Cache演进史
不可忽缺的Cache
缓存作为计算机领域中最常见的组件,一直扮演着很重要的角色。在操作系统领域,通过L1,L2,L3三级Cache设计来提升CPU和内存间的数据访问速度;在类Unix操作系统中,通过Page Buffer和Page Cache来提升磁盘的IO效率;在企业级应用开发中,Cache一样是高并发场景下提升性能的必备组件,同时,随着NoSQL中间件的普及,和近些年来微服务技术的落地,我们也慢慢从单一的应用内Cache,迈向了分布式Cache。
作为一个后端开发人员,了解并合理的运用Cache,更是一项必备技能。工欲善其事,必先利其器,我们不仅仅要懂得运用Cache框架,同时也要熟悉Cache框架设计背后的背景和逻辑,继而如果从设计的角度抽象出如何设计一个优良的Cache框架。
本文主要就Java开发中的应用内缓存进行介绍,分析其主要原理,并从Cache框架发展历史的角度,层层递进,道出Cache框架的设计原理。
Cache使用场景
在服务端开发过程中,缓存通常用户提高接口的性能,主要的使用场景有一下几种
- 读多写少,尤其是在高并发场景下;
- 静态数据,或实时性要求较低的数据;
- 数据构建复杂,比较耗时
通过以上的场景看到,缓存主要用于提升数据访问性能,由此可以给出缓存的一个大致定义:
In computing, a cache is a hardware or software component that stores data so future requests for that data can be served faster
Cache实现的演化
基于ConcurrentHashMap
从缓存的定义可以看出,缓存是将数据存储在某种存储介质中,那么必然需要一个get和put方法分别用于查询和新增/修改缓存数据,那么基于HashMap的方式是最容易想到的一种实现,但是由于缓存通常在并发环境下使用,所以线程安全的ConcurrentHashMap成为最佳选择,下面是一个简单的缓存实现
void initCache(){
cache=new ConcurrentHashMap();
loadCacheFromRemote ();
}
Object get(Key)
void loadCache(Key)
基于ConcurrentHashMap实现的缓存实现简单,读写性能高,但是缓存通常是在某个较短的时间内才有效,而且Map中的数据不能无限制的增长,需要一种过期机制或者淘汰策略来移除已经失效的缓存。
LRUHashMap
通常来说需要缓存的数据都是热点数据,那么就可以根据缓存的热度来对缓存进行排序,如果要对热度进行量化,有两个维度可以参考,访问时间和访问频率。
时间维度:越久未被访问的缓存,热度越低,同理,最近访问的缓存,热度越高,所以如果采用队列来存储缓存,可以将缓存按照访问时间排序,每次缓存访问后,将其移到队首,队尾的缓存就代表最久未被访问,这种缓存淘汰算法通常叫做LRU(Least Recently Used)
