超好用的自带火焰图的 Java 性能分析工具 Async-profiler 了解一下
可以点击上方蓝色 “ 未读代码 ” 关注我。
回复 资源 获取精心整理的 Java核心知识&面试资料。
火焰图
如果你经常遇到 Java 线上性能问题束手无策,看着线上服务 CPU 飙升一筹莫展,发现内存不断泄露满脸茫然。别慌,这里有一款低开销、自带 火焰图 、让你大呼好用的 Java 性能分析工具 - async-profiler 。
最近 Arthas 性能分析工具上线了 火焰图 分析功能,Arthas 使用 async-profiler 生成 CPU/内存火焰图进行性能分析,弥补了之前内存分析的不足。在 Arthas 上使用还是比较方便的,使用方式可以看官方文档。这篇文章介绍 async-profiler 相关内容。
Arthas 火焰图官方文档:https://alibaba.github.io/arthas/profiler.html
如果你想了解更多 Arthas 信息,可以参考之前文章: Arthas - Java 线上问题定位处理的终极利器
async-profiler 介绍
async-profiler 是一款开源的 Java 性能分析工具 ,原理是基于 HotSpot 的 API,以 微乎其微的性能开销 收集程序运行中的堆栈信息、内存分配等信息进行分析。
使用 async-profiler 可以做下面几个方面的分析。
-
CPU cycles
-
Hardware and Software performance counters like cache misses, branch misses, page faults, context switches etc.
-
Allocations in Java Heap
-
Contented lock attempts, including both Java object monitors and ReentrantLocks
我们常用的是 CPU 性能分析和 Heap 内存分配分析。在进行 CPU 性能分析时,仅需要 非常低的性能开销 就可以进行分析,这也是这个工具的优点之一。
在进行 Heap 分配分析时,async-profiler 工具会收集内存分配信息,而不是去检测占用 CPU 的代码。async-profiler 不使用侵入性的技术,例如字节码检测工具或者探针检测等,这也说明 async-profiler 的内存分配分析像 CPU 性能分析一样,不会产生太大的性能开销,同时也不用写出 庞大的堆栈文件 再去进行进一步处理,。
async-profile 目前支持 Linux 和 macOS 平台(macOS 下只能分析用户空间的代码)。
-
Linux/ x64 / x86 / ARM / AArch64
-
macOS/ x64
async-profiler 工具在采样后可以生成采样结果的日志报告,也可以生成 SVG 格式的 火焰图 ,在之前生成 火焰图 要使用 FlameGraph 工具。现在已经不需要了,从 1.2 版本开始,就已经内置了开箱即用的 SVG 文件生成功能。
其他信息可以看官方文档:https://github.com/jvm-profiling-tools/async-profiler
async-profiler 安装
下载 async-profiler 工具可以在官方的 Github 上直接下载编译好的文件,如果你就是想体验手动挡的感觉,也可以克隆项目,手动编译一下,不得不说这个工具十分的易用,我在手动编译的过程十分顺滑,没有出现任何问题。
如果你想下载编译好的,可以到这里下载。
https://github.com/jvm-profiling-tools/async-profiler/releases
如果想体验手动挡的感觉,可以克隆整个项目,进项项目编译。
手动编译的环境要求。
-
JDK
-
GCC
下面是手动安装的操作命令。
git clone https://github.com/jvm-profiling-tools/async-profiler
cd async-profiler
make
执行 make 命令编译后会在项目的目录下生成一个 build 文件夹,里面存放着编译的结果。下面是我手动编译的过程输出。
➜ develop git clone https://github.com/jvm-profiling-tools/async-profiler
Cloning into 'async-profiler'...
remote: Enumerating objects: 69, done.
remote: Counting objects: 100% (69/69), done.
remote: Compressing objects: 100% (54/54), done.
remote: Total 1805 (delta 34), reused 32 (delta 15), pack-reused 1736
Receiving objects: 100% (1805/1805), 590.78 KiB | 23.00 KiB/s, done.
Resolving deltas: 100% (1288/1288), done.
➜ develop cd async-profiler
➜ async-profiler git:(master) make
mkdir -p build
g++ -O2 -D_XOPEN_SOURCE -D_DARWIN_C_SOURCE -DPROFILER_VERSION=/"1.6/" -I/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/include -I/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/include/darwin -fPIC -shared -o build/libasyncProfiler.so src/*.cpp -ldl -lpthread
gcc -O2 -DJATTACH_VERSION=/"1.5/" -o build/jattach src/jattach/jattach.c
mkdir -p build/classes
/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/bin/javac -source 6 -target 6 -d build/classes src/java/one/profiler/AsyncProfiler.java src/java/one/profiler/AsyncProfilerMXBean.java src/java/one/profiler/Counter.java src/java/one/profiler/Events.java
警告: [options] 未与 -source 1.6 一起设置引导类路径
1 个警告
/Library/Java/JavaVirtualMachines/jdk1.8.0_181.jdk/Contents/Home/bin/jar cvf build/async-profiler.jar -C build/classes .
