JVM默认垃圾回收器工作原理
本文翻译自Oracle的一篇 文章 。
垃圾回收(GC)是一种对程序中不再使用的内存空间进行自动回收并复用的方式。有别于其它需要手动创建和销毁对象的编程语言,因为GC机制的存在,Java开发人员不需要检查每个对象是否必需的。相反,强大的GC进程会在背后默默丢弃无用的对象,并对剩余的对象进行整理。这种机制使得程序运行时效率更高。
什么是垃圾回收?
JVM使用对象形式来组织程序数据。对象会包含若干域(数据),这些数据存在名为 heap 的托管地址空间中。
考虑一个二叉树节点类定义:
class TreeNode {
public TreeNode left, right;
public int data;
TreeNode(TreeNode l, TreeNode r, int d) {
left = l; right = r; data = d;
}
public void setLeft(TreeNode l) { left = l;}
public void setRight(TreeNode r) {right = r;}
}
复制代码
假设对该类进行以下操作:
TreeNode left = new TreeNode(null, null, 13); TreeNode right = new TreeNode(null, null, 19); TreeNode root = new TreeNode(left, right, 17); 复制代码
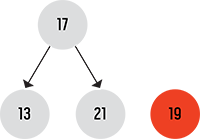
最终,我们创建了一个二叉树,根节点为17,左子节点为13,右子节点为19,入下图
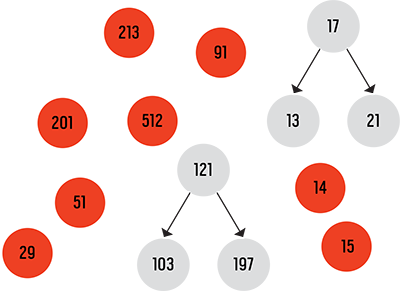
假如我们将右子节点替换,将子节点19变成一个孤立的垃圾对象:
root.setRight(new TreeNode(null, null, 21)); 复制代码
结果如下图
可以想见,在对数据结构进行构建和操作的过程中,堆应该类似于这样的状态:
整理数据,意味着需要改变其在内存中的地址。Java程序期望能根据特定的地址找到相应对象,如果垃圾回收器移动了对象,那么Java程序也需要知道该对象新的位置。要实现这一要求,最简单的方式就是停止所有的Java线程,整理所有对象,更新所有指向旧地址的应用,将其指向新的地址,之后再恢复Java程序。但是,这种方式会导致很长的GC周期( GC停顿时间 ),即Java线程不再运行的时间。
程序无法运行,这是每一个研发人员都无法接受的。对此,有两种方式来降低GC停顿时间,通常Java文献中将其称为 并发算法 (在程序运行时工作)和 并行算法 (在Java线程停止时,启用更多线程以期更快结束工作)。JDK 8中的默认垃圾收集器(可以在命令行中通过 -XX:+UseParallelGC 手动启用)就是使用了并行策略,使用了大量GC线程来获取出色的吞吐量。
并行垃圾收集器
并行垃圾收集器根据对象存活的GC周期数,将对象分置于两个区域——年轻代和老年代。新生成的对象初始时会分配在年轻代,在整理阶段,如果对象存活周期数未达到特定值的话,就继续留在年轻代。如果存活时间足够长,则会升入老年代。这种方式不会暂停程序之后清理整个堆空间——这样会花费很长时间,而且只清理可能包含短期存活对象的堆空间。随着程序运行,也有必要对存活更长的对象进行清理。
如果要只对年轻对象进行整理,垃圾回收器就需要了解老年代的哪些对象引用了年轻代中的对象。这些老年对象需要更新引用,指向年轻对象的新位置。JVM通过获取名为 卡表 的数据结构来完成,当老年代对象中写入引用时,会在卡表中进行标记。因为在下一个young GC周期中,JVM可以通过扫描该卡表来查找老年代执行年轻代的引用。因为这些引用已知,并行垃圾回收器也就可以识别,哪些对象可以清除,哪些引用需要更新。当垃圾回收器暂停程序之后,会使用多个GC线程来保证整理工作能尽快完成。
G1垃圾收集器
JDK中的G1垃圾收集器同时使用了并发线程和并行线程。程序运行时,使用并发线程扫描存活对象;使用并行线程来快速拷贝对象,降低程序暂停时间。
