你会了吗?Jenkins Pipeline
背景:我们公司的系统是基于分布式的,随着业务的增加,服务数扩增的也比较快,导致上线的工作量倍增,所以就想到了自动化部署,Jenkins刚好满足了我们分布式下自动化部署的需求。
一、Jenkins
什么是 Jenkins?
-
Jenkins是一款开源 CI&CD 软件,用于自动化各种任务,包括构建、测试和部署软件。
-
Jenkins 支持各种运行方式,可通过系统包、Docker 或者通过一个独立的 Java 程序。
关于CI&CD具体解释参考: 什么是 CI/CD?
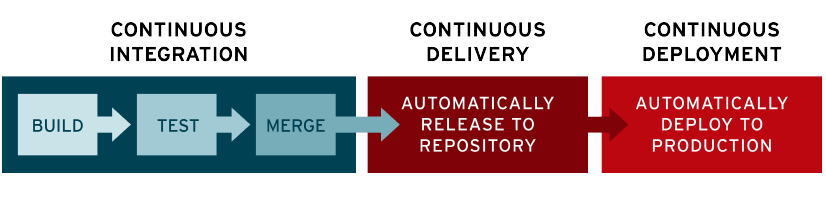
持续集成
现代应用开发 的目标是让多位开发人员同时处理同一应用的不同功能。但是,如果企业安排在一天内将所有分支源代码合并在一起(称为“ 合并日 ”),最终可能造成工作繁琐、耗时,而且需要手动完成。这是因为当一位独立工作的开发人员对应用进行更改时,有可能会与其他开发人员同时进行的更改发生冲突。如果每个开发人员都自定义自己的本地 集成开发环境(IDE) ,而不是让团队就一个基于云的 IDE 达成一致,那么就会让问题更加雪上加霜。
持续集成(CI)可以帮助开发人员更加频繁地(有时甚至每天)将代码更改合并到共享分支或“主干”中。一旦开发人员对应用所做的更改被合并,系统就会通过自动构建应用并运行不同级别的自动化测试(通常是单元测试和集成测试)来验证这些更改,确保这些更改没有对应用造成破坏。这意味着测试内容涵盖了从类和函数到构成整个应用的不同模块。如果自动化测试发现新代码和现有代码之间存在冲突,CI 可以更加轻松地快速修复这些错误。
持续交付
完成 CI 中构建及单元测试和集成测试的自动化流程后,持续交付可自动将已验证的代码发布到存储库。为了实现高效的持续交付流程,务必要确保 CI 已内置于开发管道。持续交付的目标是拥有一个可随时部署到生产环境的代码库。
在持续交付中,每个阶段(从代码更改的合并,到生产就绪型构建版本的交付)都涉及测试自动化和代码发布自动化。在流程结束时,运维团队可以快速、轻松地将应用部署到生产环境中。
持续部署
对于一个成熟的 CI/CD 管道来说,最后的阶段是持续部署。作为持续交付——自动将生产就绪型构建版本发布到代码存储库——的延伸,持续部署可以自动将应用发布到生产环境。由于在生产之前的管道阶段没有手动门控,因此持续部署在很大程度上都得依赖精心设计的测试自动化。
