Netty高性能ByteBuf源码解析
本文地址: https://juejin.im/post/5db8ea...
Netty 高性能的原因除了前面提到的 NIO 的 Reactor 线程模型, 零拷贝也是其高性能的一个重要原因.
零拷贝
- 省去了数据从用户进程到内核的拷贝(jvm 堆内的数据 os 是不能直接使用的, 要让os可以使用的话, 需要将堆内的数据拷贝一份到堆外)
- CompositeByteBuf 复合多个 ByteBuf, netty使用的是逻辑上的关联, 对外提供访问的统一接口, 而不是重新申请内存再将数据写入新的 ByteBuf
Netty 的 ByteBuf 类型
- Pooled(池化)、Unpooled(非池化)
- Direct(直接缓冲区/堆外)、Heap(jvm堆内)
- unsafe(unsafe 调用的本地方法)、safe(一般也不会这么说, 这是相对于 unsafe, 指的jvm 堆内的操作)
Netty 默认都会优先使用 unsafe 的实现
池化/非池化(Pooled/Unpooled)
Netty 先申请一块连续的空间作为 ByteBuf 池, 需要用到的时候直接去池里面取, 用完之后返还给 ByteBuf 池, 而不需要每次要用 ByteBuf 的时候都去申请. 堆外对象的创建比堆内的耗时.
总结: 池化的作用就是加快程序获取到操作的对象 ~~~~
堆外/堆内(direct/heap)
堆内指的在 JVM 中的数据,申请、操作都是在jvm里.
堆外的直接缓冲区指的是申请内存的时候用的 native 方法申请的 非jvm堆 的内存, 这一部分内存 OS 是可以直接使用的 , 不像堆内的内存OS要使用的话还需要复制一次到直接缓冲区.申请的是堆外的内存, 这时候 java 中的对象(DirectByteBuf)只是一些reader/writer Index(memory(内存地址), offset(偏移量) 等)的处理, 写数据/读数据都是通过 native 对堆外的数据在进行操作.
总结:用堆外内存是为了防止对象的拷贝, 提升效率 ~~~~
unsafe
unsafe 这个东西是 sun.misc 中提供的一个类, 用这个类可以直接通过 native 方法操作内存, 当然也会有效率提升, 上面说的申请和操作堆外内存就是用这个叫做 unsafe 的东西来完成的. 但是用这个 unsafe 必须对内存操作非常熟悉, 不然非常容易出错, 所以官方为什么把它叫做 unsafe 也是有道理的.
总结: 直接操作内存, 效率提升, 但是使用容易出错
Pool用到的一些类和概念
PoolArena、PoolChunk、PoolThreadLocalCache、PoolSubpage、Recycler
- PoolArena: Arena舞台的意思, 顾名思义是池中的操作需要这个类提供环境
- PoolChunk: Netty 中申请的内存块, 存储 chunkSize,自身 offset , 剩余空间大小 freeSize 等信息, 按照官方说明: 为了在块(chunk)中找到至少能满足请求的大小, 构造了一颗完全二叉树, 像堆(这是一个最大堆, chunk 中的节点将组成一颗完全二叉树)
- PoolThreadLocalCache: 线程本地变量,存储 PoolArena -> chunk ( -> page-> subPage)
- PoolSubPage: 位于最底层的 chunk 上的 Page
- Recycle: 顾名思义回收站, 这是一个抽象类, 主要作用从 ThreadLocal 中获取到回收站里的 ByteBuf
简单说明: PoolThreadLocalCache 和 Recycle 都使用了 ThreadLocal 变量, 减少多线程的争抢,提升操作效率.
