微服务治理实践:探寻业务的单点异常自愈能力
不断的学习新东西,不断的思考更多,不断的对原有自己造成更大的冲击。如果要给我迁移 FaaS 期间的感受下一个总结,那么一定是:“在撕裂中成长”。
微服务架构下,稳定性和高可用性一个永恒的话题,在实际的治理过程中,我们有可能会遇到以下场景:
- 某个应用灰度发布,先上了几台机器,由于代码逻辑写的有问题,造成线程池满,出现运行异常。
- 服务端集群中,某几台机器由于磁盘满,或者是宿主机资源争抢导致 load 过高,客户端出现调用超时。
- 服务端集群中,某几台机器由于线程池满,造成 Full Garbage Collection。
在以上 3 种场景中,由于客户端并不法感知已经出现问题的那些服务端,依然会发送请求到这些机器上,造成业务调用报错,上游的机子将会被下游的某台机子的短暂故障拖垮,造成应用雪崩的风险。
面对这种场景,如果仅仅为此而进行服务降级,对应用的伤害未免过大,但如果我们可以检测出服务集群中某些故障机子,并对其进行短暂隔离,即可有效保障服务的高可用与系统的稳定性,同时给运维人员提供了宝贵的缓冲时间,用于问题定位,排除故障。
本文将作为《微服务治理实践》系列篇的第一篇,为大家介绍如何实现离群实例摘除。该系列文章是基于阿里云商业化产品 EDAS 的微服务实践,如果您团队具备较强的微服务治理能力,那么希望我们在微服务治理方面的实践和背后的思考,可以为您提供一些参考。
Microservice Outlier Ejection (微服务离群实例摘除)
- 什么是离群实例摘除
当单点发生夯机异常时,consumer 能主动判断,并将对应的 provider 实例短时间剔除,不再请求,在一定时间间隔后再继续访问。同时,具有全局异常判断能力,当 provider 异常实例的数量过多时,并且超过一定的控制比例,说明此时 provide 整体服务质量低下,该机制仅保持摘除一定的比例。
- 离群实例摘除的功能
从服务层容错能力上,对业务稳定性进行增强,有效解决单点故障的问题。
- 与熔断的区别
熔断是指当服务的输入负载激增时, 避免服务被迅速压垮导致雪崩效应,而对负载进行断路的一种方式 。熔断一般由熔断请求判断算法,熔断恢复机制,熔断报警等模块组成。隔离是指,为了避免在依赖的服务故障时候造成的故障扩散,而采取的将系统进行单元化设计的一种架构方法。
若仅仅由于服务端集群中单点异常问题,就采用熔断降级方案,将会对应用的伤害过大,离群实例摘除可以有效地解决单点异常问题从而保证服务质量。若 provider 整体服务质量低下时,离群摘除效果不再明显,此时可以采用熔断降级功能。
- 离群实例摘除支持的版本
只要您的应用版本在列表中,您无需改动一行代码就可以使用到离群实例摘除功能。

