用AI打个电话骗走22万,这个Python编写的软件,克隆你的语音只需5秒录音!
点击上方“ Python高校 ”,马上关注
真爱,请置顶或星标
用 AI 打电话真的可以骗到钱?是的。而且,克隆指定人的语音只需要一段 5 秒的录音做样本。 来源: 机器之心
用 AI 打一个电话骗走 22 万欧元
AI 技术的应用门槛正在不断降低,换脸、换声音、生成各种不存在的人像都变得非常容易,但与此同时,犯罪的门槛也降低了。
据《华尔街日报》报道,今年 3 月份,一个不知名的黑客组织利用 AI 语音克隆技术打诈骗电话,结果成功骗到了 22 万欧元。

接电话的是英国能源公司的一名 CEO,在电话中,黑客冒充了该公司母公司董事长,催促该 CEO 紧急进行一笔大额转账,接收方是匈牙利的一家供应商。
黑客要求在 1 小时之内转账,而且他们成功地模仿了那位董事长夹杂德国口音的英语,于是该 CEO 信以为真,将钱打到了指定账户。
得逞之后,他们又联系该 CEO,以董事长的身份告诉他这笔钱会回流到公司账户。
但在资金回流之前,黑客再次冒充董事长打来电话,要求 CEO 再转一笔钱,而且这次是从匈牙利打来的。 此时,CEO 感觉事有蹊跷,拒绝了转账要求。 然而,之前转给匈牙利供应商的那笔钱已经被转移到了墨西哥和其它几个地方。
警方现在还没有找到犯罪嫌疑人,但所幸,为该公司承保的保险公司愿意赔偿。
克隆语音只需 5 秒的录音样本
随着自然语言处理技术的进步,用 AI 合成特定人声已经不是什么难事。

今年 5 月份,搜狗在一场大会上展示了变声功能,可以把任何人的声音转化成特定声音,让你的声音秒变志玲、马云、高晓松。
而谷歌的一项研究甚至可以借助 5 秒钟的参照语音克隆任意语音。
去年 6 月,谷歌科学家在 arXiv 上发布了一篇用迁移学习完成语音合成的论文,提出了一个名为 Speaker Verification to Multispeaker Text-To-Speech(简称 SV2TTS)的框架。 它是一个用于零样本(zero-shot)语音克隆的框架,只需要 5 秒钟的参照语音。 也就是说,如果你的录音泄露出去,哪怕只有一小段,也很有可能会被坏人利用。
这项全新的语音合成技术能够通任意一段参考音频中提取出说话者的声纹信息,并生成与其相似度极高的合成语音,参考音频与最终合成的语音甚至不必是同一种语言。 除了利用参考音频作为输入外,该技术还能随机生成虚拟的声线,以「不存在的说话者」的声音进行语音合成。
近日,来自比利时列日大学的研究人员复现了该框架并开源了他们的实现,还提供 GitHub 开源工具箱。 他们采用了一个新的声码器模型来调整框架,使其能够实时运行。
-
GitHub 地址:https://github.com/CorentinJ/Real-Time-Voice-Cloning
-
论文:https://puu.sh/DHgBg.pdf

当然,作者开源的目的肯定不是为了助长犯罪。 技术都具有两面性,我们能做的就是提高自己的隐私意识,不要轻易透露自己的各种信息。
谷歌的 SV2TTS 是什么?
