电商团队云原生实践
总篇74篇 2019年 第48篇
自 Docker和K8S开源以来,以 Docker 为代表的容器产品凭借着隔离性好、可移植性高、资源占用少、启动速度快等特性迅速风靡世界。容器使用操作系统级别的虚拟化,单个操作系统实例被动态划分为多个相互独立的容器,每个容器具有唯一可写的文件系统和资源配额,提供了比虚拟机更高的效率和更快的速度。创建和销毁容器的低开销,以及单个服务器可高密度运行多个容器的特性使得容器成为部署微服务各个模块的完美工具。
2019年是汽车之家的云原生架构落地实践元年,自5月份开始公司大力推行云平台迁移的时候,电商团队架构组成员就开始容器化的学习和准备工作。从9月底开始迁移第一个应用到11月底完成了全部应用迁移到容器平台,前后历时两月,现将一些使用的经验跟大家分享。
Java Vs Docker
低版本Java和Docker不是天然的兼容,具体表现在 Docker可以设置内存限制和CPU限制,而低版本Java却不能自动检测到。
内存限制
默认的情况下,Docker没有对容器进行硬件资源的限制,当一台主机上运行几百个容器,这些容器虽然互相隔离,但是底层却使用着相同的 CPU、内存和磁盘资源。如果不对容器使用的资源进行限制,那么容器之间会互相影响,小的来说会导致容器资源使用不公平;大的来说,可能会导致主机和集群资源耗尽,服务完全不可用。
Docker是通过cgroup来实现最大内存和CPU设置的,设置命令:
docker run -m 1024M --cpuset-cpus= "1,3"
在8u131之前的Java版本不能识别这个限制,如果不指定JVM的堆大小,JVM不能针对性地在内存资源范围内做优化,也不能及时在内存使用达到限制前及时启动内存回收等,导致容器因内存使用超过限制而被Docker杀死。我们需要的是在超过内存限制的时候,JVM抛出 OutOfMemoryException 而不是被kill掉。
CPU限制
JVM的 Runtime 会查看硬件并检测可用的CPU的数量。如果JVM看到的是宿主机的CPU数量,而不是Docker设定的CPU数量,那么会导致JVM可以看到很多CPU但是却无法使用的问题。在 线程池 和 并行GC 的情况下会导致一些不可预见的问题。
日志收集
日志保存在容器内部,它会随着容器的销毁而被删除。由于容器的生命周期相对虚拟机大大缩短,创建销毁属于常态,因此需要一种方式持久化的保存日志。
技术准备
对于上容器大家都是非常积极的态度,在战略上藐视敌人,在战术上重视敌人。 在部门内开展了Docker的学习以及模拟容器环境下可能出现的问题,充分做到兵马未动,粮草先行。
JDK版本选择
在经过充分技术调研工作之后我们发现:
-
Java8u_131之前,需要在容器中通过设置 -Xmx来限制堆大小避免容器内kill掉进程,并同时显示设定并行GC的线程数和JIT编译并行数:
-Xmx=2G -XX:ParallelGCThreads=cpus -XX:CICompilerCount=cpus
-
Java8u_131已经可以正确识别Docker设定的CPU资源限制,不用再显式设定 ParallelGCThreads 和 CICompilerCount ,而内存方面的识别还需要以下参数:
-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap
-
Java8u_191为适配Docker容器新增三个参数 InitialRAMPercentage、 MinRAMPercentage、MaxRAMPercentage分别代表初始JVM初始内存占比、最小和最大内存占比。这样做的好处是显而易见的,当容器资源发生内存和CPU扩容的时候,不需要修改启动JVM的脚本。
-