目前已经覆盖了市面上大部分微服务场景,后续我们将会持续支持开源最新的 Dubbo/Spring Cloud 版本。
我们提供了 Dubbo 和 Spring Cloud 两种场景的离群摘除功能,本文将先介绍一下 Dubbo Microservice Outlier Ejection 的实践与效果。
示例
下面将通过在 EDAS 上通过演示 Dubbo 离群摘除功能及效果。
企业级分布式应用服务 EDAS(Enterprise Distributed Application Service)是一个应用托管和微服务管理的 PaaS 平台,提供应用开发、部署、监控、运维等全栈式解决方案,同时支持 Dubbo、Spring Cloud 等微服务运行环境。
https://www.aliyun.com/product/edas
准备
接下来以微服务 Demo 为例子示范离群摘除功能,读者可以从 github 中下载验证
https://github.com/aliyun/alibabacloud-microservice-demo/tree/master/src
微服务 Demo 是一个简单的电商项目,下图为项目结构,cartservice 为 Dubbo 框架的购物车服务 provider,productservice 为 Spring Cloud 提供的商品详情服务 provider,frontend 为 web controller 即前端展示页面,可以理解为 consumer 。
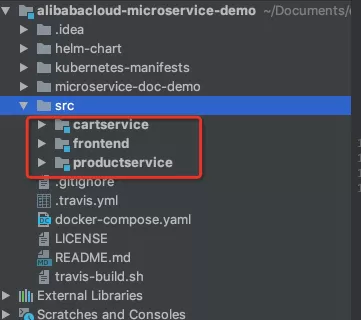
我们将以 cartservice 服务即 Dubbo 服务端为例子,展示离群实例摘除功能。
EDAS 上部署微服务 Demo
首先 cd cartservice 切换到 cartservice 目录下,再通过 mvn clean install 打包,通过 cd cartservice-provider/target 切换到 target 目录下,我们可以看到新生成的 cartservice-provider-1.0.0-SNAPSHOT.jar 包,然后在 EDAS 上 创建一个 cartservice 应用。
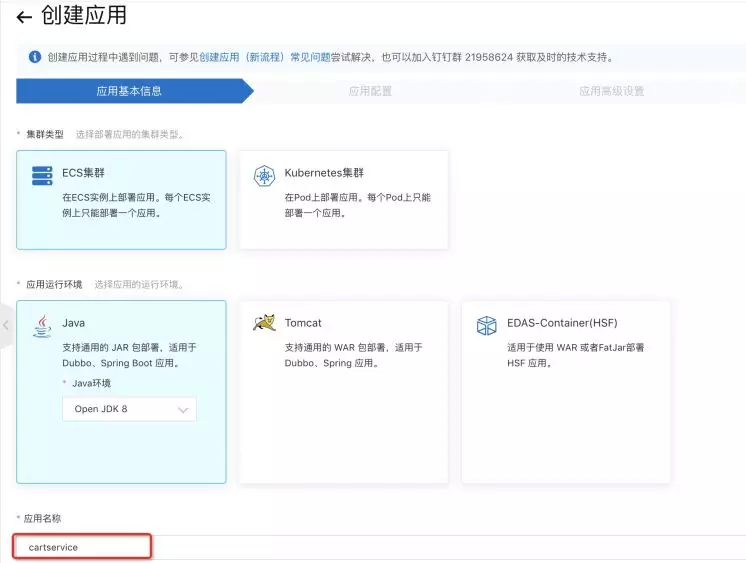
点击下一步后,上传刚才打包的 jar 包,即 cartservice-provider/target/ cartservice-provider-1.0.0-SNAPSHOT.jar 然后下一步,记住登陆密码,直到创建应用成功。
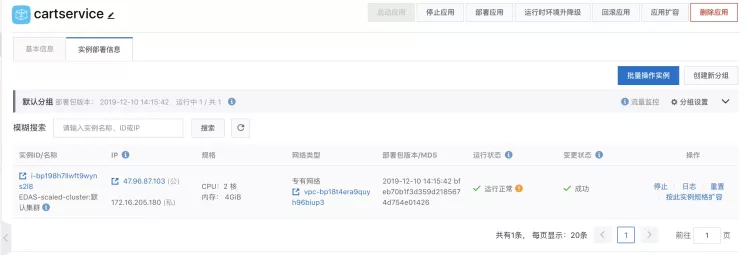
