Dubbo源码解析之SPI(一):拆解扩展类的加载过程

(图片来源于网络)
Dubbo是一款开源的、高性能且轻量级的Java RPC框架,它提供了三大核心能力: 面向接口的远程方法调用、智能容错和负载均衡,以及服务自动注册和发现。
Dubbo最早是阿里公司内部的RPC框架,于 2011 年开源,之后迅速成为国内该类开源项目的佼佼者,2018年2月,通过投票正式成为 Apache基金会孵化项目。 目前宜信公司内部也有不少项目在使用Dubbo。
本系列文章通过拆解Dubbo源码,帮助大家了解Dubbo,做到知其然,并且知其所以然。
01
JDK SPI
1.1 什么是SPI?
SPI(Service Provider Interface),即服务提供方接口,是JDK内置的一种服务提供机制。 在写程序的时候,一般都推荐面向接口编程,这样做的好处是: 降低了程序的耦合性,有利于程序的扩展。
SPI也秉承这种理念,提供了统一的服务接口,服务提供商可以各自提供自己的具体实现。 大家都熟知的JDBC中用的就是基于这种机制来发现驱动提供商,不管是Oracle也好,MySQL也罢,在编写代码时都一样,只不过引用的jar包不同而已。 后来这种理念也被运用于各种架构之中,比如Dubbo、Eleasticsearch。
1.2 JDK SPI的小栗子
SPI 的实现方式是将接口实现类的全限定名配置在文件中,由服务加载器读取配置文件,加载实现类。
了解了概念后,来看一个具体的例子。
1)定义一个接口
public interface Operation {
int operate(int num1, int num2);
}
2)写两个简单的实现
public class DivisionOperation implements Operation {
public int operate(int num1, int num2) {
System.out.println("run division operation");
return num1/num2;
}
}
3)添加一个配置文件
在ClassPath路径下添加一个配置文件,文件名字是接口的全限定类名,内容是实现类的全限定类名,多个实现类用换行符分隔。
-
