Java 字符串常量池介绍
本文将介绍 HotSpot 中的 String Pool,字符串常量池。相对是一篇比较简单的文章,大家花几分钟就看完了。
在 Java 世界中,构造一个 Java 对象是一个相对比较重的活,而且还需要垃圾回收,而缓存池就是为了缓解这个问题的。
我们来看下基础类型的包装类的缓存,Integer 默认缓存 -128 ~ 127 区间的值,Long 和 Short 也是缓存了这个区间的值,Byte 只能表示 -127 ~ 128 范围的值,全部缓存了,Character 缓存了 0 ~ 127 的值。Float 和 Double 没有缓存的意义。
Integer 可通过设置 java.lang.Integer.IntegerCache.high 扩大缓存区间
String 不是基础类型,但是它也有同样的机制,通过 String Pool 来缓存 String 对象。假设 "Java" 这个字符串我们会在应用程序中使用多次,我们肯定不希望在每次使用到的时候,都重新在堆中创建一个新的对象。
当然,之所以 Integer、Long、String 这些类的对象可以缓存,是因为它们是不可变类
基础类型包装类的缓存池使用一个数组进行缓存,而 String 类型,JVM 内部使用 HashTable 进行缓存,我们知道,HashTable 的结构是一个数组,数组中每个元素是一个链表。和我们平时使用的 HashTable 不同,JVM 内部的这个 HashTable 是不可以动态扩容的。
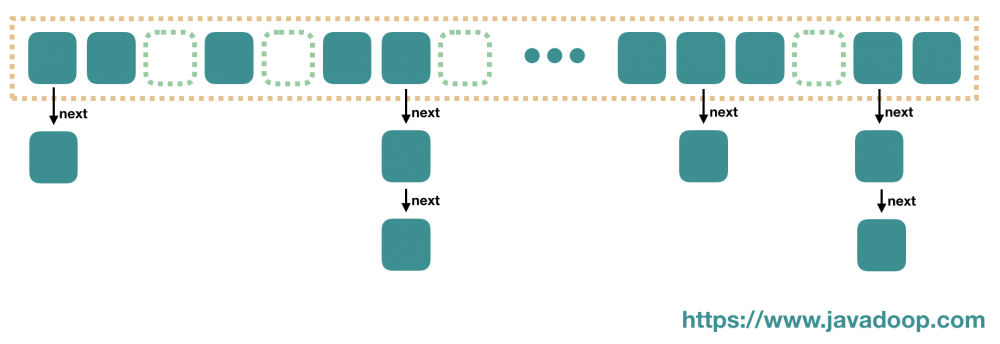
创建和回收
当我们在程序中使用双引号来表示一个字符串时,这个字符串就会进入到 String Pool 中。当然,这里说的是已被加载到 JVM 中的类。
另外,就是 String#intern() 方法,这个方法的作用就是:
- 如果字符串未在 Pool 中,那么就往 Pool 中增加一条记录,然后返回 Pool 中的引用。
- 如果已经在 Pool 中,直接返回 Pool 中的引用。
只要 String Pool 中的 String 对象对于 GC Roots 来说不可达,那么它们就是可以被回收的。
如果 Pool 中对象过多,可能导致 YGC 变长,因为 YGC 的时候,需要扫描 String Pool,可以看看笨神大佬的文章《 JVM源码分析之String.intern()导致的YGC不断变长 》。
讨论 String Pool 的实现
1、首先,我们先考虑 String Pool 的空间问题。
在 Java 6 中,String Pool 置于 PermGen Space 中,PermGen 有一个问题,那就是它是一个固定大小的区域,虽然我们可以通过 -XX:MaxPermSize=N 来设置永久代的空间大小,但是不管我们设置成多少,它终归是固定的。
所以,在 Java 6 中,我们应该尽量小心使用 String.intern() 方法,否则容易导致 OutOfMemoryError。
到了 Java 7,大佬们已经着手去掉 PermGen Space 了,首先,就是将 String Pool 移到了堆中。
把 String Pool 放到堆中,即使堆的大小也是固定的,但是这个时候,对于应用调优工作,只需要调整堆大小就行了。
在 Java 8 中,String Pool 依然还是在 Heap Space 中。感谢评论区的读者指出错误。
2、其次,我们再讨论 String Pool 的实现问题。
前面我们说了 String Pool 使用一个 HashTable 来实现,这个 HashTable 不可以扩容 ,也就意味着极有可能出现单个 bucket 中的链表很长,导致性能降低。
在 Java 6 中,这个 HashTable 固定的 bucket 数量是 1009,后来添加了选项( -XX:StringTableSize=N )可以配置这个值。到 Java 7(7u40),大佬们提高了这个默认值到 60013,Java 8 依然也是使用这个值,对于绝大部分应用来说,这个值是足够用的。当然,如果你会在代码中大量使用 String#intern(),那么有必要手动设置一下这个值。
为什么是 1009,而不是 1000 或者 1024?因为 1009 是质数,有利于达到更好的散列。60013 同理。
JVM 内部的 HashTable 是不扩容的,但是不代表它不 rehash,它会在发现散列不均匀的时候进行 rehash,这里不展开介绍。