几个重要的属性值
-
maxOrder 默认11 : 完全二叉树的深度(根节点是第0层, 所以客观来说的一共有 maxOrder+1 层) -
pageSize 默认8192 (8k) : 上面完全二叉树的最底层的叶子结点 page 的默认大小 -
pageShifts 默认13: 这个是 pageSize 的对数, 2^pageShifts = pageSize , pageSize 默认为 8192, 所以这个默认值为 13 -
chunkSize 默认 16m(pageSize * maxOrder): 这个是每个 chunk 的大小, 就是下面 chunk图 的每一层的大小 -
一个page里面的最小划分单位为16byte, 16这个数字很重要, 后续有几个关键计算的地方使用到
ByteBuf 的大小类型:
- size < 512 , tiny
- 512 < size < 8192 , small
- 8192 < size < 16m , normal
- 16m < size , huge
chunk 的结构 ~~~~
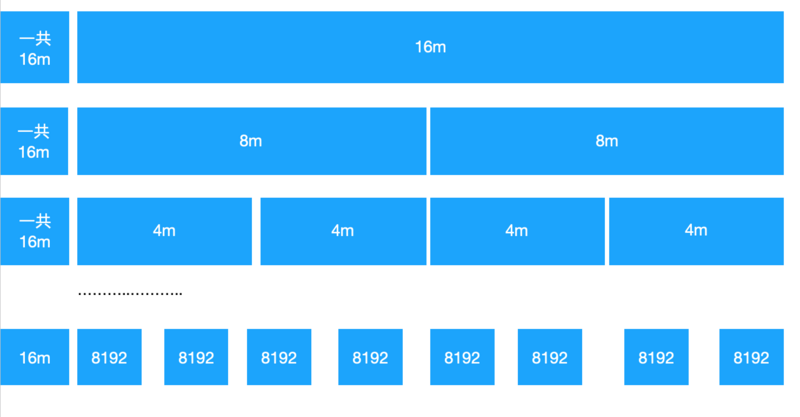
每一层的总和都是16m, 一直细分到最底层,每个 page 为 8192(8k),所以最底层有2k个节点,这里当然没有全部画出来, subPage 都在page上进行操作.
堆外/堆内ByteBuffer内存申请
一个简单测试
做一个简单测试, 测试堆外内存的申请和堆内内存申请的耗时:
static void nioAllocTest(){
int num = 10;
int cnt = 100;
int size = 256;
ByteBuffer buf;
long start1,end1,start2,end2;
long sum1,sum2;
for(int i = 0;i<num;i++){
sum1=sum2=0;
int j;
for(j = 0;j<cnt;j++) {
start1 = System.nanoTime();
buf = ByteBuffer.allocateDirect(size);
end1 = System.nanoTime();
sum1+=(end1-start1);
// System.out.println("direct 申请时间: "+(end1-start1));
start2 = System.nanoTime();
buf = ByteBuffer.allocate(size);
end2 = System.nanoTime();
// System.out.println("heap 申请时间: "+(end2-start2));
// System.out.println("-----");
sum2+=(end2-start2);
}
System.out.println(String.format("第 %s 轮申请 %s 次 %s 字节平均耗时 [direct: %s , heap: %s].",i,j,size,sum1/cnt, sum2/cnt));
}
}
输出结果为:
第 0 轮申请 100 次 256 字节平均耗时 [direct: 4864 , heap: 1616].
第 1 轮申请 100 次 256 字节平均耗时 [direct: 5763 , heap: 1641].
第 2 轮申请 100 次 256 字节平均耗时 [direct: 4771 , heap: 1672].
第 3 轮申请 100 次 256 字节平均耗时 [direct: 4961 , heap: 883].
第 4 轮申请 100 次 256 字节平均耗时 [direct: 3556 , heap: 870].
第 5 轮申请 100 次 256 字节平均耗时 [direct: 5159 , heap: 726].
第 6 轮申请 100 次 256 字节平均耗时 [direct: 3739 , heap: 843].
第 7 轮申请 100 次 256 字节平均耗时 [direct: 3910 , heap: 221].
第 8 轮申请 100 次 256 字节平均耗时 [direct: 2191 , heap: 590].
第 9 轮申请 100 次 256 字节平均耗时 [direct: 1624 , heap: 615].
可以看到 direct 堆外内存的申请耗时明显多于 jvm堆的申请耗时, 这里的耗时是几倍(测试次数的不多可能不太准确, 感兴趣的同学可以测试更大/更小的size, 可能会发现一些“有趣”的事).