然后启动应用,到目前为止,我们启动了一个 cartservice-provider。点击按此实例规格扩容,该服务我们部署在两个实例上。

我们在这个 provider 的 com.alibabacloud.hipstershop.provider.CartServiceImpl 类中可以看到,这个 provider 是提供了 viewCart 和 addItemToCart 的两个关于购物车的服务,我们在 viewCart 中加入一些模拟运行时异常的逻辑。
复制代码
@Value("${exception.ip}")
privateStringexceptionIp;
@Override
publicList<CartItem> viewCart(StringuserID) {
if(exceptionIp !=null&& exceptionIp.equals(getLocalIp())) {
thrownewRuntimeException(" 运行时异常 ");
}
returncartStore.getOrDefault(userID, Collections.emptyList());
}
其中 exceptionIp 为 ACM 配置中心的 exception.ip 的配置项,若该项配置为本机 Ip 时,该服务 throw RuntimeException ,用于模拟业务异常的场景。
- 为什么将 cartservice 扩容到两个实例,想必大家也猜到了,运行时通过配置 ACM 配置中心指定其中一个实例的 IP,模拟出一个实例异常的场景。
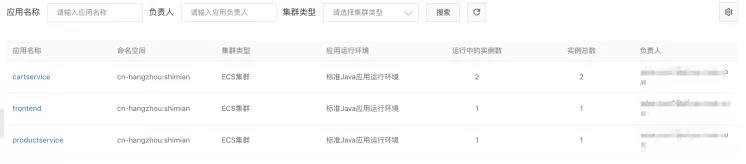
接下来,我们需要部署 frontend / productservice 两个服务,方式一样,分别上传 frontend/target/frontend-1.0.0-SNAPSHOT.jar 和 productservice/productservice-provider/target/productservice-provider-1.0.0-SNAPSHOT.jar。
从下图可以看到,我们的微服务 Demo 在 EDAS 部署上去了。
模拟业务异常
进入到 frontend 应用中,我们看到其实例的公网 Ip 为 47.99.150.33。

进入浏览器访问 :
http://47.99.150.33:8080/
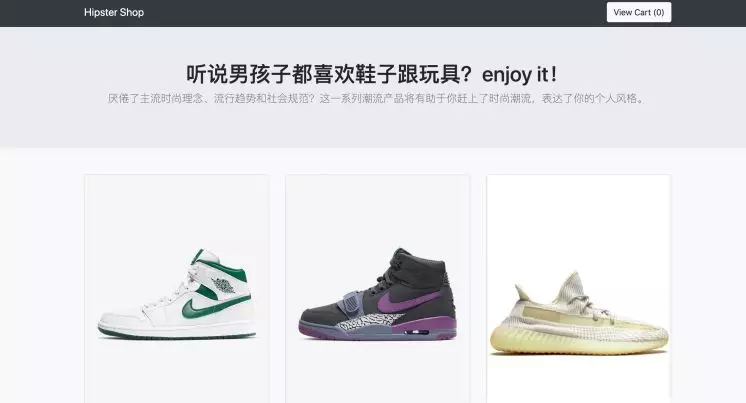
点击 View Cart 访问至 :
http://47.99.150.33:8080/cart
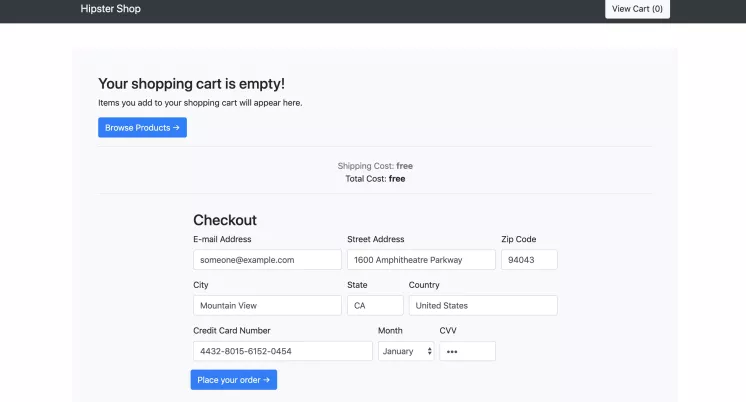
可以看到,此时服务都是正常的。
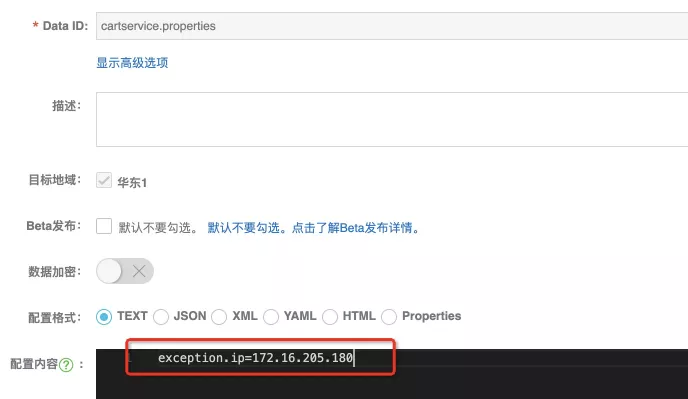
