A/B test 平台架构设计
本文以一次性设计好A/B test功能架构为目的,对A/B test的使用场景与功能模块进行了分析。

最近在考虑一个产品的小功能改进,目前我们的产品列表按照产品带来的收益排序,如果用户点击了产品之后,那再点击这个产品可能就无法带来很大的收益,于是我们想到,那把用户点过的产品放在产品列表底部怎么样呢?
当然团队内部也有不同的声音,用户点击产品之后,可能由于网速、或者手滑,并没有实际上注册到第三方产品中去,那么放在产品列表底部可能会给用户造成困惑,也失去了用户第二次点击的机会。
内部讨论过后,我们认为这是个值得做的尝试,但应该以A/B test的方式去实现。根据数据,来决定是否要全量覆盖该功能。
A/B test的概念大家并不陌生,被广泛应用于快速迭代的互联网产品中。同时在以前的迭代过程中,我们也以其他方式进行过A/B test。
但是A/B test带来的问题是,单个功能的A/B test是很容易做的,但与此带来的数据统计拆分,每次都会带来重复的工作量。因此比较节约的方式是,一次性设计好A/B test功能架构,支持未来的持续A/B test,降低单次测试带来的边际成本。
一、A/B test的使用场景
从技术上讲,AB测试存在两种场景:纯页面交互A/B和功能A/B。这两种场景的区别仅在于是否需要向后端申请不同的服务。
二、功能模块
A/B test功能模块大概有以下三个: 用户分流服务 、 A/B test 配置 、 数据统计 。整个流程如下:
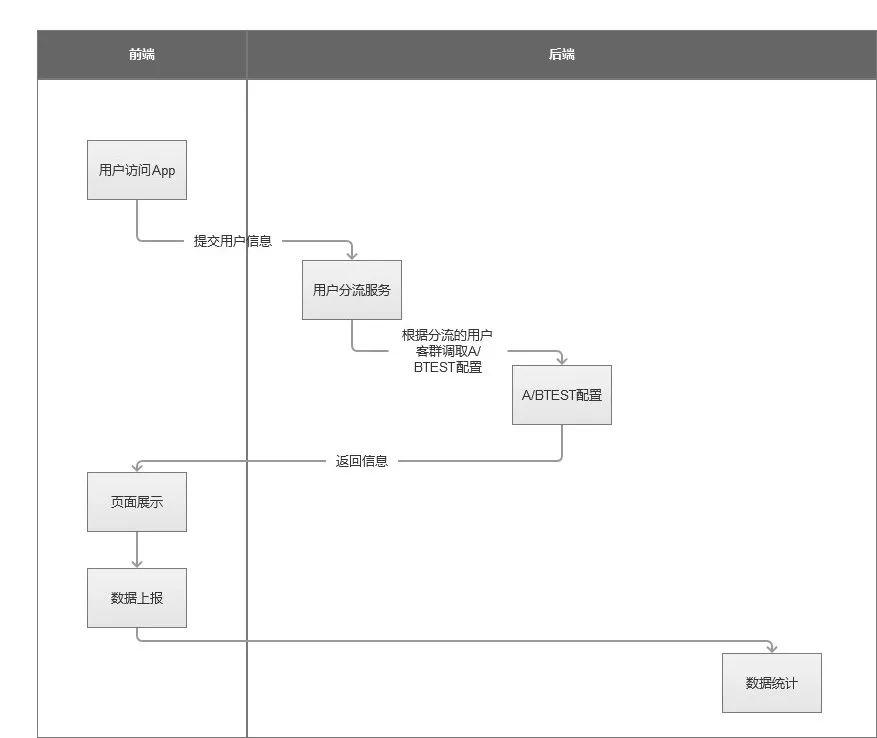
用户访问后,根据用户属性,调取用户分流服务,根据用户分流服务返回结果调取相应 AB/TEST 配置。
前端业务侧做数据埋点,在用户访问时,前端做数据上报。同时自动生成数据报表,处理原始数据后给出是否采信方案的结论。
2.1 用户分流服务
用户分流服务用于将访问用户分流进入对应客群。
这里我做设计的时候有一个部分很后悔,就是我曾经做了一个版本是将用户分类展示不同产品列表的功能。本质上就是一种设定客群然后分流的服务,当时没有考虑到后来这个功能有这样的拓展,所以与产品列表与运营位配置耦合度很高。在做 A/B test 的分流服务时,只能独立再做一套。
事实上不仅用户分流服务是一个应该与各功能模块解耦的部分,客群服务(包括用户信息、用户画像建设)也应该解耦。这两个服务结合起来可用于:为不同用户做定制化展示、A/B test、黑白名单等功能应用。
2.1.1 分层分流
说回用户分流服务来,大型系统会遇到一个问题,我们总是希望以小范围的测试来验证足够多的的假设。可如果多个部门多实验并行,实验之间又相互互斥的话,流量会不足。这里我们产生一个“域”的概念,不同域之间互斥,同一个域的不同层正交,正如下图所示(图片引用,具体见文末参考文章,之后不再赘述):
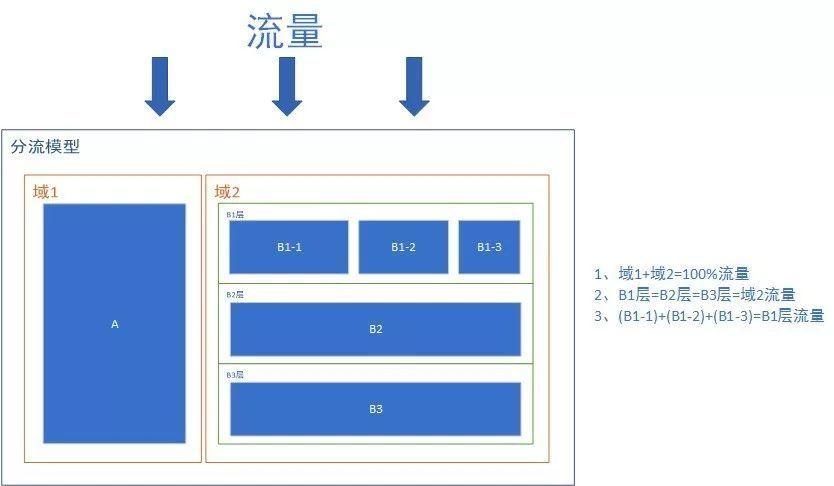
- 不同域之间共享100%流量,例如域1分流了30%,那域2就分流70%;
