使用机器学习分析10个Java微服务框架对吞吐量和响应时间的影响与对比 - amis
性能调优通常遵循以下步骤:
- 出现性能问题
- 有经验的人知道可能是什么原因,并提出具体的建议
- 确定基准性能,应用更改,然后再次测量性能
- 如果与基准相比性能有所改善,请保留更改,否则恢复更改
- 如果现在认为性能已经足够,那么您就完成了。如果不是,请返回有经验的人员,询问下一步要做的更改,然后重复上述步骤
这整个过程可能很昂贵。尤其是在复杂的环境中,有经验的人的建议通常是(很有希望)提供的猜测。这可能需要进行一些迭代才能使性能充分。如果您可以通过增加这种明智的判断来使这些猜测更加准确,则可能会更有效地进行调整。
在这篇博客文章中,我将尝试做到这一点。当然,这里主要免责声明适用,因为每个应用程序,环境,硬件等都是不同的。绩效的定义以及如何衡量绩效也是您可能会有不同意见的地方。简而言之,我所做的工作是研究许多不同的变量,并针对这些变量的每种组合来测量响应时间和最小化微服务实现的吞吐量。我将所有数据提供给机器学习模型,并询问该模型用于预测性能的变量。我还在英国布莱顿的UKOUG Techfest 2019上就此主题进行了演讲。您可以在 此处 查看演示 。
方法
- 在10个框架中编写了类似的最小hello世界,例如实现(请参见 此处的 代码 )
- 改变分配核心的数量
- 改变了JVM可用的内存
- 改变了Java版本(8,11,12,13)
- 各种JVM风格(OpenJ9,Zing,OpenJDK,OracleJDK)
- 改变了垃圾收集算法(尝试了每个JVM /版本的所有可能算法)
- 改变并发请求的数量
我测量了每种可能的变量组合的响应时间和吞吐量。您可以在 此处 查看数据 。
接下来,我将所有数据放入随机森林回归模型中,确认它是准确的,并要求该模型为我提供功能上的重要性。在确定响应时间和吞吐量的生成模型中,哪个功能最重要。这些都是首先要进行调整的功能。具有较低特征重要性的特征不那么相关。当然,正如我已经提到的,该模型是根据我提供的数据生成的。我必须做出一些选择,因为即使使用20s的测试,每个组合的测试也要花一周的时间。当查看测试方案以外的情况时,模型的准确性如何?我不能说; 你必须自己检查。
为什么使用随机森林回归?
- 它易于使用,适合我的数据。(监督学习)回归模型,在偏差和方差之间具有适当的平衡。
- 可以轻松确定功能的重要性
- 我还尝试了支持向量回归,但即使接近随机森林回归也无法获得准确性。对我来说,这是SVR装备不足的标志;该模型无法捕获数据中的模式
我使用了哪些工具?
