netty的线程模型, 调优 及 献上写过注释的源码工程
Netty能干什么?
Http服务器
使用Netty可以编写一个 Http服务器, 就像tomcat那样,能接受用户发送的http请求, , 只不过没有实现Servelt规范, 但是它也能解析携带的参数, 对请求的路径进行路由导航, 从而实现将不同的请求导向不同的handler进行处理
对socket与RPC的支持
Netty可是实现的第二件事就是Socket编程,也是它最为广泛的应用领域
进行微服务开发时不可丢弃的一个点, 服务和服务之间如果使用Http通信不是不行,但是http的底层使用的也是socket, 相对我们直接使用netty加持socket效果会更好 (比如阿里的Dubbo)
当然Netty能做的事还有很多比如自定义通信协议等等,,,
对WebSocket的支持
Netty对WebSocket也提供了强大的支持, netty内置的处理器会为我们做好大量的机械性麻烦性的工作, 如 WebSocketServerProtocolHandler 内置编解码处理, 心跳检验等, 可以让我们专注于实现自己的业务逻辑
Reactor线程模型
Reactor线程模型, 顾名思义就像核反应堆一样, 是一种很劲爆的线程模型
最经典的两种图就像下面这样
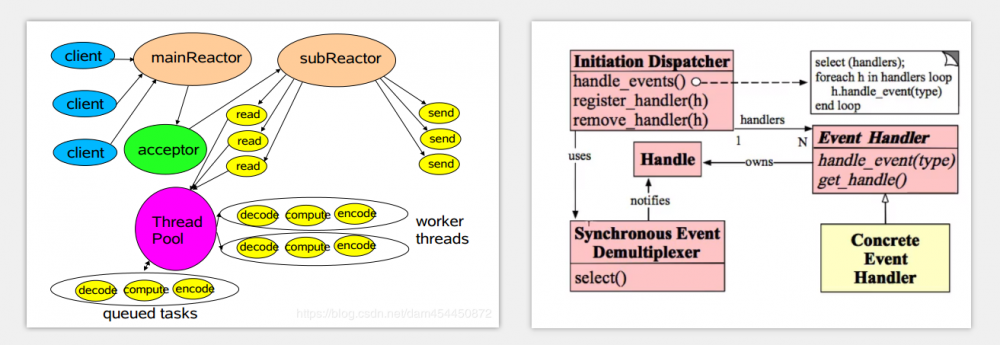
上面两种图所描述的都是Reactor线程模型
Reactor线程模型五大角色
- handle
handle本质上表示是一种资源 , 在不同的操作系统上他们的名称又不一样, 比如在windows上成它为文件句柄 , 而在linux中称它为文件描述符, 其实我这样说, handle的概念就显得比较抽象 不容易理解 , 具体一点说handle是啥呢 ?比如客户端向服务端发送一个连接请求,这个socket请求对操作系统来说, 本质上就是handle
在Reactor线程模型中的Handle 就是限制netty并发量的主要原因, 下面的调优主要也是为了突破这个限制
- Synchronius Event Demultiplexer
意为同步事件分离器, 也是一看这个名字完全没有头绪它是什么, 其实, 在本质上它是一个操作系统层面的系统调用, 操作系统用它来 阻塞的等待 事件的发生, 具体一点它来说, 比如它可以是Linux系统上的IO多路复用, select(), 或者是 poll(),epoll() , 或者是Nio编程模型中的selector, 总之, 它的特点就是阻塞的等待事件的发生
- EventHandler
事件处理器, 事件处理器是拥有Handle的, 我们可以直观将将EventHandler理解成是当系统中发生了某个事件后, 针对这个事件进行处理的回调 , 为啥说是回调, 结合netty的实现中, 我们在启动netty前, 会往他的pipeline中添加大量的handler ,这些handler的地位其实和 EventHandler的地位相当
- concrete EventHandler
顾明思议, 具体的事件处理器的实现, 换句话说, 这是我们根据自己的需求, 不同的业务逻辑自己去添加上去的处理器
- InitiationDispacher
初始分发器, 它其实就是整个编程模型的核心, 没错, 他就是Reactor, 具体怎么理解这个Reactor , 比如我们就能把他看成一个规范, 由它聚合, 支配其他的四大角色之间有条不紊的工作, 迸发出巨大的能量
Reactor线程模型五大角色的关系与工作流程
首先: 我们需要将 EventHandler注册进 Reactor, 通过上图也能看到, EventHandler 拥有 操作系统底层的 Handle,
并且, Reactor 要求, 当EventHandler 注册进自己时, 务必将他关联的handle一并告诉自己, 由Reactor统一进行维护
我们将上面所说的handle , 联想成Nio编程模型中的将channel注册进Selector时刻意,也是必须绑定上的这个感性趣的事件, 牢记, Reactor是的这个模型的核心, 待会操作一旦系统发现handle有了某些变动,需要由Reactor去通知具体哪个EventHandler来处理这个资源. 如何找到正确的EventHandler依赖的就是这个handle , 或者说它是感兴趣的事件
更近一步: 当所有的EventHandler都注册进了Reactor中后, Reactor就开始了它放纵的一生, 于是它开始调与 同步事件分离器通信 ,企图等待一些事件的发生, 什么事件呢? 比如说 socket的连接事件