SV2TTS 是一种三段式深度学习框架,允许人们从几秒钟的音频中创建语音的数字表征,文字转语音模型使用数字表征进行训练并生成新的语音。
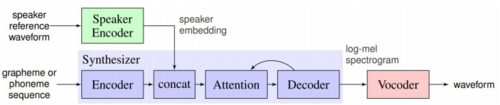
图 7: 推理过程中的 SV2TTS 框架。 蓝色方块: 改进的 Tacotron 架构能够对语音进行调节。
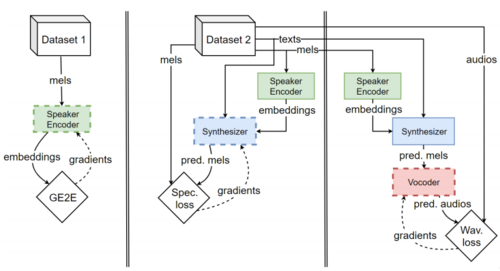
图 8: SV2TTS 的三段式训练流程(根据研究实现)。 具有实体轮廓线的模型被冻结。 值得注意的是,模型使用不同的参数创建梅尔声谱图(mel spectrograms),作为扬声器编码器和声音合成器的输入。
扬声器编码器
扬声器编码器从单个扬声器的短语音中获得嵌入向量,该嵌入是扬声器语音的意义表征,而相似的语音在隐空间中接近。
模型架构
扬声器编码器模型是一个三层的 LSTM,有 768 个隐藏节点,之后是一个由 256 个单元的映射层。 目前尚无论文解释所谓的映射层是什么,因此根据研究者的判断,这种映射层只是全连接层,分别连接在每个 LSTM 层之后,接收上一个 LSTM 层的输出。 为了快速建模,研究人员刚开始使用了有 256 个单元的 LSTM。 他们发现,更小模型的效果极好。 目前他们尚无时间去训练一个更大的模型。
扬声器编码器在扬声器验证任务上接受训练。 扬声器验证是一种典型的生物鉴定应用,通过鉴定人声判定人的身份。 通过从人的一些话语中获取扬声器嵌入,进而可以创建此人的模板。 这个过程被称为登入(enrollment)。 在运行过程中,用户说出一些话,并且系统会对这段话语的嵌入与已登入的扬声器嵌入进行比较。 如果两个嵌入向量的相似度超过给定的阈值,则用户验证成功。 GE2E loss 模拟这一过程,作为模型的目标函数。
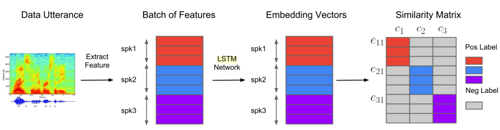
图 9: 训练期间构建相似度矩阵的过程。
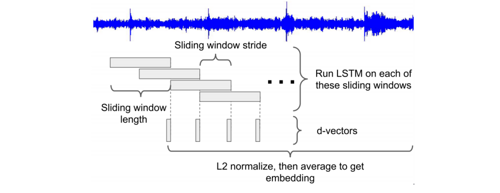
图 10: 计算一段完整话语的嵌入向量。 d-vector 是该扬声器编码器模型的非归一化输出。
实验
为了避免从语音中采样时出现基本无声的音频片段,研究者使用 webrtcvad Python 包执行语音活动检测(VAD)。 这将在音频上产生一个二进制标志,用来表示片段有无声音。 他们在这个二进制标志上执行一个移动平均数,从而使检测中的短峰值(short spike)趋于平滑,然后再次对其进行二值化。 最后,他们扩展了内核大小为 s+1 的标志,其中 s 表示所允许的最大沉默持续时间。 之后,研究者对音频的无声部分进行修剪。 结果发现,值 s =0.2s 时是一个好的选择,能够保持自然的语音韵律。 具体过程如图 11 所示。 应用于音频波形的最后一个预处理步骤是归一化(normalization),用于弥补数据集中扬声器产生的不同的音量。
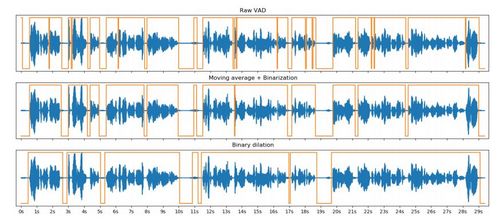
图 11: 从上到下是利用 VAD 消除静音的步骤。 橙色线条代表二进制语音标志,轴上面的值表示有声片段,轴下面的值表示无声片段。
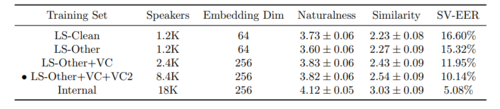
表 2: 扬声器编码器在不同数据集上的训练。 LS 表示 LibriSpeech,VC 表示 VoxCeleb。 合成器在 LS-Clean 上进行训练并在一个测试集上进行评估。 「黑点」标注的行是研究者想要复现的实现对象。