池化/非池化
一个简单测试
做一个简单测试,测试池化的效果
static void nettyPooledTest(){
try {
int num = 10;
int cnt = 100;
int size = 8192;
ByteBuf direct1, direct2, heap1, heap2;
long start1, end1, start2, end2, start3, end3, start4, end4;
long sum1, sum2, sum3, sum4;
for (int i = 0; i<num; i++) {
sum1 = sum2 = sum3 = sum4 = 0;
int j;
for (j = 0; j<cnt; j++) {
start1 = System.nanoTime();
direct1 = PooledByteBufAllocator.DEFAULT.directBuffer(size);
end1 = System.nanoTime();
sum1 += (end1-start1);
start2 = System.nanoTime();
direct2 = UnpooledByteBufAllocator.DEFAULT.directBuffer(size);
end2 = System.nanoTime();
sum2 += (end2-start2);
start3 = System.nanoTime();
heap1 = PooledByteBufAllocator.DEFAULT.heapBuffer(size);
end3 = System.nanoTime();
sum3 += (end3-start3);
start4 = System.nanoTime();
heap2 = UnpooledByteBufAllocator.DEFAULT.heapBuffer(size);
end4 = System.nanoTime();
sum4 += (end4-start4);
direct1.release();
direct2.release();
heap1.release();
heap2.release();
}
System.out.println(String.format("Netty 第 %s 轮申请 %s 次 [%s] 字节平均耗时 [direct.pooled: [%s] , direct.unpooled: [%s] , heap.pooled: [%s] , heap.unpooled: [%s]].", i, j, size, sum1/cnt, sum2/cnt, sum3/cnt, sum4/cnt));
}
}catch(Exception e){
e.printStackTrace();
}finally {
}
}
最终输出的结果:
Netty 第 0 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [1784931] , direct.unpooled: [105310] , heap.pooled: [202306] , heap.unpooled: [23317]].
Netty 第 1 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [12849] , direct.unpooled: [15457] , heap.pooled: [12671] , heap.unpooled: [12693]].
Netty 第 2 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [13589] , direct.unpooled: [14459] , heap.pooled: [18783] , heap.unpooled: [13803]].
Netty 第 3 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [10185] , direct.unpooled: [11644] , heap.pooled: [9809] , heap.unpooled: [12770]].
Netty 第 4 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [15980] , direct.unpooled: [53980] , heap.pooled: [5641] , heap.unpooled: [12467]].
Netty 第 5 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [4903] , direct.unpooled: [34215] , heap.pooled: [6659] , heap.unpooled: [12311]].
Netty 第 6 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [2445] , direct.unpooled: [7197] , heap.pooled: [2849] , heap.unpooled: [11010]].
Netty 第 7 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [2578] , direct.unpooled: [4750] , heap.pooled: [3904] , heap.unpooled: [255689]].
Netty 第 8 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [1855] , direct.unpooled: [3492] , heap.pooled: [37822] , heap.unpooled: [3983]].
Netty 第 9 轮申请 100 次 [8192] 字节平均耗时 [direct.pooled: [1932] , direct.unpooled: [2961] , heap.pooled: [1825] , heap.unpooled: [6098]].
这里看 DirectByteBuffer, 频繁的申请堆外内存的话, 会降低服务端的性能, 这时候池化的作用就显现出来了.池化只需开始的时候申请一块足够大的内存, 后续获取对象只是从池里取出, 用完返还Pool, 并非每次都单独去申请, 省去了后续使用从堆外申请空间的耗时.
ByteBuf 具体的实现
这里就讲个人感觉最重要的一个, 也是 netty 默认使用的类型: PooledUnsafeDirectByteBuf , 我们也从它的申请 PooledByteBufAllocator.DEFAULT.directBuffer() 开始讲起.
下面从PooledByteBufAllocator.DEFAULT.directBuffer()进入
// 到第一个要分析的方法
protected ByteBuf newDirectBuffer(int initialCapacity, int maxCapacity) {
// 从 threadlLocal 获取一个线程本地缓存池
PoolThreadCache cache = (PoolThreadCache)this.threadCache.get();
// 这个缓存池包含 heap 和 direct 两种, 获取直接缓存池
PoolArena<ByteBuffer> directArena = cache.directArena;
Object buf;
if (directArena != null) {
buf = directArena.allocate(cache, initialCapacity, maxCapacity); // 这里往下 -- 1
} else {
// 如果没有堆外缓存池, 直接申请堆外的 ByteBuf, 优先使用 unsafe
buf = PlatformDependent.hasUnsafe() ? UnsafeByteBufUtil.newUnsafeDirectByteBuf(this, initialCapacity, maxCapacity) : new UnpooledDirectByteBuf(this, initialCapacity, maxCapacity);