当同步事件分离器发现了某个handle的状态发生了改变, 比如它的状态变成了ready, 就说明这个handle中发生了感兴趣的事件, 这时, 同步事件分离器会将这个handle的情况告诉Reactor , Reactor进一步用这个handle当成key, 获取出相对应的 EventHandler 开始方法的回调...
如何实现单机百万性能调优
当我们进行socket编程时, 我们得给Server端绑定上一个端口号, 客户端一般会被自动分配Server所在的机器上的一个端口号, 区间一般是1025-65535之间, 这样看上去, 即使服务器的性能再强, 即使netty再快, 并发数目都被操作系统的特性限制的死死的
突破局部文件句柄的限制
像 windows中的句柄或者是linux的文件描述符 这种能打开的资源的数量是有限的, 每一个socket连接都是一个句柄或者是描述符, 换句话说, 这一个特性限制了socket连接数, 也就限制了并发数
查看linux系统中一个进程能打开的单个文件数,(它限制了单个jvm能打开的文件描述符数,每一个tcp连接对linux来说都是一个文件)
ulimit -n
修改这个限制:
# 在 /etc/security/limits.conf 追加以下内容 , 表示任何用户的链接最多都能打开100万个文件 * hard nofile 100000 * soft nofile 100000
重启机器生效:
突破全局文件句柄的限制
查看当前系统中的全局文件句柄数
cat /proc/sys/fs/file-max
修改这个配置
# 在 /etc/sysctl.conf 中追加如下的内容 fs.file-max = 1000000
虚拟机参数的经验值
# 堆内存 -Xms6.5g -Xmx6.5g # 新生代的内存 -XX:NewSize=5.5g -XXMaxNewSize=5.5g # 对外内存 -XX: MaxDirectMemorySize=1g
应用级别的性能调优
问题:
Netty基于Reactor这种线程模型的, 进行非阻塞式编程, 一般我们在编写服务端的代码时, 都会在 往 服务端的Channel pipeline上添加大量的 入站出站处理器, 客户端的消息一般我们都是在 handler中的 ChannelRead() 或者是 ChannelRead0() 中取出来, 再和后台的业务逻辑结合
客户端的消息,会从Pipeline这个双向链表中的header中开始往后传播, 一直到tail, 这其实是个责任链
这时, 如果我们将耗时的操作放在这些处理器中, 毫无疑问, nettey会被拖垮, 系统的并发量也提升不上去
解决方式一:
新开辟一个线程池 , 将耗时的业务逻辑放到新开辟的业务去执行
public class MyThreadPoolHandler extends SimpleChannelInboundHandler<String> {
private static ExecutorService threadPool = Executors.newFixedThreadPool(20);
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) throws Exception {
threadPool.submit(() -> {
Object result = searchFromMysql(msg);
ctx.writeAndFlush(ctx);
});
}
public Object searchFromMysql(String msg) {
Object obj = null;
// todo obj =
return obj;
}
}
解决方式二:
netty 提供的一种原生的解决方式, netty可以将我们的handler 放到一个专门的线程池中去处理
public class MyInitializer extends ChannelInitializer<SocketChannel> {
@Override
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
// 业务线程池
NioEventLoopGroup eventLoopGroup = new NioEventLoopGroup(20);
// 使用这个重载的方法,给handler指定线程池去执行
pipeline.addLast(eventLoopGroup,new MyHandler());
}
}
Netty带给我的收获
能立即成为Netty的领域的大佬吗?
