从JVM堆内存分析验证深浅拷贝
在重写性能测试框架的过程中,遇到一个问题,每个线程都要收集一些统计数据,但是在我之前的框架Demo里面有一种情况:单一的threadbase线程任务,多线程并发。我是直接使用的这个对象,如果每个线程threadbase包含统计信息的话,多线程执行一个任务肯定会出现不安全的情况,如果加锁又会导致“多线程”失去意义。故而采用了创建任务时将对象按照线程数拷贝一份,保证每个线程执行的threadbase对象都是独立绑定的。
顺便学习了一番Java深浅拷贝对象的知识,发现又学到了一点,关于深浅拷贝的原理和演示从代码级别来讲已经很多了,加之之前学到了Java堆内存相关的一些技巧,我决定使用内存分析来演示一下深浅拷贝。
关于概念性的问题,大家可以自行搜索,这里不便多说,直接开搞。
拷贝对象a分三种方式:1、直接创建另外一个对象a1=a;2、浅拷贝一个对象a2;3、深拷贝一个对象a3。
理论来家,1只会在堆内存有一个A对象实例,2会有两个A对象实例,3会有三个A对象实例。如果该对象还包含了对象B的话,那么1只会产生一个B实例,2也只会产生一个B实例,3会产生两个对象B实例。
到底是不是这样呢,实践是检验整理的唯一标准。
下面是我的测试代码:
package com.fun;
import com.fun.frame.SourceCode;
import java.io.Serializable;
public class AR extends SourceCode {
public static void main(String[] args) {
waitForKey("1");
HeapDumper.dumpHeap("1",true);
Tttt clone = tttt.clone();
waitForKey("2");
HeapDumper.dumpHeap("2",true);
Tttt tttt1 = deepClone(tttt);
HeapDumper.dumpHeap("3",true);
waitForKey("3");
}
static class Tttt implements Cloneable, Serializable {
public Sss sss = new Sss();
private static final long serialVersionUID = 4989553780571753462L;
public Tttt clone() {
try {
return (Tttt) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return null;
}
}
static class Sss implements Cloneable, Serializable {
private static final long serialVersionUID = -5487147719650620894L;
public Sss clone() {
try {
return (Sss) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return null;
}
}
}
我用了三次暂停,分别标记了三个节点,然后通过使用 jconsole 中的 mbean 工具类获取堆内存的转储文件,其他方法请参考往期文章 如何获取JVM堆转储文件 ,大家也可以在代码中直接使用
dump工具类的方法,参考往期文章 获取JVM转储文件的Java工具类 。
下面是 jconsole 的操作界面:
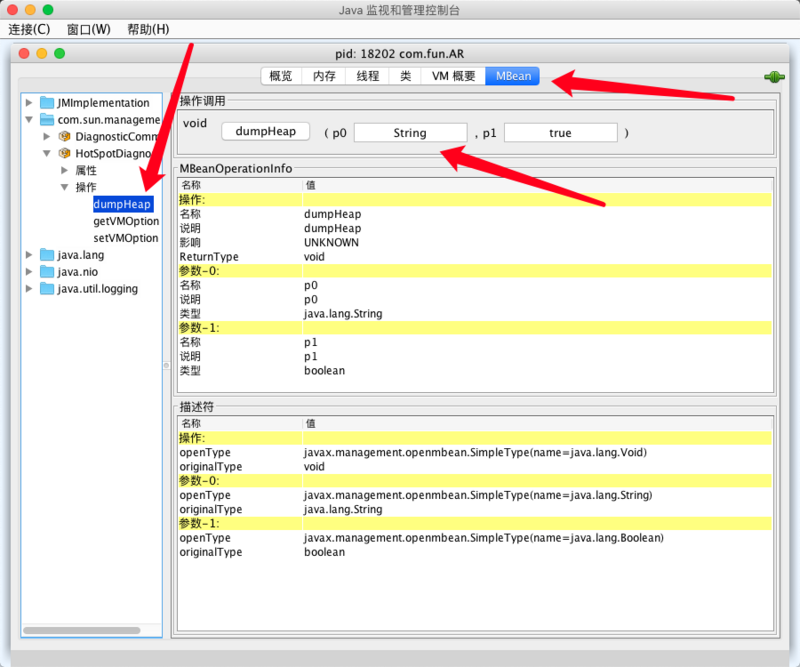
p0是生成转储文件的文件名,不能跟已存在的文件重复,不然会报错。dumpheap的默认路径是当前项目的工作路径。
使用 jhat -port 8001 1 这样的命令即可启动一个服务,然后访问 http://localhost:8001/ 看到堆内存使用情况。
查看访问是先找到想要查看的类名,点击之后选择 instance 实例选项即可看到实例个数。
下面是Ttt对象实例的情况,按照1、2、3排列。



果然1、2、3个Ttt对象实例,符合预期。
下面是Sss对象实例的情况:



果然1、1、2个Sss对象实例,符合预期。
完美收工,哈哈!
- 郑重声明 :文章首发于公众号“FunTester”,禁止第三方(腾讯云除外)转载、发表,事情原委 测试窝,首页抄我七篇原创还拉黑,你们的良心不会痛吗?
正文到此结束
热门推荐










相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