实际上,持续部署意味着开发人员对应用的更改在编写后的几分钟内就能生效(假设它通过了自动化测试)。这更加便于持续接收和整合用户反馈。总而言之,所有这些 CI/CD 的关联步骤都有助于降低应用的部署风险,因此更便于以小件的方式(而非一次性)发布对应用的更改。不过,由于还需要编写自动化测试以适应 CI/CD 管道中的各种测试和发布阶段,因此前期投资还是会很大。
什么是 Jenkins Pipeline?
Jenkins Pipeline(或简称为 "Pipeline")是一套插件,将持续交付的实现和实施集成到 Jenkins 中。持续交付 Pipeline 自动化的表达了这样一种流程:将基于版本控制管理的软件持续的交付到您的用户和消费者手中。 Jenkins Pipeline 提供了一套可扩展的工具,用于将“简单到复杂”的交付流程实现为“持续交付即代码”。Jenkins Pipeline 的定义通常被写入到一个文本文件(称为 Jenkinsfile )中,该文件可以被放入项目的源代码控制库中。
二、安装jenkins
Jenkins的安装方式非常简单,直接去官网下载jenkins的war包,找一台准备安装Jenkins的服务器,并事先安装好Tomcat,然后将War包拷贝到tomcat的webapps文件夹下面,启动tomcat服务器,就可以访问jenkins啦!!例如:localhost:8080/jenkins/ 如下图:
Jenkins基于Docker的安装方式这里就不具体说明。
-
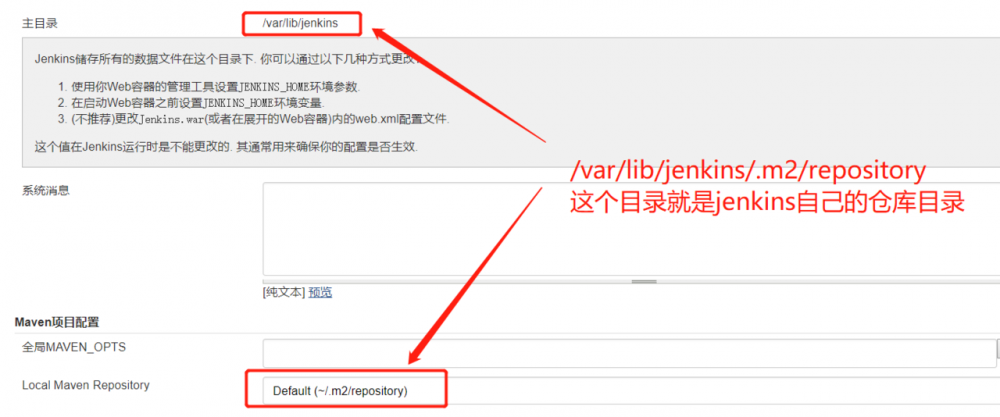
全局配置
进入系统配置中,见下图:配置Jenkins仓库目录
三、Jenkins构建流水线 (Jenkins Pipeline)
通过上面两步我们已经简单了解了Jenkins和Jenkins Pipeline, 并且已经在服务器上面成功安装了Jenkins,那么接下来怎么把项目自动化部署在Jenkins上面呢?这里我们演示的是Jenkins pipeline方式,其它方式不做演示。
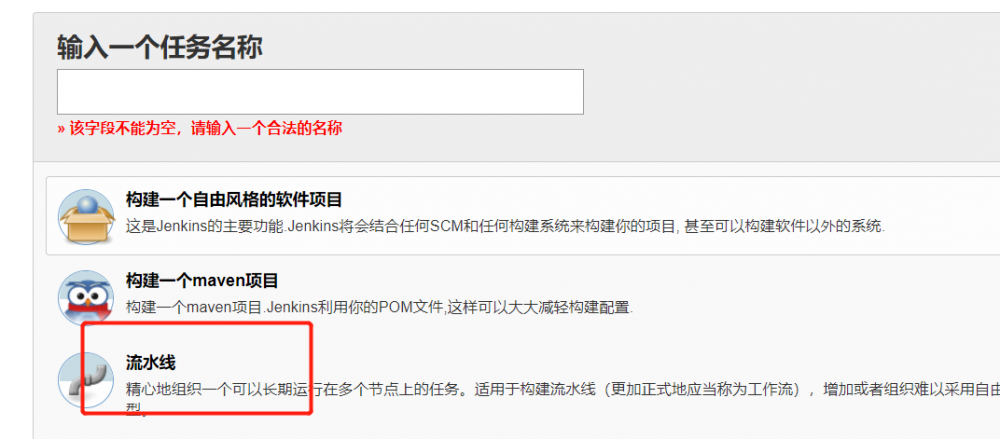
1. 新建流水线
首先点击左侧的新建任务,将看到下面这个界面,任务名称必填,选择类型为流水线。
2. 配置流水线
流水线建好了以后,需要进行配置,主要配置如下图所示:
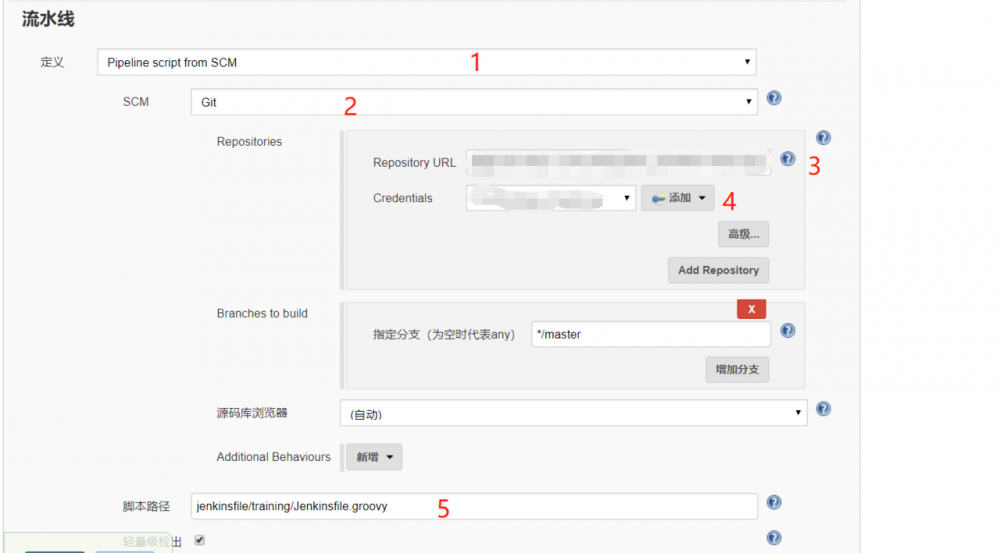
步骤1:选择流水线类型。