我们去 ACM 配置中心 配置 exception.ip 为 172.16.205.180(即 cartservice 的其中某个实例的 IP)。
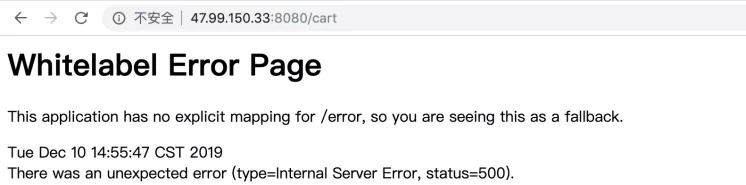
然后继续访问 :
http://47.99.150.33:8080/cart ,
发现 50 % 的概率错误页面。
此时,我们写一个脚本,定时大量访问 :
http://47.99.150.33:8080/cart
模拟请求。
复制代码
while: do result=`curl$1-s` if[["$result"== *"500"* ]];then echo`date +%F-%T`$result else echo`date +%F-%T`"success" fi sleep 0.1 done
然后 sh curlservice.sh http://47.99.150.33:8080/cart。
我们看到不断重复的每秒钟 10 次的 50% 的调用成功率。

其实也可以理解到,下游的服务质量随着上游的某台机子的异常而急剧下降,甚至可能导致下游服务被上游某些机子的(系统、业务)异常给拖垮。
开启离群摘除策略
下面我将演示离群摘除的策略的开启及其效果的展示。
创建
我们进入到 EDAS 左侧列表的 [微服务管理] 下的 [离群实例摘除] 界面中,并选择创建离群实例摘除策略。
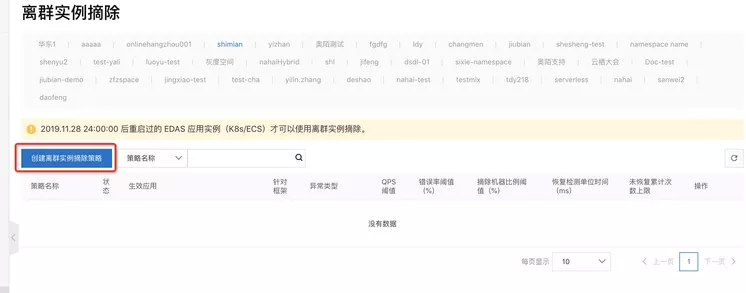
然后按照提示一步步创建离群摘除的策略。
基本信息

如上图可以选择命名空间、填写策略名称、选择该策略支持的框架类型(Dubbo/Spring Cloud)。
选择生效应用
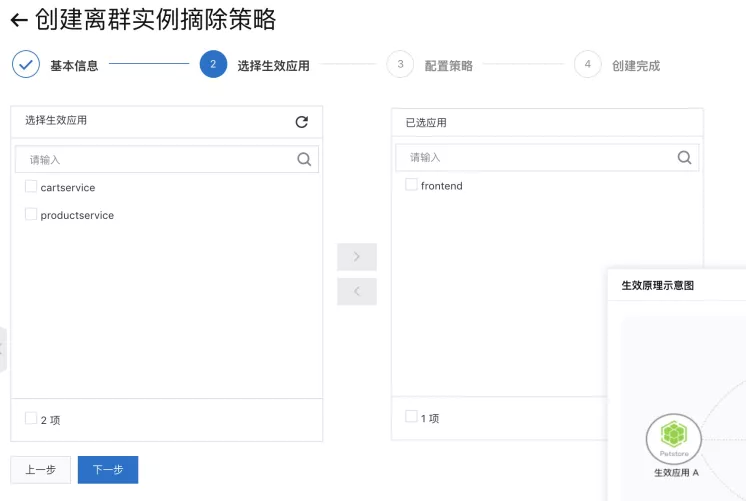
按照目前的调用方式,我们只需要配置 frontend 应用,保护下游应用 consumer。
配置策略
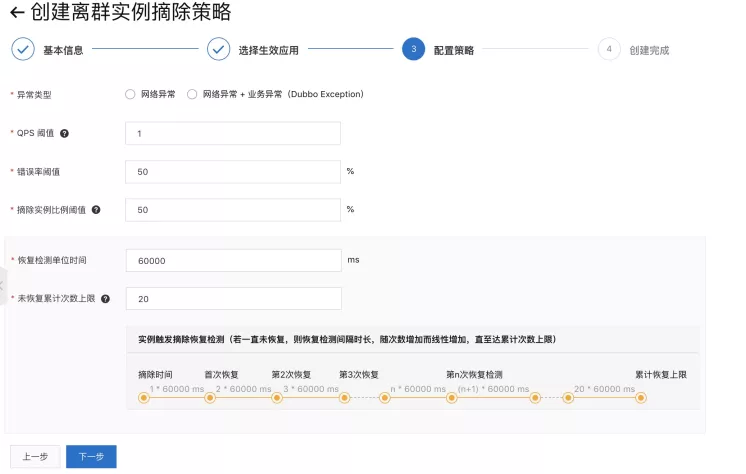
这些参数都提供了默认值,需要根据自己应用的具体情况调整最合适的值,由于需要保护的 RuntimeException 属于业务异常于是选上 网络异常 + 业务异常。(需要注意的是即使摘除实例比例上限配得特别低,向下取整数小于 1,当集群中实例数目大于 1,且某一实例异常,我们也会摘除一实例)。
创建完成

可以看到策略的信息,创建完成。
策略

看到了我们创建的离群摘除策略,且是针对 Dubbo 框架,并且针对的是 网络异常 + 业务异常 的异常类型。
验证离群摘除效果
这时,我们看到,再感知到异常后,离群摘除功能生效,请求调用一阵子后,均返回正确结果。