- 同一个域的不同层之间,会重复使用这个域中的流量,但不同层之间,每次进入流量会重新打散,保证互相不影响;
- 同一个层之间配置 A/B test 的实验 A/B/N,共同分享这个域中的流量,不同实验组之间相互互斥共享100%该域流量;
2.1.2 如何对用户分流
用户分流方式有三种,一般使用的是以用户维度分流,这样可以保证单一用户每次进来看到的是相同实验,不会造成体验上的不一致:
- 以用户维度;
- 以分类维度;
- 完全随机;
哈希因子:实验的 Hash 因子有设备 ID、策略 ID、流量层 ID,根据具体需求,可以选择其中的几个因子组合后 Hash,。
HashID=Hash(设备 ID,策略 ID,流量层 ID)%100+1
这样每个用户会得到唯一的 HashID,同时会落在[1,100]的范围内,让用户随机均匀散落在这个范围内。如果需要将流量控制的更精准,可以对1000甚至10000取余,这个根据实际情况灵活做选择就好。
在配置实验时,根据实际需求,为各个版本均匀切分流量。譬如A版本划分10%的流量,则 HashID 从 0-10 的用户被划分到 A 版本,以此类推。
2.2 A/B test 设置
AB/TEST 设置用于配置实验,做实验的增删查改,同时对线上的实验做管理,及时上下线。
管理员在 AB/TEST 配置系统中,新建实验,并设置分流规则。完成后实验配置入库,当用户访问产品时,根据分流规则调取 AB/TEST 实验版本。
2.2.1 新建/编辑实验
- step1:新建实验
- step2:输入实验信息(实验的基本信息、生效时间)等
- step3:选择分流服务
- step4:选择后端服务
- step4:选择数据指标
2.2.2 管理实验
管理实验模块主要用于上下架实验。
2.3 数据统计
A/B test 最重要的一部分是统计和分析数据。在建立实验时,同步选择需要关注的数据指标。以实时或T+1的方式,展示数据报表。在新建实验时,可以在现有的埋点指标中做选择,选择出用于分析实验效果的关键漏斗指标,生成报表。在技术实现上,埋点的数据上报,需增加分流服务ID。
2.4 数据分析
在数据统计完成后,更重要的部分是我们如何根据数据报表来判断各个版本的优劣。由于其他因素的扰动,譬如流量质量、级别等因素,同一个实验的多个版本会有微小数据差别,在一定程度内的数据差别是正常波动,并不能说明某个版本更优。因此大部分的 A/B test 系统采用了 T 检验。
为什么要 T 检验或者其他检验呢,是因为 **样本参数=总体参数+机会误差+偏差** ,现在我们手里有样本,可以计算样本参数,但是我们想知道的是总体参数,但是这个样本参数能不能代表总体参数呢?T 检验在这里就是用来判断是否是机会误差这个因素造成,通俗点说就是样本得到的参数值可不可能由于是抽取的时候的随机造成的。

2.4.1 P 值(P value)
P 值检验用于验证假设。在 A/B test 里,原先的版本可以称它为H0(原假设),新的版本称为H1(备择假设),假设就是我们认为H1版本是优于H0的。若 P 值落在置信区间里,那我们的假设成立,若 P 值没有落在置信区间,就认为 P 值推翻了我们的假设。