Jenkinsfile 能使用两种语法进行编写 - 声明式和脚本化。 声明式和脚本化的流水线从根本上是不同的。 声明式流水线的是 Jenkins 流水线更近的特性: 相比脚本化的流水线语法,它提供更丰富的语法特性,是为了使编写和读取流水线代码更容易而设计的。
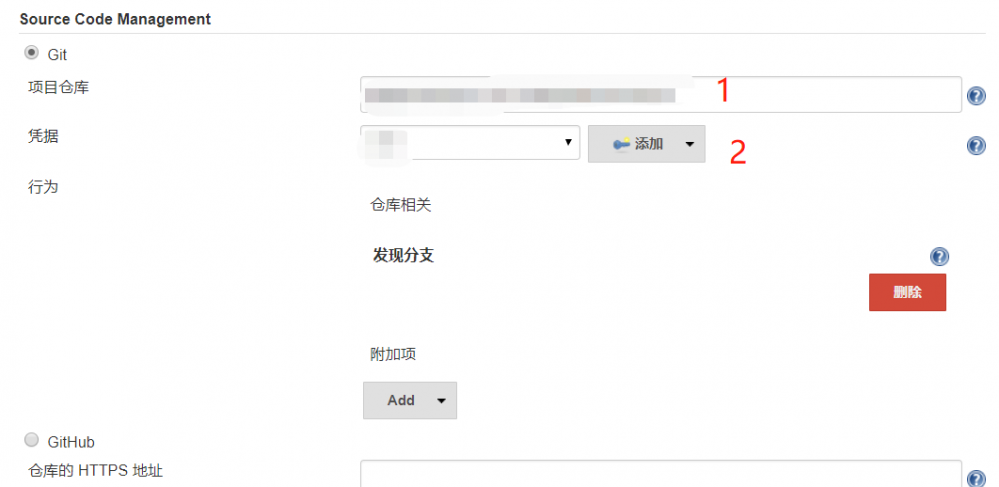
步骤2:软件配置管理( SCM ),选择Git
软件配置管理(SCM)是指通过执行版本控制、变更控制的规程,以及使用合适的配置管理软件, 来保证所有配置项的完整性和可跟踪性。配置管理是对工作成果的一种有效保护。
步骤3:选择JenkinsFile所在的托管仓库地址
本项目托管在阿里云 Jenkinsfile 是一个包含Jenkins Pipeline定义的文本文件,并被检入源代码控制。
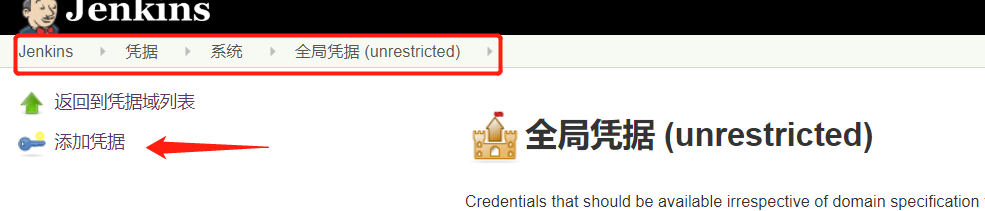
步骤4:添加凭证
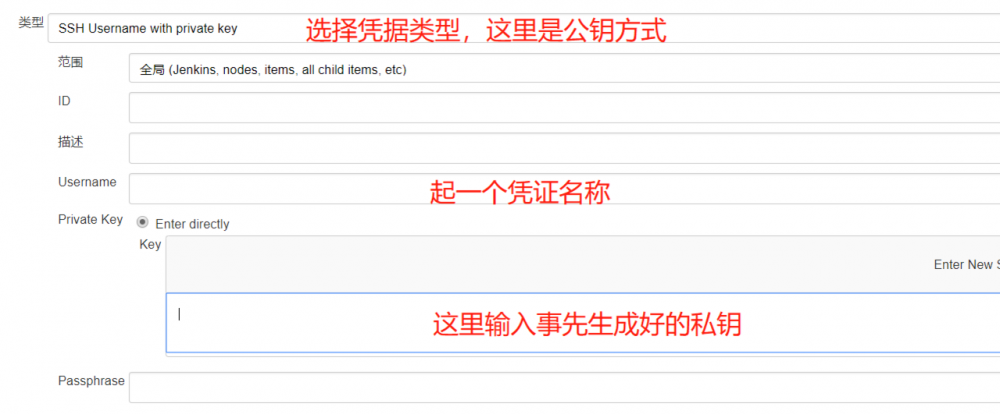
为什么需要凭证:是因为我们的JenkinsFile是托管在阿里云上,所以我们指定文件来源为阿里云托管地址时,访问需要权限控制,这里可以通过系统中生成凭据,再添加进来,具体见下图。选择凭据的类型,这里选择 的是ssh私钥方式,具体操作就是在任何一台计算机中生成公钥和私钥,将公钥拷贝到阿里云代码托管平台,私钥粘贴在下面文本框,点击确定则添加凭证完成,之后我们选择该凭证即可。
步骤5:指定脚本路径
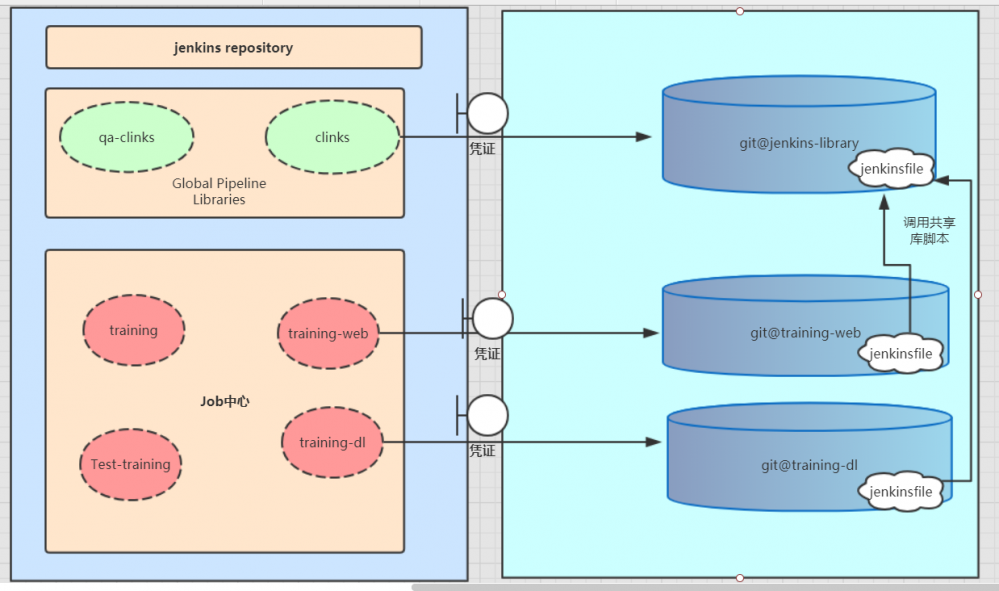
整个流程参考下图:
四、JenkinsFile
现在,我们已经会创建一个流水线任务了,并且基本的配置也差不多完成了,接下来就是说明怎么编写JenkinsFile脚本文件。
我们按照上面步骤又创建了一个流水线任务,其中一个作为构建任务,另一个作为部署任务,接下来就看构建脚本和部署脚本分别这么写。
在开始写脚本之前我们首先了解一下Jenkins共享库library。
library是什么?
library是Jenkins共享库,为什么出现共享库概念,因为当我们写了很多JenkinsFile脚本文件后,我们会发现有很多重复脚本代码操作,例如项目构建、部署的命令,以及一些校验逻辑,都非常重复,每个项目脚本里面几乎都有这些代码,所以Jenkins提供了共享库的概念。大致的含义就是将公共的部分抽取出来,新建一个项目管理这些公共脚本代码,并把项目托管起来,这样我们就可以在每个项目的脚本文件里面调用这个共享库啦!
怎么创建library?