目录结构
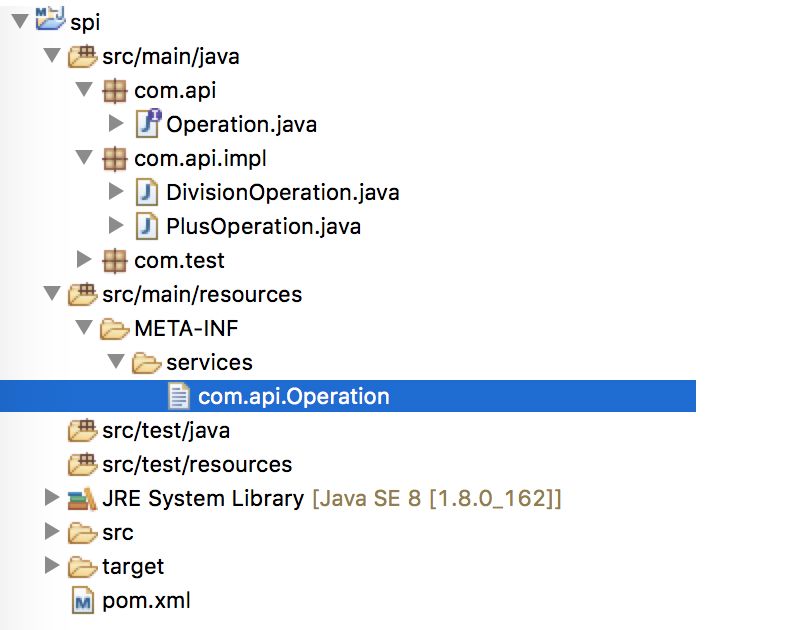
-
文件内容
com.api.impl.DivisionOperation com.api.impl.PlusOperation
4)测试程序
public class JavaSpiTest {
@Test
public void testOperation() throws Exception {
ServiceLoader<Operation> operations = ServiceLoader.load(Operation.class);
operations.forEach(item->System.out.println("result: " + item.operate(2, 2)));
}
}
5)测试结果
run division operation result:1 run plus operation result:4
1.3 JDK SPI的源码分析
例子很简单,实现的话,可以大胆猜测一下,看名字“ServiceLoader”应该就是用类加载器根据接口的类型加上配置文件里的具体实现名字将实现加载了进来。
接下来通过分析源码进一步了解其实现原理。
1.3.1 ServiceLoader类
PREFIX定义了加载路径,reload方法初始化了LazyIterator , LazyIterator是加载的核心,真正实现了加载。加载的模式从名字上就可以看出,是懒加载的模式,只有当真正调用迭代时才会加载。
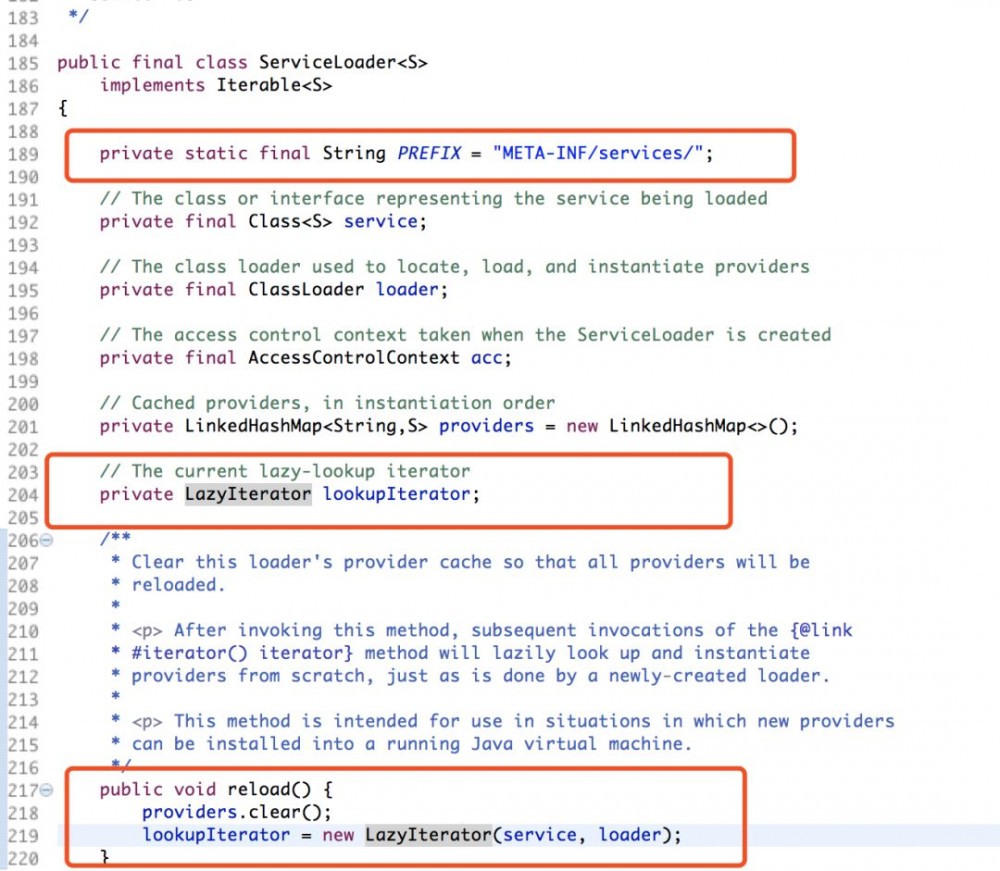
1.3.2 hasNextService方法
LazyIterator中的hasNextService方法负责加载配置文件和解析具体的实现类名。

1.3.3 nextService方法
LazyIterator中的nextService方法负责用反射加载实现类。
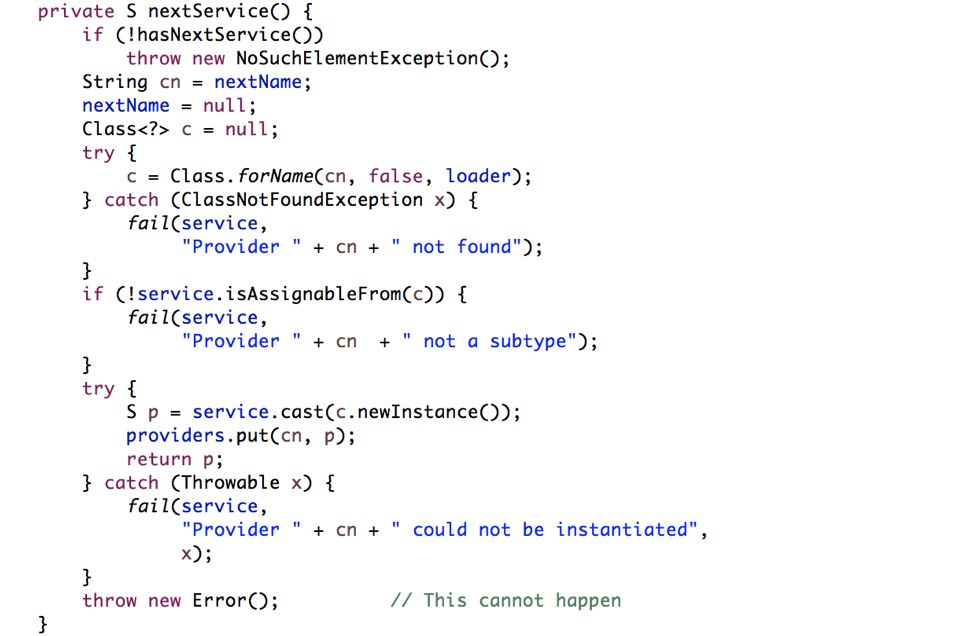
看完了源码,感觉这个代码是有优化空间的,实例化所有实现其实没啥必要,一来比较耗时,二来浪费资源。 Dubbo就没有使用Java原生的SPI机制,而是对其进行了增强,使其能够更好地满足需求。
