最简单的 Java内存模型 讲解
本博客系列是学习并发编程过程中的记录总结。由于文章比较多,写的时间也比较散,所以我整理了个目录贴(传送门),方便查阅。
并发编程系列博客传送门
前言
在网上看了很多文章,也看了好几本书中关于JMM的介绍,我发现JMM确实是Java中比较难以理解的概念。网上很多文章中关于JMM的介绍要么是照搬了一些书上的内容,要么就干脆介绍的就是错的。本文试着用比较简洁的语言介绍清楚JMM到底是什么,解决了Java编程中的哪些问题。不求深入,但求让读者看地清楚,看完之后能对JMM有个比较直观的认识。
本文是笔者在总结了网上的多篇文章之后加上自己的理解整理出来的,内容上可能和JMM标准存在偏差,有问题还望留言指出。
什么是JMM
JMM是一个规范,我从 JSR113 标准中摘录了一段对JMM的简单介绍:
JavaTM virtual machines support multiple threads of execution. Threads are represented by the Thread class. The only way for a user to create a thread is to create an object of this class; each thread is associated with such an object. A thread will start when the start() method is invoked on the corresponding Thread object. The behavior of threads, particularly when not correctly synchronized, can be confusing and counterintuitive. This specification describes the semantics of multithreaded programs written in the JavaTM programming language; it includes rules for which values may be seen by a read of shared memory that is updated by multiple threads. As the specification is similar to the memory models for different hardware architectures, these semantics are referred to as the JavaTM memory model. These semantics do not describe how a multithreaded program should be executed. Rather, they describe the behaviors that multithreaded programs are allowed to exhibit. Any execution strategy that generates only allowed behaviors is an acceptable execution strategy.
上面的英文简要翻译如下:
Java虚拟机支持多线程执行。在Java中 Thread 类代表线程,创建一个线程的唯一方法就是创建一个 Thread 类的实例对象。当调用了对象的start方法后,相应的线程将会执行。
线程的行为有时会令人困惑而且和我们的直觉相左,特别是在线程没有正确同步的情况下。本规范描述了JVM平台上多线程程序的语义(含义),具体包括一个线程对共享变量的写入何时能被其他线程“看到”。由于本规范和不同硬件平台上的内存模型相似,所以将本规范命名为Java内存模型。
从上面这段英文介绍中我们可以得到关于JMM的简要信息:
- JMM是一个和多线程相关的规范;
- JMM描述了JVM平台上多线程程序的语义(含义),具体包括一个线程对共享变量的写入何时能被其他线程“看到”。
但是只看上面对于JMM的简单解释,我相信大多数人还是会很晕,对JMM具体是什么还是很模糊。
不过我在上面的这段介绍中又发现了一段对JMM介绍的关键信息:
As the specification is similar to the memory models for different hardware architectures, these semantics are referred to as the JavaTM memory model. (JMM和硬件平台上的内存模型相似)
上面的介绍中提到JMM和硬件平台上的内存模型相似,那么我们就先看看硬件平台上的内存模型究竟是什么?
