empty($title)) {
throw new RuntimeException('Title cannot be empty');
}
$this->title = $title;
}
private function setContent($content)
{
if (empty($content)) {
throw new RuntimeException('Content cannot be empty');
}
$this->content = $content;
}
}
class PostRepository
{
private $db;
public function __construct()
{
$this->db = new PDO(
'mysql:host=localhost;dbname=my_database',
'a_username',
'4_p4ssw0rd',
[
PDO::MYSQL_ATTR_INIT_COMMAND => 'SET NAMES utf8mb4',
]
);
}
public function add(Post $post)
{
$this->db->beginTransaction();
try {
$stm = $this->db->prepare(
'INSERT INTO posts (title, content) VALUES (?, ?)'
);
$stm->execute([
$post->title(),
$post->content(),
]);
$this->db->commit();
} catch (Exception $e) {
$this->db->rollback();
throw new UnableToCreatePostException($e);
}
}
}
模型层现在用一个 Post 类和一个 PostRepository 类定义。 Post 类表示一个博客帖子, PostRepository 类表示可用博客帖子的整个集合。除此之外,另一层 - 用来协调和编排这些领域行为 - 也是模型层内需要的。现在进入应用层:
class PostService
{
public function createPost($title, $content)
{
$post = Post::writeNewFrom($title, $content);
(new PostRepository())->add($post);
return $post;
}
}
PostService 类即我们所说的应用服务,它的目的是编排和组织领域行为。换句话说,应用服务是领域模型的直接客户端,是那些使业务发生的服务。没有其他类型的对象可以直接与模型层内部直接对话。
视图层
视图层可以从模型层和/或者控制层接收数据,也能向其发送数据。它的主要目的是向用户UI层呈现模型,同时在模型每次更新后刷新UI的呈现形式。一般来说,视图层接收的对象 - 通常是一个数据传输对象( DTO )而不是模型层实例 - 从而收集被成功呈现的所有必需信息。对于 PHP,这已经有几种模板引擎可以帮助从模型本身和从控制层分离模型的表示。其中最流行的一个叫 Twig 。让我们看看使用 Gwig 的视图层是怎样的。
为什么是数据传输对象(
DTO
)而不是模型实例?
这是一个古老且有活力的话题。为什么要创建一个 DTO 而不是把模型实例直接交给视图层?简短来说,还是关注点分离。让视图层方便直接使用模型实例将导致视图层与模型层间的紧耦合。事实上,模型层中的一个改变将可能破坏所有使用改变后的模型的所有视图。
{% extends "base.html.twig" %}
{% block content %}
{% if errormsg is defined %}
<div class="alert error">{{ errormsg }}</div>
{% else %}
<div class="alert success">
Bravo! Post was created successfully!
</div>
{% endif %}
<table>
<thead>
<tr>
<th>ID</th>
<th>TITLE</th>
<th>ACTIONS</th>
</tr>
</thead>
<tbody>
{% for post in posts %}
<tr>
<td>{{ post.id }}</td>
<td>{{ post.title }}</td>
<td><a href="{{ editPostUrl(post.id) }}">Edit Post</a></td>
</tr>
{% endfor %}
</tbody>
</table>
{% endblock %}
大多数时候,当模型触发一个状态改变,同时也会通知相关视图 UI 已经刷新了。在一个典型的 web 场景中,由于客户端-服务器这一约束,模型和它的表示之间的同步可能会有一点棘手。在这些情况下,通常要用一些 JavaScript 定义的交互方式来维护这些同步。由于这个原因,近年来 JavaScript MVC 框架开始变得广泛流行,正如下面这些框架:
- AngularJS
- Ember.js
- Marionette.js
- React
控制层
控制层主要负责组织和编排视图和模型。它接收来自视图层的消息和为了执行期望的动作而触发模型行为。此外,为了呈现模型的表示,它也发送消息给视图。被执行的动作也需要感谢应用层,即负责编排,组织和封装领域行为的这一层。
就一个 PHP 的 web 应用来说,控制层包括一组类,为了达到它们的目的,叫做 "HTTP" 。换句话说,它们接收一个 HTTP 请求,同时返回一个 HTTP 响应:
class PostsController
{
public function updateAction(Request $request)
{
if (
$request->request->has('submit') &&
Validator::validate($request->request->post)
) {
$postService = new PostService();
try {
$postService->createPost(
$request->request->get('title'),
$request->request->get('content')
);
$this->addFlash(
'notice',
'Post has been created successfully!'