在Jenkins全局配置中找到共享库配置,如下图:
第一步是指定共享库项目的托管地址;
第二步是添加凭证。(凭证逻辑不再说明) 因为共享库脚本都是通过托管工具托管的,所以要访问这些脚本,需要添加凭证。
怎么写构建脚本
我们打开上面用于构建任务指定的JenkinsFile文件,见下图:
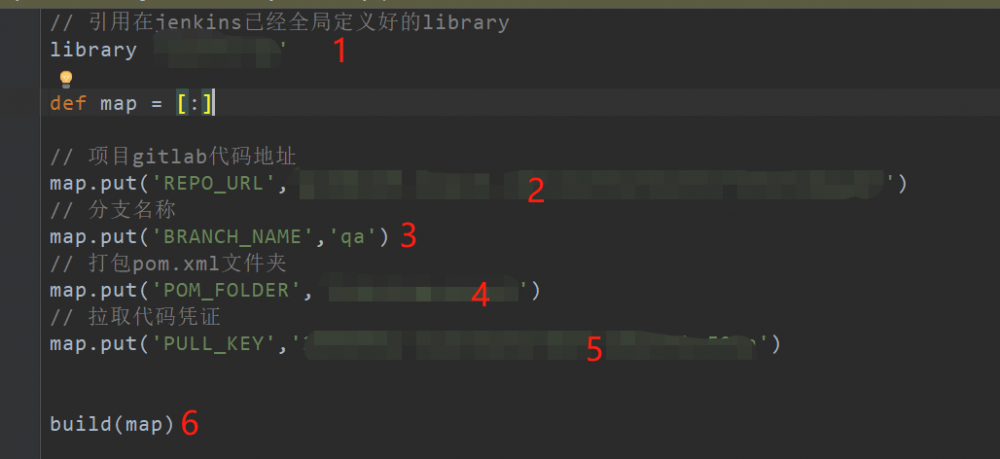
步骤1:指定library名称
步骤2:指定需要构建的项目地址,例如demo项目
步骤3:指定需要构建的分支名称,例如qa
步骤4:指定构建的pom.xml模块位置,例如demo-parent
步骤5:指定凭证,该凭证在上面已经详细说明,在这里是拉取demo项目需要的凭证,如果demo项目和JenkinsFile文件所托管的位置相同,例如都在阿里云,那么直接使用上面的凭证即可。
步骤6:这里的build方法就是调用在共享库中定义的 build 方法,build方法是专门做构建的,并且传入了map参数,下面是写的helloword的构建脚本,内容自定义。
def call(map) {
pipeline {
agent any
parameters {
string(name: 'BRANCH_NAME', defaultValue: "${map.BRANCH_NAME}", description: '选择分支名称')
string(name: 'POM_FOLDER', defaultValue: "${map.POM_FOLDER}", description: '选择pom文件夹')
}
tools {
maven 'maven 3'
}
// 声明全局变量
environment {
REPO_URL = "${map.REPO_URL}"
BRANCH_NAME = "${BRANCH_NAME}"
}
stages {
stage('获取代码') {
steps {
echo "========================开始拉取代码========================"
git branch: "${BRANCH_NAME}", url: "${REPO_URL}", credentialsId: "${map.PULL_KEY}"
echo "代码git地址:" + "${REPO_URL}"
echo "分支名称:" + "${BRANCH_NAME}"
echo "========================结束拉取代码========================"
}
}
stage('编译代码') {
steps {
dir("${map.POM_FOLDER}") {
echo "========================开始编译代码========================"
sh 'mvn clean install -Dmaven.test.skip=true'
echo "========================结束编译代码========================"
}
}
}
}
}
}
复制代码
到了这里,我们的构建任务算是完成了,可以去页面点击立即构建按钮实验一下是否成功,如果是成功的话,我们会发现jenkins已经自动帮我们打好了包。
怎么写部署脚本
我们已经成功打好了war包,那么怎么部署到远程服务器呢,这个脚本该怎么写呢?
同样,我们打开上面用于部署任务的指定的JenkinsFile文件,见下图:
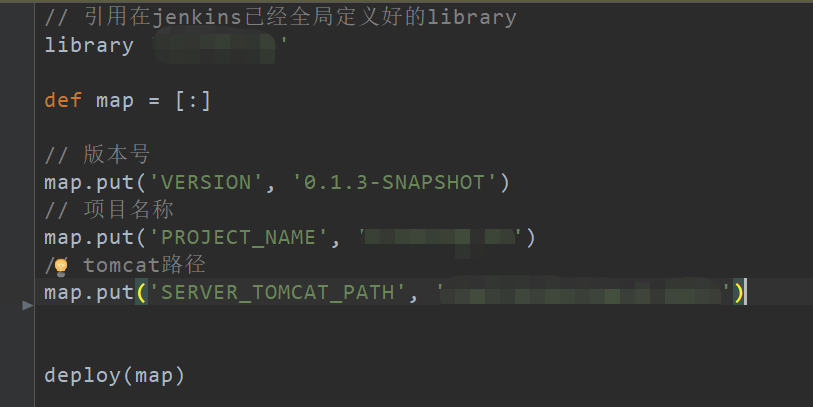
和上面构建脚本类似,传入一些自定义参数,只不过本次调用的是共享库中的 deploy 方法,该方法脚本主要做项目部署工作的。
本次的deploy脚本是核心内容
思考一:怎么在一台服务器杀死另一台服务器tomcat进程?