02
Dubbo SPI
2.1 Dubbo SPI的小栗子
老习惯,在拆解源码之前,先来个栗子。 此处示例是在前文例子的基础上稍做了些修改。
1)定义一个接口
修改接口,加上了Dubbo的@SPI注解。
@SPI
public interface Operation {
int operate(int num1, int num2);
}
2)写两个简单的实现
沿用之前的两个实现类。
3)添加一个配置文件
新增配置文件放在dubbo目录下。
-
目录结构
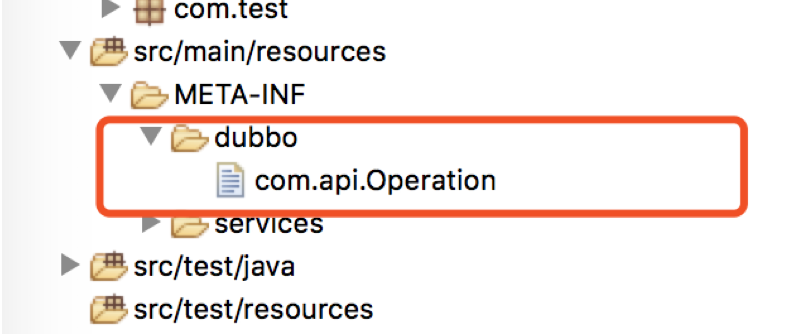
-
文件内容
division=com.api.impl.DivisionOperation plus=com.api.impl.PlusOperation
4)测试程序
public class DubboSpiTest {
@Test
public void testOperation() throws Exception {
ExtensionLoader<Operation> loader = ExtensionLoader.getExtensionLoader(Operation.class);
Operation division = loader.getExtension("division");
System.out.println("result: " + division.operate(1, 2));
}
}
5)测试结果
run division operation result:0
2.2 Dubbo SPI源码
上面的测试例子也很简单,和JDK原生的SPI对比来看,Dubbo的SPI可以根据配置的kv值来获取。 在没有拆解源码之前,考虑一下如何实现。
我可能会用双层Map来实现缓存: 第一层的key为接口的class对象,value为一个map; 第二层的key为扩展名(配置文件中的key),value为实现类的class。 实现懒加载的方式,当运行方法的时候创建空map。 在真正获取时先从缓存中查找具体实现类的class对象,找得到就直接返回、找不到就根据配置文件加载并缓存。
Dubbo又是如何实现的呢?