);
} catch (Exception $e) {
$this->addFlash(
'error',
'Unable to create the post!'
);
}
}
return $this->render('posts/update-result.html.twig');
}
}
依赖倒置:六边形架构
依照分层架构的基本思想,当实现包含有关基础设施层的领域接口时,是存在风险的。
以 MVC 为例,先前例子中的 PostRepository 类应该放在领域模型当中。然而,把基础设施细节放在领域之中是违背关注点分离这一原则的.这是有问题的;它很难避免违背分层架构的基本思想,如果模型层有技术实现,这将会导致一种很难测试的代码类型出现。
依赖倒置原则(DIP)
我们可以怎样改进呢?由于领域模型层依赖基础设施的具体实现,依赖倒置原则(DIP),可以通过应将基础设施层重新放在其它三层之上来应用。
依赖倒置原则
高层次模型不应该依赖于低层次模型。它们都应该依赖于抽象。
抽象不应该依赖于细节,细节应该依赖于抽象。
-- Robert C.Martin
通过使用依赖倒置原则,架构模式改变了,基础设施层 - 可以称为低层次模块 - 现在依赖于 UI,应用层和模型层这些高层次模块。于是依赖被倒置了。
但什么是六边形架构呢?它是怎样适合这里面的所有问题呢?六边形架构(即端口与适配器)是 Alistair Cockburn 在他的书《六边形架构》中定义的。它将应用描述成一个六边形,每条边被表示为一个端口和多个适配器。端口是一个可插拔适配器的连接器件,适配器将外部输入转换为应用内部可理解的数据。就依赖倒置( DIP )来说,端口是高层次模块,适配器是低层次模块。此外,如果应用需要发送消息给外部,它可以用一个带适配器的端口来发送和转换可以被外部可理解的数据。正因为如此,六边形架构提出了应用里对称性的概念,这也是为什么架构模式发生变化的主要原因。它经常被表示为六边形,因为讨论顶层或者底层不再有任何意义。相反,六边形架构主要是外与内部间的对话。
如果你想要了解更多细节,Youtube 上有 Matthias Noback 关于六边形架构的非常好的视频
应用六边形架构
我们继续博客应用的例子,首先我们需要的概念就是端口,即外部世界与应用程序对话的渠道。在这个例子中,我们使用一个 HTTP 端口及相应的适配器,外部通过端口发送消息给应用程序。博客例子使用数据库存储整个博客帖子集合,所以为了让应用程序从数据库中检索博客帖子数据,端口就是必须的:
interface PostRepository
{
public function byId(PostId $id);
public function add(Post $post);
}
该接口暴露有关博客帖子的端口,应用程序通过它检索信息。它也被放置在领域层。现在,则需要这个端口的适配器。该适配器负责定义用特定技术检索博客帖子的方法:
class PDOPostRepository implements PostRepository
{
private $db;
public function __construct(PDO $db)
{
$this->db = $db;
}
public function byId(PostId $id)
{
$stm = $this->db->prepare(
'SELECT * FROM posts WHERE id = ?'
);
$stm->execute([$id->id()]);
return recreateFrom($stm->fetch());
}
public function add(Post $post)
{
$stm = $this->db->prepare(
'INSERT INTO posts (title, content) VALUES (?, ?)'