}
return toLeakAwareBuffer((ByteBuf)buf);
}
// 1 directArena.allocate(cache, initialCapacity, maxCapacity);
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// newByteBuf(maxCapacity); 有两种实现, directArena 和 heapArena
// Pool 的为在 recycle 中重用一个 ByteBuf
PooledByteBuf<T> buf = newByteBuf(maxCapacity); // -- 2
allocate(cache, buf, reqCapacity); // -- 7
return buf;
}
// 2 newByteBuf(maxCapacity)
protected PooledByteBuf<ByteBuffer> newByteBuf(int maxCapacity) {
// 优先使用 PooledUnsafeDirect
if (HAS_UNSAFE) {
// PooledUnsafeDirect
return PooledUnsafeDirectByteBuf.newInstance(maxCapacity); // -- 3
} else {
// PooledDirect
return PooledDirectByteBuf.newInstance(maxCapacity);
}
}
// 3 PooledUnsafeDirectByteBuf.newInstance
static PooledUnsafeDirectByteBuf newInstance(int maxCapacity) {
// 从用于回收的 ThreadLocal 中获取一个 ByteBuf
PooledUnsafeDirectByteBuf buf = RECYCLER.get(); // -- 4
// 重置 ByteBuf 的下标等
buf.reuse(maxCapacity); // -- 6
return buf;
}
// 4 Recycler.get()
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject((Handle<T>) NOOP_HANDLE);
}
// 每个线程都有一个栈
Stack<T> stack = threadLocal.get();
// 弹出一个 handle
DefaultHandle<T> handle = stack.pop();
// 如果 stack 中没有 handle 则新建一个
if (handle == null) {
handle = stack.newHandle();
// newObject 由调用者实现, 不同的 ByteBuf 创建各自不同的 ByteBuf, 需要由创建者实现
// handle.value is ByteBuf, 从上面跟下来, 所以这里是 PooledUnsafeDirectByteBuf
handle.value = newObject(handle); // -- 5
}
// 返回一个 ByteBuf
return (T) handle.value;
}
// 5 Stack.pop() , 从栈中取出一个 handle
DefaultHandle<T> pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
size --;
// 取出栈最上面的 handle
DefaultHandle ret = elements[size];
elements[size] = null;
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 重置这个 handle 的信息
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}
// 6 重用 ByteBuf 之前需要重置一下之前的下标等
final void reuse(int maxCapacity) {
maxCapacity(maxCapacity);
setRefCnt(1);
setIndex0(0, 0);
discardMarks();
}
上面的1到6步, 从 PoolThreadLocalCache 中获取堆外的Arena, 并且根据出需要的大小从 RECYCLE 中获取一个线程本地的 ByteBuf 栈, 从栈中弹出一个 ByteBuf 并且重置 ByteBuf 的读写下标等.
讲到这里, 代码中第二步的就算跟踪完了, 接下来就是第七步开始了.
PooledByteBuf<T> allocate(PoolThreadCache cache, int reqCapacity, int maxCapacity) {
// newByteBuf(maxCapacity); 有两种实现, directArena 和 heapArena
// Pool 的为在 recycle 中重用一个 ByteBuf
PooledByteBuf<T> buf = newByteBuf(maxCapacity); // -- 2
allocate(cache, buf, reqCapacity); // -- 7
return buf;
}
上面讲到从 RECYCLE 的 线程本地栈 中获取到了一个 ByteBuf ,并且重置了读写下标等. 接下来的才算是重点.我们继续跟着代码走下去
// allocate(cache, buf, reqCapacity); -- 7
// 这一段都很重要,代码复制比较多, normal(>8192) 和 huge(>16m) 的暂时不做分析
private void allocate(PoolThreadCache cache, PooledByteBuf<T> buf, final int reqCapacity) {
// 计算应该申请的大小
final int normCapacity = normalizeCapacity(reqCapacity); // -- 8
// 申请的大小是否小于一页 (默认8192) 的大小
if (isTinyOrSmall(normCapacity)) { // capacity < pageSize
int tableIdx;
PoolSubpage<T>[] table;
// reqCapacity < 512
boolean tiny = isTiny(normCapacity);
if (tiny) { // < 512 is tiny
// 申请 tiny 容量的空间
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
// 计算属于哪个子页, tiny 以 16B 为单位
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
} else {
//8192 > reqCapacity >= 512 is small
// small 以 1024为单位
if (cache.allocateSmall(this, buf, reqCapacity, normCapacity)) {
return;
}
tableIdx = smallIdx(normCapacity);
table = smallSubpagePools;
}
// head 指向自己在 table 中的位置的头
final PoolSubpage<T> head = table[tableIdx];
/**
* Synchronize on the head. This is needed as {@link PoolChunk#allocateSubpage(int)} and
* {@link PoolChunk#free(long)} may modify the doubly linked list as well.