No!
读过Netty的代码,真的并不意味着即刻成为一个netty领域的大佬,相反读的我发慌, 这么庞大的知识体系, 得用多久去慢慢消化, 我们看到的大佬要么是天才, 要么是在自己多年的使用经验里面历练出来的, 想在netty这个领域有所建树,真的是需要不断是去实践,真的得用多年的工作经验去总结才行!也许这样才可能发自内心的感触到netty为什么要这么实现, 如果想着立即多厉害, 也许是做梦了...
真的熟练掌握了Netty吗?
No!
读过netty, 也并不是意味着可以了解netty整个领域的方方面面, 以及如何恰当的使用netty去解决我们的业务需求, 站在一个学生的角度来看, 这一点我心里感觉的特别深刻, 同样的东西,比如同一个ArrayList, 大家都在用, 但是对它的掌握程度的差距甚至能达到使人瞠目结舌的地步, 不得不承认, 技术是需要时间去积累, 需要时间去消化的东西,就像尘封的酒,越酿越香
有什么收获?
当然,读源码也不是没有用,起码对netty框架整体的架构不是那么是陌生了,当自己遇到bug时,也敢于点开源码去找原因了,这应该是我最大的收获
献上注解过的Netty源码工程
当时我在学netty时, 是从github上拉取的netty原生工程, 然后在本地重新编译运行, 这样我就能在源码工程中写注解, 记笔记...
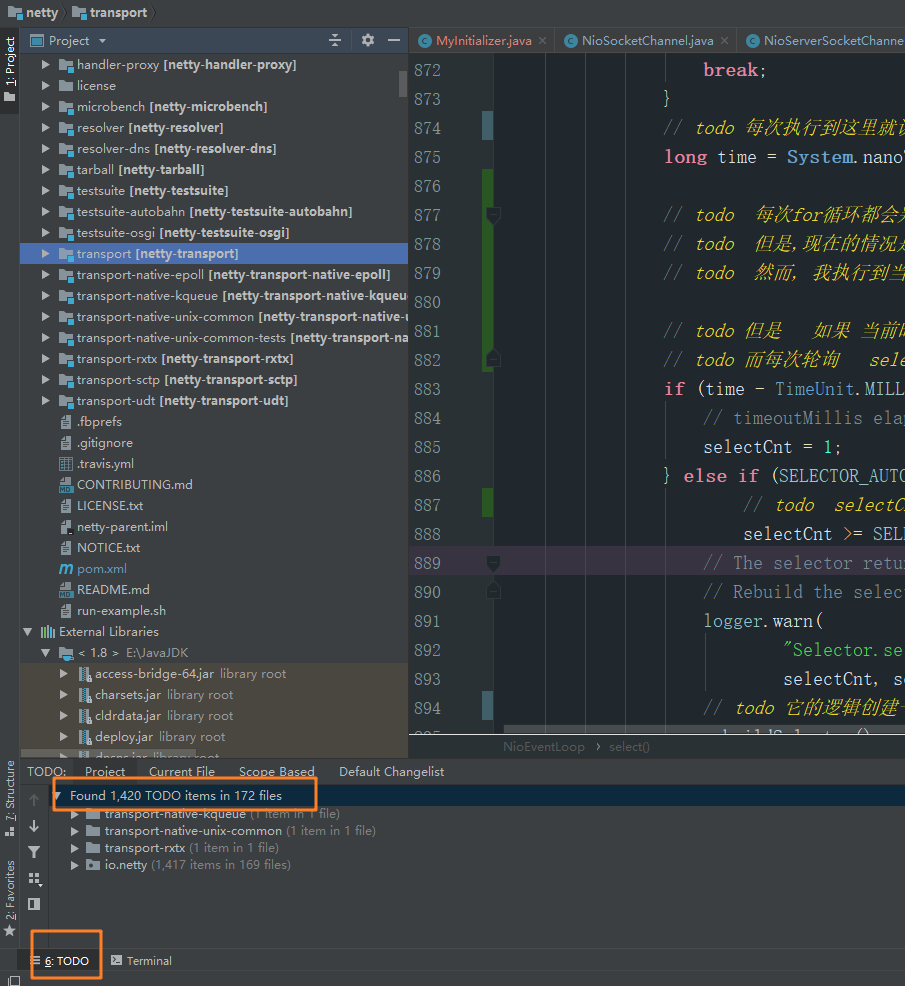
在这个工程里面大概写了 1400 多行注释(所有的笔记都打上了todo 高亮标记) , 也翻译了一些类和方法上的文档和注释, 不能说百分百正确, 但是这个过程也是挺走心的, 比如netty是如何解决JDK空轮询的bug的? 这些在代码中都是有迹可循的,如下