);
$stm->execute([
$post->title(),
$post->content(),
]);
}
}
只要我们定义了端口及其适配器,最后就是重构 PostService 从而可以它们。这可以通过依赖注入(Dependency Injection)轻松实现:
class PostService
{
private $postRepository;
public function __construct(PostRepositor $postRepository)
{
$this->postRepository = $postRepository;
}
public function createPost($title, $content)
{
$post = Post::writeNewFrom($title, $content);
$this->postRepository->add($post);
return $post;
}
}
这仅仅是六边形架构的一个简单例子,它是一个灵活的,类似分层,有利于关注点分离的架构。由于内部应用通过端口与外部通信,这也同时提升了对称性。从现在开始,这将作为基本架构来构建和解释 CQRS 及事件源模式。
想了解更多关于这种架构的例子,你可以去查看附录中的 《Hexagonal Architecture with PHP》 。对于一个更详细的例子,你可以跳到第 11 章 - 应用程序,此章介绍了一些高级主题,像事务性和其它交叉问题。
命令查询职责分离(CQRS)
六边形架构是一个很好的基础性架构,但它有一些限制。例如,复杂 UI 需要在不同的表单上显示聚合信息(第八章,聚合),或者它们可以从多个聚合获取数据。在这种场景下,我们可以在仓储里使用许多查找方法(可能和应用程序里存在的 UI 视图一样多)。或者,也许我们可以直接将这种复杂性转移到应用服务,使用复杂结构来从多个聚合里积累数据,这里有一个例子:
interface PostRepository
{
public function save(Post $post);
public function byId(PostId $id);
public function all();
public function byCategory(CategoryId $categoryId);
public function byTag(TagId $tagId);
public function withComments(PostId $id);
public function groupedByMonth();
// ...
}
当这些技术被滥用时,对 UI 视图层的构建将变得非常痛苦。我们应该权衡是该用应用服务返回领域实例还是某些 DTO 。后一种选择里,我们避免了领域模型与基础设施代码( web 控制器,CLI 控制器等等)间的紧耦合。
幸运的是,我们有另一种方法。如果需求有许多且独立的视图,我们可以将它们从领域模型中排除,把它们视为一种纯粹的基础设施问题。这种方法即基于一个设计原则,命令查询分离( CQS )。这个原则由 Bertrand Meyer 提出,然后,相应地,成长为一个全新的架构模式,叫作命令查询职责分离( CQRS ), CQRS 由 Greg Young 定义。
命令查询分离
提出一个问题不应该改变对应的答案 - Bertrand Meyer
这种设计原则提出每个方法应该要么是执行动作的命令,要么是返回数据给调用者的查询,而不是两者都是 - 维基百科
CQRS 谋求一种更为激进的关注点分离,即将模型分为两部分:
- 写模型: 同时也称为命令模型,它执行写入和负责真实的领域行为。
- 读模型: 它在应用内负责读取,并将这部分视为领域模型之外的内容。
每次只要触发一个命令给写模型,它就会执行渴求数据的存储写入。除此之外,它还会触发读模型的更新,保证在读模型上显示最后一次的更改。
这种严格的分离导致了另一个问题,最终一致性。读模型的一致性现在受写模型执行的命令的影响。换句话说,读模型是最终一致性的。也就是说,每次当写模型执行一个命令,它就会负责挂起一个进程,依照写模型上最后一次更改,来更新读模型。所以这里存在一个时间窗口,UI可能会向用户展示旧的信息。在 web 场景中,这种情况经常发生,因为我们受当前技术因素限制。
考虑一个 web 应用的缓存系统,每次用新信息数更新数据库时,缓存层的数据有可能是陈旧的,所以每当模型有更新时,也应该同时更新缓存系统。所以 缓存系统是最终一致性的。
这些处理过程,在 CQRS 术语中被称为写模型投影,或者就称作投影。即投影一个写模型到读模型上。这个过程可以是同步或者异步,取决于你的需要,同时它可以用另一种很有用的战术设计模式 - 领域事件(本书后面的章节会讲到)来实现。写模型投影的基本过程就是收集所有发布的领域事件,然后用事件中的信息来更新读模型。
写模型
写模型是领域行为的真实持有者,继续我们的例子,仓储接口将被简化如下:
interface PostRepository
{
public function save(Post $post);
public function byId(PostId $id);
}
现在 PostRepository 已经从所有读关注点中分离出来,除了一个: byId 方法,负责通过 ID 来加载聚合以便我们对其进行操作。那么只要这一步完成,所有的查询方法都将从 Post 模型中剥离出来,只留下命令方法。这意味着我们可以有效地摆脱所有getter方法和任何其它暴露 Post 聚合信息的方法。取而代之的是,通过订阅聚合模型来发布领域事件,以触发写模型投影:
class AggregateRoot
{
private $recordedEvents = [];
protected function recordApplyAndPublishThat(
DomainEvent $domainEvent
)
{
$this->recordThat($domainEvent);
$this->applyThat($domainEvent);
$this->publishThat($domainEvent);
}
protected function recordThat(DomainEvent $domainEvent)
{
$this->recordedEvents[] = $domainEvent;
}
protected function applyThat(DomainEvent $domainEvent)
{
$modifier = 'apply' . get_class($domainEvent);
$this->$modifier($domainEvent);
}
protected function publishThat(DomainEvent $domainEvent)
{
DomainEventPublisher::getInstance()->publish($domainEvent);
}
public function recordedEvents()