已添加清单
正在添加: one/(输入 = 0) (输出 = 0)(存储了 0%)
正在添加: one/profiler/(输入 = 0) (输出 = 0)(存储了 0%)
正在添加: one/profiler/AsyncProfiler.class(输入 = 1885) (输出 = 908)(压缩了 51%)
正在添加: one/profiler/Events.class(输入 = 405) (输出 = 286)(压缩了 29%)
正在添加: one/profiler/Counter.class(输入 = 845) (输出 = 473)(压缩了 44%)
正在添加: one/profiler/AsyncProfilerMXBean.class(输入 = 631) (输出 = 344)(压缩了 45%)
rm -rf build/classes
➜ async-profiler git:(master)
async-profiler 使用
运行项目里的 profiler.sh 可以看到 async-profiler 的使用帮助文档。
➜ async-profiler git:(master) ./profiler.sh
Usage: ./profiler.sh [action] [options] <pid>
Actions:
start start profiling and return immediately
resume resume profiling without resetting collected data
stop stop profiling
status print profiling status
list list profiling events supported by the target JVM
collect collect profile for the specified period of time
and then stop (default action)
Options:
-e event profiling event: cpu|alloc|lock|cache-misses etc.
-d duration run profiling for <duration> seconds
-f filename dump output to <filename>
-i interval sampling interval in nanoseconds
-j jstackdepth maximum Java stack depth
-b bufsize frame buffer size
-t profile different threads separately
-s simple class names instead of FQN
-g print method signatures
-a annotate Java method names
-o fmt output format: summary|traces|flat|collapsed|svg|tree|jfr
-v, --version display version string
--title string SVG title
--width px SVG width
--height px SVG frame height
--minwidth px skip frames smaller than px
--reverse generate stack-reversed FlameGraph / Call tree
--all-kernel only include kernel-mode events
--all-user only include user-mode events
--sync-walk use synchronous JVMTI stack walker (dangerous!)
<pid> is a numeric process ID of the target JVM
or 'jps' keyword to find running JVM automatically
Example: ./profiler.sh -d 30 -f profile.svg 3456
./profiler.sh start -i 999000 jps
./profiler.sh stop -o summary,flat jps
可以看到使用的方式是:Usage: ./profiler.sh [action] [options]
常用的使用的几个步骤:
-
查看 java 进程的 PID(可以使用 jps )。
-
使用 ./profiler.sh start
开始采样。 -
使用 ./profiler.sh status
查看已经采样的时间。 -
使用 ./profiler.sh stop
停止采样,输出结果。
这种方式使用起来多费劲啊,而且最后输出的是文本结果,看起来更是费劲,为了不那么费劲,可以使用帮助里给的采样后生成 SVG 文件例子。
./profiler.sh -d 30 -f profile.svg 3456
这个命令的意思是,对 PID 为 3456 的 java 进程采样 30 秒,然后生成 profile.svg 结果文件。
默认情况下是分析 CPU 性能,如果要进行其他分析,可以使用 -e 参数。
-e event profiling event: cpu|alloc|lock|cache-misses etc.