P 值越小,我们认为H1这个备择假设越靠谱。P 值越大,H1越不靠谱。置信区间是我们自行定义的“靠谱区间”。
以上我们计算出了 T 值,通过查询界值表,可以获取到 P 值。
2.4.2 置信区间
刚才说置信区间是人工定义的,α值你可以定义为0.05、0.1,这个根据实际情况去做选择,1-α就是置信区间,除此以外的就是拒绝域。
- 若 p ≤ α,那么拒绝原假设;
- 若 p > α,那么不能拒绝原假设。
推荐阅读(即参考文献)
1.【ABtest在OpenSearch上的设计与实现】
https://yq.aliyun.com/articles/672758?spm=a2c4e.11153940.0.0.74981c4aY0BCsg&type=2
https://help.aliyun.com/document_detail/89958.html
2.【推荐系统衡量:ABtest框架】
https://cloud.tencent.com/developer/article/1450557
3.【马蜂窝ABTest多层分流系统的设计与实现】
https://my.oschina.net/u/4084220/blog/3053499?from=timeline&isappinstalled=0
4.【美图 AB Test 实践:Meepo系统】
https://my.oschina.net/leejun2005/blog/302500
5.【Netflix推荐系统模型的快速线上评估方法——Interleaving】
https://www.jianshu.com/p/40eb1b7d6932
6.【携程机票的ABTest实践】
https://zhuanlan.zhihu.com/p/25685006
7.【沪江ABTest测试平台实践】
https://www.itcodemonkey.com/article/5227.html
#专栏作家#
作者:张小四儿,微信公众号:产品小怪兽
本文原创发布于人人都是产品经理。未经许可,禁止转载。
题图来自Unsplash,基于CC0协议
正文到此结束
热门推荐









相关文章

近期评论
-
出现OpenClaw "device signature expired"。the Gateway rejects if Math.abs(Date.now() - signedAt) > 10 * 60 * 1000 (10 minutes)
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
博主的博客用的什么技术栈,内容都是干货,赞
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
-
不会英语啊。
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