G1将堆空间划分为很多分区,在程序运行过程中,一个分区既可以是老年代,也可以是年轻代。年轻代分区在每个GC周期都必须进行回收,但是对于老年代分区,G1会根据用户指定的GC停顿时间要求,灵活选择可以回收的分区数量。这种灵活性也保证了G1可以将老年代GC工作集中在垃圾对象最多的分区进行,同时也使得G1可以根据用户指定的GC停顿时间来调整垃圾收集的停顿时间。
如下图所示,G1会将对象整理到新的分区中。 Region1 和 Redion2 内的对象被整理到 Region4 ,新对象也会分配在 Region4 。 Region3 因为过多的复制操作(70%)和较低的空间回收率(30%),没有被垃圾回收器处理。
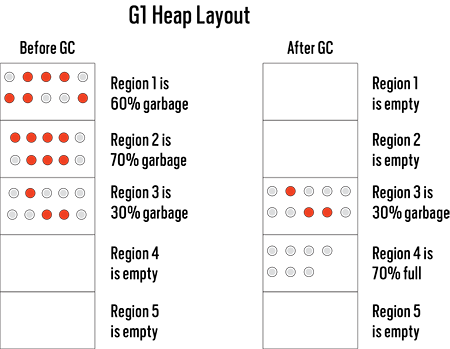
G1回收器清楚每个分区中有多少数据,以及拷贝其中的存活对象所消耗的大致时间。如果用户期望GC停顿时间短,G1会选择回收一些分区,如果用户不关心GC停顿时间,或者期望的停顿时间比较长,G1会选择回收更多的分区。
G1回收器如果要只手机年轻代分区,必须维护一个卡表数据结构,同时也需要记录每个老年代分区被其它老年代分区的引用,这个数据结构叫做 into remembered set 。
停顿时间设置较短的一个缺点在于,G1可能会跟不上程序的内存分配速率,这种情况下回收器会放弃并回退为STW GC模式。也就是说,扫描和拷贝都是在Java线程暂停的时候完成的。注意,如果垃圾回收器在进行部分收集时无法满足对停顿时间的要求,那么 full GC 一定会超过指定的停顿时间。
综合来说,G1是一个平衡和吞吐量和停顿时间的优秀垃圾回收器。
Shenandoah垃圾收集器
Shenandoah垃圾回收器是一个OpenJDK项目,是OpenJDK 12发行版中的一部分,也被移植到了JDK 8和IDK 11。与G1回收器一样,Shenandoah使用了相同的基于分区的堆空间布局方式,并且同样使用并发扫描线程计算每个分区中的存活数据。二者区别之处在于整理阶段的处理方法不同。
Shenandoah使用并发方式对数据进行整理。(明眼人应该注意到一个问题,GC可能会在程序对对象数据进行读写操作时迁移数据,不用担心,这个问题马上就会讲到)因此,Shenandoah不需要为了最小化程序停顿时间而限制回收的分区数量。相对地,它会选择最有效的分区——也就是包含很少存活对象的分区,或者说含有大量无效空间的分区。整个过程中,只有在扫描的初始和结束阶段一些相关步骤中需要停止程序。
Shenandoah并发复制对象的主要难点在于,进行复制工作的GC线程与访问堆存储的Java线程需要就对象的内存地址达成一致。地址可能会存储在多个地方,并且对地址的更新操作必须同时进行。跟计算机科学中的大多数问题一样,解决方法就是增加一层转换。
(这种回收器中)对象结果中分配了额外的空间存储间接指针。当Java线程访问对象时,首先读取间接指针查看对象是否被移动。如果垃圾回收器移动了某个对象,就会更新其间接指针指向新的位置。新分配的对象中的间接指针会指向其自身,而且对象中的间接指针只有在GC过程中被复制时才会指向其它位置。
间接指针的使用并不是无代价的。读取指针已经查找对象的当前位置都需要消耗时间空间,但是这些代码要比你想象的小。空间方面,Shenandoah不需要通过类似卡表和into remembered sets等堆外数据结构来支持部分回收。时间方面,目前也有一些策略来消除阅读障碍。优化的JIT编译器也可以识别到程序在访问一个不可变属性,比如数组的大小,这种情况下无论是读原对象还是副本中的数据都是一样的,因此也就不需要间接阅读。此外,如果Java程序要读取同一个对象中的多个属性,JIT会识别并删除后面对于间接指针的读取。
如果Java程序要写的对象也是Shenandoah回收器正在拷贝的对象,就会出现竞争条件。这个问题可以通过Java线程与GC线程的协作来解决。如果Java线程要对一个需要拷贝的对象进行写操作,Java进程首先会将该对象拷贝到自己的分配区域中,并检查这是否是该对象的第一次拷贝,然后再进行写操作。如果GC线程首先拷贝了对象,那么Java线程可以释放其内存分配,使用GC线程的副本。
Shenandoah消除了拷贝存活对象时对线程的暂停,因此也就提供了更短的程序停顿时间。
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