我当然可以写一本关于这项研究的书。使用的方法的细节,解释所有测试的不同微服务框架,详细说明使用的测试工具等。我不会。您可以检查自己的脚本, 在这里 ,我已经写了大部分数据的文章 在这里
- 我使用 Apache Bench 进行负载生成。在某些人看来,Apache Bench可能没有得到很高的评价,但它做得很好。至少比我先用Node写的自定义代码好,然后再用Python重写的自定义代码更好。例如,将负载生成的性能与 wrk 进行比较时 ,并没有太大的区别,只是在更高的并发性上,这超出了我所测量的范围(请参阅 此处 )。为了将来的测试,我将尝试wrk。
- 我使用Python来运行不同的场景。比我以前使用的Bash更容易。
- 为了分析和可视化数据,我使用了Jupyter Notebook。
- 在开始实际测试之前,我首先做了一些预热/灌注
- 我特别注意不要使用VirtualBox或Docker等虚拟化工具
- 即使我在与产生负载的硬件相同的硬件上进行了测量,我也特别着眼于避免资源竞争。将负载生成和服务分配给不同的机器是行不通的,因为有时性能差异很小(不到毫秒)。通过网络进行传输时,这些差异将丢失。
结果
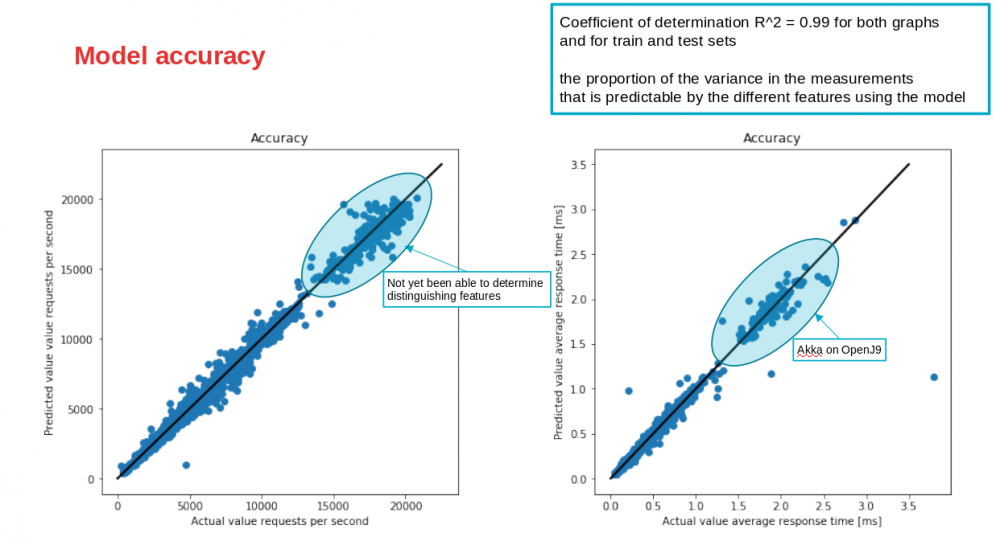
在下面的图中,我显示了预测值与实际值的对比。对角线表示完美的精度。如您所见,该模型的准确性很高。同样,响应时间和吞吐量的R ^ 2值(确定系数)都约为0.99,这非常好!
功能重要性
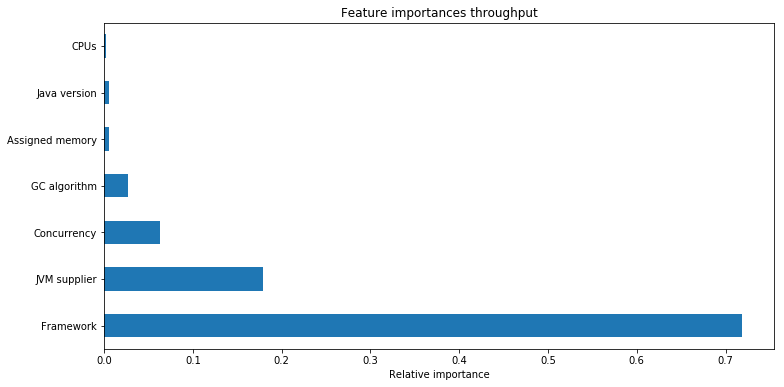 对Java程序的吞吐量影响最大的是框架选择,其次是JVM版本,并发性和GC算法,最后是分配内存和Java版本以及CPU,说明硬件对程序的吞吐量影响最小。