合成器
合成器是移除了 Wavenet 的 Tacotron 2。 研究者使用了 Tacotron 2 的一个开源 Tensorflow 实现,从中剥离 Wavenet 并添加了 SV2TTS。
模型架构
Tacotron 是一个循环的序列到序列模型,它能够从文本中预测梅尔声谱图。 Tacotron 是编码器-解码器结构(并非 SV2TTS 的扬声器编码器),中间由位置敏感的注意力机制连接。 首先,输入为文本序列,其中的字符首先转换为嵌入向量。 随后嵌入向量通过卷积层,用于增加单个编码器帧的范围。 通过卷积层之后的编码器帧再通过双向 LSTM,生成编码器输出帧。 SV2TTS 对架构进行修改的地方在于,这里由扬声器嵌入帧级联编码器输出帧,作为 Tacotron 编码器的输出。
注意力机制对编码器输出帧进行处理,以生成解码器输入帧。 每个解码器输入帧和经过 pre-net 的前一个解码器帧输出级联,使模型实现自回归。 这个级联向量通过两个单向 LSTM 层,然后映射到梅尔声图谱帧。 级联向量同时映射到一个标量(scalar)上,使网络预测一个值,如果该值超过设定阈值,则停止生成。 整个帧序列在转换为梅尔声谱图前通过残差 post-net 传递。 体系架构如图 15 所示:
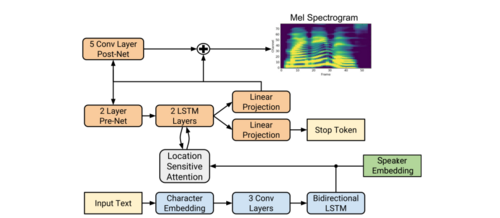
图 15: 修改版 Tacotron 架构。 蓝色方块对应编码器,橙色方块对应解码器。
实验
在 SV2TTS 中,研究者考虑以两个数据集来训练合成器和声码器,它们分别是 LibriSpeech-Clean 和 VCTK(一个由专业设备记录的仅包含 109 位英语母语者的语料库)。 VCTK 数据集上的采样率为 48kHz,实验中降至 24kHz,但仍高于 LibriSpeech 数据集上的 16kHz 采样率。 研究者发现,就相似性来说,在 LibriSpeech 数据集上训练的合成器生成效果优于 VCTK 数据集,但损失了语音自然度。 他们的评估方法是在一个数据集上训练合成器,在另一个数据集上测试。 结果如表 3 所示:

表 3: 对未见的扬声器的生成声音的自然度和与扬声器相似性进行跨数 据集评估。
数据集上语音片段长度的分布如图 16 所示。 注意,无声状态持续时间为 64 小时(13.7%)。
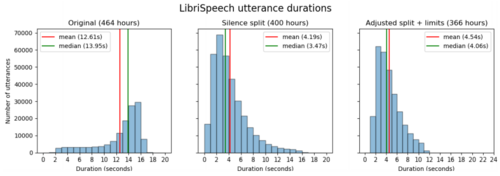
图 16: (左)LibriSpeech-Clean 数据集上话语持续时间直方图; (中): 无声状态打破后持续时间直方图; (右)限制语音片段长度和重新调整后的持续时间直方图。
虽然参考语音的「最佳」持续时间为 5 秒,但参考语音长度仅为 2 秒时,嵌入向量就可以显示出意义,如表 4 所示。
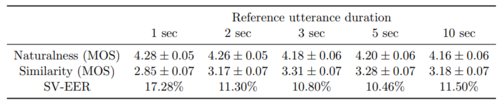
表 4: 参考语音持续时间的影响。 在 VCTK 数据集上进行评估。
研究者观察到,该模型在非正式听力测试中生成了正确输出,但正式评估需要设置主观分数投票(subjective score poll)来获得主观平均得分(MOS)。 但对于合成器来说,人们还可以验证注意力模块是否生成了正确的对齐方式。 示例见图 17:
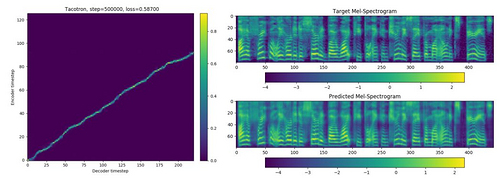
图 17: (左)编码器步骤和解码器步骤之间的数轴对应; (右)GTA 预测声谱图和 ground truth 声谱图之间的比较。