频率维度:缓存的访问频率越高,代表下一秒被访问的概率越大,所以越高,代表缓存的热度值越高。这种基于访问频率的缓存淘汰算法叫做LFU(Least Frequently Used)
从底层数据结构实现上,通常用链表的方式实现LRU算法,时间复杂度是O(1),而基于频率的LRU算法,因为涉及到排序,时间复杂度通常为O(logN),不过目前也存在多种近似频率统计的算法被实现并运用到缓存中,而且根据大量实践结果表明,采用LRU算法的缓存命中率更高,所以LRU是缓存框架设计优先选用的算法。
在Java中,如果我们要实现一个基于LRU算法的缓存,只需要继承 LinkedHashMap 并重写 removeEldestEntry 方法
class LRUHashMap extends LinkedHashMap{
private int maxSize;
@Override
protected Boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > maxSize;
}
}
但是这种实现方式并非线程安全,可以通过 Collections.synchronizedMap 方法将其转化为一个线程安全的版本。
以上两种方式实现的缓存虽然满足了缓存的基本使用场景,但是从功能上无法满足缓存指定时间后过期,缓存自动刷新,缓存未命中后自动加载等特性,为了弥补易用性上的不足,需要设计一个完整的缓存框架。
Guava Cache
Guava是Google开源的一个Java框架,Guava Cache作为其中的一个模块,底层基于LRU算法,功能上比较丰富,简单易用,一直以来都是比较受欢迎的缓存框架。
主要的功能包含
-
Population
缓存的查询,删除,更新和自动刷新
-
Eviction
缓存能够按照特定策略淘汰
- Size-Based:基于缓存的容量
- Time-Based:基于缓存的存活时间
- Reference-Based:提供了StrongReference,SoftReference,WeakReference三种缓存引用类型,并可以分别指定Key和Value的Reference类型,借助JVM的垃圾回收机制来对缓存进行清理。
-
Statistics
缓存的统计信息,主要包含命中率,命中请求数,Miss请求数,缓存总数等
-
Listener
提供对缓存生命周期变化的监听,例如通过RemovalListener实现缓存移除事件的监听处理。
下面是Guava Cache的一个示例
//创建一个Cache
Cache<String, Integer> cache = CacheBuilder.newBuilder() . recordStats()
.initialCapacity(100).maximumSize(1000)
.expireAfterWrite(300,TimeUnit.SECONDS)
.refreshAfterWrite(5, TimeUnit.MINUTES)
.build(new CacheLoader<String, Integer>() {