2.2.1 getExtensionLoader方法
首先来拆解getExtensionLoader方法。

这是一个静态的工厂方法,要求传入的类型必须为接口并且有SPI的注解,用map做了个缓存,key为接口的class对象,而value是 ExtensionLoader对象。
2.2.2 getExtension方法
再来拆解ExtensionLoader的getExtension方法。
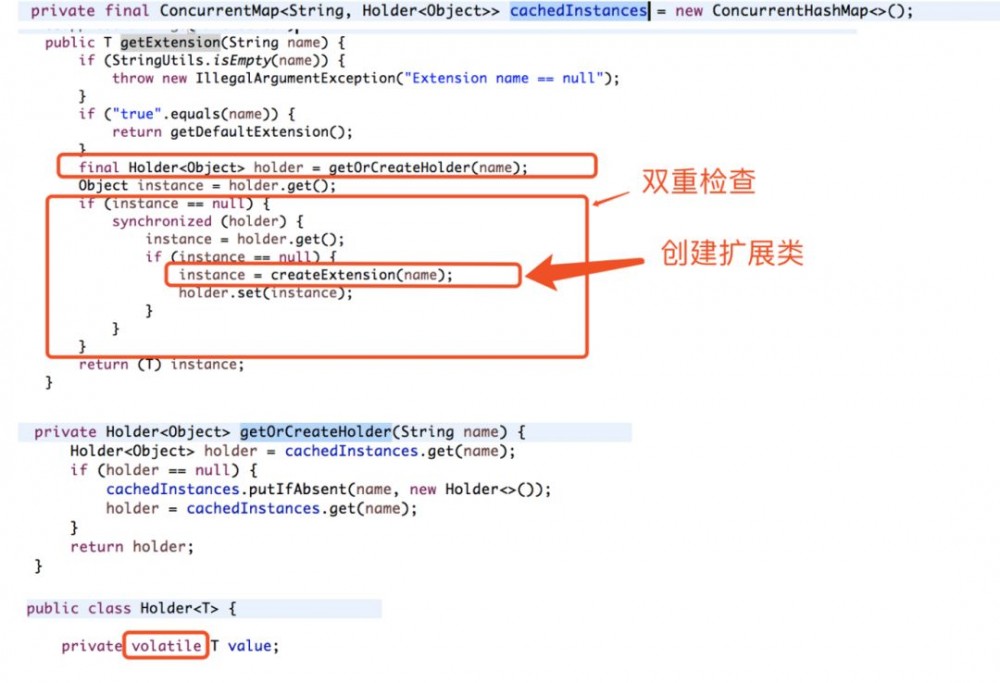
这段代码也不复杂,如果传入的参数为'true',则返回默认的扩展类实例; 否则,从缓存中获取实例,如果有就从缓存中获取,没有的话就新建。 用map做缓存,缓存了holder对象,而holder对象中存放扩展类。 用volatile关键字和双重检查来应对多线程创建问题,这也是单例模式的常用写法。
2.2.3 createExtension方法
重点分析createExtension方法。
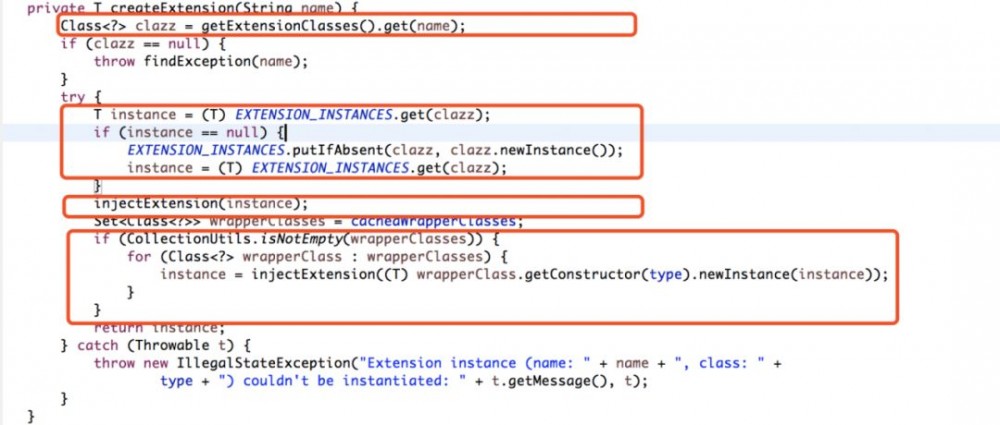
这段代码由几部分组成:
-
根据传入的扩展名获取对应的class。
-
根据class去缓存中获取实例,如果没有的话,通过反射创建对象并放入缓存。
-
依赖注入,完成对象实例的初始化。
-
创建wrapper对象。 也就是说,此处返回的对象不一定是具体的实现类,可能是包装的对象。