Java11开始可以使用 -XX:UseContainerSupport 来保证JVM可以获取到正确的CPU数量和内存限制。并且这个参数是默认开启的,如果要关闭可以通过 -XX:-UseContainerSupport选项禁用。
综合看来Java11是真香,自带ZGC,并且是长期支持版本。由于一些历史原因,电商依然有80%的项目的运行在Java8的131版本之上,5%运行在Java8的065版本之上,15%的项目是运行在Java7之上。考虑盲目升级Java大版本可能会出现一些大的改动,这不是我们所想遇见的,最终决定了决定还是用Java8最新的191版本。
日志收集
之家云平台提供了完整的容器日志收集平台。对于容器内的系统日志和程序日志提供了不同的采集方案。
-
系统日志
采集容器内文本日志最简单的方法是在启动容器时通过 bind mounts 或 volumes 方式将宿主机目录挂载到容器日志所在目录。这样当容器实例发布重建或者重启都不会丢失这个目录的数据。然后通过 filebeat 实时采集容器映射在宿主机上的固定目录的日志上传到日志收集服务器。
-
程序日志
在image层集成nxlog插件以及nxlog的配置文件,启动容器内的应用的同时启动nxlog。通过nxlog将 容器内的应用程序日志上传到鹰眼日志收集平台。
COPY nxlog.conf /etc/
CMD /usr/bin/nxlog && java $JAVA_OPTS -jar /app.jar
镜像架构
容器镜像我们分了三层,依次为 OS 层、Runtime 层、应用层。
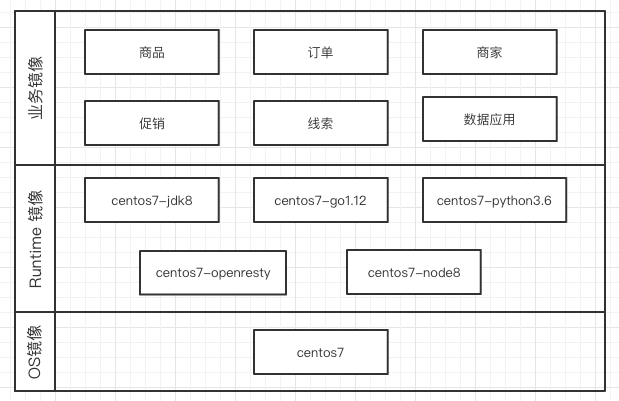
在OS层和Runtime层我们没有选择Google提供的distroless镜像或者 Alpine镜像,这两种类型的镜像优势是体积小,打完包都不到100M。 镜像的体积是我们选 择基础镜像的一个标准,却不是绝对标准,还有以下考虑:
-
之家云平台的JVM的监控体系还在起步阶段。根据墨菲定律,如果你担心什么事会发生,那么它在将来一定会发生。在Java应用运行的生命周期内一定会出现各种异常情况,这时候就需要登录容器内部排查问题。便捷性和完善性将是考虑的核心。distroless镜像不支持bash,所以无法使用top,jstat等jvm工具查看Java进程的运行状态,也无法dump。
-
鹰眼日志收集平台使用的收集工具nxlog在Alpine镜像上无法很好的运行。
-
考虑现在是微服务的链路监控系统skywalking插装使用的jar包以及Java性能诊断工具Arthas的jar包可以放在Runtime层,这样就避免每个工程项目都自带一份jar。
制作镜像的Dockerfile如下:
FROM xxxx.autohome.com.cn/project/centos7-jdk8:full-nxlog
ADD skywalking-agent/6.4.0/ /skywalking-agent/
ADD arthas-3.1.4/ /arthas/
RUN echo 'Asia/Shanghai' > /etc/timezone && chown -R root:root "/var/run/nxlog" && chown -R root:root "/var/spool/nxlog" && mkdir -p /usr/local/nxlog-config/data
MAINTAINER fangli@autohome.com.cn
镜像制作命令
docker build -t xxxx.autohome.com.cn/project/centos7-jdk8:v1 <Dockerfile Path>
镜像上传命令
docker push xxx.autohome.com.cn/project/centos7-jdk8:v1
镜像上传到服务器之后,在业务项目的Dockerfile 使用