3、观察 String Pool 的使用情况。
JVM 提供了 -XX:+PrintStringTableStatistics 启动参数来帮助我们获取统计数据。
遗憾的是,只有在 JVM 退出的时候,JVM 才会将统计数据打印出来,JVM 没有提供接口给我们实时获取统计数据。
SymbolTable statistics: Number of buckets : 20011 = 160088 bytes, avg 8.000 Number of entries : 10923 = 262152 bytes, avg 24.000 Number of literals : 10923 = 425192 bytes, avg 38.926 Total footprint : = 847432 bytes Average bucket size : 0.546 Variance of bucket size : 0.545 Std. dev. of bucket size: 0.738 Maximum bucket size : 6 ## 看下面这部分: StringTable statistics: Number of buckets : 60003 = 480024 bytes, avg 8.000 Number of entries : 4000774 = 96018576 bytes, avg 24.000 Number of literals : 4000774 = 1055252184 bytes, avg 263.762 Total footprint : = 1151750784 bytes Average bucket size : 66.676 Variance of bucket size : 19.843 Std. dev. of bucket size: 4.455 Maximum bucket size : 84
统计数据中包含了 buckets 的数量,总的 String 对象的数量,占用的总空间,单个 bucket 的链表平均长度和最大长度等。
上面的数据是在 Java 8 的环境中打印出来的,Java 7 的信息稍微少一些,主要是没有 footprint 的数据:
StringTable statistics: Number of buckets : 60003 Average bucket size : 67 Variance of bucket size : 20 Std. dev. of bucket size: 4 Maximum bucket size : 84
测试 String Pool 的性能
接下来,我们来跑个测试,测试下 String Pool 的性能问题,并讨论 -XX:StringTableSize=N 参数的作用。
我们将使用 String#intern() 往字符串常量池中添加 400万 个不同的长字符串。
package com.javadoop;
import java.lang.ref.WeakReference;
import java.util.ArrayList;
import java.util.List;
import java.util.WeakHashMap;
public class StringTest {
public static void main(String[] args) {
test(4000000);
}
private static void test(int cnt) {
final List<String> lst = new ArrayList<String>(1024);
long start = System.currentTimeMillis();
for (int i = 0; i < cnt; ++i) {
final String str = "Very very very very very very very very very very very very very very " +
"very long string: " + i;
lst.add(str.intern());
if (i % 200000 == 0) {
System.out.println(i + 200000 + "; time = " + (System.currentTimeMillis() - start) / 1000.0 + " sec");
start = System.currentTimeMillis();
}
}