*/
synchronized (head) {
final PoolSubpage<T> s = head.next;
// 这里判断是否已经添加过 subPage
// 添加过的话, 直接在该 subPage 上面进行操作, 记录标识位等
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
// 在 subPage 的 bitmap 中的下标
long handle = s.allocate();
assert handle >= 0;
// 用 已经初始化过的 bytebuf 初始化 subPage 中的信息
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
// 计数
incTinySmallAllocation(tiny);
return;
}
}
// 第一次创建该类型大小的 ByteBuf, 需要创建一个subPage
synchronized (this) {
allocateNormal(buf, reqCapacity, normCapacity);
}
// 增加计数
incTinySmallAllocation(tiny);
return;
}
}
计算应该申请的 ByteBuf 的大小
// 8 以下代码是在 normalizeCapacity(reqCapacity) 中
// 如果 reqCapacity >= 512 ,则使用 跟hashMap 相同的扩容算法
// reqCapacity < 512(tiny类型) 则将 reqCapacity 变成 16 的倍数
if (!isTiny(reqCapacity)) {
// 是不是很熟悉, 有没有印象 HashMap 的扩容, 找一个不小于原数的2的指数次幂大小的数
int normalizedCapacity = reqCapacity;
normalizedCapacity --;
normalizedCapacity |= normalizedCapacity >>> 1;
normalizedCapacity |= normalizedCapacity >>> 2;
normalizedCapacity |= normalizedCapacity >>> 4;
normalizedCapacity |= normalizedCapacity >>> 8;
normalizedCapacity |= normalizedCapacity >>> 16;
normalizedCapacity ++;
//
if (normalizedCapacity < 0) {
normalizedCapacity >>>= 1;
}
assert directMemoryCacheAlignment == 0 || (normalizedCapacity & directMemoryCacheAlignmentMask) == 0;
return normalizedCapacity;
}
// reqCapacity < 512
// 已经是16的倍数,不做操作
if ((reqCapacity & 15) == 0) {
return reqCapacity;
}
// 不是16的倍数,转化为16的倍数
return (reqCapacity & ~15) + 16;
因为 small 和 tiny 还是有比较多相似的, 所以我们选 tiny 来讲
// 申请 tiny 容量的空间
if (cache.allocateTiny(this, buf, reqCapacity, normCapacity)) {
return;
}
// 计算属于哪个子页, tiny 以 16b 为单位
tableIdx = tinyIdx(normCapacity);
table = tinySubpagePools;
// head 指向自己在 table 中的位置的头
final PoolSubpage<T> head = table[tableIdx];
这里看到 tinySubpagePools, 看名字应该是存储 tinySubPage 的地方, 跟踪一下可以看到, tinySubPage 在构造方法里进行了初始化
tinySubpagePools = newSubpagePoolArray(numTinySubpagePools);
// 初始化 32 种类型的 subPage 的 head , 这里是记录 head
for (int i = 0; i < tinySubpagePools.length; i ++) {
tinySubpagePools[i] = newSubpagePoolHead(pageSize);
}
// 512 / 16 = 32
static final int numTinySubpagePools = 512 >>> 4;
numTinySubpagePools , 这是一个静态变量, 512是small和tiny的边界点, 512 >>> 4 = 32 ,为什么是无符号右移4位, 还记得上面说的 subPage 分配的基本单位吗, subPage 分配的基本单位就是 16byte, 所以这里是计算从16 到 512 以 16为单位 一共有多少种类型大小的 ByteBuf, tinySubpagePools->[16,32,48....512] , 上面的 tinyIdx(int normCapacity) 就是计算属于哪种类型的ByteBuf 并获取该类型 ByteBuf 在 tinySubpagePools 中的下标, 后续就可以根据下标获取到 pool 中对应下标的 head, 构造函数中初始化了所有的 head, 实际申请的话 ,不是用这个head来申请, 而是会另外 new 一个 subPage ,然后跟这个 head 形成双向链表. 按照上面的代码顺序, 接下来就到了 poolSubPage(init or allocate)
subPage一些字段的作用
final PoolChunk<T> chunk;
// 当前 subPage 所处的 Page 节点下标
private final int memoryMapIdx;