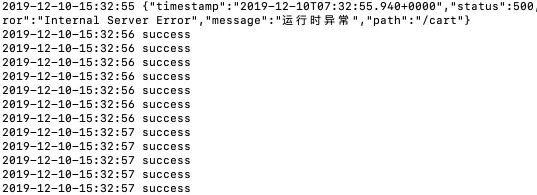
不断刷新浏览器访问:
http://47.99.150.33:8080/cart
也均正常。
客户端感知到某台服务端机子异常后,主动摘除。仅仅调用业务正常的 Provider 实例,同时我们也可以通 ARMS(EDAS 监控系统) 监控看到服务质量的上升,以及流量从异常 Provider 中摘除。
Dubbo 框架可以从 /home/admin/.opt/ArmsAgent/logs 目录下的日志中,搜索日志中的 “OutlierRouter” 关键字可以看到一系列离群实例摘除的事件日志。
修改 / 关闭离群摘除策略
对于 EDAS 的应用我们支持通过控制台动态修改和删除离群摘除策略。
- 对应策略规则的修改
点击 修改生效应用 或者 编辑策略。
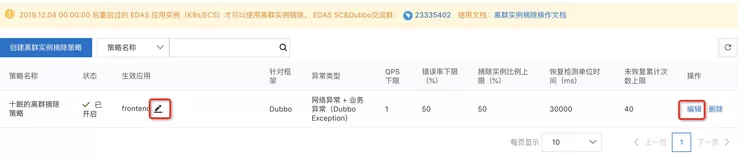
然后增加删除应用或者调整参数,确定后均立即生效
- 删除对应策略

控制台的操作,对应用中的配置都是实时生效的,若删除策略后,默认关闭相关策略。
若我们打开 ARMS 监控观察具体的调用情况。
ARMS 监控
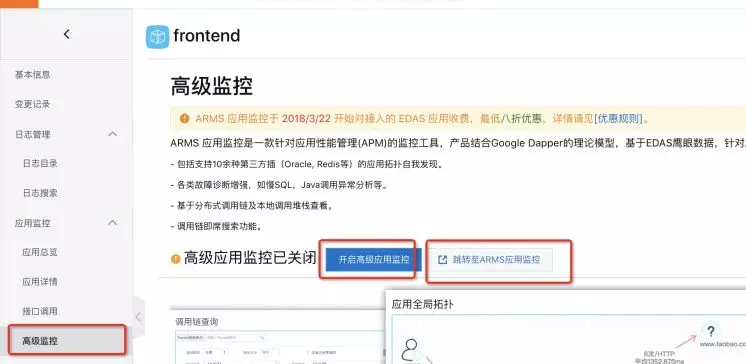
若我们开启监控,将会直观看到流量与请求错误等信息。
开启离群摘除前
如下图方式开启,然后跳转至 ARMS( EDAS 监控系统)应用监控页面,我们需要把三个应用都开启高级监控。
我们可以从下图即 ARMS( EDAS 监控系统)应用监控页面直观地看到结果。
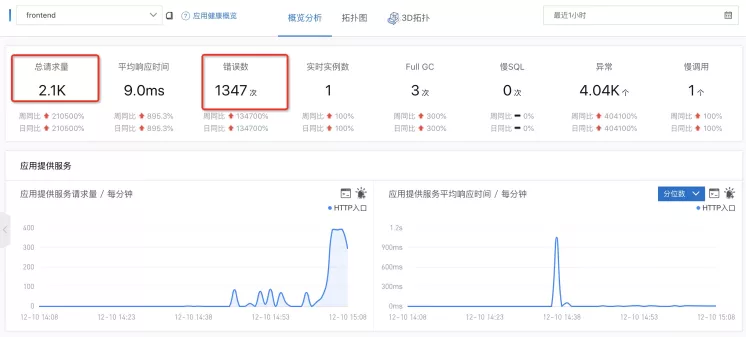
从以下拓扑图中我们看到,流量不断地访问到 cartservice 服务上。
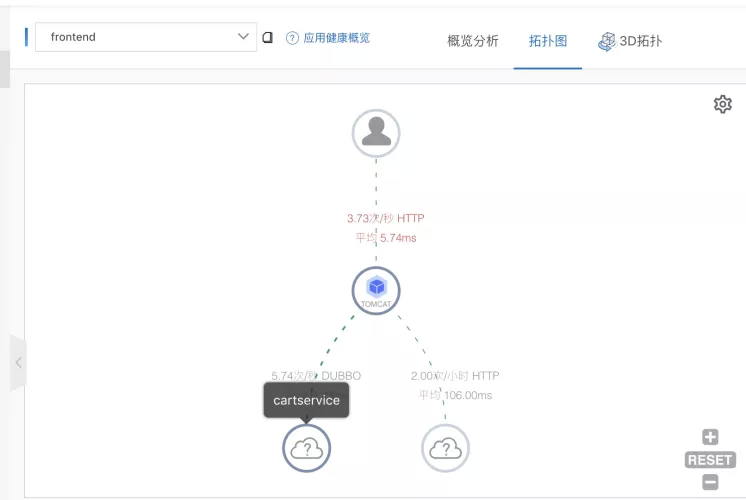
开启离群摘除后
离群摘除效果通过简单的例子就看到了,当然可以通过 ARMS ( EDAS 监控系统)的监控可以明显观察到服务质量的提升。
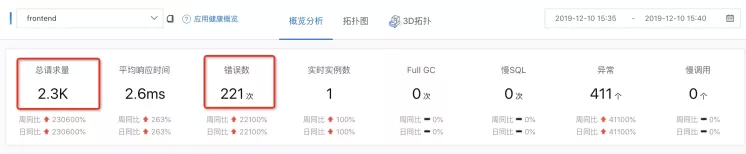
可以看到,在开启了离群摘除的那个点只后,错误率从 50% 明显下降。
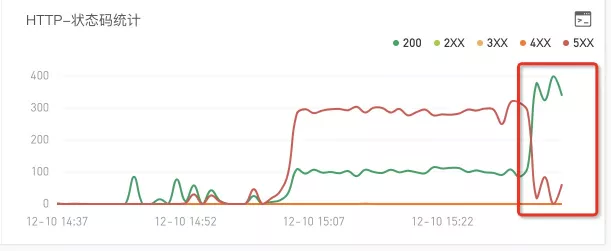
其中两个小的起伏毛刺是因为,离群摘除一段时间后会重新尝试访问被摘除的 endPoint ,若依旧错误率高于阈值,继续隔离,且间隔时间更长。
离群实例摘除具体控制逻辑
前面我们看到了,离群实力摘除对应用稳定性提高带来的帮助,下面我们将具体分析离群实例摘除的控制逻辑,有助于您更好地理解其各种参数的意义,以及可以根据自己的应用情况,通过调整参数,配置出最合适自己的离群摘除策略。
