Terminal Brain Damage:在硬件错误攻击下深度神经网络的严重退化

作者: CDra_90n
原文作者: Sanghyun Hong, Pietro Frigo, Yigitcan Kaya, Cristiano Giufffida, Tudor Dumitras
原文标题: Terminal Brain Damage : Exposing the Graceless Degradation in Deep Neural Networks Under Hardware Fault Attacks
原文会议: USENIX 2019
原文链接: https://arxiv.org/pdf/1906.01017.pdf
摘要:深度神经网络(DNN)已被证明可能发生“脑损伤”:网络参数的累积变化(例如,修剪,数值扰动)通常会导致分类精度的下降。本文研究了19个DNN模型的比特位错误(三种图像分类任务的六种架构)的影响,并显示大多数模型具有至少一个参数,这些参数在按位表示经过特定的比特位翻转后会导致精度损失超过90%。对于大型模型,参数中有40%至50%单独受到这种单比特位反转( single bit-flip )时,其精度下降可能会超过10%。结果揭示了DNN对现实世界错误攻击引起的参数扰动的恢复能力的局限性。
一、简介
本文研究了实际硬件错误攻击( hardware fault attack )引起的比特位错误下DNN的安全特性。具体来说,DNN对于硬件错误攻击者可能导致的原子损坏( atomic corruption )有多脆弱?本文重点研究了真实的单比特位反转攻击,因为它们很好地模拟了实际硬件错误攻击(如Rowhammer)的约束内存损坏原语( constrained memory corruption primitive )。为了回答这个问题,本文进行了一项全面的研究,描述了DNN模型对其每个参数中单比特位损坏的响应。
首先,本文实现一个系统的漏洞分析框架,允许我们通过检查各种因素的影响来表征漏洞的能力:位置,反转方向,参数符号,层宽度,激活函数,标准化和模型架构。主要发现包括:
1)该漏洞是由参数值急剧上升造成的;
2)正参数急剧上升具有更大的威胁性,但是,允许负输出的激活函数也会使负参数易受攻击;
3)随着DNN层的变宽,易受攻击的参数数量成比例增加;
4)两种常见的训练技术,例如丢弃( dropout )和批量标准化( batch normalization ),在防止大规模位反转引起的急剧增加的效果方面无效;和
5)在不同架构(例如AlexNet,VGG16等)之间,易受攻击的参数的比率几乎是恒定的。
贡献。DNN模型比以前假设的更容易遭受位反转损坏。特别是,我们显示了由硬件错误攻击引起的对抗性按位损坏,可以通过大幅增加或减小模型参数的值来轻易造成严重的无差别分类错误损害( indiscriminate damages )。
二、威胁模型