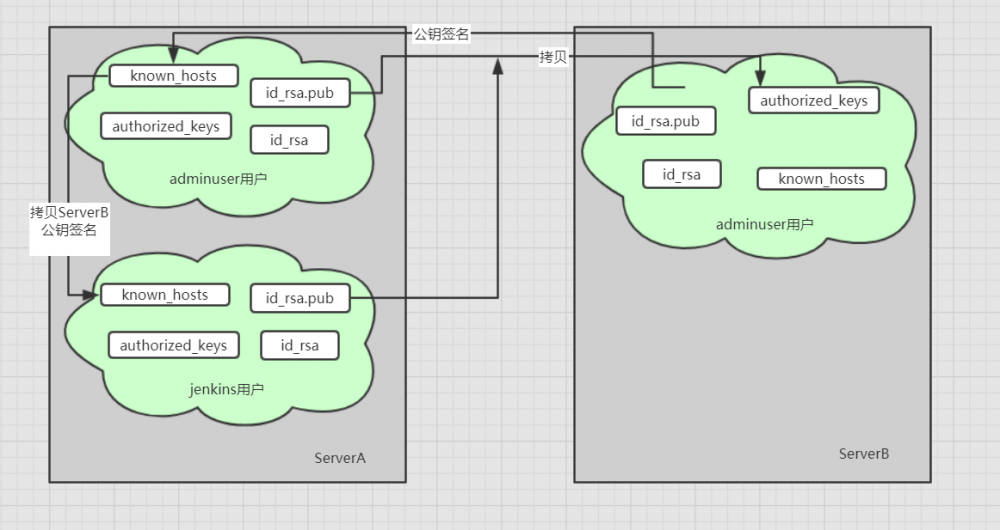
假设我们的Jenkins是安装在服务器ServerA上面,要部署的项目是在服务器ServerB上面,一般手动杀死tomcat我们都会访问ServerB/bin/shutdown.sh可以杀死tomcat进程,那么我们怎么远程操作呢,因为在分布式系统中,我们的项目都是部署在很多不同的服务器,理想状态就是在ServerA可以远程操作其他服务器,控制tomcat生命周期,首先想到的就是ssh,所以尝试配置了免密登录。
常规方法就是将ServerA的adminuser用户下面生成的公钥拷贝到ServerB的adminuser用户下面authorized_keys文件夹,然后通过访问 ssh -p 端口 adminuser@ip 发现ServerA成功登录ServerB,接下来我们ServerA尝试访问命令:
ssh -p 端口 adminuser@ip /${SERVER_B_TOMCAT_PATH}/bin/shutdown.sh,希望通过这种方式可以远程杀死ServerB的tomcat进程, 惊喜的是可以执行成功,所以我们就大胆把这行命令拷贝到Jenkins Pipeline脚本中,脚本如下:
stage('执行shutdown.sh命令') {
steps {
ssh -p 端口 adminuser@ip /${SERVER_B_TOMCAT_PATH}/bin/shutdown.sh
}
}复制代码
本以为可以顺利执行,却出现下面报错Host key verification failed.
思考二:为什么两台服务器已经成功通信,在Jenkins中仍然失败?
按照我的猜想觉得应该可行,但还是失败了,感觉还是没有权限操作,这是什么原因,明明已经两台服务器可以免密登录,为啥还是受限。
之后通过查阅资料发现ssh操作在Jenkins中都是通过凭证来完成的,于是我们又生成了凭证,方式同之前生成凭证方式,点击确定生成了凭证X1,然后利用Jenkins提供的插件:SSH Agent方式,把凭证X1粘贴进去按照官方提供的方式如下,发现并不成功
stage('执行shutdown.sh命令') {
steps {
sshagent ('X1') {
ssh -p 端口 adminuser@ip /${SERVER_B_TOMCAT_PATH}/bin/shutdown.sh
}
}
}复制代码
于是按照网上的方式
stage('执行shutdown.sh命令') {
steps {
sshagent (credentials: ['X1']) {
ssh -p 端口 adminuser@ip /${SERVER_B_TOMCAT_PATH}/bin/shutdown.sh
}
}
}复制代码
心里觉得这次肯定可以,于是执行发现还是之前报错
Host key verification failed.
!!!!欲哭无泪!!!! 只好又去百度,这次又有了新的发现,其实Jenkins启动是由Jenkins用户的,我们刚操作的都是ServerA的adminuser用户,于是我们又进入到Jenkins用户文件夹下面,找到.ssh文件夹,同样的方式生成凭证X2,此时凭证里面的私钥填的是jenkins用户下面的私钥,再SSH Agent尝试一下:
stage('执行shutdown.sh命令') {
steps {
sshagent (credentials: ['X2']) {
ssh -p 端口 adminuser@ip /${SERVER_B_TOMCAT_PATH}/bin/shutdown.sh
}
}
}复制代码
这次总能成功了吧,发现还是抛红了,仍还失败:Host key verification failed.
急急急!!!
思考三:是不是我的方向错了
最后是在同事的帮助下,发现了问题所在,主要原因是自己对SSH原理了解不深刻,导致一直报错Host key verification failed却反应不过来是SSH导致的。
这个主要原因是通过 ssh 连接一台机器的时候需要验证一下 host key, 有两个办法: 一个是在服务端也就是把 ssh 的配置 StrictHostKeyChecking 改成 no ;另外一个就是在需要远程登录的当前用户下面保存一下远程服务器的公钥签名。
什么意思呢?
这里要深入了解一下ssh原理:
SSH提供了口令登录和公钥登录
( 资料来源 )
-
口令登录
如果我们是第一次登录对方服务器,系统会出现下面的提示:
$ ssh user@host The authenticity of host 'host (12.18.429.21)' can't be established. RSA key fingerprint is 98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d. Are you sure you want to continue connecting (yes/no)? 复制代码
这段话的意思是,无法确认host主机的真实性,只知道它的公钥指纹,问你还想继续连接吗?