FROM xxxx.autohome.com.cn/project/centos7-jdk8:v1
多阶段构建镜像
Docker多阶段构建镜像是17.05之后引入的新功能,允许用户在一个 Dockerfile 中使用多个 From 语句。每个 From 语句可以指定不同的基础镜像并将开启一个全新的构建流程。一个标准的多阶段构建镜像的Dockerfile如下:
FROM maven:3.5-jdk-8 AS build
COPY src /usr/src/app/src
COPY pom.xml /usr/src/app
RUN mvn -f /usr/src/app/pom.xml clean package
FROM openjdk:8-jre
ARG DEPENDENCY=/usr/src/app/target/dependency
COPY --from=build ${DEPENDENCY}/BOOT-INF/lib /app/lib
COPY --from=build ${DEPENDENCY}/META-INF /app/META-INF
COPY --from=build ${DEPENDENCY}/BOOT-INF/classes /app
ENTRYPOINT ["java","-cp","app:app/lib/*","hello.Application"]
多阶段编译的核心思想就是将编译好的.class文件和依赖的第三方 jar 包拷贝到最终的镜像里,通过这种方式可以显著的减少镜像的体积。但是也存在着一些问题:
-
编译命令 mvn clean package 在Dockerfile里。在之家云平台上都是不同的环境都是对应不同的流水线,每个流水线的编译节点的脚本才会带上不同的环境变量。云平台制作镜像的时候默认选择的是项目根目录下的Dockerfile进行编译。虽然可以通过建立多个profile下不同的Dockerfile,然后在编译阶段将不同环境的Dockerfile 拷贝到根目录。但是这种方式会产生Dockerfile冗余。
-
多阶段构建镜像每次在构建的时候都会在mvn执行的时候会从nexus服务下载项目依赖的jar包,需快的项目编译1-2分钟可以搞定,对于一些大型项目,编译时间超过10分钟都是有可能的,这就导致了在一些紧急情况需要上线修复的情况下,无法满足快速交付的需要。
分层构建镜像
Jib 是Google开源的一个 Maven 或 Gradle 插件,用于简化 Java 应用程序镜像的打包过程。 以一个Spring Boot 应用程序为例,打成后的 JAR 包60~100MB,包含三个部分:
-
依赖项:它们占了很大的一部分比例,但很少发生改动。大多数时候我们只会修改我们的代码,很少会去修改依赖项。但依赖项每次都会被拷贝到发布版本中。
-
资源文件: 这个问题跟依赖项差不多。虽然资源文件(HTML、CSS、图像、配置文件等等)比依赖项更经常发生改动,但比起代码还是相对少一些。它们也会被拷贝到发布版本中。
-
代码:代码只占 JAR 包很小的一部分(通常 300KB 到 2MB),但会经常发生改动。
经常发生改动的代码只有几 MB,但每次都需要拷贝所有的依赖项和资源文件,这是对存储空间、带宽和时间的一种浪费。Jib利用 Docker 镜像的分层机制,就像已经分好的 OS层 和 Runtime 层那样。更进一步引入了依赖项层、资源文件层和代码层,按照改动的频繁程度来安排这些层的次序。
Jib 最重要的一个特性是,它会扫描我们的 Java 项目,并为依赖项、资源文件和代码创建不同的层。 Docker 构建流程:

Jib 构建流程:
使用jib编译可以显著减少镜像体积。以电商其中的一个项目为例,使用jib编译的过程中可以看到是分层编译。
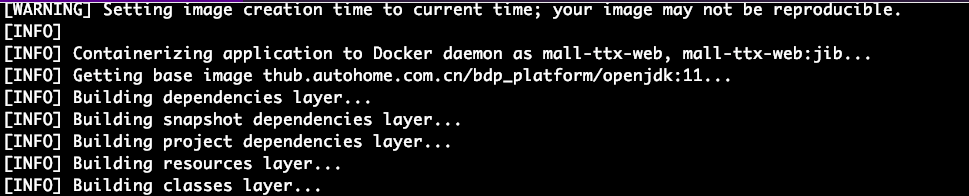