第二个没啥好说的,我们重点来分析一下1、3、4三个部分。
1)getExtensionClasses方法
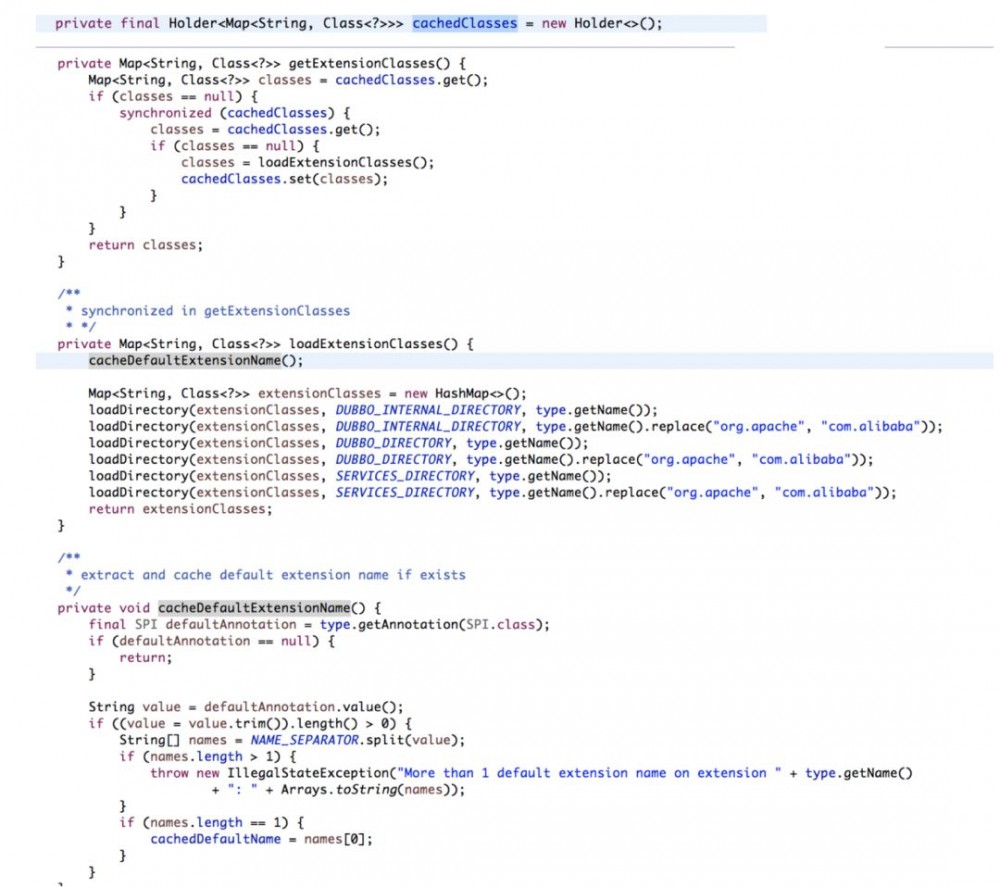
老套路,从缓存获取,没有的话创建并加入缓存。 这里缓存的是一个扩展名和class的关系。 这个扩展名就是在配置文件中的key。 创建之前,先缓存了一下接口的限定名。 加载配置文件的路径是以下这几个。

2)loadDirectory方法
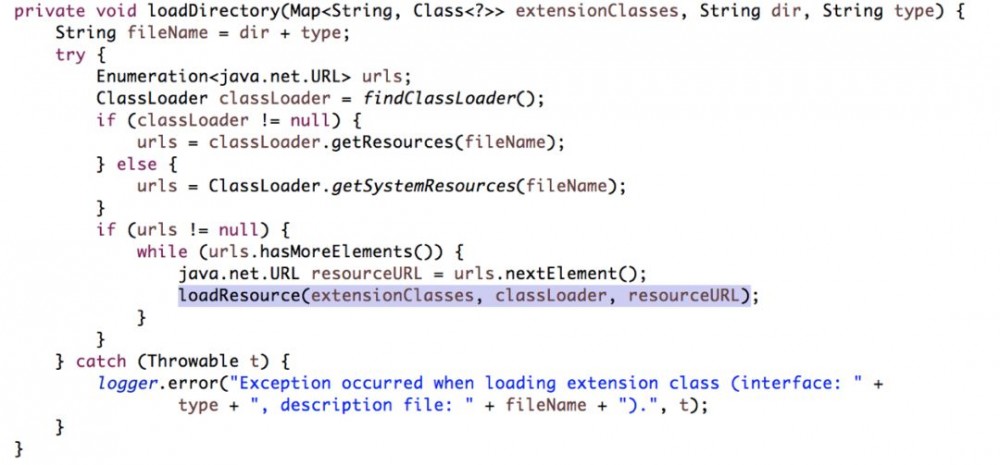
获取配置文件路径,获取classLoader,并使用loadResource方法做进一步处理。
3)loadResource方法
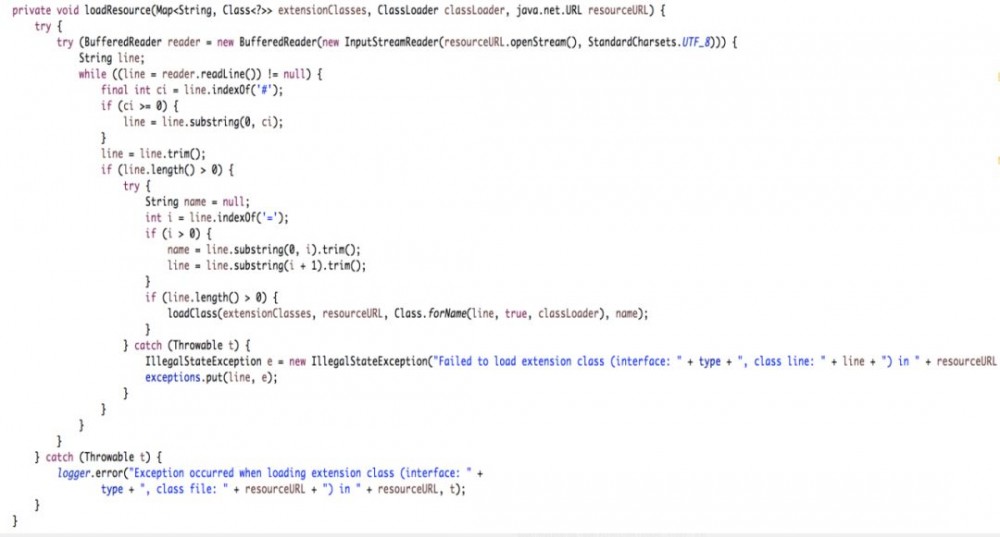
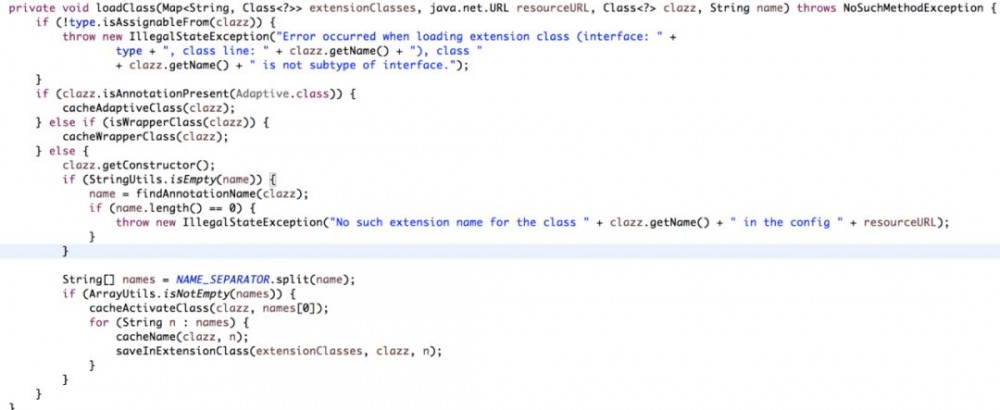
loadResource加载了配置文件,并解析了配置文件中的内容。 loadClass 方法操作了不同的缓存。
首先判断是否有Adaptive注解,有的话缓存到cacheAdaptiveClass(缓存结构为class); 然后判断是否wrapperclasses,是的话缓存到cacheWrapperClass中(缓存结构为Set); 如果以上都不是,这个类就是个普通的类,存储class和名称的映射关系到cacheNames里(缓存结构为Map)。