所谓"公钥指纹",是指公钥长度较长(这里采用RSA算法,长达1024位),很难比对,所以对其进行MD5计算,将它变成一个128位的指纹。上例中是98:2e:d7:e0:de:9f:ac:67:28:c2:42:2d:37:16:58:4d,再进行比较,就容易多了。
很自然的一个问题就是,用户怎么知道远程主机的公钥指纹应该是多少?回答是没有好办法,远程主机必须在自己的网站上贴出公钥指纹,以便用户自行核对。
假定经过风险衡量以后,用户决定接受这个远程主机的公钥。
Are you sure you want to continue connecting (yes/no)? yes复制代码
系统会出现一句提示,表示host主机已经得到认可。
Warning: Permanently added 'host,12.18.429.21' (RSA) to the list of known hosts.复制代码
然后,会要求输入密码。
Password: (enter password)复制代码
如果密码正确,就可以登录了。
-
公钥登录
使用密码登录,每次都必须输入密码,非常麻烦。好在SSH还提供了公钥登录,可以省去输入密码的步骤。
所谓"公钥登录",原理很简单,就是用户将自己的公钥储存在远程主机上。登录的时候,远程主机会向用户发送一段随机字符串,用户用自己的私钥加密后,再发回来。远程主机用事先储存的公钥进行解密,如果成功,就证明用户是可信的,直接允许登录shell,不再要求密码。
这种方法要求用户必须提供自己的公钥。如果没有现成的,可以直接用ssh-keygen生成一个:
$ ssh-keygen复制代码
运行上面的命令以后,系统会出现一系列提示,可以一路回车。其中有一个问题是,要不要对私钥设置口令(passphrase),如果担心私钥的安全,这里可以设置一个。
运行结束以后,在$HOME/.ssh/目录下,会新生成两个文件:id_rsa.pub和id_rsa。前者是你的公钥,后者是你的私钥。
这时再输入下面的命令,将公钥传送到远程主机host上面:
$ ssh-copy-id user@host复制代码
好了,从此你再登录,就不需要输入密码了。
参考上面资料,我们对照自己的情况思考一下,当远程主机的公钥被接受以后,它就会被保存在文件$HOME/.ssh/known_hosts之中。下次再连接这台主机,系统就会认出它的公钥已经保存在本地了,从而跳过警告部分,直接提示输入密码。每个SSH用户都有自己的known_hosts文件,于是我看了一下Jenkins用户下面的known_hosts文件,发现是没有保存ServerB的公钥签名的,于是从ServerA的adminuser用户下面拷贝了一份ServerB的公钥签名,然后再试了一下,发生了感人的一面,居然成功了!!!!原理参考下图:
成功截图:

至此,我们的Jenkins Pipeline也算是成功入门了,过程很坎坷,结局是好的。下面是关于流水线基本语法介绍,在官网都有详细介绍,下面只是部分。
五、流水线语法
stages
包含一系列一个或多个 stage 指令, stages 部分是流水线描述的大部分"work" 的位置。 建议 stages 至少包含一个 stage 指令用于连续交付过程的每个离散部分,比如构建, 测试, 和部署。
| Required | Yes |
|---|---|
| Parameters | None |
| Allowed | Only once, inside the pipeline block. |
示例
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}复制代码
steps
steps 部分在给定的 stage 指令中执行的定义了一系列的一个或多个steps。
| Required | Yes |
|---|---|
| Parameters | None |
| Allowed | Inside each stage block. |
示例
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}复制代码
指令
environment
environment 指令制定一个 键-值对序列,该序列将被定义为所有步骤的环境变量,或者是特定于阶段的步骤, 这取决于 environment 指令在流水线内的位置。该指令支持一个特殊的助手方法 credentials() ,该方法可用于在Jenkins环境中通过标识符访问预定义的凭证。对于类型为 "Secret Text"的凭证, credentials() 将确保指定的环境变量包含秘密文本内容。对于类型为 "SStandard username and password"的凭证, 指定的环境变量指定为 username:password ,并且两个额外的环境变量将被自动定义 :分别为 MYVARNAME_USR和 MYVARNAME_PSW 。
| Required | No |
|---|---|
| Parameters | None |
| Allowed | Inside the pipeline block, or within stage directives. |
示例
pipeline {
agent any
environment {
CC = 'clang'
}
stages {
stage('Example') {
environment {
AN_ACCESS_KEY = credentials('my-prefined-secret-text')
}
steps {
sh 'printenv'
}
}
}
}复制代码
顶层流水线块中使用的 environment 指令将适用于流水线中的所有步骤。 在一个 stage 中定义的 environment 指令只会将给定的环境变量应用于 stage 中的步骤。 environment 块有一个 助手方法 credentials() 定义,该方法可以在 Jenkins 环境中用于通过标识符访问预定义的凭证。
options
`options`` 指令允许从流水线内部配置特定于流水线的选项。 流水线提供了许多这样的选项, 比如 buildDiscarder,但也可以由插件提供, 比如 timestamps.`````
| Required | No |
|---|---|
| Parameters | None |
| Allowed | Only once, inside the pipeline block. |
可用选项
buildDiscarder为最近的流水线运行的特定数量保存组件和控制台输出。
例如: options { buildDiscarder(logRotator(numToKeepStr: '1')) }
disableConcurrentBuilds不允许同时执行流水线。 可被用来防止同时访问共享资源等。
例如: options { disableConcurrentBuilds() }
overrideIndexTriggers允许覆盖分支索引触发器的默认处理。 如果分支索引触发器在多分支或组织标签中禁用,
options { overrideIndexTriggers(true) } 将只允许它们用于促工作。
否则, options { overrideIndexTriggers(false) } 只会禁用改作业的分支索引触发器。
skipDefaultCheckout在`agent` 指令中,跳过从源代码控制中检出代码的默认情况。例如: options { skipDefaultCheckout() }
skipStagesAfterUnstable一旦构建状态变得UNSTABLE,跳过该阶段。例如: options { skipStagesAfterUnstable() }
checkoutToSubdirectory在工作空间的子目录中自动地执行源代码控制检出。例如: options { checkoutToSubdirectory('foo') }
timeout设置流水线运行的超时时间, 在此之后,Jenkins将中止流水线。例如: options { timeout(time: 1, unit: 'HOURS') }
retry在失败时, 重新尝试整个流水线的指定次数。 For example: options { retry(3) }