System.out.println("Total length = " + lst.size());
}
}
我们每插入 20万 条数据,输出一次耗时。
# 编译 javac -d . StringTest.java # 使用默认 table size (60013) 运行一次 java -Xms2g -Xmx2g com.javadoop.StringTest # 设置 table size 为 400031,再运行一次 java -Xms2g -Xmx2g -XX:StringTableSize=400031 com.javadoop.StringTest
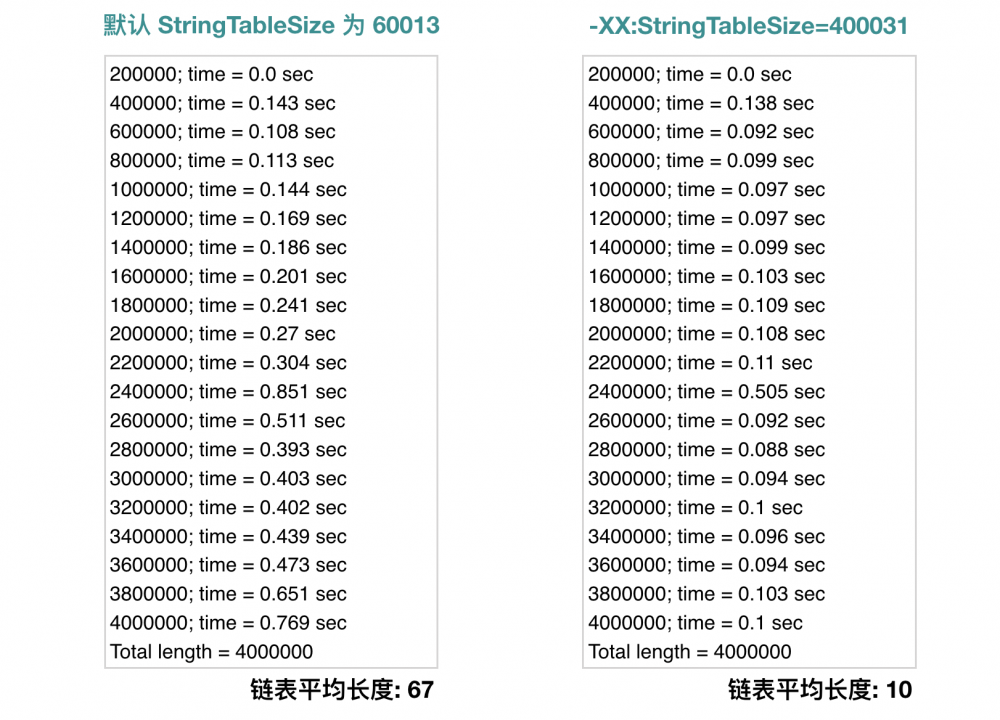
从左右两部分数据可以很直观看出来,插入的性能主要取决于链表的平均长度。当链表平均长度为 10 的时候,我们看到性能是几乎没有任何损失的。
还是那句话,根据自己的实际情况,考虑是否要设置 -XX:StringTableSize=N,还是使用默认值。
讨论自建 String Pool
这一节我们来看下自己使用 HashMap 来实现 String Pool。
这里我们需要使用 WeakReference:
private static final WeakHashMap<String, WeakReference<String>> pool
= new WeakHashMap<String, WeakReference<String>>(1024);
private static String manualIntern(final String str) {
final WeakReference<String> cached = pool.get(str);
if (cached != null) {
final String value = cached.get();
if (value != null) {
return value;
}
}
pool.put(str, new WeakReference<String>(str));
return str;
}
我们使用 1000 * 1000 * 1000 作为入参 cnt 的值进行测试,分别测试 [1] 和 [2]:
private static void test(int cnt) {
final List<String> lst = new ArrayList<String>(1024);
long start = System.currentTimeMillis();
for (int i = 0; i < cnt; ++i) {
// [1]
lst.add(String.valueOf(i).intern());
// [2]
// lst.add(manualIntern(String.valueOf(i)));
if (i % 200000 == 0) {
System.out.println(i + 200000 + "; time = " + (System.currentTimeMillis() - start) / 1000.0 + " sec");
start = System.currentTimeMillis();
}
}
System.out.println("Total length = " + lst.size());
}
测试结果,2G 的堆大小,如果使用 String#intern() ,大概在插入 3000万 数据的时候,开始进入大量的 FullGC。
而使用自己写的 manualIntern() ,大概到 1400万 的时候,就已经不行了。
没什么结论,如果要说点什么的话,那就是不要自建 String Pool,没必要。
小结
记住有两个 JVM 参数可以设置:-XX:StringTableSize=N、-XX:+PrintStringTableStatistics
StringTableSize,在 Java 6 中,是 1009;在 Java 7 和 Java 8 中,默认都是 60013,如果有必要请自行扩大这个值。
参考资料
Java Performance Tuning Guide: String.intern in Java 6, 7 and 8 – string pooling
笨神是真正的大佬: JVM源码分析之String.intern()导致的YGC不断变长
(全文完)
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