内存模型
有点计算机基础的同学都应该知道,程序执行的时候其实就是一条条指令在CPU上执行的过程,而指令的执行又势必会涉及到数据的读取和写入。说到数据,就又不得不提到一个重要的硬件:内存。在计算机中,内存是数据的“收集站”,数据从键盘、网络、文件也有可能是一些传感器设备进入到内存,然后CPU从内存中读取这些数据并对这些数据进行“加工”后再写回到内存。
上面整个过程看起来很完美,但是就像人与人之间是有差别的一样,硬件和硬件之间也存在差别。CPU的运行速度就和尤塞恩·博尔特的速度一样(飞一样的速度),而内存的运行速度和CPU相比就像我的跑步速度和博尔特比一样,根本不是一个数量级的。 CPU和内存运行速度的差距会导致整个系统性能的下降,因为CPU每次读写数据都要等待内存。(木桶理论在计算机中的体现)
但是这个问题根本就难不倒我们伟大的硬件工程师们。“聪明”的工程师们在CPU中加入了一层CPU高速缓存层。 这个缓存的运算速度和CPU相当,当指令在CPU上运行的时候,会先将运算需要的数据从内存中复制一份到CPU的高速缓存当中,那么CPU进行计算时就可以直接从它的高速缓存读取数据和向其中写入数据,当运算结束之后,再将高速缓存中的数据刷新到主存当中。 (现代CPU其实是有多级缓存的,但是为了简单起见就没介绍了,因为我觉得这里不介绍CPU多级缓存不会影响对JMM的理解)
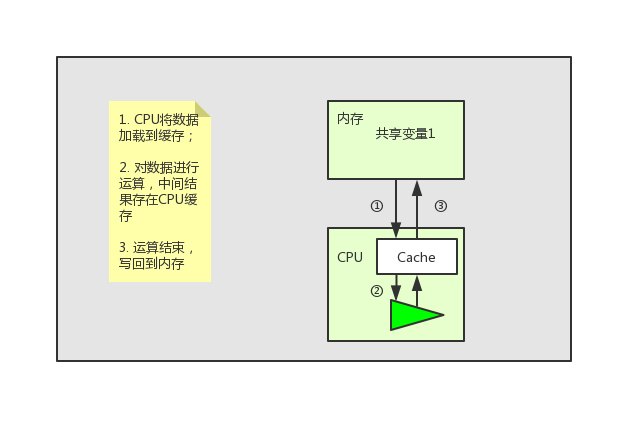
世界好像又重归于平静,一切又显得那么美好。但是其实问题才刚刚开始。
原子性问题
上面提到 CPU 进行运算时需要将共享变量先加载到CPU缓存中,运算结束后再将最新数据写回共享内存。这种看起来完美的工作方式其实存在一个问题,下面我们就以上面的图片为列子,说下这个问题。
假如现在系统环境是 单核CPU+多线程工作模式,共享变量初始值是1,线程1和线程2分别对这个共享变量进行加一操作,理论上这个共享变量最后的值是3。我们看看程序的执行行为是否会和我们预期的一致。
线程对一个共享变量加一的过程需要分三步进行:
step1: read共享变量到工作内存 step2:对共享变量+1 step3:将共享变量写回主内存
但是上面的三个步骤并不是原子操作,也就是说可能会被打断。现在假如线程1已经执行完了step1,但是这时CPU时间片用完了,线程2获得执行机会也从内存中加载共享变量的值(此时共享变量的值还是1),最后两个线程执行完step2和step3之后共享变量的值是2,并不是3。
出现上面问题的原因就是对共享变量的加一操作并不是原子性操作, 所谓原子性操作是指一个或多个操作,要么全部执行且在执行过程中不被任何因素打断,要么全部不执行 。在多线程环境下原子性问题可能会造成错误的执行结果。
原子性问题是内存模型存在的第一个问题,但是内存模型存在的问题不止这一个。
缓存一致性问题
随着科技的进步,对CPU的需求越来越高。但是摩尔定律的失效注定单个CPU的性能已经很难再大幅度提升。此时“聪明”的硬件工程师又出场了,他们创造性地将多个CPU集成到一个上,这样CPU的性能不就能成倍地增长了么。多核CPU的确带来了CPU性能的提升,但是这却“害苦”了软件工程师,因为多核CPU大大提升了多线程编程的难度。
多核CPU进行多线程编程时存在的一个显著问题就是 缓存一致性问题 。
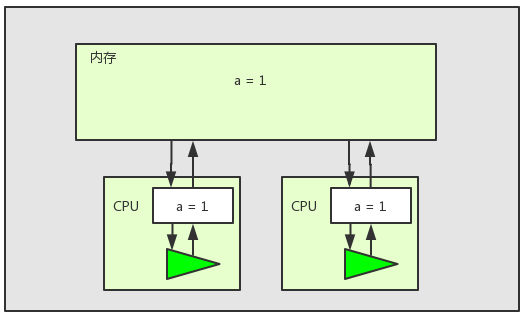