timestamps预谋所有由流水线生成的控制台输出,与该流水线发出的时间一致。 例如: options { timestamps() }
复制代码
Example
pipeline {
agent any
options {
timeout(time: 1, unit: 'HOURS')
}
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}复制代码
指定一个小时的全局执行超时, 在此之后,Jenkins 将中止流水线运行。 一个完整的可用选项列表正在等待完成第 INFRA-1503次。 复制代码
阶段选项
stage复制代码
的 options 指令类似于流水线根目录上的 options 指令。然而, stage -级别 options 只能包括 retry, timeout, 或 timestamps 等步骤, 或与 stage 相关的声明式选项,如 skipDefaultCheckout。在`stage`, options 指令中的步骤在进入 agent 之前被调用或在 when 条件出现时进行检查。复制代码
可选的阶段选项
skipDefaultCheckout在 agent 指令中跳过默认的从源代码控制中检出代码。例如: options { skipDefaultCheckout() }
timeout设置此阶段的超时时间, 在此之后, Jenkins 会终止该阶段。 例如: options { timeout(time: 1, unit: 'HOURS') }
retry在失败时, 重试此阶段指定次数。 例如: options { retry(3) }
timestamps预谋此阶段生成的所有控制台输出以及该行发出的时间一致。例如: options { timestamps() }
复制代码
示例
pipeline {
agent any
stages {
stage('Example') {
options {
timeout(time: 1, unit: 'HOURS')
}
steps {
echo 'Hello World'
}
}
}
}复制代码
| ** | 指定 Example 阶段的执行超时时间, 在此之后,Jenkins 将中止流水线运行。 |
|---|---|
参数
parameters`` 指令提供了一个用户在触发流水线时应该提供的参数列表。这些用户指定参数的值可通过 params 对象提供给流水线步骤, 了解更多请参考示例。
| Required | No |
|---|---|
| Parameters | None |
| Allowed | Only once, inside the pipeline block. |
可用参数
string字符串类型的参数, 例如: parameters { string(name: 'DEPLOY_ENV', defaultValue: 'staging', description: '') }
booleanParam布尔参数, 例如: parameters { booleanParam(name: 'DEBUG_BUILD', defaultValue: true, description: '') }
复制代码
示例
pipeline {
agent any
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
stages {
stage('Example') {
steps {
echo "Hello ${params.PERSON}"
}
}
}
}复制代码
触发器
triggers 指令定义了流水线被重新触发的自动化方法。对于集成了源( 比如 GitHub 或 BitBucket)的流水线, 可能不需要 triggers ,因为基于 web 的集成很肯能已经存在。 当前可用的触发器是 cron , pollSCM 和 upstream 。
| Required | No |
|---|---|
| Parameters | None |
| Allowed | Only once, inside the pipeline block. |
cron
接收 cron 样式的字符串来定义要重新触发流水线的常规间隔 ,比如: triggers { cron('H */4 * * 1-5') }
pollSCM
接收 cron 样式的字符串来定义一个固定的间隔,在这个间隔中,Jenkins 会检查新的源代码更新。如果存在更改, 流水线就会被重新触发。例如: triggers { pollSCM('H */4 * * 1-5') }
upstream
接受逗号分隔的工作字符串和阈值。 当字符串中的任何作业以最小阈值结束时,流水线被重新触发。例如: triggers { upstream(upstreamProjects: 'job1,job2', threshold: hudson.model.Result.SUCCESS) }
| ** | pollSCM 只在Jenkins 2.22 及以上版本中可用。 |
|---|---|
示例
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
triggers {
cron('H */4 * * 1-5')
}
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}复制代码
stage
stage`` 指令在 stages 部分进行,应该包含一个 实际上, 流水巷所做的所有实际工作都将封装进一个或多个 stage 指令中。
``
| Required | At least one |
|---|---|
| Parameters | One mandatory parameter, a string for the name of the stage. |
| Allowed | Inside the stages section. |
示例
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
}
}
}
}复制代码
工具
定义自动安装和放置 PATH 的工具的一部分。如果 agent none 指定,则忽略该操作。
| Required | No |
|---|---|
| Parameters | None |
| Allowed | Inside the pipeline block or a stage block. |
支持工具
maven
jdk
gradle
示例
pipeline {
agent any
tools {
maven 'apache-maven-3.0.1'
}
stages {
stage('Example') {
steps {
sh 'mvn --version'
}
}
}
}复制代码
input
stage`` 的 input 指令允许你使用 ```[ input step提示输入。 在应用了 options 后,进入 stage 的 agent 或评估 when 条件前,stage 将暂停。 如果 input 被批准, stage 将会继续。 作为 input 提交的一部分的任何参数都将在环境中用于其他 stage。 ]( jenkins.io/doc/pipelin… )
配置项
message必需的。 这将在用户提交 input 时呈现给用户。 idinput 的可选标识符, 默认为 stage 名称。 ok`input`表单上的"ok" 按钮的可选文本。 submitter可选的以逗号分隔的用户列表或允许提交 input 的外部组名。默认允许任何用户。 submitterParameter环境变量的可选名称。如果存在,用 submitter 名称设置。 parameters提示提交者提供的一个可选的参数列表。 更多信息参见 [parameters]。 复制代码
示例
pipeline {
agent any
stages {
stage('Example') {
input {
message "Should we continue?"
ok "Yes, we should."
submitter "alice,bob"
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
}
steps {
echo "Hello, ${PERSON}, nice to meet you."
