基于Calcite自定义JDBC Driver
最近在公司享受福报,所以更新进度严重脱节了,本期依旧是一篇Calcite相关的文章,上一篇《 基于Calcite自定义SQL解析器 》有兴趣的童鞋可以移步去看看。本文我们将介绍一下如何自定义JDBC Driver。
不知道正在读文章的你在刚开始使用JDBC编程的时候,是否很好奇jdbc规范是如何实现的?为什么通过URL,就能打开一个链接,这里面是如何运作的?我们自己是否可以定义一套自己的jdbc url规范?是否想知道ResultSet是如何实现的?反正这些问题,是一直伴随我的编程生涯,直到遇到了Calcite。
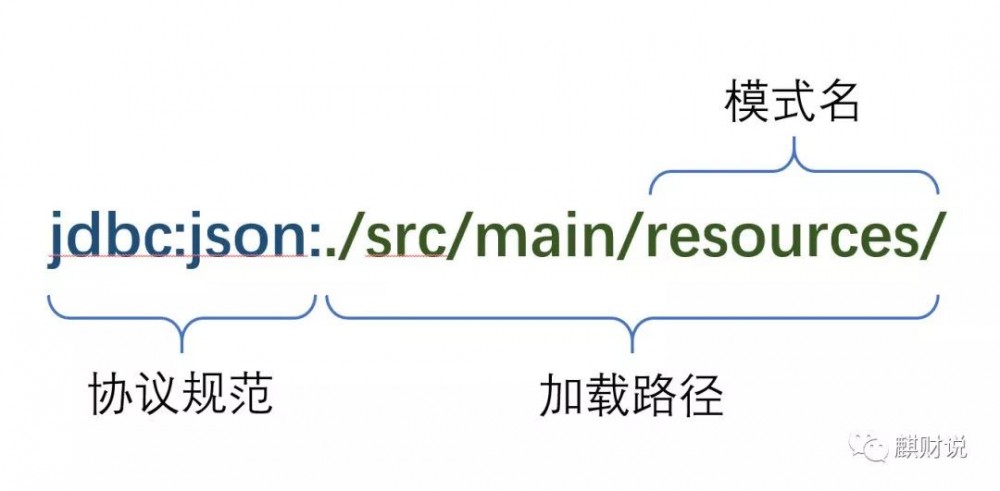
由于篇幅限制,我们本次不会实现那么多内容,今天主要来构建一套自定义JDBC URL 及驱动程序,实现对json的jdbc封装 。 其中url包含如下部分,协议规范使用jdbc:json固定格式,后面跟着一段加载路径,驱动程序将遍历该路径,将json文件加载进来,以json的文件名为表名,加载路径的最后一部分为schema名。如下图所示。

下面是user.json的demo数据
[{
"uid": 1,
"name": "dafei1288",
"age": 33,
"aka": "+7"
},
{
"uid": 2,
"name": "libailu",
"age": 1,
"aka": "maimai"
},
{
"uid": 3,
"name": "libaitian",
"age": 1,
"aka": "doudou"
}
]
下面是order.json的demo数据
[
{
"oid": 1,
"uid": 1,
"value": 11
},
{
"oid": 2,
"uid": 2,
"value": 15
}
]
这里需要我们之前文章里介绍的一些内容,来定义json的schema和table,主要是为了遍历获取元数据,以及迭代数据的时候,使用的方法。
package wang.datahub.jdbc;
import com.google.common.collect.Maps;
import org.apache.calcite.DataContext;
import org.apache.calcite.linq4j.AbstractEnumerable;
import org.apache.calcite.linq4j.Enumerable;
import org.apache.calcite.linq4j.Enumerator;
import org.apache.calcite.linq4j.Linq4j;
import org.apache.calcite.linq4j.tree.Expression;
import org.apache.calcite.linq4j.tree.Expressions;
import org.apache.calcite.linq4j.tree.Types;
import org.apache.calcite.rel.type.RelDataType;
import org.apache.calcite.rel.type.RelDataTypeFactory;
import org.apache.calcite.schema.ScannableTable;
import org.apache.calcite.schema.SchemaPlus;
import org.apache.calcite.schema.Schemas;
import org.apache.calcite.schema.Statistic;
import org.apache.calcite.schema.Statistics;
import org.apache.calcite.schema.Table;
import org.apache.calcite.schema.impl.AbstractSchema;
import org.apache.calcite.schema.impl.AbstractTable;
import org.apache.calcite.util.BuiltInMethod;
import org.apache.calcite.util.Pair;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class JsonSchema extends AbstractSchema {
private String target;
private String topic;
static Map<String, Table> table = Maps.newHashMap();
public JsonSchema(){
super();
}
public void put(String topic, String target) {
this.topic = topic;
if (!target.startsWith("[")) {
this.target = '[' + target + ']';
} else {
this.target = target;
}
final Table table = fieldRelation();
if (table != null) {
this.table.put(topic,table);
}
}
public JsonSchema(String topic, String target) {
super();
this.put(topic,target);
}
@Override
public String toString() {
return "wang.datahub.jdbc.JsonSchema(topic=" + topic + ":target=" + target + ")"+ this.table;
}
public String getTarget() {
return target;
}
@Override
protected Map<String, Table> getTableMap() {
return table;
}