{
return $this->recordedEvents;
}
public function clearEvents()
{
$this->recordedEvents = [];
}
}
class Post extends AggregateRoot
{
private $id;
private $title;
private $content;
private $published = false;
private $categories;
private function __construct(PostId $id)
{
$this->id = $id;
$this->categories = new Collection();
}
public static function writeNewFrom($title, $content)
{
$postId = PostId::create();
$post = new static($postId);
$post->recordApplyAndPublishThat(
new PostWasCreated($postId, $title, $content)
);
}
public function publish()
{
$this->recordApplyAndPublishThat(
new PostWasPublished($this->id)
);
}
public function categorizeIn(CategoryId $categoryId)
{
$this->recordApplyAndPublishThat(
new PostWasCategorized($this->id, $categoryId)
);
}
public function changeContentFor($newContent)
{
$this->recordApplyAndPublishThat(
new PostContentWasChanged($this->id, $newContent)
);
}
public function changeTitleFor($newTitle)
{
$this->recordApplyAndPublishThat(
new PostTitleWasChanged($this->id, $newTitle)
);
}
}
所有触发状态改变的动作都通过领域事件来实现。对于每一个已发布的领域事件,都有一个对应的 apply 方法负责状态的改变:
class Post extends AggregateRoot
{
// ...
protected function applyPostWasCreated(
PostWasCreated $event
)
{
$this->id = $event->id();
$this->title = $event->title();
$this->content = $event->content();
}
protected function applyPostWasPublished(
PostWasPublished $event
)
{
$this->published = true;
}
protected function applyPostWasCategorized(
PostWasCategorized $event
)
{
$this->categories->add($event->categoryId());
}
protected function applyPostContentWasChanged(
PostContentWasChanged $event
)
{
$this->content = $event->content();
}
protected function applyPostTitleWasChanged(
PostTitleWasChanged $event
)
{
$this->title = $event->title();
}
}
读模型
读模型,同时也称为查询模型,是一个纯粹的从领域中提取的非规范化的数据模型。事实上,使用 CQRS,所有的读取侧都被视为基础设施关注的表述过程。一般来说,当使用 CQRS 时,读模型与 UI 所需有关,与组合视图的 UI 复杂性有关。在一个关系型数据库中定义读模型的情况下,最简单的方法就是建立数据表与 UI 视图一对一的关系。这些数据表和 UI 视图将用写模型投影更新,由写一侧发布的领域事件来触发:
-- Definition of a UI view of a single post with its comments CREATE TABLE single_post_with_comments ( id INTEGER NOT NULL, post_id INTEGER NOT NULL, post_title VARCHAR(100) NOT NULL, post_content TEXT NOT NULL, post_created_at DATETIME NOT NULL, comment_content TEXT NOT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci; -- Set up some data INSERT INTO single_post_with_comments VALUES (1, 1, "Layered" , "Some content", NOW(), "A comment"), (2, 1, "Layered" , "Some content", NOW(), "The comment"), (3, 2, "Hexagonal" , "Some content", NOW(), "No comment"), (4, 2, "Hexagonal", "Some content", NOW(), "All comments"), (5, 3, "CQRS", "Some content", NOW(), "This comment"), (6, 3, "CQRS", "Some content", NOW(), "That comment"); -- Query it SELECT * FROM single_post_with_comments WHERE post_id = 1;
这种架构风格的一个重要特征就是,读模型应该完全是一次性的,因为应用的真实状态是由写模型来处理。这意味着读模型在需要时,可以用写模型投影来移除和重建。
这里我们可以看到一个博客应用里的一些可能存在的视图的例子:
SELECT * FROM posts_grouped_by_month_and_year ORDER BY month DESC,year ASC; SELECT * FROM posts_by_tags WHERE tag = "ddd"; SELECT * FROM posts_by_author WHERE author_id = 1;
