SpringBoot+MyBatis+MySQL读写分离(实例)
1、 引言
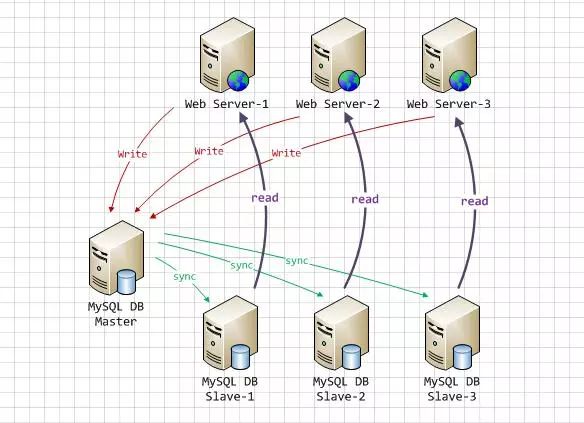
读写分离要做的事情就是对于一条SQL该选择哪个数据库去执行,至于谁来做选择数据库这件事儿,无非两个,要么中间件帮我们做,要么程序自己做。因此,一般来讲,读写分离有两种实现方式。第一种是依靠中间件(比如:MyCat),也就是说应用程序连接到中间件,中间件帮我们做SQL分离;第二种是应用程序自己去做分离。这里我们选择程序自己来做,主要是利用Spring提供的路由数据源,以及AOP
然而,应用程序层面去做读写分离最大的弱点(不足之处)在于无法动态增加数据库节点,因为数据源配置都是写在配置中的,新增数据库意味着新加一个数据源,必然改配置,并重启应用。当然,好处就是相对简单。
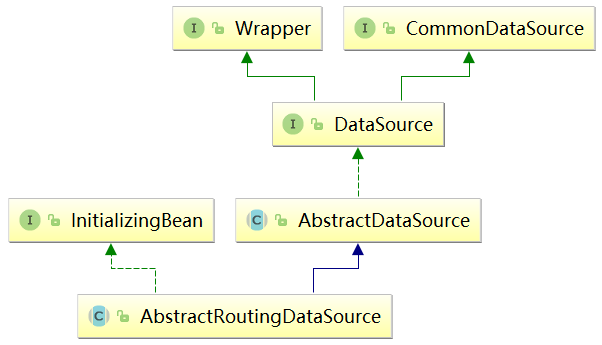
2、 AbstractRoutingDataSource
基于特定的查找key路由到特定的数据源。它内部维护了一组目标数据源,并且做了路由key与目标数据源之间的映射,提供基于key查找数据源的方法。
3、 实践
关于配置请参考《MySQL主从复制配置》
https://www.souyunku.com/2017/08/26/mysql-Master-Slave
3.1、 maven依赖
3.2、 数据源配置
application.yml
多数据源配置
这里,我们配置了4个数据源,1个master,2两个slave,1个路由数据源。前3个数据源都是为了生成第4个数据源,而且后续我们只用这最后一个路由数据源。
MyBatis配置
由于Spring容器中现在有4个数据源,所以我们需要为事务管理器和MyBatis手动指定一个明确的数据源。
3.3、 设置路由key / 查找数据源
目标数据源就是那前3个这个我们是知道的,但是使用的时候是如果查找数据源的呢?
首先,我们定义一个枚举来代表这三个数据源
接下来,通过ThreadLocal将数据源设置到每个线程上下文中
获取路由key
设置路由key
默认情况下,所有的查询都走从库,插入/修改/删除走主库。我们通过方法名来区分操作类型(CRUD)
有一般情况就有特殊情况,特殊情况是某些情况下我们需要强制读主库,针对这种情况,我们定义一个主键,用该注解标注的就读主库
例如,假设我们有一张表member
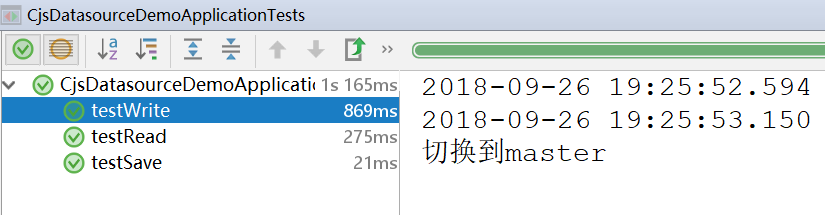
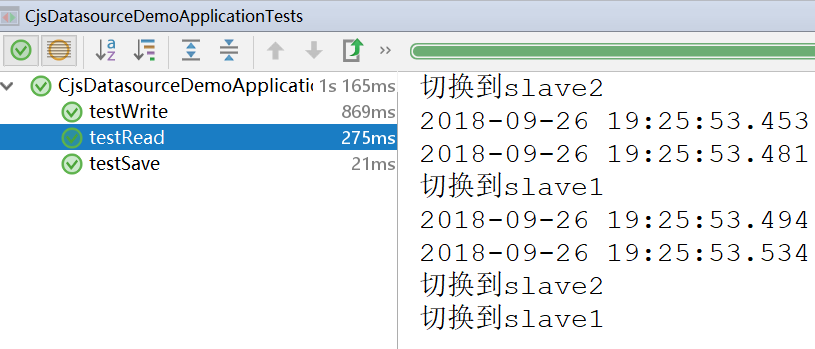
4、 测试
查看控制台

5、 工程结构
来源:http://www.cnblogs.com/cjsblog/p/9712457.html
6、 参考
https://www.jianshu.com/p/f2f4256a2310
http://www.cnblogs.com/gl-developer/p/6170423.html
https://www.cnblogs.com/huangjuncong/p/8576935.html
https://blog.csdn.net/liu976180578/article/details/77684583
正文到此结束
热门推荐









相关文章






Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