Expression getTargetExpression(SchemaPlus parentSchema, String name) {
return Types.castIfNecessary(target.getClass(),
Expressions.call(Schemas.unwrap(getExpression(parentSchema, name), JsonSchema.class),
BuiltInMethod.REFLECTIVE_SCHEMA_GET_TARGET.method));
}
private <T> Table fieldRelation() {
JSONArray jsonarr = JSON.parseArray(target);
// final Enumerator<Object> enumerator = Linq4j.enumerator(list);
return new JsonTable(jsonarr);
}
private static class JsonTable extends AbstractTable implements ScannableTable {
private final JSONArray jsonarr;
// private final Enumerable<Object> enumerable;
public JsonTable(JSONArray obj) {
this.jsonarr = obj;
}
public RelDataType getRowType(RelDataTypeFactory typeFactory) {
final List<RelDataType> types = new ArrayList<RelDataType>();
final List<String> names = new ArrayList<String>();
JSONObject jsonobj = jsonarr.getJSONObject(0);
for (String string : jsonobj.keySet()) {
final RelDataType type;
type = typeFactory.createJavaType(jsonobj.get(string).getClass());
names.add(string);
types.add(type);
}
if (names.isEmpty()) {
names.add("line");
types.add(typeFactory.createJavaType(String.class));
}
return typeFactory.createStructType(Pair.zip(names, types));
}
public Statistic getStatistic() {
return Statistics.UNKNOWN;
}
public Enumerable<Object[]> scan(DataContext root) {
return new AbstractEnumerable<Object[]>() {
public Enumerator<Object[]> enumerator() {
return new JsonEnumerator(jsonarr);
}
};
}
}
public static class JsonEnumerator implements Enumerator<Object[]> {
private Enumerator<Object[]> enumerator;
public JsonEnumerator(JSONArray jsonarr) {
List<Object[]> objs = new ArrayList<Object[]>();
for (Object obj : jsonarr) {
objs.add(((JSONObject) obj).values().toArray());
}
enumerator = Linq4j.enumerator(objs);
}
public Object[] current() {
return (Object[]) enumerator.current();
}
public boolean moveNext() {
return enumerator.moveNext();
}
public void reset() {
enumerator.reset();
}
public void close() {
enumerator.close();
}
}
}
下面是我们的驱动程序,在这里,我们定义jdbc url字符串,并在创建连接的时候,对url进行分析,并将json的名字,注册到root schema 。 当然这里是最小化实现,我们继承了
org.apache.calcite.jdbc.Driver
如果完全自定义的话,则需要实现的更多一些。基本原则是不变的。
import org.apache.calcite.jdbc.CalciteConnection;
import org.apache.calcite.schema.SchemaPlus;
import java.io.File;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.Properties;
import java.util.stream.Collectors;
public class Driver extends org.apache.calcite.jdbc.Driver {
public static final String CONNECT_STRING_PREFIX = "jdbc:json:";
static {
new Driver().register();
}
@Override protected String getConnectStringPrefix() {
return CONNECT_STRING_PREFIX;
}
@Override
public Connection connect(String url, Properties info) throws SQLException {