需要特别指出的是,CQRS 并不约束读模型的定义和实现要用关系型数据库,它取决于被构建的应用实际所需。它可以是关系型数据库,面向文档的数据库,键-值型存储,或任意适合应用所需的存储引擎。在博客帖子应用里,我们使用 Elasticsearch - 一个面向文档的数据库 - 来实现一个读模型:
class PostsController
{
public function listAction()
{
$client = new ElasticsearchClientBuilder::create()->build();
$response = $client->search([
'index' => 'blog-engine',
'type' => 'posts',
'body' => [
'sort' => [
'created_at' => ['order' => 'desc']
]
]
]);
return [
'posts' => $response
];
}
}
读模型被彻底地简化为针对 Elasticsearch 的单个查询索引。
这表明读模型并不真正需要一个对象关系映射器,因为这是多余的。然而,写模型可能会得益于对象关系映射的使用,因为这允许你根据应用程序所需要来组织和构建读模型。
用读模型同步写模型
接下来便是棘手的部分。如何用写模型同步读模型?我们之前已经说过,通过使用写模型事务中捕获的领域事件来完成它。对于捕获的每种类型的领域事件,将执行一个特定的投影。因此,将设置领域事件和投影间的一个一对一的关系。
让我们看看配置投影的一个例子,以便我们得到一个更好的方法。首先,我们需要定义一个投影接口:
interface Projection
{
public function listensTo();
public function project($event);
}
所以为 PostWasCreated 事件定义一个 Elasticsearch 投影如下述一般简单:
namespace Infrastructure/Projection/Elasticsearch;
use Elasticsearch/Client;
use PostWasCreated;
class PostWasCreatedProjection implements Projection
{
private $client;
public function __construct(Client $client)
{
$this->client = $client;
}
public function listensTo()
{
return PostWasCreated::class;
}
public function project($event)
{
$this->client->index([
'index' => 'posts',
'type' => 'post',
'id' => $event->getPostId(),
'body' => [
'content' => $event->getPostContent(),
// ...
]
]);
}
}
Projector 的实现就是一种特殊的领域事件监听器。它与默认的领域事件监听器的主要区别在于 Projector 触发了一组领域事件而不是仅仅一个:
namespace Infrastructure/Projection;
class Projector
{
private $projections = [];
public function register(array $projections)
{
foreach ($projections as $projection) {
$this->projections[$projection->eventType()] = $projection;
}
}
public function project(array $events)
{
foreach ($events as $event) {
if (isset($this->projections[get_class($event)])) {
$this->projections[get_class($event)]
->project($event);
}
}
}
}
下面的代码展示了 projector 和事件间的流向:
$client = new ElasticsearchClientBuilder::create()->build(); $projector = new Projector(); $projector->register([ new Infrastructure/Projection/Elasticsearch/ PostWasCreatedProjection($client), new Infrastructure/Projection/Elasticsearch/ PostWasPublishedProjection($client), new Infrastructure/Projection/Elasticsearch/ PostWasCategorizedProjection($client), new Infrastructure/Projection/Elasticsearch/ PostContentWasChangedProjection($client), new Infrastructure/Projection/Elasticsearch/ PostTitleWasChangedProjection($client), ]); $events = [ new PostWasCreated(/* ... */), new PostWasPublished(/* ... */), new PostWasCategorized(/* ... */), new PostContentWasChanged(/* ... */), new PostTitleWasChanged(/* ... */), ]; $projector->project($event);
这里的代码是一种同步技术,但如果需要的话也可以是异步的。你也通过在视图层放置一些警告通知来让客户知道这些不同步的数据。
对于接下来的例子,我们将结合使用 amqplib PHP 扩展和 ReactPHP:
// Connect to an AMQP broker
$cnn = new AMQPConnection();
$cnn->connect();
// Create a channel
$ch = new AMQPChannel($cnn);
// Declare a new exchange
$ex = new AMQPExchange($ch);
$ex->setName('events');
$ex->declare();
// Create an event loop