基本上getExtensionClasses方法就分析完了,可以看出来,其实并不是很复杂。
2.2.4 IOC
1)injectExtension方法
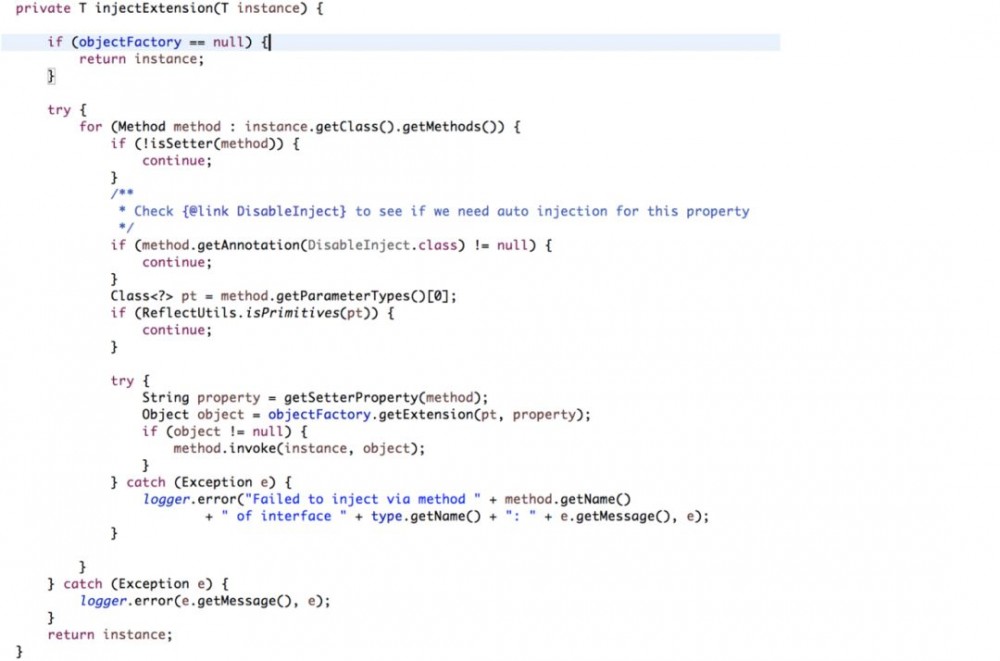
这个方法实现了依赖注入,即IOC。 首先通过反射获取到实例的方法; 然后遍历,获取setter方法; 接着从objectFactory中获取依赖对象; 最后通过反射调用setter方法注入依赖。
objectFactory的变量类型为AdaptiveExtensionFactory。
2)AdaptiveExtensionFactory
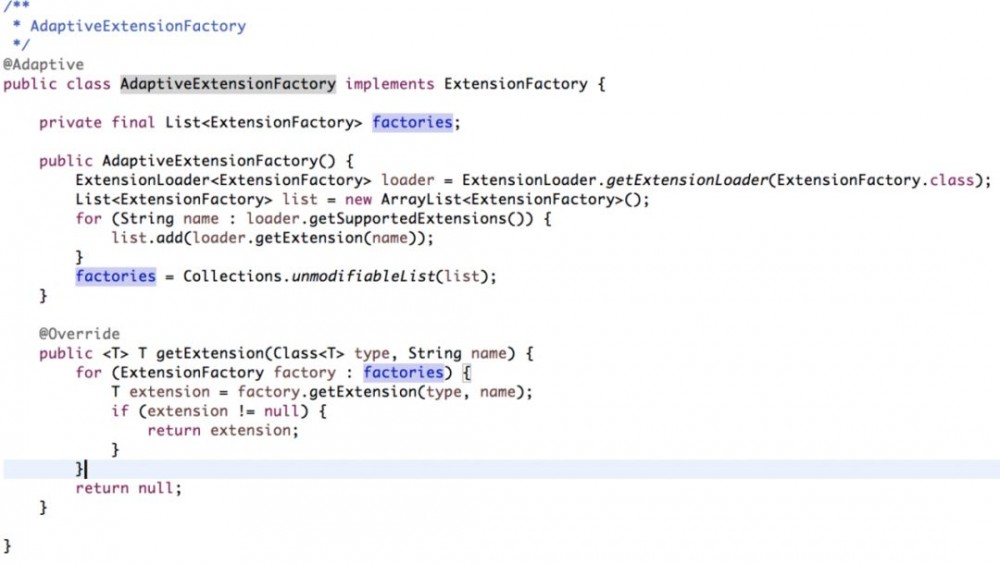
这个类里面有个ExtensionFactory的列表,用来存储其他类型的 ExtensionFactory。 Dubbo提供了两种ExtensionFactory,一种是SpiExtensionFactory, 用于创建自适应的扩展; 另一种是SpringExtesionFactory,用于从Spring的IOC容器中获取扩展。 配置文件一个在dubbo-common模块,一个在dubbo-config模块。
-
配置文件


SpiExtensionFactory中的Spi方式前面已经解析过了。

SpringExtesionFactory是从ApplicationContext中获取对应的实例。 先根据名称查找,找不到的话,再根据类型查找。