考虑了敌手在使用硬件错误攻击时可能在实践中引起的一类修改。假设在一个云环境中,受害者的深度学习系统部署在VM或容器内,以服务于外部用户的请求。为了进行测试时间推断,将经过训练的DNN模型及其参数加载到系统的(共享)内存中,并在正常操作中保持不变。最近的研究将其描述为MLaaS中的典型场景。
能力。本文认为攻击者与受害者的深度学习系统位于同一物理主机上。由于位于同一地点,攻击者可以利用众所周知的软件引发的错误攻击Rowhammer来破坏存储在DRAM中的受害者模型。我们考虑了两种可能的情况:
1)外科手术式攻击( surgical attack ),攻击者可以通过利用高级内存刷洗原语( advanced memory massaging primitives )来使受害者的进程内存中的预定位置发生位反转;
2)盲目攻击( blind attack ),攻击者对位反转缺乏细粒度的控制;因此,完全不知道模型布局中的位反转会落在何处。
知识。使用现有术语,我们考虑攻击者对受害者模型的了解分为两个级别,例如,模型的体系结构及其参数以及它们在内存中的位置:
1)黑盒设置,其中攻击者不了解受害者模型。在这里,外科手术式攻击者和盲目攻击者都只希望使准确性下降,因为他们无法预料到比特反转的影响。
2)白盒设置,其中攻击者至少部分了解受害者模型。在这里,外科手术式攻击者可以故意调整攻击造成的准确度下降-从轻度到灾难性损害。可选地,攻击者可以迫使受害者模型对特定的输入样本进行错误分类,而不会显着损害整体准确性。但是与黑盒场景相比,盲目攻击者没有明显的优势,因为缺乏能力会阻止攻击者根据知识采取行动。
三、DNN上的单比特位损坏
1、实验设置
(1) 数据集。 使用三个流行的图像分类数据集:MNIST ,CIFAR10 和ImageNet。MNIST是用于手写数字(零到九)识别的灰度图像数据集,包含60,000个训练图像和10,000个28x28像素的验证图像。CIFAR10和ImageNet是用于对象识别的彩色图像数据集。CIFAR10包括32x32像素,10类彩色自然图像,其中包含50,000个训练图像和10,000个验证图像。对于ImageNet,使用ILSVRC-2012子集,其子集的大小调整为224x224像素,由1,281,167个训练和来自1,000个类别的50,000个验证图像组成。
(2) 指标。 为了量化单比特位反转的无差别分类错误损害,我们将相对准确度下降定义为RAD =(Acc pristinee - Acc corrupted )/ Acc pristine ;其中Acc pristine 和Acc corrupted 分别表示原始模型和损坏模型的分类精度。在实验中使用[RAD> 0.1]作为模型无差别分类错误损害的标准。还测量了验证集中每个类的准确性,以分析单比特位反转是否导致类的子集主导其余子类。在MNIST和CI FAR10中,仅计算测试数据的Top-1准确性(以百分比表示),然后使用该准确性进行分析。对于ImageNet,同时考虑了Top-1和Top-5的准确性。为了量化模型的脆弱性,我们只计算这些脆弱参数的数量。
(3) 方法。 在8个MNIST模型上进行了完整的分析:在(0→1)和(1→0)两个方向上反转模型所有参数中的每个比特位,并在整个验证过程中计算RAD。