$loop = ReactEventLoopFactory::create();
// Create a producer that will send any waiting messages every half a
second
$producer = new Gos/Component/React/AMQPProducer($ex, $loop, 0.5);
$serializer = JMS/Serializer/SerializerBuilder::create()->build();
$projector = new AsyncProjector($producer, $serializer);
$events = [
new PostWasCreated(/* ... */),
new PostWasPublished(/* ... */),
new PostWasCategorized(/* ... */),
new PostContentWasChanged(/* ... */),
new PostTitleWasChanged(/* ... */),
];
$projector->project($event);
为了能让它工作,我们需要一个异步的 projector 。这有一个原生的实现如下:
namespace Infrastructure/Projection;
use Gos/Component/React/AMQPProducer;
use JMS/Serializer/Serializer;
class AsyncProjector
{
private $producer;
private $serializer;
public function __construct(
Producer $producer,
Serializer $serializer
)
{
$this->producer = $producer;
$this->serializer = $serializer;
}
public function project(array $events)
{
foreach ($events as $event) {
$this->producer->publish(
$this->serializer->serialize(
$event, 'json'
)
);
}
}
}
在 RabbitMQ 交换机上的事件消费者如下:
// Connect to an AMQP broker
$cnn = new AMQPConnection();
$cnn->connect();
// Create a channel
$ch = new AMQPChannel($cnn);
// Create a new queue
$queue = new AMQPQueue($ch);
$queue->setName('events');
$queue->declare();
// Create an event loop
$loop = React/EventLoop/Factory::create();
$serializer = JMS/Serializer/SerializerBuilder::create()->build();
$client = new Elasticsearch/ClientBuilder::create()->build();
$projector = new Projector();
$projector->register([
new Infrastructure/Projection/Elasticsearch/
PostWasCreatedProjection($client),
new Infrastructure/Projection/Elasticsearch/
PostWasPublishedProjection($client),
new Infrastructure/Projection/Elasticsearch/
PostWasCategorizedProjection($client),
new Infrastructure/Projection/Elasticsearch/
PostContentWasChangedProjection($client),
new Infrastructure/Projection/Elasticsearch/
PostTitleWasChangedProjection($client),
]);
// Create a consumer
$consumer = new Gos/Component/ReactAMQP/Consumer($queue, $loop, 0.5, 10);
// Check for messages every half a second and consume up to 10 at a time.
$consumer->on(
'consume',
function ($envelope, $queue) use ($projector, $serializer) {
$event = $serializer->unserialize($envelope->getBody(), 'json');
$projector->project($event);
}
);
$loop->run();
从现在开始,只需让所有所需的仓储使用 projector 实例,然后让它们调用投影过程就可以了:
class DoctrinePostRepository implements PostRepository
{
private $em;
private $projector;
public function __construct(EntityManager $em, Projector $projector)
{
$this->em = $em;
$this->projector = $projector;
}
public function save(Post $post)
{
$this->em->transactional(
function (EntityManager $em) use ($post) {
$em->persist($post);
foreach ($post->recordedEvents() as $event) {
$em->persist($event);
}
}
);
$this->projector->project($post->recordedEvents());
}
public function byId(PostId $id)
{
return $this->em->find($id);
}
}
Post 实例和记录事件在同一个事务中触发和持久化。这就确保没有事件丢失,只要事务成功了,我们就会把它们投影到读模型中。因此,在写模型和读模型之间不存在不一致的情况。