使用jib制作的镜像和Dockerfile方式的镜像大小对比:

使用jib可以显著的减少镜像的体积,但是在实际生产中却是不可用的:
-
从jib构建流程的图里也可以看到,jib是直接推送到镜像服务器里的,这样就会导致研发可能会在本地开发环境推送不可用的镜像到服务器里,会极大的浪费了服务器存储资源。
-
直接推送到镜像服务器里,与云平台的流水线的CI、CD概念违背。
JVM参数设置
为了方便容器资源的管理和规划,之家云抽象出来了容器的套餐管理,不同的应用可以根据自己的需要选择对应的配置。
容器里的Java服务的启动参数采取的是读取云平台预设值的环境变量JAVA_OPTS。Dockerfile的启动命令:
CMD java $JAVA_OPTS -jar /app.jar
技术改造
为了保证订单系统的高可用和业务层面的刷单,订单系统在接入层Nginx上有一层风控,主要做一些参数校验、安全校验以及风控的逻辑,使用Nginx+Lua+Redis来实现的。 架构图如下:
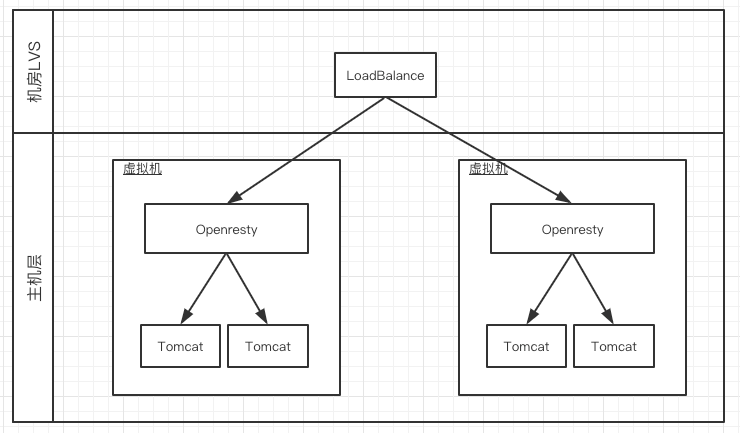
Nginx是部署在虚拟机上,风控通过后轮询转发给虚机上的Java服务。如果按照这种方式平移的话,就会产生一个项目的镜像耦合了Nginx+Lua的环境和Java环境,不仅镜像的体积巨大,而且服务发布也是耦合的。修改了nginx的lua脚本也会重启Java的服务,应用的整体可用性下降。 为了提高系统的整体可用性,我们决定将Nginx+lua环境的风控服务抽象成单独的风控层,新建一个项目,只用来做风控,风控通过后通过新的域名转发给后面的Java应用。改造之后的系统架构图如下:
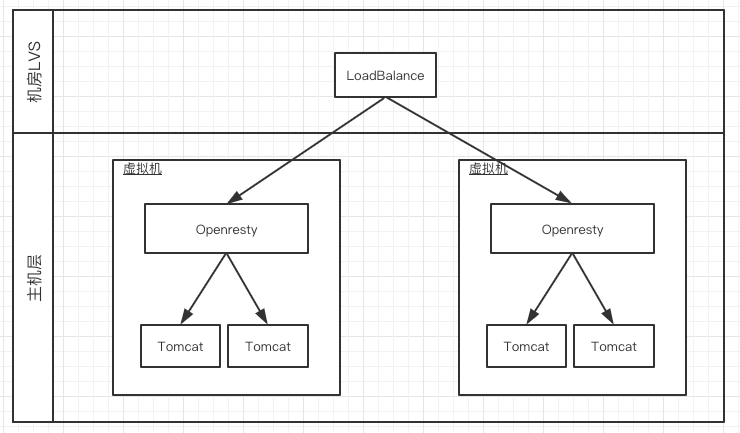
容 器健康检查
在云原生的架构下,应用程序运行在K8S的Pod实例的容器里,Kubernetes提供了两种探针来检查容器的状态,存活探针Liveness和就绪探针Readiness。
Liveness探针是为了查看容器是否正在运行,目的是让Kubernetes知道你的应用是否活着。定时检查运行是否正常,如果你的应用还活着,那么Kubernetes就让它继续存在。如果你的应用程序已经死了,Kubernetes将重启容器。Liveness探针职责是在 容器运行期 。
Readiness探针是为了查看容器是否准备好接受HTTP请求。就绪探针旨在让Pod实例知道你的容器是否准备好为请求提供服务。只有在就绪探针通过才会通过负载均衡将流量转发到容器。如果就绪探针检测失败,Kubernetes将停止向该容器发送流量,直到它通过。Readiness探针的职责则是在 应用服务运行之前 。除了初始决定加入负载列表外,Readiness也会持续探测,在检测失败次数达到条件时会将容器从负载列表暂时摘除,摘除出也会持续探测达到条件重新加回来。
健康检测机制其实是在依赖倒置原则下设立的,虽然集群根据具体容器的探测结果来负责重启容器/上下负载,但是最终决定容器生死和服务状态的其实还是容器应用自身。容器应用还是应该仔细规划两个探针返回健康状态的逻辑,以达到利用健康检查机制执行自动化运维的目的。对于上容器的应用我们建议设置独立的健康检查:
-
若因依赖方、调用方问题导致的业务不可用但 还在不断重试且可恢复 , 只需要将 【就绪检测】 置 失败状态;
-
若进入了不可恢复的状态, 还是需要设置【存活检测】为失败以通知集群重启容器;
-
若应用已直接判断出容器重启即可解决问题,应用也可直接退出运行的方式让集群重新拉起容器。
另外之家云容器平台也有规划,将当前的健康检查拆分为就绪检测和存活检测两套接口,且提供更丰富的机制与应用进行交互以及方便故障定位等。