2、量化无差别分类错误损害
下表列出了针对19种不同DNN模型的单比特位破坏实验结果。配备单比特位反转攻击原语的攻击者可以成功造成无差别分类错误损害[RAD> 0.1],并且模型中易受攻击的参数的比例在40%到99%之间变化,取决于模型。MNIST实验(检查所有可能的位反转)与其余实验(通过试探性地检查一个子集)之间的一致性表明,在DNN模型中,大约一半的参数易受单比特位反转的影响。实验还显示出成功攻击机会的微小变化,这由易受攻击的参数的比率表示。InceptionV3模型具有40%的易受攻击参数,是ImageNet模型中最明显的异常值。相比之下,其余的比例为42-49%。
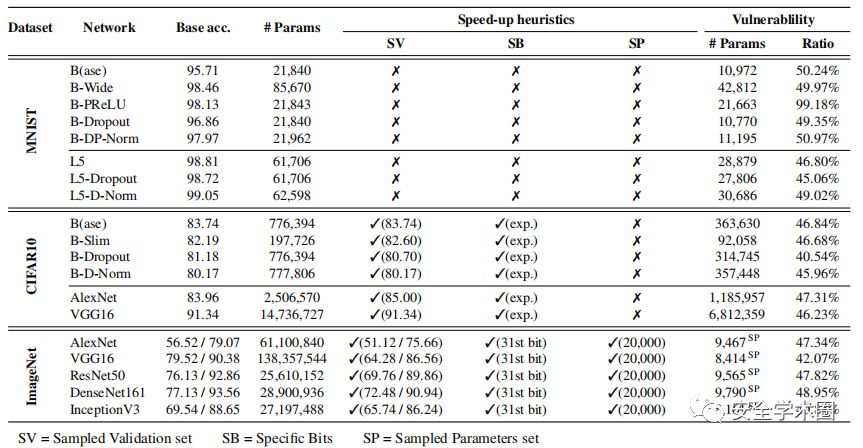
3、比特位反转位置的影响
为了检查参数值的多少变化会导致无差别分类错误损害,将重点放在损坏位的位置上。在下图中,对于每个比特位位置给出了指数范围中表示在模型上反转时会造成分类错误损害的位数。在MNIST实验中检查了所有比特位位置发现除指数以外的比特位位置大部分不会导致明显的损坏。指数位尤其是第31位会导致无差别分类错误损害。原因是指数的位反转会导致参数值急剧变化,而尾数的反转只会使值增加或减少一小部分-[0,1]。还观察到第30位到第28位的反转几乎是无关紧要的,因为在IEEE754表示中,对于大多数DNN参数通常需要的值,这些位设置为 [3.0517×10^-5,2]。
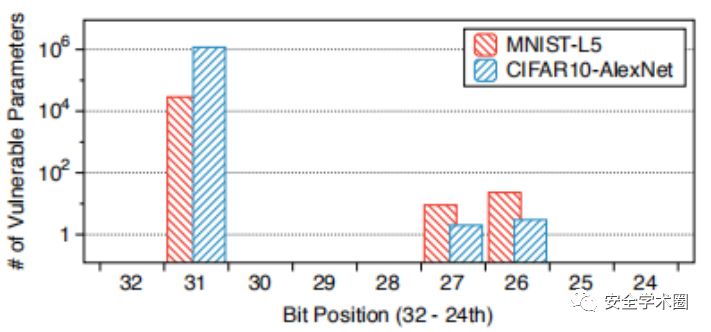
4、反转方向的影响
(0→1)或(1→0)反转的哪个方向会导致更大的无差别分类错误损害?在下表中观察到只有(0→1)反转会造成无差别分类错误损害,没有(1→0)反转会导致漏洞。原因是(1→0)反转只能降低参数值,与(0→1)反转不同。模型参数的值通常呈正态分布-N(0,1)-将大多数值置于[-1,1]范围内。因此,指数的(1→0)反转最多可将典型参数的大小减小1;这不足以引起重大损害。类似地在符号位中,(0→1)和(1→0)反转都不会造成严重损坏,因为它们最多会将参数的大小更改两次。另一方面,按指数的(0→1)翻转可以显着增加参数值。因此,在前向传递过程中,由参数损坏导致的极端神经元激活会覆盖其余的激活。
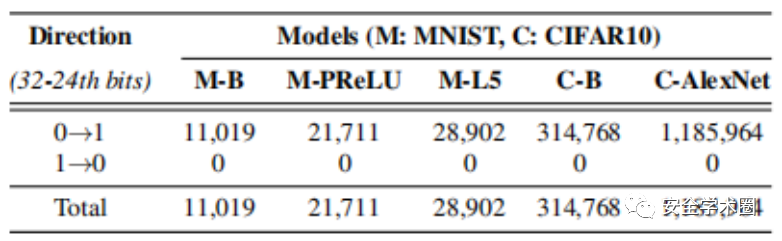
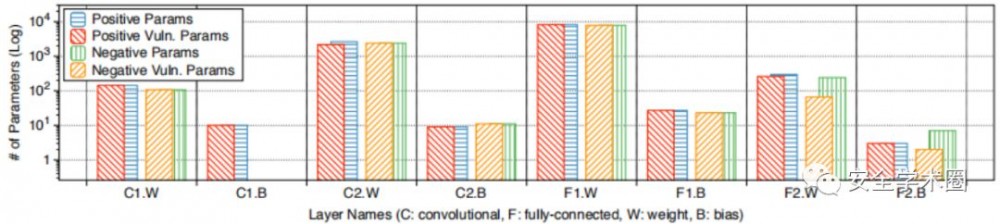
5、参数符号的影响
调查损坏的参数的正负号是否会影响漏洞。在下图中的结果表明,正参数比负参数更容易受到单比特位反转的影响。确定常见的ReLU激活函数是因为:ReLU立即将负激活值归零,这通常是由负参数引起的。结果破坏负参数的有害影响无法在模型中进一步传播。此外观察到在第一层和最后一层中,负参数以及正参数都是脆弱的。假设在第一卷积层中,参数的变化产生与直接破坏模型输入相似的效果。另一方面,DNN在其最后一层通常具有Softmax函数,该函数没有与ReLU相同的归零效果。