对于 Dubbo/SpringCloud 框架:
- 默认 QPS 下限为 1
只有当前某实例的调用 QPS 大于 1 才会开始离群实例摘除保护。
- 默认错误率下限 50%
只有当前某实例的调用错误率高于 50% ,则系统会认为该服务端集群的当前某实例处于异常状态。
- 默认摘除实例比例上限 20%
若当前服务集群中,有大于 20% 的实例节点处于异常状态,则系统只会摘除异常状态的实例数占集群总数的 50% 。
- 异常类型
若异常类型为 网络异常 ,则系统仅仅把网络异常的错误算进错误率统计中,忽略掉业务异常;反之,若选择了 网络异常 + 业务异常 则系统会将所有异常当成错误算进错误率统计中。
- 关于恢复检测单位时间(默认 30000ms 即 30s )与未恢复累计次数上限(默认 40 )的解释
其中第一次摘除时长为 0.5 分钟,时间到了之后 consumer 会继续访问该 provider ,若该 provider 服务质量依旧低下,则会继续摘除,摘除时长随着连续被摘除次数的增加线性递增每次增加 0.5 分钟,每次最多摘除 20 分钟。当然,若继续调用之后,服务质量恢复了,则会当成健康服务,下一次又出现异常导致服务质量低下问题时,会重新隔离 0.5 分钟,并继续上述规则。
- 兜底
但是当客户端调用的服务仅有 1 个实例提供服务提供则不会隔离这个实例。
若当前客户端调用的服务实例大于 1 个,且当前离群摘除隔离比例计算出的实例数小于 1,若服务端集群出现单点故障,则会摘除 1 个实例。
上面所有的实例可以理解为 endpoint(ip+port 为纬度)
- 通用最佳实践
可以配置相对的错误率阈值(50%)与过低的摘除实例比例上限(10%),全链路开启。
离群实例摘除技术细节
无侵入技术
无侵入方案即通过 agent 技术来实现,一句话来说就是通过字节码增强技术,运行时插入我们的代码,改变应用的原有逻辑,可以理解为运行时 AOP ,通过在 Dubbo 的链路中插入 Filter/Router ,在 Spring Cloud 中增强 LoadBalance 逻辑,来实现我们期望的路由控制逻辑。同时因为是 agent 增强的,再加上 Dubbo 各个版本的链路整体基本没大的变化,Spring Cloud 模型的统一性,因此我们可以花少的代价将能力基本覆盖到所有版本。

对于用户来说,无需改动一行代码,一行配置,即可享受到稳定性增强的能力。
离群实例摘除技术
Outlier Detection 离群检测
均是基于时间窗口的数据统计。两种实现如下:
1、Dubbo 2.7 版本通过向链路中嵌入一个 MetricsFilter ,对于链路的每个 request/response 做打点处理,统计 rt、调用成功与否、异常类型,并且已 endpoint(ip+port) 为 key 存储。