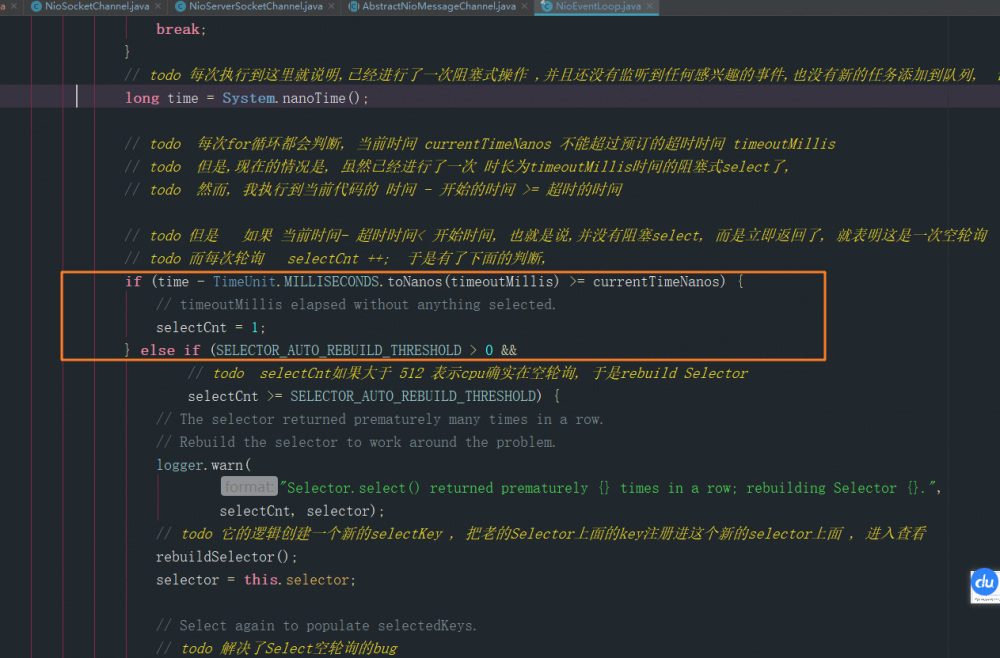
另外一个学习的感触就是忘东西, 还有就是随着时间的推移, 接触到技术会越来越多, 确实很难在同一个时间将学的所有的技术都提升到最高的熟练程度, 好处也有, 可能原来学用了一个星期, 现在重新看只要1天就够了
github地址: https://github.com/zhuchangwu/netty-project
我更推荐你也这样自己编译一个使用,学习netty是一个漫长的过程, 如果你也有一腔热血 , 可以联系我哦...
致敬真神: Netty的创始人trustin lee 和 Netty的开发者们
正文到此结束
- 本文标签: 源码 开发者 TCP 参数 DDL NIO ArrayList 翻译 突破 UI 注释 list src executor 本质 https 配置 时间 key 同步 Service bug 协议 git sql 需求 Select dubbo HTTP服务器 专注 编译 ip cat 代码 解析 开源 处理器 模型 并发 服务器 tomcat 进程 GitHub HTML 总结 Security id 微服务 web 端口 线程 Netty CTO 开发 线程池 服务端 Reactor mysql windows 学生 IDE 创始人 操作系统 http IO JVM linux
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