可以看到支持的分析事件有 CPU、Alloc、Lock、Cache-misses 。
async-profiler 案例
上面说完了 async-profiler 工具的作用和使用方式,既然能进行 CPU 性能分析和 Heap 内存分配分析,那么我们就写几个不一般的方法分析试试看。看看是不是有像上面介绍的那么好用。
Java 案例编码
很简单的几个方法,hotmethod 方法写了几个常见操作,三个方法中很明显 hotmethod3 方法里的生成 UUID 和 replace(需要正则匹配)操作消耗的 CPU 性能会较多。allocate 方法里因为要不断的创建长度为 6万的数组,消耗的内存空间一定是最多的。
import java.util.ArrayList;
import java.util.Random;
import java.util.UUID;
/**
* <p>
* 模拟热点代码
*
* @Author niujinpeng
*/
public class HotCode {
private static volatile int value;
private static Object array;
public static void main(String[] args) {
while (true) {
hotmethod1();
hotmethod2();
hotmethod3();
allocate();
}
}
/**
* 生成 6万长度的数组
*/
private static void allocate() {
array = new int[6 * 1000];
array = new Integer[6 * 1000];
}
/**
* 生成一个UUID
*/
private static void hotmethod3() {
ArrayList<String> list = new ArrayList<>();
UUID uuid = UUID.randomUUID();
String str = uuid.toString().replace("-", "");
list.add(str);
}
/**
* 数字累加
*/
private static void hotmethod2() {
value++;
}
/**
* 生成一个随机数
*/
private static void hotmethod1() {
Random random = new Random();
int anInt = random.nextInt();
}
}
CPU 性能分析
运行上面的程序,然后使用 JPS 命令查看 PID 信息。
➜ develop jps
2800 Jps
2449 HotCode
2450 Launcher
805 RemoteMavenServer36
470 NutstoreGUI
699
➜ develop
上面运行的类名是 HotCode,可以看到对应的 PID 是 2449。
使用 ./profiler.sh -d 20 -f 2449.svg 2449
命令对 2449 号进程采样20秒,然后得到生成的 2449.svg 文件,然后我们使用浏览器打开这个文件,可以看到 CPU 的使用 火焰图
。
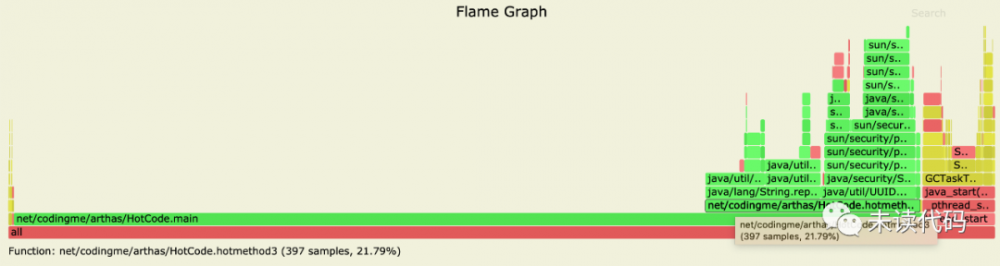
关于火焰图怎么看,一言以蔽之: 火焰图里,横条越长,代表使用的越多,从下到上是调用堆栈信息 。在这个图里可以看到 main 方法上面的调用中 hotmethod3 方法的 CPU 使用是最多的,点击这个方法。还可能看到更详细的信息。
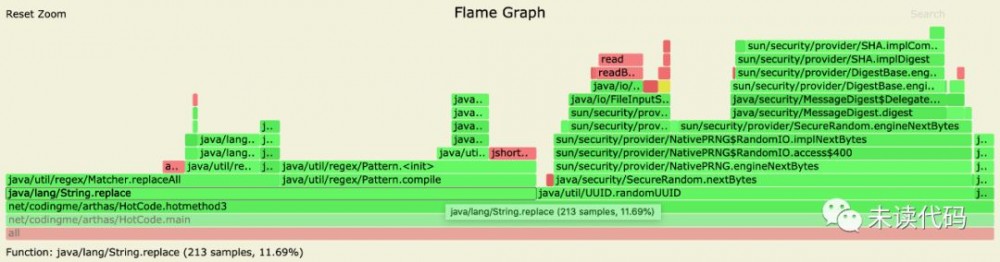
可以看到 replace 方法占用的 CPU 最多,也是程序中性能问题所在,是需要注意的地方。
Heap 内存分析
还是上面运行的程序,进程 PID 还是 2449,这次使用 -e 参数分析内存使用情况。
命令: ./profiler.sh -d 20 -e alloc -f 2449-alloc.svg 2449
命令的意思是收集进程号是 2449 的进程的内存信息 20 秒,然后输出为 2449-alloc.svg 文件。20秒后得到 svg 文件使用浏览器打开,可以看到内存分配情况。

依旧是横条越长,代表使用的越多,从下到上是调用堆栈信息。从图里可以看出来 main 方法调用的 allocate 方法使用的内存最多,这个方法里的 Integer 类型数组占用的内存又最多,为 71%。
往期文章
-
Springboot 系列(十六)你真的了解 Swagger 文档吗?
-
还看不懂同事的代码?超强的 Stream 流操作姿势还不学习一下
-
Jdk14都要出了,还不能使用 Optional优雅的处理空指针?
-
Springboot 系列(十五)如何编写自己的 Springboot starter
-
网络协议之HTTP
-
原来热加载如此简单,手动写一个 Java 热加载吧
-
Jdk14 都要出了,Jdk8 的时间处理姿势还不了解一下?
-
IDEA 的独孤求败江湖
-
Tomcat 的单机多实例配置
---- END ----

一个「在看」,一段时光! :point_down:
正文到此结束
- 本文标签: cat 时间 参数 http ORM 字节码 spring ip 进程 代码 list src bean JVM 目录 tomcat find GitHub value lib Action ArrayList linux maven tar API key build 下载 springboot remote IDE 实例 example 文章 id 协议 js UI DOM 开源 ACE Master 编译 https 配置 HTML 性能问题 Word IO rand 探针 安装 空间 volatile jstack cache stream java git
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