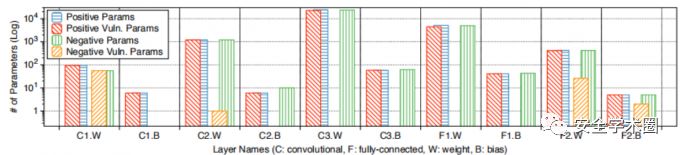
6、激活函数的影响
接下来探讨激活函数的选择是否会影响漏洞能力。在允许负输出的不同激活函数上进行了实验,例如PReLU,LeakyReLU或RReLU。这些ReLU变体已显示出可改善训练性能和DNN的准确性。在本实验中训练MNIST-B-PReLU模型;它与MNIST-B模型完全相同,只是它用PReLU代替ReLU。下图给出了MNIST-B PReLU中易受攻击的正负参数的分层数量。观察到使用PReLU会导致负参数变得脆弱,因此导致DNN的脆弱性大约是使用ReLU的DNN的两倍-分别为50.2%和99.2%的脆弱参数。
四、使用Rowhammer进行攻击
为了证实针对DNN的硬件错误攻击的可行性,测试了这些模型针对Rowhammer的容忍性。从较高的层次上讲,Rowhammer是一种由软件引起的错误攻击,可以为攻击者提供对特定物理内存位置的单比特位写原语。也就是说,能够执行特定内存访问模式(在DRAM级别上)的攻击者可能会导致软件造成持久和可重复的位损坏。考虑到我们在实际设置中专注于DNN参数的单比特位扰动,Rowhammer代表了该任务的理想选择。
由于外科手术式攻击者知道易受攻击参数的位置,因此她可以预先对内存进行模板化。也就是说,攻击者通过在自己分配的块中引入Rowhammer位反转并寻找可利用的位反转来扫描内存。外科手术式攻击者针对特定的位反转。因此,在对内存进行模板化时,攻击者通过查找与内存页起始地址(即4 KB)(从OS分配的最小可能块)相距特定偏移量的位反转来简化扫描。这使攻击者可以在给定的页面偏移量(即易受攻击的模板)下找到容易受Rowhammer比特位反转影响的内存页面,攻击者随后可以将其用于可预测地攻击存储在该位置的受害者数据。
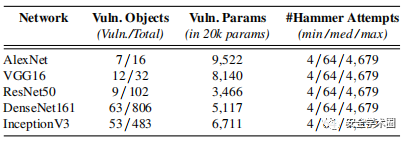
1、使用Rowhammer的外科手术式攻击
每个模型使用了五个采样参数中的一组。在下表中报告了攻击者需要攻击的行数的最小值、中值和最大值,以便在每个模型的12个不同DRAM设置中找到第一个易受攻击的模板。这提供了一个有意义的指标来了解外科手术式攻击的成功率。如表所示,结果在所有不同模型中均保持不变。也就是说,对于在最佳情况下测试的每个模型,只需要攻击4行(A_2 DRAM设置),即可找到最易受攻击的模板,直到最坏情况(C_1),最高可达4,679。结果在不同模型之间相等的原因是由于易受攻击的参数数量大大超过了可以存储此类参数的页面内可能的偏移数量(即1024)。由于每个易受攻击的参数都会产生不确定的损害[RAD> 0.1],因此只需要确定一个可以匹配任何给定易受攻击参数的模板。这意味着攻击者最多可以在几秒钟之内找到漏洞模板,而最坏的是几分钟之内。一旦找到易受攻击的模板,攻击者就可以利用内存重复数据删除技术对DNN模型进行有效的攻击,而不会干扰系统的其余部分。
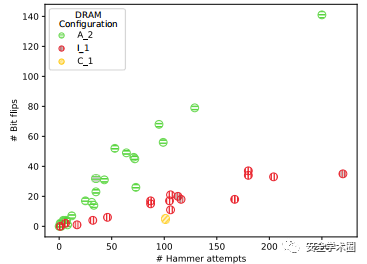
2、使用Rowhammer的盲目攻击