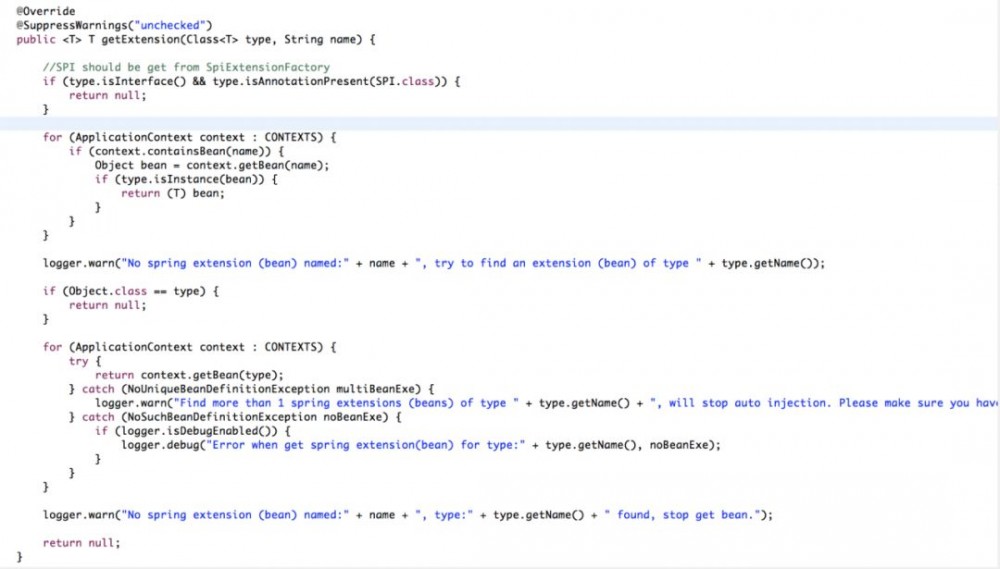
依赖注入的部分也拆解完毕,看看这次拆解的最后一部分代码。
2.2.5 AOP
创建wrapper对象的部分,wrapper对象是从哪里来的呢? 还记得之前拆解的第一步么,loadClass方法中有几个缓存,其中wrapperclasses就是缓存这些wrapper的class。
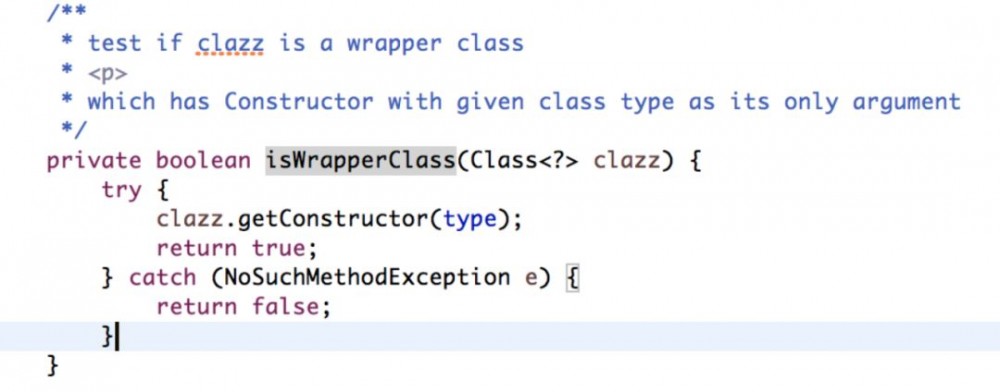
从代码中可以看出,只要构造方法里有且只有唯一参数,同时此参数为当前传入的接口类型,即为wrapper class。

此处循环创建wrapper实例,首先将instance做为构造函数的参数,通过反射来创建wrapper对象,然后再向wrapper中注入依赖。
看到这里,可能会有人有疑问: 为什么要创建一个wrapper对象? 其实很简单,系统要在真正调用的前后干点别的事呗。 这个就有点类似于spring的aop了。
03
总结
本文简单介绍了JDK的SPI和Dubbo的SPI用法,分析了JDK的SPI源码和Dubbo的SPI源码。 在拆解的过程中可以看出,Dubbo的源码还是很值得一读的。在实现方面考虑得很周全,不仅有对多线程的处理、多层缓存,也有IOC、AOP的过程。不过,Dubbo的SPI就这么简单么?当然不是,这篇只拆解了扩展类的加载过程,Dubbo的SPI中还有个很复杂的扩展点-自适应机制。欲知后事如何,请听下回分解~~
本文作者:宜信支付结算部支付研发团队Java研发高级工程师郑祥斌
- the end -
【野指针】专注分享技术人的点点滴滴,包括但不限于技术点解析、技术心得、实践案例、技术人成长等。P.S. 本公众号会...不定时地...更新~全看技术小哥哥/小姐姐们的写作时(xin)间(qing)  虽然数量不多,但是我们的内容丰富、好玩、有用,欢迎关注、在看、转发嗷~
虽然数量不多,但是我们的内容丰富、好玩、有用,欢迎关注、在看、转发嗷~

关注“野指针”
不拘泥于工作的一群人,技术不在乎野不野。
正文到此结束
- 本文标签: App volatile ACE MQ 测试 线程 开源项目 智能 参数 http AOP 缓存 ssl Oracle IDE CTO 滴滴 src IO JDBC apache UI 空间 value 自适应 图片 类加载器 java 负载均衡 基金 需求 key provider cache 构造方法 spring https 配置 代码 实例 dubbo ioc 工程师 目录 db map 遍历 开源 Service 专注 mysql 源码 sql 多线程 解析 总结 文章 id classpath cat API
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