}
}
}
}复制代码
when
when`` 指令允许流水线根据给定的条件决定是否应该执行阶段。 when 指令必须包含至少一个条件。 如果 when 指令包含多个条件, 所有的子条件必须返回True,阶段才能执行。 这与子条件在 allOf 条件下嵌套的情况相同 (参见下面的示例)。使用诸如 not, allOf, 或 anyOf 的嵌套条件可以构建更复杂的条件结构 can be built 嵌套条件刻意潜逃到任意深度。
| Required | No |
|---|---|
| Parameters | None |
| Allowed | Inside a stage directive |
内置条件
branch当正在构建的分支与模式给定的分支匹配时,执行这个阶段, 例如: when { branch 'master' }。注意,这只适用于多分支流水线。
environment当指定的环境变量是给定的值时,执行这个步骤, 例如: when { environment name: 'DEPLOY_TO', value: 'production' }
expression当指定的Groovy表达式评估为true时,执行这个阶段, 例如: when { expression { return params.DEBUG_BUILD } }
not当嵌套条件是错误时,执行这个阶段,必须包含一个条件,例如: when { not { branch 'master' } }
allOf当所有的嵌套条件都正确时,执行这个阶段,必须包含至少一个条件,例如: when { allOf { branch 'master'; environment name: 'DEPLOY_TO', value: 'production' } }
anyOf当至少有一个嵌套条件为真时,执行这个阶段,必须包含至少一个条件,例如: when { anyOf { branch 'master'; branch 'staging' } }
在进入 stage 的 agent 前评估 when默认情况下, 如果定义了某个阶段的代理,在进入该`stage` 的 agent 后该 stage 的 when 条件将会被评估。但是, 可以通过在 when 块中指定 beforeAgent 选项来更改此选项。 如果 beforeAgent 被设置为 true, 那么就会首先对 when 条件进行评估 , 并且只有在 when 条件验证为真时才会进入 agent 。
复制代码
示例
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
branch 'production'
}
steps {
echo 'Deploying'
}
}
}
}复制代码
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
branch 'production'
environment name: 'DEPLOY_TO', value: 'production'
}
steps {
echo 'Deploying'
}
}
}
}
复制代码
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
allOf {
branch 'production'
environment name: 'DEPLOY_TO', value: 'production'
}
}
steps {
echo 'Deploying'
}
}
}
}
复制代码
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
branch 'production'
anyOf {
environment name: 'DEPLOY_TO', value: 'production'
environment name: 'DEPLOY_TO', value: 'staging'
}
}
steps {
echo 'Deploying'
}
}
}
}
复制代码
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
when {
expression { BRANCH_NAME ==~ /(production|staging)/ }
anyOf {
environment name: 'DEPLOY_TO', value: 'production'
environment name: 'DEPLOY_TO', value: 'staging'
}
}
steps {
echo 'Deploying'
}
}
}
}
复制代码
Jenkinsfile (Declarative Pipeline)
pipeline {
agent none
stages {
stage('Example Build') {
steps {
echo 'Hello World'
}
}
stage('Example Deploy') {
agent {
label "some-label"
}
when {
beforeAgent true
branch 'production'
}
steps {
echo 'Deploying'
}
}
}
}
复制代码
并行
声明式流水线的阶段可以在他们内部声明多隔嵌套阶段, 它们将并行执行。 注意,一个阶段必须只有一个 steps 或 parallel 的阶段。 嵌套阶段本身不能包含进一步的 parallel 阶段, 但是其他的阶段的行为与任何其他 stage 相同。任何包含 parallel 的阶段不能包含 agent 或 tools 阶段, 因为他们没有相关 steps。另外, 通过添加 failFast true 到包含 parallel 的 `stage 中, 当其中一个进程失败时,你可以强制所有的 parallel 阶段都被终止。
示例
pipeline {
agent any
stages {
stage('Non-Parallel Stage') {
steps {
echo 'This stage will be executed first.'
}
}
stage('Parallel Stage') {
when {
branch 'master'
}
failFast true
parallel {
stage('Branch A') {
agent {
label "for-branch-a"
}
steps {
echo "On Branch A"
}
}
stage('Branch B') {
agent {
label "for-branch-b"
}
steps {
echo "On Branch B"
}
}
}
}
}
}
复制代码
步骤
声明式流水线可能使用在 流水线步骤引用 中记录的所有可用的步骤, 它包含一个完整的步骤列表, 其中添加了下面列出的步骤,这些步骤只在声明式流水线中 only supported 。
脚本
script 步骤需要 [ scripted-pipeline] 块并在声明式流水线中执行。 对于大多数用例来说,应该声明式流水线中的“脚本”步骤是不必要的, 但是它可以提供一个有用的"逃生出口"。 非平凡的规模和/或复杂性的 script 块应该被转移到 共享库 。
示例
Jenkinsfile (Declarative Pipeline)
pipeline {
agent any
stages {
stage('Example') {
steps {
echo 'Hello World'
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < browsers.size(); ++i) {
echo "Testing the ${browsers[i]} browser"
}
}
}
}
}
}
复制代码
脚本化流水线
脚本化流水线, 与[ declarative-pipeline] 一样的是, 是建立在底层流水线的子系统上的。与声明式不同的是, 脚本化流水线实际上是由 Groovy 构建的通用 DSL [ 2 ]。 Groovy 语言提供的大部分功能都可以用于脚本化流水线的用户。这意味着它是一个非常有表现力和灵活的工具,可以通过它编写持续交付流水线。
流控制
脚本化流水线从 Jenkinsfile 的顶部开始向下串行执行, 就像 Groovy 或其他语言中的大多数传统脚本一样。 因此,提供流控制取决于 Groovy 表达式, 比如 if/else 条件, 例如:
Jenkinsfile (Scripted Pipeline)
node {
stage('Example') {
if (env.BRANCH_NAME == 'master') {
echo 'I only execute on the master branch'
} else {
echo 'I execute elsewhere'
}
}
}
复制代码
另一种方法是使用Groovy的异常处理支持来管理脚本化流水线流控制。当 步骤 失败 ,无论什么原因,它们都会抛出一个异常。处理错误的行为必须使用Groovy中的 try/catch/finally 块 , 例如:
Jenkinsfile (Scripted Pipeline)
正文到此结束
- 本文标签: Master 回答 tk ssh node git map 需求 value 开发 build 下载 希望 权限控制 tag java 端口 ip 安全 代码 key 参数 example 项目管理 MQ bug 加密 目录 tab shell 网站 GitHub XML 阿里云 投资 Word 分布式系统 stream 云 测试 tomcat cat 管理 Docker 软件 企业 生命 IO 分布式 retry 编译 pom 进程 IDE App 插件 Webapps http message tomcat进程 单元测试 服务器 maven description UI CTO 组织 开源 主机 FAQ id Agent web jenkins 配置 空间 Chrome 百度 src trigger 服务端 索引 部署 apache 自动化 https 安装 时间 list final lib Job
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