一个非常普遍的问题就是当实现 CQRS 时,是否真正需要一个对象关系映射(ORM)。我们真的认为,写模型使用 ORM 是极好的,同时有使用工具的所有优点,这将帮助我们节省大量的工作,只要我们使用了关系型数据库。但我们不应该忘了我们仍然需要在关系型数据库中持久化和检索写模型状态。
事件源
CQRS 是一个非常强大和灵活的架构。在收集和保存领域事件(在聚合操作期间发生)这方面,它有一个额外的好处,就是给你领域中发生的事件一个高度的细节。因为领域事件描述了过去发生的事情,它对于领域的意义,使它成为战术模式的一个关键点。
越来越多的事件是一种坏味道。在领域中记录事件也许是一种成瘾,这也最有可能被企业激励。作为一条经验法则,记住要保持简单。
通过使用 CQRS,我们可以在领域层记录所有发生的相关性事件。领域的状态可以通过重现之前记录的领域事件来呈现。我们只需要一个工具,用一致的方法来存储所有这些事件。所以我们需要储存事件。
事件源背后的基本原理是用一个线性的事件集来表现聚合的状态。
用 CQRS,我们基本上可以实现如下: Post 实体用领域事件输出他的状态,但它的持久化,可以将对象映射至数据表。
事件源则更进一步。按照之前的做法,如果我们使用数据表存储所有博客帖子的状态,那么另外一个表存储所有博客帖子评论的状态,依次类推。而使用事件源我们则只需要一张表:一个数据库中附加的单独的一张表,来存储所有领域模型中的所有聚合发布的所有的领域事件。是的,你得看清了,是单独的一张表。
按照这种模型思路,像对象关系映射的工具就不再需要了。唯一需要的工具就是一个简单的数据抽象层,通过它来附加事件:
interface EventSourcedAggregateRoot
{
public static function reconstitute(EventStream $events);
}
class Post extends AggregateRoot implements EventSourcedAggregateRoot
{
public static function reconstitute(EventStream $history)
{
$post = new static($history->getAggregateId());
foreach ($events as $event) {
$post->applyThat($event);
}
return $post;
}
}
现在 Post 聚合有一个方法,当给定一组事件集(或者说事件流)时,可以一步步重现状态直到当前状态,这些都在保存之前。下一步将构建一个 PostRepository 适配器端口从 Post 聚合中获取所有已发布的事件,并将它们添加到数据存储区,所有的事件都存储在这里。这就是我们所说的事件存储:
class EventStorePostRepository implements PostRepository
{
private $eventStore;
private $projector;
public function __construct($eventStore, $projector)
{
$this->eventStore = $eventStore;
$this->projector = $projector;
}
public function save(Post $post)
{
$events = $post->recordedEvents();
$this->eventStore->append(new EventStream(
$post->id(),
$events)
);
$post->clearEvents();
$this->projector->project($events);
}
}
这就是为什么 PostRepository 的实现看起来像我们使用一个事件存储来保存所有 Post 聚合发布的事件。现在我们需要一个方法,通过历史事件来重新存储一个聚合。 Post 聚合实现的 reconsititute 方法,它通过事件触发来重建博客帖子状态,此刻派上用场:
class EventStorePostRepository implements PostRepository
{
public function byId(PostId $id)
{
return Post::reconstitute(
$this->eventStore->getEventsFor($id)
);
}
}
事件存储就像是负责关于保存和存储事件流的驮马。它的公共 API 由两个简单方法组成:它们是 append 和 getEventsFrom . 前者追加一个事件流到事件存储,后者加载所有事件流来重建聚合。
我们可以通过一个键-值实现来存储所有事件:
class EventStore
{
private $redis;
private $serializer;
public function __construct($redis, $serializer)
{
$this->redis = $redis;
$this->serializer = $serializer;
}
public function append(EventStream $eventstream)
{
foreach ($eventstream as $event) {
$data = $this->serializer->serialize(
$event, 'json'
);
$date = (new DateTimeImmutable())->format('YmdHis');
$this->redis->rpush(
'events:' . $event->getAggregateId(),
$this->serializer->serialize([
'type' => get_class($event),
'created_on' => $date,
'data' => $data
], 'json')
);
}
}
public function getEventsFor($id)
{
$serializedEvents = $this->redis->lrange('events:' . $id, 0, -1);
$eventStream = [];
foreach ($serializedEvents as $serializedEvent) {
$eventData = $this->serializerdeserialize(
$serializedEvent,
'array',
'json'
);
$eventStream[] = $this->serializer->deserialize(
$eventData['data'],
$eventData['type'],
'json'
);
}
return new EventStream($id, $eventStream);
}
}
这里的事件存储的实现是基于 Redis,一个广泛使用的键-值存储器。追加在列表里的事件使用一个 event 前缀:除此之外,在持久化这些事件之前,我们提取一些像类名或者创建时间之类的元数据,这些在之后会派上用场。