以上图为例,在多核CPU多线程环境下,两个线程对共享变量a进行加1操作。两个线程都将共享变量a在内存中的值加载到了工作内存中,如上图所示。但是此时线程2失去了CPU时间片,而线程1还是继续执行并成功将变量加一。当线程1执行完之后,内存中的值如下图所示:
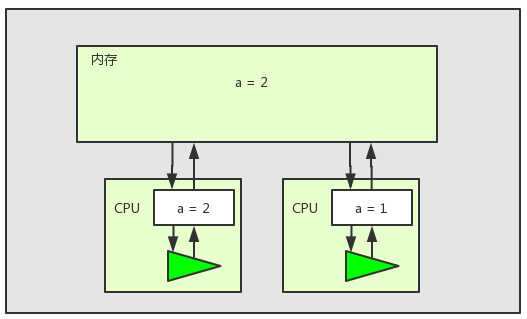
我们发现此时线程2中的变量a的值已经是过期的值,并不是变量a最新的值,所以当线程2执行完之后变量a并不是我们想要的值3。这个问题就是多核CPU中缓存一致性问题。
和上面的原子性问题不同,缓存一致性问题只有在多核多线程环境下才会出现,而原子性问题只要是在多线程环境下都可能会出现。
指令重排序问题
所谓的指令重拍是指CPU为了是内部的处理器单元得到充分的应用,可能会对代码进行乱序执行的行为。这个指令重拍的行为在单线程环境下不会有任何问题,但是在多线程环境下程序就可能出现错误的执行结果。
这边不准备会指令重排进行深入的讨论,大家只要知道指令重排序是一种CPU性能优化的行为,而这个行为在多线程环境下可能会导致程序错误的执行结果。
通过上面分析我们看到:随着CPU性能的不断提升,随之出现了原子性问题、缓存一致性问题和指令重排序问题。细心的我们会发现这些问题其实是和多线程环境下共享变量访问的原子性、可见性和有序性问题一一对应的。
内存模型的作用
为了既保证CPU的高效执行,有保证共享内存读写的正确性(原子性、可见性和有序性),人们定义了内存模型。内存模型是一个规范,这个规范能保证共享内存读写的正确性。
Java内存模型
上面提到内存模型的出现是为了解决共享变量读写的原子性、可见性和有序性问题,但是没有具体讲怎么解决的。下面就来看看在Java中的内存模型JMM。
Java内存模型是内存模型在Java语言中的体现。这个模型的主要目标是定义程序中各个共享变量的访问规则,也就是在虚拟机中将变量存储到内存以及从内存中取出变量这类的底层细节。通过这些规则来规范对内存的读写操作,保证了并发场景下的可见性、原子性和有序性。
Java内存模型规定了所有的变量都存储在主内存中,每条线程还有自己的工作内存,线程的工作内存中保存了该线程中是用到的变量的主内存副本拷贝,线程对变量的所有操作都必须在工作内存中进行,而不能直接读写主内存。不同的线程之间也无法直接访问对方工作内存中的变量,线程间变量的传递均需要自己的工作内存和主存之间进行数据同步进行。
而JMM就作用于工作内存和主存之间数据同步过程。他规定了如何做数据同步以及什么时候做数据同步。

以上图片来自(https://www.hollischuang.com/archives/2550)
简单总结
JMM是一个和多线程编程的相关概念,是内存模型在Java平台上的体现。这个模型保证了在多核CPU多线程编程环境下,对共享变量读写的原子性、可见性和有序性。
本篇博客只是简单讲了下JMM的概念,以及解决哪些问题。具体JMM怎么解决原子性、可见性和有序性问题的,后续会写博客分析。
参考
- https://yq.aliyun.com/articles/715712
- https://yq.aliyun.com/articles/720689?spm=a2c4e.11163080.searchblog.24.16c62ec1rUruam
- https://www.hollischuang.com/archives/2550
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