Connection c = super.connect(url, info);
CalciteConnection optiqConnection = (CalciteConnection) c.unwrap(CalciteConnection.class);
SchemaPlus rootSchema = optiqConnection.getRootSchema();
String[] pars = url.split(":");
Path f = Paths.get(pars[2]);
try {
JsonSchema js = new JsonSchema();
Files.list(f).forEach(it->{
File file = it.getName(it.getNameCount()-1).toFile();
String filename = file.getName();
filename = filename.substring(0,filename.lastIndexOf("."));
String json = "";
try {
json = Files.readAllLines(it.toAbsolutePath()).stream().collect(Collectors.joining());//.forEach(line->{ sb.append(line);
} catch (Exception e) {
e.printStackTrace();
}
js.put(filename,json);
});
//
rootSchema.add(f.getFileName().toString(), js);
} catch (Exception e) {
e.printStackTrace();
}
return c;
}
}
下面是测试代码,通过标准JDBC的方式获取连接,使用自定义的url,
jdbc:json:./src/main/resources/
然后就是几个测试的sql了,这里分别查了两个表,以及做了一个join。
import com.alibaba.fastjson.JSONObject;
import java.sql.*;
public class CalciteTest1 {
public static void main(String[] args) throws Exception {
Class.forName("wang.datahub.jdbc.Driver");
Connection connection = DriverManager.getConnection("jdbc:json:./src/main/resources/");
Statement statement = connection.createStatement();
ResultSet resultSet = resultSet = statement.executeQuery(
"select /"user/"./"uid/" from /"resources/"./"user/" ");
printResultSet(resultSet);
resultSet = statement.executeQuery(
"select * from /"resources/"./"order/" ");
printResultSet(resultSet);
resultSet = statement.executeQuery(
"select * from /"resources/"./"user/" inner join /"resources/"./"order/" on /"user/"./"uid/" = /"order/"./"uid/"");
printResultSet(resultSet);
}
public static void printResultSet(ResultSet resultSet) throws SQLException {
while(resultSet.next()){
JSONObject jo = new JSONObject();
int n = resultSet.getMetaData().getColumnCount();
for (int i = 1; i <= n; i++) {
jo.put(resultSet.getMetaData().getColumnName(i), resultSet.getObject(i));
}
System.out.println(jo.toJSONString());
}
}
}
控制台,输出结果如下:
{"uid":1}
{"uid":2}
{"uid":3}
{"uid":1,"oid":1,"value":11}
{"uid":2,"oid":2,"value":15}
{"uid":1,"aka":"+7","name":"dafei1288","oid":1,"value":11,"age":33}
{"uid":2,"aka":"maimai","name":"libailu","oid":2,"value":15,"age":1}
好了,自定义jdbc driver部分,先说到这里,其实要想真正实现好一个自己的驱动,还需要处理很多东西,可能很琐碎,也有很多乐趣,希望在逐步分解中,为大家带来一点不一样的东西,也期待您的意见与建议。
如果文章对您有帮助
欢迎关注,分享

你 「 在看 」 吗?
正文到此结束
- 本文标签: tab cat 基本原则 key http ArrayList 测试 tar 代码 json src HashMap 协议 Google Select lib id root js IDE parse schema 希望 apache https 数据 遍历 Connection IO stream zip struct UI 解析 final NIO ResultSet java ip map App list 文章 Statement db sql CTO value ACE JDBC
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