显然,就性能而言,聚合总是通过重现它的历史事件来达到最终状态是非常奢侈的。尤其是当事件流有成百上千个事件。克服这种局面最好的办法就是从聚合中拍摄一个快照,只重现快照拍摄后发生的事件。快照就是聚合状态在给定时刻的一个简单的序列化版本。它可以基于聚合的事件流的事件序号,或者基于时间。第一种方法,每 N 次事件触发时就要拍摄一次快照(例如每20,50,或者200次)。第二种方法,每 N 秒就要拍摄一次。
在下面的例子中,我们使用第一种方法。在事件的元数据中,我们添加一个附加字段,版本(version),即从我们开始重现聚合历史状态之处:
class SnapshotRepository
{
public function byId($id)
{
$key = 'snapshots:' . $id;
$metadata = $this->serializer->unserialize(
$this->redis->get($key)
);
if (null === $metadata) {
return;
}
return new Snapshot(
$metadata['version'],
$this->serializer->unserialize(
$metadata['snapshot']['data'],
$metadata['snapshot']['type'],
'json'
)
);
}
public function save($id, Snapshot $snapshot)
{
$key = 'snapshots:' . $id;
$aggregate = $snapshot->aggregate();
$snapshot = [
'version' => $snapshot->version(),
'snapshot' => [
'type' => get_class($aggregate),
'data' => $this->serializer->serialize(
$aggregate, 'json'
)
]
];
$this->redis->set($key, $snapshot);
}
}
现在我们需要重构 EventStore 类,来让它使用 SnapshotRepository 在可接受的次数内加载聚合:
class EventStorePostRepository implements PostRepository
{
public function byId(PostId $id)
{
$snapshot = $this->snapshotRepository->byId($id);
if (null === $snapshot) {
return Post::reconstitute(
$this->eventStore->getEventsFrom($id)
);
}
$post = $snapshot->aggregate();
$post->replay(
$this->eventStore->fromVersion($id, $snapshot->version())
);
return $post;
}
}
我们只需要定期拍摄聚合快照。我们可以同步或者异步地通过监视事件存储进程来实现。下面的代码例子简单地演示了聚合快照的实现:
class EventStorePostRepository implements PostRepository
{
public function save(Post $post)
{
$id = $post->id();
$events = $post->recordedEvents();
$post->clearEvents();
$this->eventStore->append(new EventStream($id, $events));
$countOfEvents = $this->eventStore->countEventsFor($id);
$version = $countOfEvents / 100;
if (!$this->snapshotRepository->has($post->id(), $version)) {
$this->snapshotRepository->save(
$id,
new Snapshot(
$post, $version
)
);
}
$this->projector->project($events);
}
}
是否需要 ORM?
小结
在这一章,因为有大量可选的架构风格,你可能会感到一点困惑。为了做出明显的选择,你不得不在它们中考虑和权衡。不过一件事是明确的:大泥球是不可取的,因为代码很快就会变质。分层架构是一个更好的选择,但它也带来一些缺点,例如层与层之间的紧耦合。可以说,最合适的选择就是六边形架构,因为它可以作为一个基础的架构来使用,它能促进高层次的解耦并且带来内外应用间的对称性,这就是为什么我们在大多数场景下推荐使用它。
我们还可以看到 CQRS 和事件源这些相对灵活的架构,可以帮助你应对严重的复杂性。CQRS 和事件源都有它们的场景,但不要让它的魅力因素分散你判断它们本身提供的价值。由于它们都存在一些开销,你应该有技术原因来证明你必须得使用它。这些架构风格确实有用,在大量的 CQRS 仓储查找方法中,和事件源事件触发量上,你可以很快受到这些风格的启发。如果查找方法的数量开始增长,仓储层开始变得难以维护,那么是时候开始考虑使用 CQRS 来分离读写关注了。之后,如果每个聚合操作的事件量趋向于增长,业务也对更细粒度的信息感兴趣,那么一个选项就该考虑,转向事件源是否能够获得回报。
大泥球就是杂乱无章的,散乱泥泞的,牵连交织的意大利式面条代码。
正文到此结束
- 本文标签: ip 进程 Bootstrap 基本原则 实例 consumer lib 监听器 ORM 模型 stream web db 数据库 redis 时间 Select client Architect Service Elasticsearch 适配器 update find 数据 需求 DOM 开发 build 数据模型 Action rabbitmq 缓存 java 端口 tar UI 代码 HTML 组织 Connection ACE JavaScript validator 存储引擎 目录 tab 配置 API App list 回报 博客 queue id 索引 mysql 测试 js sql SOA CTO value 企业 http producer MQ amqp rand 服务器 https cat 管理 设计模式 key AngularJS entity message Collection 架构设计 tag root struct 产品 NSA 灵魂 json 同步 src JMS IO 一致性 category PHP
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