就具体实现而言,如果RPC框架使用的是Dubbo,Dubbo在解析到<dubbo:service />时就会打开端口对外提供服务,有些服务需要一定的预热时间,比如初始化缓存,等待相关资源就位等,如果此时请求进来,则会报错。在Dubbo-2.6.5 之前版本 可以通过在提供的服务的配置文件上增加 delay="-1",将暴露服务延迟到Spring初始化之后;或者 delay="3000" 等spring初始化之后再延长3s。Dubbo-2.6.5 及以后版本,默认所有的服务都在Spring完成初始之后对外暴露。
对于一些特定的Readiness检查项目,可以使用蚂蚁金服的SofaStack框架提供的healthcheck相关包来实现:
<dependency>
<groupId>com.alipay.sofa</groupId>
<artifactId>healthcheck-sofa-boot</artifactId>
<version>3.2.0</version>
</dependency>
扩展 HealthChecker 接口实现自己的检查项目,通过/actuator/readiness路径来获取应用的 Readiness Check 的状况。
程序安全退出
K8S为容器生命周期提供了preStop钩子,也就是在准备关闭pod时会调用的。这个接口调用是至少一次,有可能调用多次,需要做好幂等处理。之家云平台主要通过http接口的方式进行preStop的处理。
Dubbo 是通过 JDK 的 Runtime的ShutdownHook 来完成优雅停机的。SpringBoot 1.x 版本的spring-boot-starter-actuator 模块提供了一个 restful 接口,用于优雅停机。添加配置:
endpoints.shutdown.enabled=true #启用shutdown endpoint的HTTP访问
endpoints.shutdown.sensitive=false #不需要验证
生产中请注意该端口需要设置权限,如配合 spring-security 使用。 执行
curl -X POST host:port/shutdown
指令 ,关闭成功便可以获得如下的返回:
{"message":"Shutting down, bye..."}
SpringBoot 2.x的版本没有提供默认的优雅停机的方案,开发者需要自己实现,核心思想是关闭应用服务器的接收请求的线程池。
需要注意事项:
-
用粗暴延时方式执行preStop会延长应用的结束时间,会延缓升级进程。
-
preStop返回的任何结果,集群并不参考。集群只根据preStop调用是否已完成来决定,preStop调用一旦完成,即会发送结束信号给容器。
-
preStop只有在teminated时才会被调用,就是集群主动杀容器时。如果容器因为各种原因自己退出运行以及其它难以处理的异常时是不会激活此调用的,所以不可将工作完全寄托于此机制。参见 https://github.com/kubernetes/kubernetes/issues/55807
-
另外preStop也不严格保证只调用一次。
-
如果没有配置preStop的接口,就一定要保证程序以pid=1的方式运行。
那些踩过的坑
乱码问题
礼品抽奖有个功能是运营上传中奖名单文件到服务器后,服务器返回给前台的文件列表中出现中文乱码,所有的中文文件名全部变成?,英文文件名则正常显示。之后看了代码后发现在转换excel文件的时候这段代码读取了宿主系统的语言配置,所以确定了问题的原因就是系统字符编码设置。 解决方案就是在Dockerfile里面加上操作系统的语言设置:
ENV LANG="zh_CN.UTF-8"
时区配置问题
其中一个应用在上完容器之后发现没有日志文件,登录webshell之后查看发现日志文件提前进行了切割,如图:
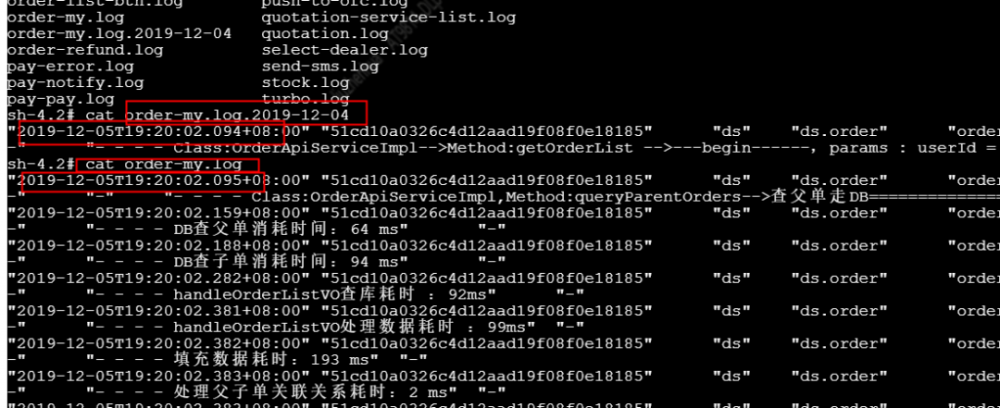
