Dubbo加权轮询负载均衡的源码和Bug,了解一下?
持续输出原创文章,关注我吧

本文是对于Dubbo负载均衡策略之一的加权随机算法的详细分析。从 2.6.4版本 聊起,该版本在某些情况下存在着 比较严重的性能问题 。由问题入手,层层深入,了解该算法在Dubbo中的演变过程,读懂它的前世今生。
本文目录
第一节:什么是轮询?
本小节主要是介绍轮询算法和其对应的优缺点。引出加权轮询算法。
第二节:什么是加权轮询?
本小节主要是介绍加权轮询的概率,并和加权随机算法做对比。区分两者之间的关系。
第三节:Dubbo 2.6.4版本的实现
本小节主要分析了Dubbo 2.6.4版本的源码,以及对调用过程进行了详细的分析。并引出该版本的性能问题。
第四节:推翻,重建
针对Dubbo 2.6.4版本的性能问题,在对应的issue中进行了激烈的讨论。并提出了第一版优化意见,时间复杂度优化到了常量级。但不久之后,又有人发现了该版本的其他问题,计算过程不够平滑。
第五节:再推翻,再重建,平滑加权。
针对改进后的算法还是不够平滑的问题,最终借助Nginx的思想,融入了平滑加权的过程,形成最终版。
什么是轮询?
在描述加权轮询之前,先解释一下什么是轮询算法,如下图所示:
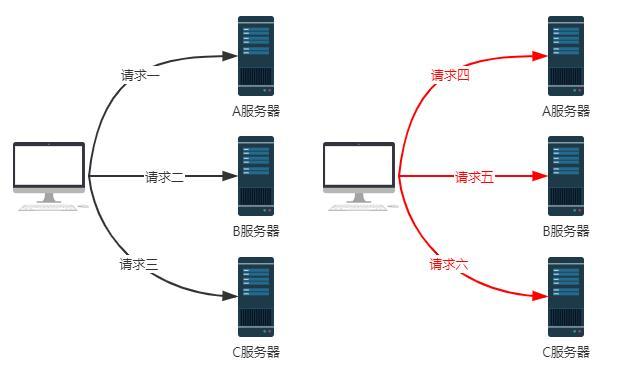
假设我们有A、B、C三台服务器,共计处理6个请求,服务处理请求的情况如下:
第一个请求发送给了A服务器
第二个请求发送给了B服务器
第三个请求发送给了C服务器
第四个请求发送给了A服务器
第五个请求发送给了B服务器
第六个请求发送给了C服务器
......
上面这个例子演示的过程就叫做轮询。可以看出, 所谓轮询就是将请求轮流分配给每台服务器 。
轮询的 优点 是无需记录当前所有服务器的链接状态,所以它一种无状态负载均衡算法,实现简单,适用于每台服务器性能相近的场景下。
轮询的 缺点 也是显而易见的,它的应用场景要求所有服务器的性能都相同,非常的局限。
大多数实际情况下,服务器性能是各有差异,针对性能好的服务器,我们需要让它承担更多的请求,即需要给它配上更高的权重。
所以加权轮询,应运而生。
什么是加权轮询?
为了解决轮询算法应用场景的局限性。当遇到每台服务器的性能不一致的情况,我们需要对轮询过程进行加权,以调控每台服务器的负载。
经过加权后,每台服务器能够得到的请求数比例, 接近或等于他们的权重比。 比如服务器 A、B、C 权重比为 5:3:2。那么在10次请求中,服务器 A 将收到其中的5次请求,服务器 B 会收到其中的3次请求,服务器 C 则收到其中的2次请求。
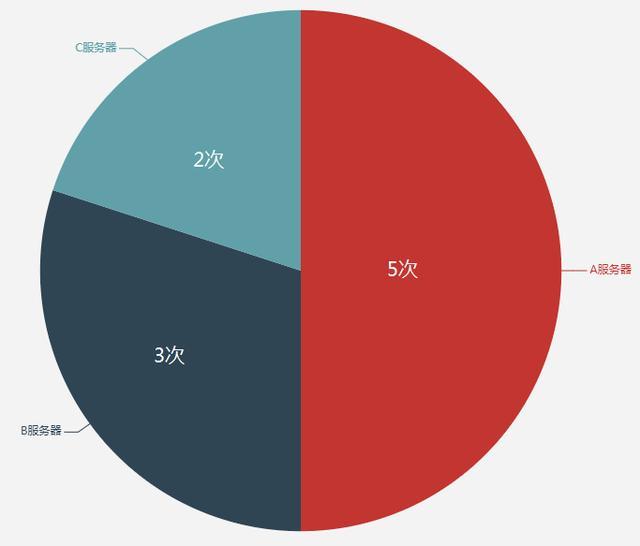
这里要和加权随机算法做区分哦。加权随机我在《一文讲透Dubbo负载均衡之最小活跃数算法》中介绍过,直接把画的图拿过来:

上面这图是按照比例画的,可以直观的看到,对于某一个请求,区间(权重)越大的服务器,就越可能会承担这个请求。所以, 当请求足够多的时候 ,各个服务器承担的请求数,应该就是区间,即权重的比值。
假设有A、B、C三台服务器,权重之比为5:3:2,一共处理10个请求。
那么负载均衡采用 加权随机算法 时, 很有可能 A、B服务就处理完了这10个请求,因为它是随机调用。
负载均衡采用 轮询加权算法 时,A、B、C服务 一定是 分别承担5、3、2个请求。
Dubbo2.6.4版本的实现
对于Dubbo2.6.4版本的实现分析,可以看下图,我加了很多注释,其中的输出语句都是我加的:

示例代码还是沿用之前文章中的Demo,不了解的可以查看《一文讲透Dubbo负载均衡之最小活跃数算法》,本文分别在20881、20882、20883端口启动三个服务,各自的权重分别为1,2,3。
客户端调用8次:
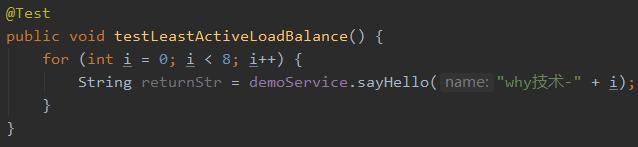
输出结果如下:
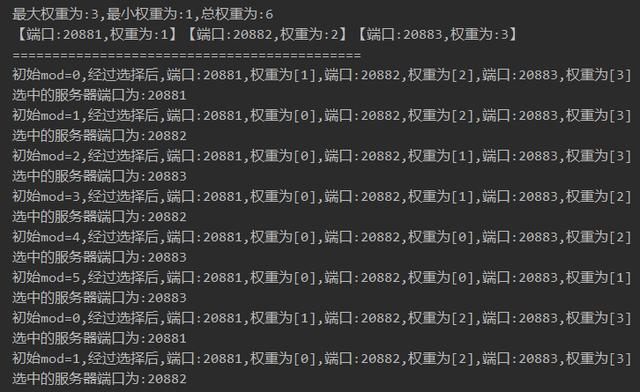
可以看到第七次调用后mod=0,回到了第一次调用的状态。 形成了一个闭环。
再看看判断的条件是什么:
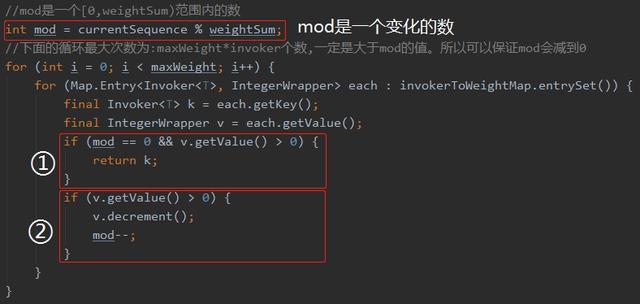
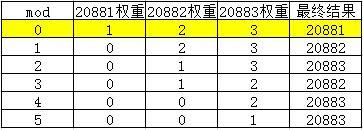
其中 mod在代码中扮演了极其重要的角色 ,mod根据一个方法的调用次数不同而不同, 取值范围是[0,weightSum)。
因为weightSum=6,所以列举mod不同值时,最终的选择结果和权重变化:
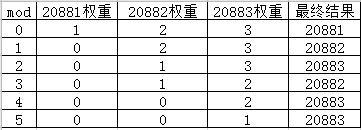
可以看到20881,20882,20883承担的请求数量比值为1:2:3。同时我们可以看出,当 mod >= 1 后,20881端口的服务就不会被选中了 ,因为它的权重被减为0了。当 mod >= 4 后,20882端口的服务就不会被选中了 ,因为它的权重被减为0了。
结合判断条件和输出结果,我们详细分析一下(下面内容稍微有点绕,如果看不懂,多结合上面的图片看几次):
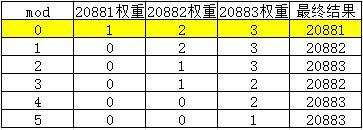
- 第一次调用
mod=0, 第一次循环 就满足代码块①的条件,直接返回当前循环的invoker,即20881端口的服务。此时各端口的权重情况如下:

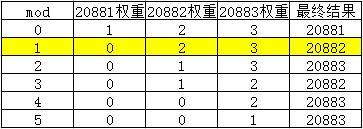
- 第二次调用
mod=1,需要进入代码块②,对mod进行一次递减。
第一次循环对20881端口的服务权重减一,mod-1=0。
第二次循环,mod=0,循环对象是20882端口的服务,权重为2,满足代码块①,返回当前循环的20882端口的服务,此时各端口的权重情况如下:

- 第三次调用
mod=2,需要进入代码块②,对mod进行两次递减。
第一次循环对20881端口的服务权重减一,mod-1=1;
第二次循环对20882端口的服务权重减一,mod-1=0;
第三次循环时,mod已经为0,当前循环的是20883端口的服务,权重为3,满足代码块①,返回当前循环的20883端口的服务,此时各端口的权重情况如下:

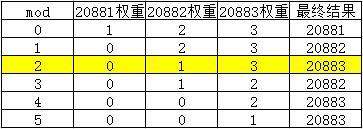
- 第四次调用
mod=3,需要进入代码块②,对mod进行三次递减。
第一次循环对20881端口的服务权重减一,从1变为0,mod-1=2;
第二次循环对20882端口的服务权重减一,从2变为1,mod-1=1;
第三次循环对20883端口的服务权重减一,从3变为2,mod-1=0;
第四次循环的是20881端口的服务,此时mod已经为0,但是20881端口的服务的权重已经变为0了,不满足代码块①和代码块②,进入第五次循环。
第五次循环的是20882端口的服务,当前权重为1,mod=0,满足代码块①,返回20882端口的服务,此时各端口的权重情况如下:

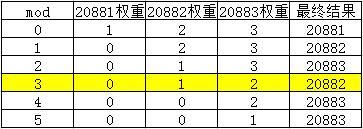
- 第五次调用
mod=4,需要进入代码块②,对mod进行四次递减。
第一次循环对20881端口的服务权重减一,从1变为0,mod-1=3;
第二次循环对20882端口的服务权重减一,从2变为1,mod-1=2;
第三次循环对20883端口的服务权重减一,从3变为2,mod-1=1;
第四次循环的是20881端口的服务,此时mod为1,但是20881端口的服务的权重已经变为0了,不满足代码块②,mod不变,进入第五次循环。
第五次循环时,mod为1,循环对象是20882端口的服务,权重为1,满足代码块②,权重从1变为0,mod从1变为0,进入第六次循环。
第六次循环时,mod为0,循环对象是20883端口的服务,权重为2,满足条件①,返回当前20883端口的服务,此时各端口的权重情况如下:

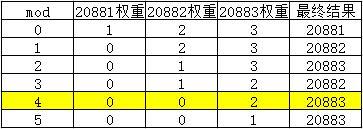
- 第六次调用
第六次调用,mod=5,会 循环九次 ,最终选择20883端口的服务,读者可以自行分析一波,分析出来了,就了解的透透的了。

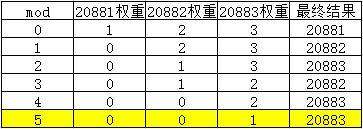
- 第七次调用
第七次调用,又回到mod=0的状态:

2.6.4版本的加权轮询就分析完了,但是事情并没有这么简单。这个版本的加权轮询是有性能问题的。
该问题对应的issue地址如下:
https://github.com/apache/dub...
问题出现在invoker返回的时机上:
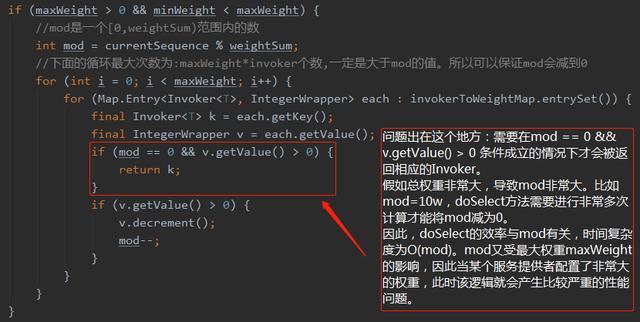
截取issue里面的一个回答:

10分钟才选出一个invoker,还怎么玩?
有时间可以读一读这个issue,里面各路大神针对该问题进行了激烈的讨论,第一种改造方案被接受后,很快就被推翻,被第二种方案代替,可以说优化思路十分值得学习,很精彩,接下来的行文路线就是按照该issue展开的。
推翻,重建。
上面的代码时间复杂度是O(mod),而第一次修复之后时间 复杂度降低到了常量级别 。可以说是一次非常优秀的优化,值得我们学习,看一下优化之后的代码,我加了很多注释:

其关键优化的点是这段代码,我加入输出语句,便于分析。
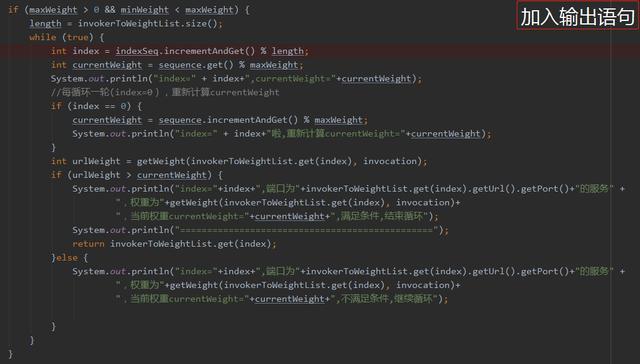
输出日志如下:

把上面的输出转化到表格中去,7次请求的选择过程如下:
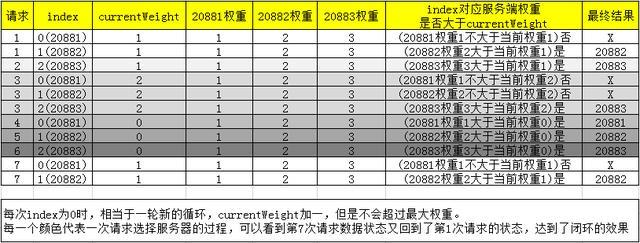
该算法的原理是:
把服务端都放到集合中(invokerToWeightList),然后获取服务端个数(length),并计算出服务端权重最大的值(maxWeight)。
index表示本次请求到来时,处理该请求的服务端下标,初始值为0,取值范围是[0,length)。
currentWeight表示当前调度的权重,初始值为0,取值范围是[0,maxWeight)。
当请求到来时,从index(就是0)开始轮询服务端集合(invokerToWeightList),如果是一轮循环的开始(index=0)时,则对currentWeight进行加一操作(不会超过maxWeight),在循环中找出第一个权重大于currentWeight的服务并返回。
这里说的 一轮循环是指index再次变为0所经历过的循环 ,这里可以把 index=0看做是一轮循环的开始 。每一轮循环的次数与Invoker的数量有关,Invoker数量通常不会太多,所以我们可以认为上面代码的时间复杂度为常数级。
从issue上看出,这个算法最终被merged了。
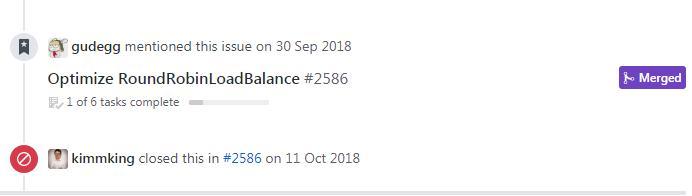
但是很快又被推翻了:
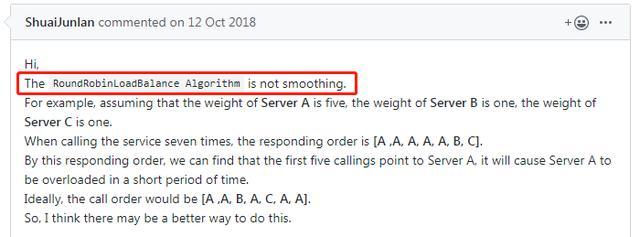
这个算法不够平滑。什么意思呢?
翻译一下上面的内容就是:服务器[A, B, C]对应权重[5, 1, 1]。进行7次负载均衡后,选择出来的序列为[A, A, A, A, A, B, C]。前5个请求全部都落在了服务器A上,这将会使服务器A短时间内接收大量的请求,压力陡增。而B和C此时无请求,处于空闲状态。而我们期望的结果是这样的[A, A, B, A, C, A, A],不同服务器可以穿插获取请求。
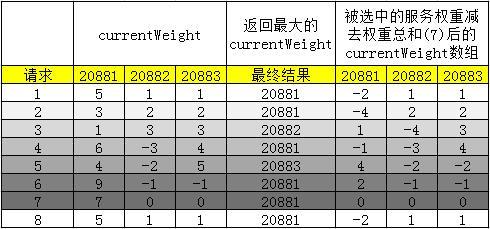
我们设置20881端口的权重为5,20882、20883端口的权重均为1。
进行实验,发现确实如此:可以看到一共进行7次请求,第1次到5次请求都分发给了权重为5的20881端口的服务,前五次请求,20881和20882都处于空闲状态:

转化为表格如下:
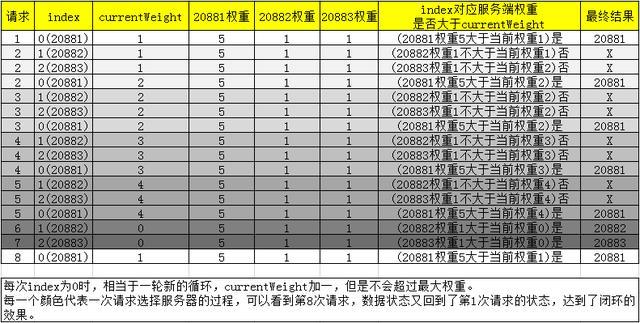
从表格的最终结果一栏也可以直观的看出,七次请求对应的服务器端口为:

分布确实不够均匀。
再推翻,再重建,平滑加权。
从issue中可以看到,再次重构的加权算法的 灵感来源是Nginx的平滑加权轮询负载均衡:
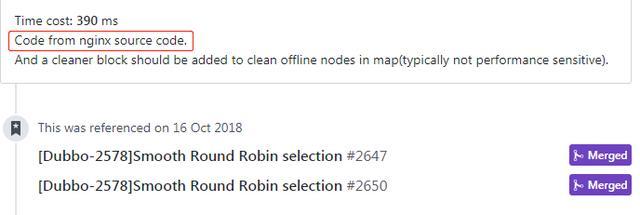
看代码之前,先介绍其计算过程。
假设每个服务器有两个权重,一个是配置的weight,不会变化,一个是currentWeight会动态调整,初始值为0。当有新的请求进来时,遍历服务器列表,让它的currentWeight加上自身权重。遍历完成后,找到最大的currentWeight,并将其减去权重总和,然后返回相应的服务器即可。
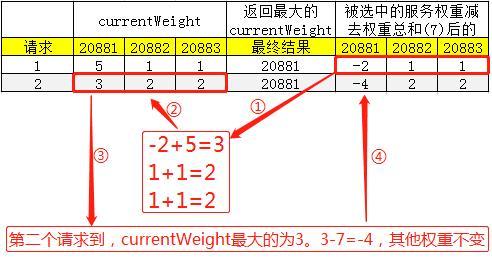
如果你还是不知道上面的表格是如何算出来的,我再给你详细的分析一下第1、2个请求的计算过程:
第一个请求计算过程如下:

第二个请求计算过程如下:
后面的请求你就可以自己分析了。
从表格的最终结果一栏也可以直观的看出,七次请求对应的服务器端口为:

可以看到,权重之比同样是5:1:1,但是最终的请求分发的就比较的"平滑"。对比一下:

对于平滑加权算法,我想多说一句。我觉得这个算法非常的神奇,我是彻底的明白了它每一步的计算过程,知道它最终会形成一个闭环,但是我想了很久,我还是不知道背后的数学原理是什么, 不明白为什么会形成一个闭环 ,非常的神奇。
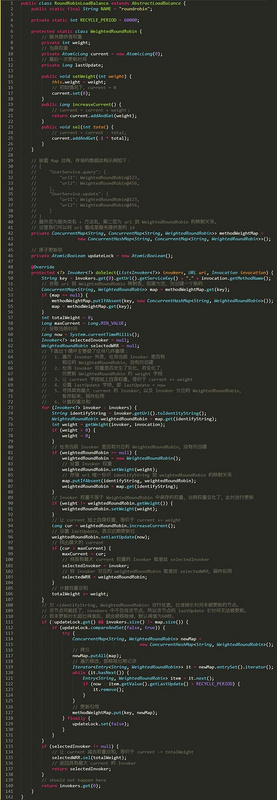
但是我们只要能够理解我前面所表达的平滑加权轮询算法的计算过程,知道其最终会形成闭环,就能理解下面的代码。配合代码中的注释食用,效果更佳。以下代码以及注释来源官网:
http://dubbo.apache.org/zh-cn... _code_guide/loadbalance.html
最后说一句
Dubbo官方提供了四种负载均衡算法,分别是:
LeastActiveLoadBalance 最小活跃数算法 RandomLoadBalance 加权随机算法 RoundRobinLoadBalance 加权轮询算法
对于官方提供的加权随机算法,原理十分简单。所以在《一文讲透Dubbo负载均衡之最小活跃数算法》中也提到过。
本文是Dubbo负载均衡算法的最后一篇。前两篇为:
《一文讲透Dubbo负载均衡之最小活跃数算法》
《Dubbo一致性哈希负载均衡的源码和Bug,了解一下?》
至此,Dubbo的负载均衡算法都已分享完成。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,还请你留言给我指出来,我对其加以修改。
如果你觉得文章还不错,你的转发、分享、赞赏、点赞、留言就是对我最大的鼓励。
感谢您的阅读 , 十分欢迎并感谢您的关注。
以上。
原创不易,求个关注。

正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