在下图中给出了三个采样DRAM设置的结果。选择A_2,I_1和C_1作为代表样本,因为它们是最脆弱,最不脆弱和中等脆弱的DRAM芯片。根据DRAM的设置可获得完全不同的结果。发现A_2在25个实验中的24个中成功得到了对模型的成功无差别分类错误损害,而在C_1等不脆弱的环境中,成功次数仅减少为一次,而其他24次则失败了。但是重要的是超时并不代表负面结果-崩溃。相反,尽管C_1仅发生了一次成功攻击,但它也代表了一个特殊情况。在此成功的实验中产生的损坏是由一次位反转引起的,这是造成最严重错误的原因之一。在整个实验中检测到显着的RAD,即在Top-1和Top-5中为0.9992和0.9959。无论这种极端情况如何,报告在不同的DRAM设置下,针对该Rowhammer变体的25次有效攻击中的平均值为15.6。
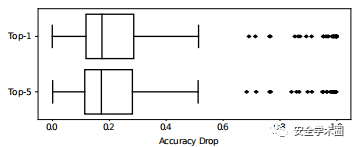
此外,在下图中报告了Top-1和Top-5的准确性下降的分布。特别是,Top-1和Top-5的中值下降证实了前面各节中的主张,即盲目攻击者平均可以期望[RAD> 0.1]。
五、缓解措施
使DNN模型对位反转具有容忍性的两个研究方向:限制激活幅度( restricting activation magnitudes )和使用低精度数字( using low-precision numbers )。先前针对Rowhammer攻击防御的工作表明,系统级防御甚至经常需要特定的硬件支持。但是,由于它们需要云主机提供商在基础架构范围内进行更改,因此尚未得到广泛部署。而且,即使基础架构可以抵抗Rowhammer攻击,但对手也可以利用其他媒介利用位反转攻击破坏模型。因此,我们专注于受害者可以应用于其模型的解决方案。
1、限制激活幅度
如果我们选择始终将输出限制在特定范围内的激活函数,则位反转很难造成无差别分类错误损害。有多种函数可以抑制激活,例如Tanh或HardTanh。这种机制:
通过限制激活幅度的实验结果表明:这种机制:
1)允许防御者控制相对准确度下降与减少易受攻击的参数之间的折衷,并且
2)启用对DNN模型的临时防御不需要从头开始培训网络。但是,其余易受攻击的参数数量表明,Rowhammer攻击者仍然可能造成破坏,只是成功率降低。
2、使用低精度数字
另一个方法是通过使用量化和二值化将模型参数表示为低精度数字。使用难以通过位反转显着增加的低精度数字。例如,通过反转MSB(第8位),最多可以将表示为8位量化格式的整数增加128。因此,攻击者只能以这种限制范围增加模型参数。流行的深度学习框架(如TensorFlow)支持使用低精度数字的训练模型。受害者可以通过利用框架来训练和部署带有量化或二值化参数的模型。
即使通过8位量化消除了漏洞,但在现实世界中,从头开始训练大型模型在超级计算集群上可能需要一周的时间。
安全学术圈招募队友-ing ,有兴趣加入学术圈的请联系secdr#qq.com

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