对Java程序的吞吐量影响最大的是框架选择,其次是JVM版本,并发性和GC算法,最后是分配内存和Java版本以及CPU,说明硬件对程序的吞吐量影响最小。
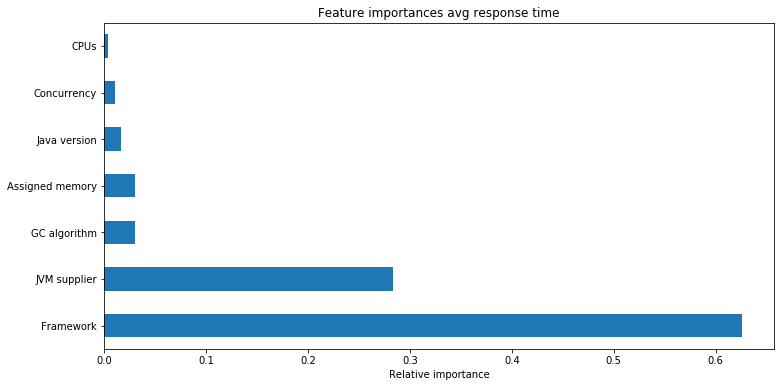 对Java程序的响应时间也就是延迟影响最大的也是框架选择,其次是JVM版本以及GC算法,分配的内存,其次是Java版本、并发性和CPU,可见并发性只是对Java吞吐量提高,对响应时间有影响。
对Java程序的响应时间也就是延迟影响最大的也是框架选择,其次是JVM版本以及GC算法,分配的内存,其次是Java版本、并发性和CPU,可见并发性只是对Java吞吐量提高,对响应时间有影响。
总结
选择的框架的重要性最高。这表明在响应时间和吞吐量方面,实现的选择(当然在我的测试范围内)比JVM供应商(Zing,OpenJ9,OpenJDK,OracleJDK)更重要。JVM供应商比特定垃圾收集算法的选择更重要(垃圾收集算法似乎根本没有那么重要,即使内存受到限制时,垃圾收集算法似乎也变得越来越重要)。Java版本选择对这两个指标没有太大差异。
最不重要的是分配的CPU内核数。显然, 分配更多的内核并不能改善性能 。因为我发现这很奇怪,所以我对数据进行了一些额外的分析,并且发现某些框架在使用更多内核或处理更高的并发性方面比其他框架更好(当不使用默认设置专门调整单个框架/ HTTP服务器时)。
下图是在单个CPU上一个请求和4个请求的吞吐量,没有框架使用是最高的,其实是Vertx,Spring Boot和Quarkus垫底:
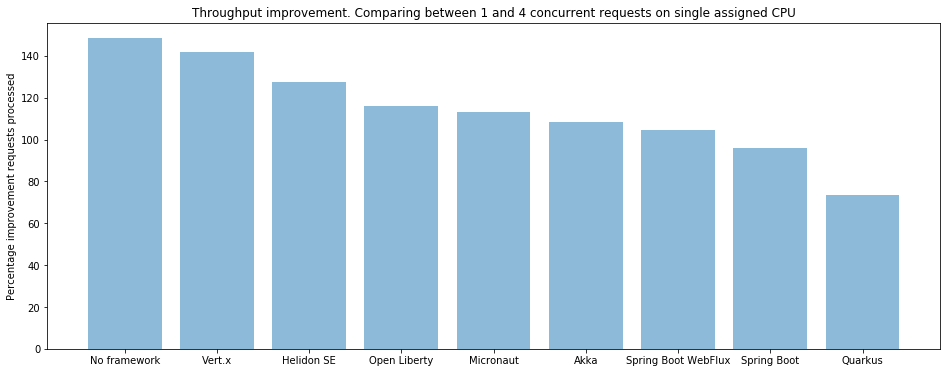
下图是一个CPU无并发和4个CPU4个并发请求的吞吐量,除了SPring Boot WebFlux上升到中位以后,其他没有变化。 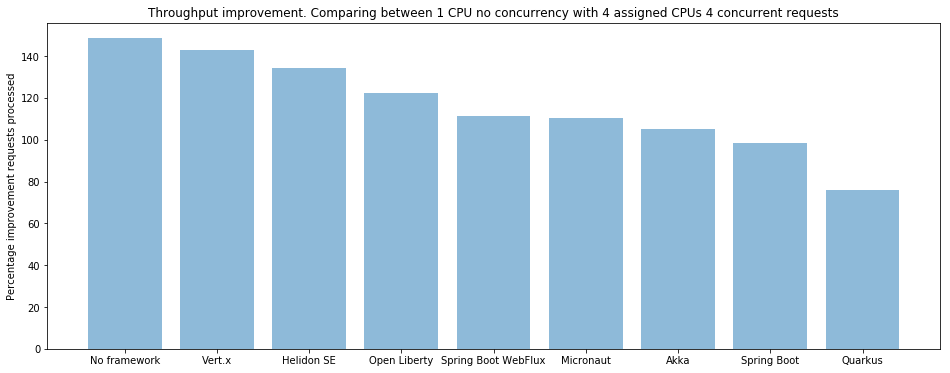
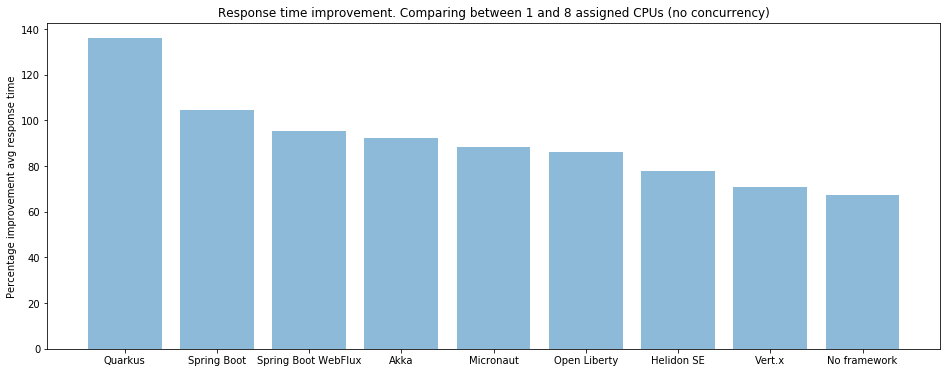
下图是在单个CPU上一个请求和4个请求的响应时间:Quarkus从吞吐量的垫底排名到第一名,顺序基本是吞吐量排名的颠倒,说明高吞吐量和低延迟的矛盾:
下图是一个CPU无并发和4个CPU4个并发请求的响应时间:Spring Boot Webflux从第三名下落到第五名,被Akka替代。
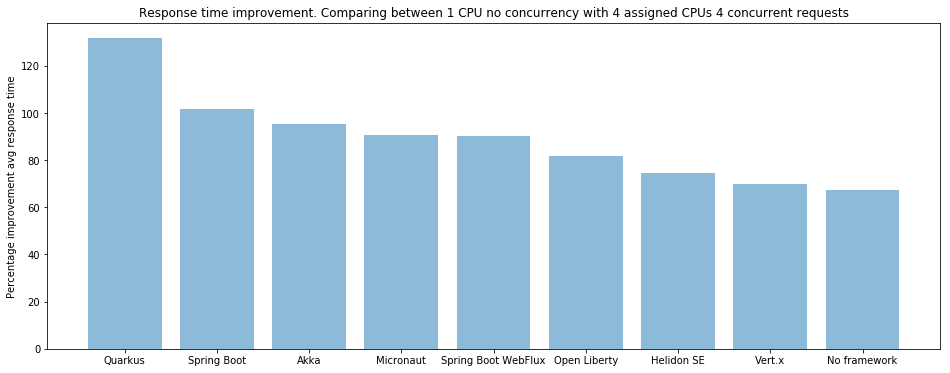
Micronaut在吞吐量和响应时间方面无论是单CPU还是多CPU并发表现都是中位,在吞吐量和响应时间之间平衡。
您可以在 这里 检查笔记本 。
正文到此结束
热门推荐









相关文章

近期评论
-
ws0132613@gmail.comhttps://getmacos.com/gopanel/william smith
-
谢谢
-
https://www.newcmy.com/register?aff=HBVX建议您试试草莓云机场,可以流畅观看youtube和tiktok,上reddit/x也没有问题,还有各种ai优化节点。
-
-
-
想购买您这个站,我的联系方式QQ741756694微信同步 能卖联系
-
-
-
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