2、在 Agent 底座中统计经过的 http 请求,通过 url、rt、状态码、异常类型等数据结果,统计最近时间窗口的数据(目前写死 10 秒,暂时不透出)。
实时统计前 N 秒的调用信息,作为离群实例摘除动作的依据。
Outlier Ejection 离群摘除
Dubbo 基于 Dubbo Router 实现,对于调用的上游服务对应的所有 invokers 中,拉黑掉“不健康”的节点,同时记录拉黑的信息。
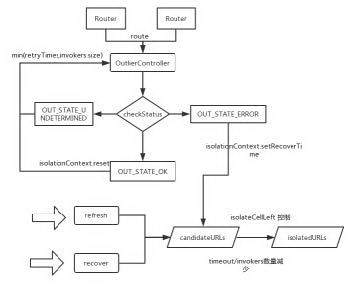
每次请求过来仅仅 check 一下并标记状态,后台有专门两个线程将标记的流量进行判断是否进入隔离列表或从中剔除,修改拉黑信息等耗时操作,最大程度上保证请求的实时性。
Spring Cloud 基于 扩展 LoadBalace 实现,原理相似。
作者介绍:
泮圣伟,花名十眠,中间件技术 - 微服务产品团队研发工程师,负责 Dubbo / Spring Cloud 商业化产品开发相关工作,目前主要关注云原生、微服务等技术方向。
本文转载自公众号阿里巴巴中间件(ID:Aliware_2018)。
原文链接:
https://mp.weixin.qq.com/s?__biz=MzU4NzU0MDIzOQ==&mid=2247488458&idx=3&sn=681e033fe57f036fc036034f1222398b&chksm=fdeb21aaca9ca8bcb1ff5a59f653fc1ed9670920fef03141810419b6da9461a7c910a9be3eac&scene=27#wechat_redirect
正文到此结束
- 本文标签: Master springcloud 部署 db 产品 IDE 实例 总结 src 下载 希望 灰度发布 微服务 web 线程 PaaS URLs 开发 lib 文章 MQ 工程师 Agent spring tar 数据 App 参数 dist Enterprise 模型 QPS 目录 https UI 空间 阿里云 企业 ACE AOP 高可用 字节码 云 git 配置 时间 list consumer 删除 Collection 分布式 equals ip 阿里巴巴 代码 value provider http IO id 配置中心 集群 GitHub key dubbo 主机 Service 服务端 Spring cloud 质量 cat 管理 Collections 开源 统计 线程池
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