查看容器后的时间后发现时区不对。云平台启动容器时会设置 /etc/localtime文件但没有设置 /etc/timezone。解决方案就是Dockerfile加上时区设置:
RUN echo 'Asia/Shanghai' > /etc/timezone
日志文件不打印
订单的促销项目在切换docker的过程中,测试同学反馈Docker容器的4个实例里,一个实例没有打印日志,另外3个实例有日志。同一编译版本再次发步后,问题重现。登录webshell后查看Tomcat的catalina.out的输出有错误信息:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/app/tomcat/webapps/ROOT/WEB-INF/lib/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/app/tomcat/webapps/ROOT/WEB-INF/lib/slf4j-log4j12-1.6.4.jar!/org/slf4j/impl/StaticLoggerBinder.class]
很明显由于日志组件冲突,同样的类(类的全限定名完全一样)出现在多个不同的依赖Jar包中,即该类有多个版本,并由于Jar包加载的先后顺序导致JVM加载了错误版本的类。使用maven helper插件解除掉冲突jar包解决。
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
下载容器内的文件
绝大多数情况下,是不需要下载容器内文件的。在新系统上线或者旧系统上线引用了新包的时候,会有几率遇到OOM问题,排查问题需要一些堆dump文件和线程栈的dump文件。这些文件需要下载到本地用MAT软件进行分析。目前来讲有2种方案:
-
容器内启动了tomcat/nginx/flask等服务,直接把文件放在这些服务器的服务目录内不就可以下载了。
-
在容器外能控制的服务器上提供个能上传的ftp/http服务,在容器里使用 curl 进行上传操作。
# 使用curl进行ftp上传操作示例
curl -T project.hprof ftp://username:password@ftp.server.com/dump/project.hprof
# 使用curl进行http form 上传示例
curl -F ‘data=@path/to/local/file’ UPLOAD_ADDRESS
CMD的错误使用
Docker本身提供了两种终止容器运行的方式,即docker stop与docker kill。docker kill命令不会给容器中的应用程序有任何gracefully shutdown的机会,它会直接发出SIGKILL的系统信号,以强行终止容器中程序的运行,类似虚拟机的kill -9 。 在dock e r stop命令执行的时候,会先向容器中PID为1的进程发送系统信号SIGTERM,然后等待容器中的应用程序终止执行,如果等待时间达到设定的超时时间,或者默认的10秒,会继续发送SIGKILL的系统信号强行kill掉进程。 在容器中的应用程序,可以选择忽略和不处理SIGTERM信号,不过一旦达到超时时间,程序就会被系统强行kill掉,因为SIGKILL信号是直接发往系统内核的,应用程序没有机会去处理它。 因此我们可以想办法让 JVM 应用以 PID 1 运行即可。
启动命令前的脚本:
CMD java $JAVA_OPTS -jar /app.jar && /usr/bin/nxlog