通过计算合成语音的嵌入并利用 UMAP 将它们与 ground truth 嵌入共同映射,研究者能够进一步观察一些语音特征随 Griffin-Lim 算法丧失。 示例见图 18:
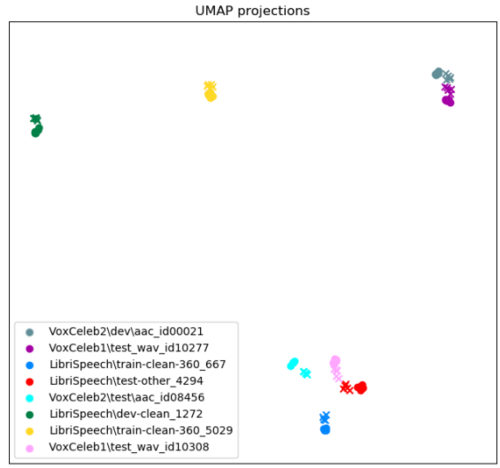
图 18: ground truth 嵌入的映射以及由相同 ground truth 嵌入生成的 Griffin-Lim 算法合成语音嵌入的映射。 Ground truth 嵌入用圆圈表示,合成嵌入用叉号表示。
在 SV2TTS 和 Tacotron2 中,WaveNet 是声码器。 自推出以来,WaveNet 一直都是音频深度学习的核心,并在 TTS 的语音自然性方面保持当前最优水平。 但是,WaveNet 也是推理时速度最慢的实用型深度学习架构。 之后的研究对这方面进行了改进,使生成速度接近或快于实时速度,生成语音的质量则几乎没有影响。 尽管如此,WaveNet 在 SV2TTS 中依然作为声码器,因为速度不是主要的考虑因素,并且 Google 自己的 WaveNet 实现进行了各种改进,每秒钟能够生成 8,000 个样本。 这与 Vanilla WaveNet 形成对比,后者每秒最多能够生成 172 个步骤。 在撰写本文时,WaveNet 的大多数开源实现依然是 Vanilla 实现。
模型架构
在 WaveRNN 中,WaveNet 的全部 60 个卷积被一个 GRU 层替代。 WaveNet 的 MOS 值为 4.51 ± 0.08,而最佳的 WaveRNN 模型的 MOS 值为 4.48 ± 0.07。 模型输入的是由合成器生成的 GTA met 声谱图,以 ground truth 音频为目标。 模型在训练时预测固定大小的波形片段。 在粗精方案(coarse-fine scheme)中,WaveRNN 的前向传递通过 N = 5 的矩阵向量乘积来实现,其中首先对 16 位目标样本的较低 8 位(粗)进行预测,然后据此对较高 8 位(精)的预测进行调整。 预测包含对输出进行采样的分布参数。

图 19: 张量的批采样。 注意,折叠张量在两段的交接处出现重叠。
备选的 WaveRNN 是研究者所使用的架构。 由于该架构缺少相关文档或论文,研究者依赖源代码和图 20 中的图表来理解其内部运行原理。

图 20: 备选的 WaveRNN 架构。
实验
在处理短话语时,声码器的运行速度通常低于实时速度。 推理速度高度依赖于批采样过程中的折叠次数。 事实上,就折叠次数而言,声码器网络几乎是在恒定时间内运行,并且随着折叠次数的增加,时间只有少量增加。 研究者发现讨论阈值持续时间更加简单,超过该阈值持续时间则模型实时运行。 研究者设置的阈值持续时间为 12.5 秒,意味着如果话语短于该阈值,则模型的运行速度将慢于实时速度。 在 PyTorch 上,模型性能似乎出人意料地随环境因素(如操作系统)而变化,所以研究者展示了单个相同配置下的结果。
工具箱和开源
最后,研究者正在开发出一个图形界面,用户不需要率先进行研究即可以快速获取该框架。 他们称之为「SV2TTS 工具箱」,其界面如图 21 所示。 SV2TTS 工具箱使用 Python 语言编写,具有 Qt4 图像界面,可跨平台。
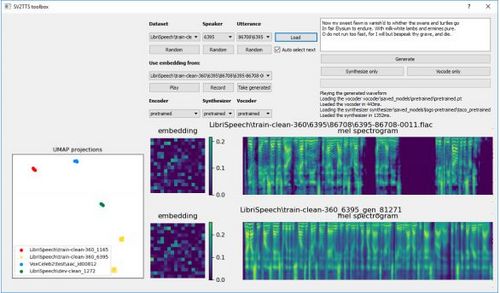
图 21: SV2TTS 工具箱界面。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

