Java的内存模型
首先给出定义, Java 内存模型( Java Memory Model , JMM )是一种符合内存模型规范的,屏蔽了各种硬件和操作系统的访问差异的,保证了 Java 程序在各种平台下对内存的访问都能保证效果一致的机制及规范。
在弄懂 JMM 之前,我们要先了解下 CPU 和内存是如何交互的。
CPU和高速缓存以及内存(主存)的交互
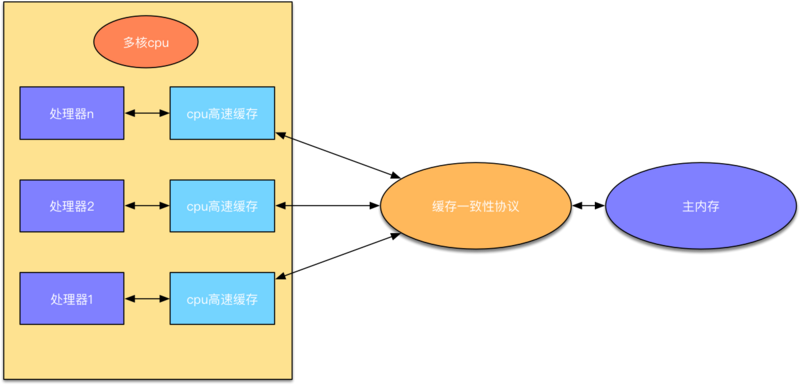
从图中可以看出在多 CPU 的系统中,每个 CPU 都有都有各自的高速缓存,一般分为 L1 、 L2 、 L3 缓存,因为这些缓存的存在,提供了数据的访问性能,也减轻了数据总线上数据传输的压力,而主内存却只有一个 。
CPU 要读取一个数据时,首先从一级缓存中查找,如果没有找到再从二级缓存中查找,如果还是没有就从三级缓存或内存中查找,每个 CPU 有且只有一套自己的缓存。
但是问题也就来了,如果两个 CPU 同时去操作同一个内存地址,会发生什么?也就是说,如何保证多个处理器运算涉及到同一个内存区域时,多线程场景下的缓存一致性问题?运行时如何保证数据一致性?那就是 内存屏障 ( Memory Barrier )。
内存屏障
CPU 中的高速缓存提高了数据访问性能,避免每次都向内存索取,但是不能实时的和内存发生信息交换。在不同 CPU 执行的不同线程对同一个变量的缓存值可能是不同的,由此就出现了内存屏障,硬件层的内存屏障分为两种: Load Barrier 和 Store Barrier 即读屏障和写屏障。
内存屏障的作用主要有两点:
- 阻止屏障两侧指令重排序
- 强制把写缓冲区/高速缓存中的脏数据等写回主内存,让缓存中相应的数据失效。
之所以扯了那么多计算机内存模型,是因为 Java 内存模型的设定符合了计算机的规范。
实际上, JMM 是 JVM 的一种规范,定义了 JVM 的内存模型。
它屏蔽了各种硬件和操作系统的访问差异,不像 C 那样直接访问硬件内存,相对安全很多。
它的主要目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。可以保证并发编程场景中的原子性、可见性和有序性。
Java内存模型的应用
Java 中的几个关键字: volatile 、 final 、 synchronized ,可以帮助程序员把代码中的并发需求描述给编译器。 Java 内存模型中定义了它们的行为,以确保正确同步的 Java 代码在所有的处理器架构上都能正确执行。
volatile
在 Java 中, volatile 关键字可以解决上面的问题, Java 屏蔽掉这些差异,通过 JVM 生成内存屏障的指令。
当我们声明某个变量为 volatile 修饰时,这个变量就有了线程可见性, volatile 会在读写操作前后添加内存屏障。 volatile 字段的每次读行为都能看到其它线程最后一次对该字段的写行为,通过它就可以避免拿到缓存中陈旧数据。它们必须保证在被写入之后,会被刷新到主内存中,这样就可以立即对其它线程可以见。
final
如果一个类包含 final 字段,且在构造函数中初始化,那么正确的构造一个对象后, final 字段被设置后对于其它线程是可见的。
注意这里所说的正确构造对象,意思是在对象的构造过程中,不允许对该对象进行引用,不然的话,可能存在其它线程在对象还没构造完成时就对该对象进行访问,造成其他的问题。
synchronized
对于一个被 synchronized 修饰的 monitor 对象,只能够被一个线程持有,意味着一旦有线程进入了同步代码块,那么其它线程就不能进入,直到第一个进入的线程退出代码块。
在一个线程退出同步块时,线程释放 monitor 对象,它的作用是把 CPU 缓存数据(本地缓存数据)刷新到主内存中,从而实现该线程的行为可以被其它线程看到。在其它线程进入到该代码块时,需要获得 monitor 对象,它在作用是使 CPU 缓存失效,从而使变量从主内存中重新加载,然后就可以看到之前线程对该变量的修改。
但从缓存的角度看,这个问题只会影响多处理器的机器,对于单核来说没什么问题,但是它还有一个语义是禁止指令的重排序,对于编译器来说,同步块中的代码不会移动到获取和释放 monitor 的外面。
总结
JMM 是 JVM 的一种规范,定义了 JVM 的内存模型。它的主要目的是解决由于多线程通过共享内存进行通信时,存在的本地内存数据不一致、编译器会对代码指令重排序、处理器会对代码乱序执行等带来的问题。可以保证并发编程场景中的原子性、可见性和有序性。
在 Java 中, volatile 、 final 、 synchronized 这三个关键字是对与内存模型的具体实现。
本文由博客一文多发平台 OpenWrite 发布!
更多内容请点击我的博客 沐晨
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