使用 CMD command param1 param2 这种方式,其实是以shell的方式运行程序。最终程序被执行时,类似于/bin/sh -c的方式运行了我们的程序,这样会导致/bin/sh以PID为1的进程运行,而我们的程序只不过是它fork/execs出来的子进程而已。前面我们提到过docker stop的SIGTERM信号只是发送给容器中PID为1的进程,而这样,我们的程序就没法接收和处理到信号了。
修改后的脚本:
CMD ["java","$JAVA_OPTS","-jar","/app.jar"]
堆外内存的使用
JVM的内存模型里有堆内存和堆外内存之分,多数应用在上容器的平台之后会设置堆内存大小或者堆内存占用比例为容器内存大小的70%-80%。但是对于一些使用了堆外内存的应用(比如netty)来说,堆外内存如果不够的话,也会爆出OOM。在做技术调研工作的时候看到有别的公司遇到此类问题,但是我们在生产环境中并未遇到。
拥抱云平台
电商团队进行容器化的过程中还遇到了很多的问题,在王成刚老师、任卫老师和云平台技术团队的共同努力下都有了完美的解决方案。在电商团队之前已经有云平台团队、二手车事业部完成了全部的应用迁移,容器技术已经能满足之家绝大多数场景,并且在部署、交付等环节给研发和测试同学带来了极大的便捷。非常感谢云平台团队的小伙伴们,做出了一款非常棒的产品。电商团队将全面拥抱云平台,在以后的系统架构设计和业务系统改造中,将会充分考虑到面向容器设计、面向容器编程。
在当今云原生的趋势下,如何让容器技术在企业真正安全可靠的落地是一个值得深思的话题。我们电商团队的生产环境的容器化还处于开始阶段,后面可能还会碰到新的问题,希望能够和大家互相学习。
参考文章:
[1] 面向容器日志的技术实践:
https://yq.aliyun.com/articles/672054
[2]三个技巧,将 Docker 镜像体积减小 90%:
https://www.infoq.cn/article/3-simple-tricks-for-smaller-docker-images
[3] 不要把大型 JAR 包放进 Docker 镜像:
https://www.infoq.cn/article/eULlQ4A3RcaLLQeImQy9
[4] 关于docker安全:
https://www.infoq.cn/article/Wzx9JsLff7Q5vHqSakmH
[5] Java应用Docker化部署GC变长的踩坑经历:
https://juejin.im/post/5b63ff20e51d4519946020b1

正文到此结束
- 本文标签: 空间 XML 开发 dist 删除 线程池 云 MQ 服务器 Presto mina 幂等 安全 管理 时间 Docker 操作系统 build http Java环境 虚拟化 IO Nginx 模型 pom Agent 负载均衡 centos CSS 代码 实例 参数 ftp ECS 下载 汽车之家 root springboot maven 缓存 js 集群 redis 解析 快的 企业 主机 文章 ORM 探针 高可用 自动化 JVM https cat 数据 GitHub Kubernetes REST Uber ask 汽车 业务层 web Spring Boot 端口 架构设计 git 2019 产品 开发者 Google HTML 软件 Webapps 运营 ACE Service java id cmd Lua ip 部署 进程 UI 内存模型 App 插件 dubbo src Word Security spring 希望 测试 Dockerfile shell tag 线程 系统架构 Netty 域名 Excel 开源 lib 生命 message 目录 文件系统 编译 乱码 tomcat 微服务 tar 配置 RESTful
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

