云容器迁移请求丢失问题分析和排查
前言
近些年来,随着微服务系统大热,docker云容器部署已是不可忽略的话题。笔者负责的产品线应用原本是部署在虚拟机上,公司统一要求产品线应用全部迁移到docker云容器中。在迁移过程中,遇到了客户端请求丢失的问题,在此梳理总结一下供读者参考,以免出现同样的问题。
本文来自于我的博客网站 http://51think.net ,欢迎来访。
问题现象
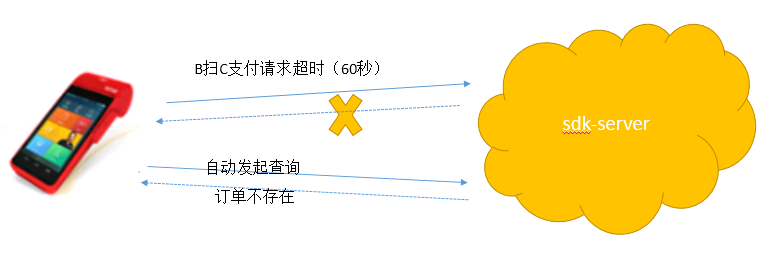
1、POS终端会发起支付请求,业务码为SDK040,服务端60秒内没有给予响应,请求超时。
2、请求超时后,POS终端自动发起查询请求,业务码为SDK041,服务端返回错误信息“订单不存在”。
这个问题只是概率性出现,出现概率约为千分之一,通过压测也没有复现这个问题。
问题规律
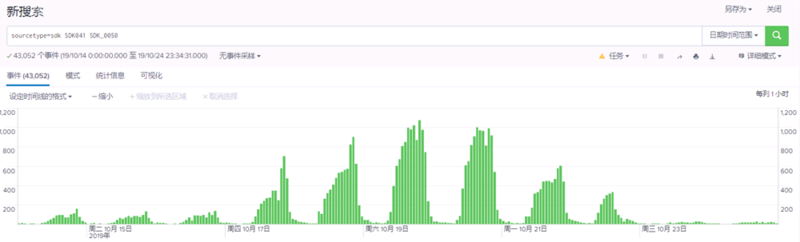
我们通过splunk日志查询发现有如下规律:
1、订单不存在的报错之前就存在,量比较少,没有报障。
2、上云之后,订单不存在问题激增,客户投诉。
3、9月26号切5%的量到云容器,错误量上涨三倍左右。
4、10月17号切40%的量到云容器,错误量上涨5至10倍。
5、10月22号下午将量全部迁回虚拟机,错误量回归至以往正常水平。
如下截图展示了,一个时间段内报有“订单不存在”错误日志的统计规律,即上云之前错误量少,上云之后(10月17日-10月22日)错误量明显增多:
问题分析
从上述的问题规律中可以看出,订单不存在的错误量在上云之后明显增加。通过代码分析得知,后台报订单不存在的原因在于数据表里没有落地本次订单交易。通过订单号查询日志,发现SDK040的支付请求根本就没有到达服务端应用,更别谈插入数据库。我们把怀疑点瞄向整个网络传输路径,可能是哪个传输过程中把请求拒绝了。先看一下网络路径:
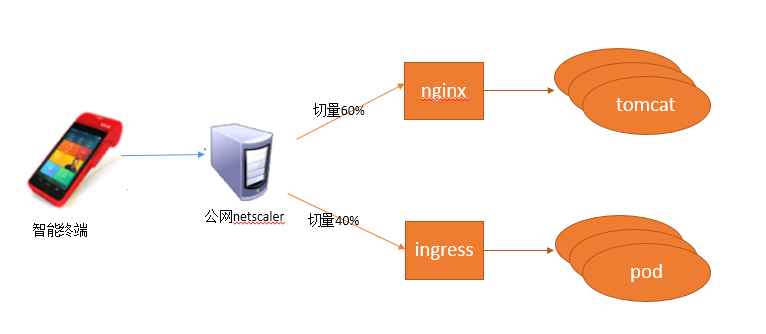
从图中可以看出,POS智能机进行支付时需要经过netscaler设备,然后进入内部代理。nginx是原有的虚机代理,ingress是k8s提供的代理组件,pod是k8s中承载web应用的容器,在本案中和tomcat同级。在进行云容器迁移时,我们通过netscaler切量,将虚机的流量逐步引流到pod中。图中是已经切量了40%到云容器环境中。由于“订单不存在”错误在应用层没有任何日志记录,我们到nginx和ingress日志上看看能否找到一些蛛丝马迹,二者的access日志都是这个样式的:
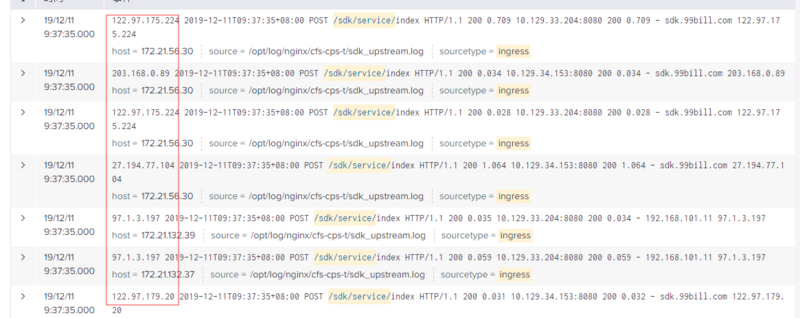
由于POS机客户端都是POST请求,到达nginx层和ingress层的access日志只能看到请求的URI部分,看不到请求参数,只能看到终端的IP信息,无法根据订单号来锁定具体的请求记录,所以我们只能根据终端的IP来查询指定时间范围内有没有请求,结果是令人失望的,问题订单的支付请求到达nginx或者ingress 。
问题排查
请求没有到达nginx或者ingress,意味着三种可能:
1、客户端POS机器没有发出请求。
我们通过客户端远程抓包,发现客户端的确发了请求包,而且还报了socketException错误。问题不可能出现在客户端,因为netscaler切量行为是发生在服务器端,一切量错误数就增加,客户端并没有做任何升级改造。
2、网络抖动导致丢包。
在本例中应该与网络抖动没有关系,netscaler切量不可能导致外部网络抖动。
3、netscaler转发请求是否出了问题。
我们找了IDC相关同事一起排查,IDC同事经过抓包,告知我们说支付请求没有到达netscaler。
那这个支付请求究竟跑哪去了,问题一度陷入僵局。系统组对比过ingress和nginx的配置,说出一个区别就是nginx配置了会话保持sticky session,而ingress没有配置。这个差异最终被我否决了,因为我们的服务端提供的接口都是无状态的,后台会话信息全部共享在redis,并不依赖会话保持。
我们再仔细思考一下整个问题过程,还有一个小规律:切量到ingress,错误数会增加,回切到nginx,错误数不会立即下降,而是缓慢下降,持续两个小时左右,错误数才能恢复到以往正常水平。这一点感觉不合理,如果切量出现的问题,那么切回去应该立即恢复才对,而不是再等个两个小时,这里面肯定有一定的联系。
问题突破
大胆质疑:会不会是, 切量后让整个链路带有一定的特性,然后这个特性会携带到回切后的链路中?并且这个特性持续了两个小时之后才消失?这两个链路的交集是POS机,我们又再次分析了POS机的代码,POS机的收银台功能是安卓写的,http请求使用了httpclient的工具包。
1、http请求的cookie信息
一开始,我以为是cookie在作怪,因为httpclient默认请求的时候会携带上次请求返回的cookie信息,然而,POS端的http调用代码是忽略cookie的,如下:
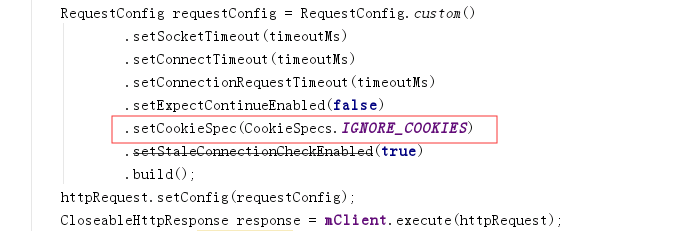
如图中红框配置项所示,即每次请求都是独立的,并不会携带任何cookie信息,线索中断。
2、http请求的header信息
cookie疑问已无望,我们转眼关注二者的header信息差异。我们在内网环境中,直接通过curl -I -X 命令来访问ingress和nginx,看看二者返回的头信息有何差异。
ingress返回的header信息:

nginx返回的header信息:

通过上图发现了一个明显差异,nginx比ingress多了一个配置项keep-Alive:timeout=10,这个配置项的意思是让这个链接保持10秒。而ingress使用的http1.1没有这个配置项,意味着这个链接会默认保持两个小时。两个小时?是不是和之前回切之后错误持续时间等同?嗯,就是这个原因!另外,我们联系了netscaler的厂商,厂商还透露了一个重要信息,netscaler上有个空闲链接时间管理,配置的是180秒,即netscaler会关闭空闲180秒的链接。至此,我们再还原一下问题场景:
切量到ingress后,POS的请求路径是netscaler>ingress>pod,由于ingress没有配置keep-Alive:timeout=10,pos客户端使用httpclient默认保持链接两个小时,而此时netscaler到达了空闲链接阈值180秒,netscaler主动关闭此链接,而POS端的httpclient仍然认为此链接可以复用,再次使用此链接发起请求时,netscaler认为此链接已关闭,会拒绝转发此请求。即使切回nginx,此问题依然会持续一段时间,不会立即消失。
问题解决
将ingress增加keep-Alive:timeout=10配置项,重新切量,问题解决。在此也要提醒一下大家:
1、谨慎使用httpclient。在本例中,POS作为客户端完全没有必要使用httpclient进行连接池管理,可以采用底层java提供的URLConnection来建立短连接,使用完毕后立即关闭,这样也不会带来链接管理的相关问题。
2、中间件替换时要关注各个配置项的差异性。nginx和ingress的这个配置项keep-Alive:timeout=10差异被公司的系统组同事忽略了,认为有connection:keep-Alive配置项就行。后期如果遇到类似奇葩问题,一定要全方位对比各个配置项,不能有缺漏。
正文到此结束
热门推荐









相关文章

近期评论
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
-
https://www.liuhaihua.cn/archives/40657.html 这篇博客中的图片打不开了
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