// 当前子页的 head 在 该 chunk 中的偏移值, 单位为 pageSize(default 8192)
private final int runOffset;
// default 8192
private final int pageSize;
// 默认 8 个 long 的字节长度, long是64位, 8*64 = 512, 512 * 16(subPage最低按照16字节分配) = 8192(one default page)
// 意思是将 一个page分为 512 个 16byte, 每一个 16byte 用一位(bit)来标记是否使用, 一个long有64bit, 所以一共需要 512 / 64 = 8个long类型来作为标记位
private final long[] bitmap;
// 这个是指一个 Page 中最多可以存储多少个 elemSize 大小 ByteBuf
// maxNumElems = pageSize / elemSize
private int maxNumElems;
// 已经容纳多少个 elemSize 大小的 ByteBuf
private int numAvail;
// 这个是记录真正能使用到的 bit 的length, 因为你不可能每个 page 中的 elemSize 都是16,肯定是有其他大小的, 在 PoolSubPage 的 init 方法中可以看到: bitmapLength = maxNumElems >>> 6;
private int bitmapLength;
// 所以初始化方法 init(), 只初始化 bitmapLength 个 long 类型
/**
* for (int i = 0; i < bitmapLength; i ++) {
* bitmap[i] = 0;
* }
*/
总结下来就是, 一个 8192 大小的 page, 先根据传入的大小计算最多能容纳多少个该大小的字节数组(堆外都是用字节数组) maxNumElems, 再根据最大能容纳的数量计算最多能用到多少个 long类型的数字作为标记位 bitmapLength , 最后初始化bitmap, 可见bitmap 是标记page中已经使用过的位置(以16byte为单位).
PoolSubPage 中还有一个很重要的方法: toHandle(); 这个方法的作用是将节点下标 memoryMapIdx 和 bitmapIdx 放到一起,用一个 long 类型来记录.通过这个handle值, 可以获取到对应节点(根据 memoryMapIdx)和该节点(page)下对应的偏移位置(就是bitmapIdx * 16)
private long toHandle(int bitmapIdx) {
// 后续会用 (int)handle 将这个 handle 值变回为 memoryMapIdx , 即所属节点下标
return 0x4000000000000000L | (long) bitmapIdx << 32 | memoryMapIdx;
}
介绍完了 subPage 的字段含义后, 继续跟踪上面的代码:
这一段代码是在根据申请的大小获取到对应下标的 head 节点后做的处理, s!=head 是判断是否有申请过相同大小subPage, 有的话直接 initBufWithSubpage在原有的 subPage 上进行操作, 而不用调用后面的 allocateNormal(buf, reqCapacity, normCapacity); 去allocate 一个新的 subPage
synchronized (head) {
final PoolSubpage<T> s = head.next;
// 这里判断是否已经添加过 subPage
// 添加过的话, 直接在该 subPage 上面进行操作, 记录标识位等
if (s != head) {
assert s.doNotDestroy && s.elemSize == normCapacity;
// 在 subPage 的 bitmap 中的下标 && 节点下标
long handle = s.allocate();
assert handle >= 0;
// 用已经初始化过的 bytebuf 更新 subPage 中的信息
s.chunk.initBufWithSubpage(buf, handle, reqCapacity);
// 计数
incTinySmallAllocation(tiny);
return;
}
}
initBufWithSubpage 方法跟踪下去可以看到:
buf.init(
this, handle,
runOffset(memoryMapIdx) + (bitmapIdx & 0x3FFFFFFF) * subpage.elemSize + offset,
reqCapacity, subpage.elemSize, arena.parent.threadCache());
runOffset(memoryMapIdx): memoryMapIdx 为节点下标, runOffset 表示该节点在chunk中的偏移量, 以 8192 为单位 节点偏移(bitmapIdx & 0x3FFFFFFF) * subpage.elemSize: 这个偏移量表示 bitmapIdx 下标在 subPage 中的偏移量
offset: 表示chunk自身的偏移.
这个3个offset 总和就是 bitmapIdx表示的下标在整个缓存池中的具体偏移值
上面就是申请一个池化的ByteBuf的具体流程
本文属作者个人理解, 有什么写错的地方望各位能指出.
最后
最后的最后,非常感谢你们能看到这里!!你们的阅读都是对作者的一次肯定!!! 觉得文章有帮助的看官顺手点个赞再走呗(终于暴露了我就是来骗赞的(◒。◒)),你们的每个赞对作者来说都非常重要(异常真实),都是对作者写作的一次肯定(double)!!!
这一篇的内容到这就结束了,期待下一篇 还能有幸遇见你!
See you later!
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