@Override
public Integer load(String key) {
return loadFromRemote();
}
});
//Cache 查询
Cache. getIfPresent(String key)
Cache.get(String key, Callable<? extends V> loader)
Caffeine Cache
从性能和功能上来说,Guava Cache是一个优良的框架,但是由于Guava最初的版本基于jdk1.5,Cache模块底层采用了ConcurrentHashMap一样的结构,在LRU算法实现上,底层采用ConcurrentLinkedQueue类型的RecencyQueue来记录缓存所有访问记录,并在当缓存发生写入或者查询结果过期时,将RecencyQueue的数据遍历取出后写入到一个LRU AccessQueue后来淘汰过期的数据。随着ConcurrentLinkedQueue中访问记录的不断写入和移除,大量的对象需要回收,增加了GC的压力。
同时由于LRU算法的局限性,在某些场景下(例如对数据顺序轮询访问)命中率较低;Guava Cache中某些操作采用同步执行的方式,限制了其吞吐量。所以,Caffeine针对以上问题,提出了一种新的方案,并且在API上完全兼容Guava Cache。
从功能上来说两个缓存框架基本类似,更多的是底层实现机制的差异,主要包含以下方面:
- 采用了Window-TinyLRU算法,结合了LRU和LFU的特征,相对于LRU算法有更高的命中率
- 采用RingBuffer记录访问顺序,避免了GC的问题
- 采用异步RingBuffer Task的方式,对缓存刷新,移除等操作采用异步的方式执行
值得一提的是Window-TinyLRU算法,底层采用一个LRU的Window队列作为缓冲层,以及一个SLRU(Segmented LRU)队列作为Main Cache,同时对于MainCache中的缓存,使用O(1)时间复杂度的CountMin Sketch算法进行频率统计,整体的算法示意图如下:

从下面的一组压测结果数据,可以更加直观的看到吞吐量对比
环境信息:MacBook Pro i7-4870HQ CPU @ 2.50GHz (4 core) 16 GB Yosemite.
Read (75%) / Write (25%) 6个线程并发读, 2个线程写
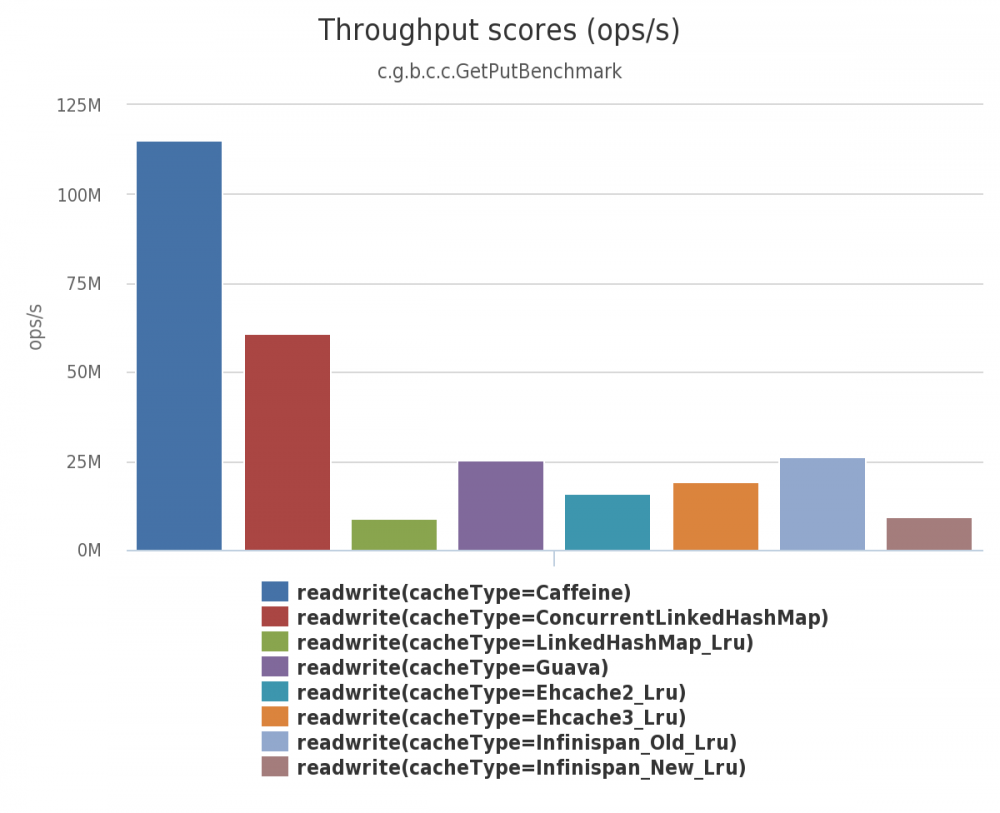
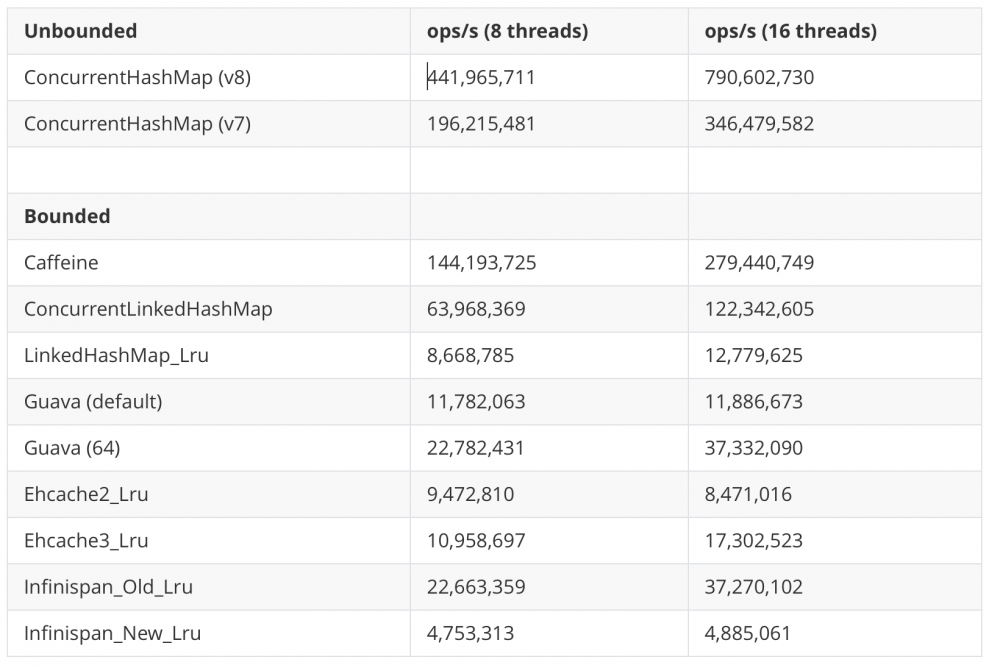
在Azure G4 16核 224 GB内存云服务器上的结果如下
Read (75%) / Write (25%)
 命中率对比
命中率对比 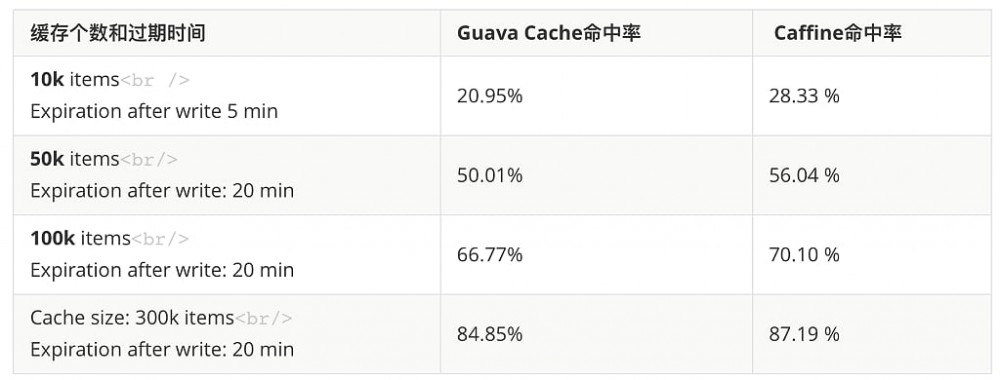
更多结果可以参考 Caffeine官方Wiki
对比与分析
通过以下表格可以更加直观的看到各种Cache实现方式的差异
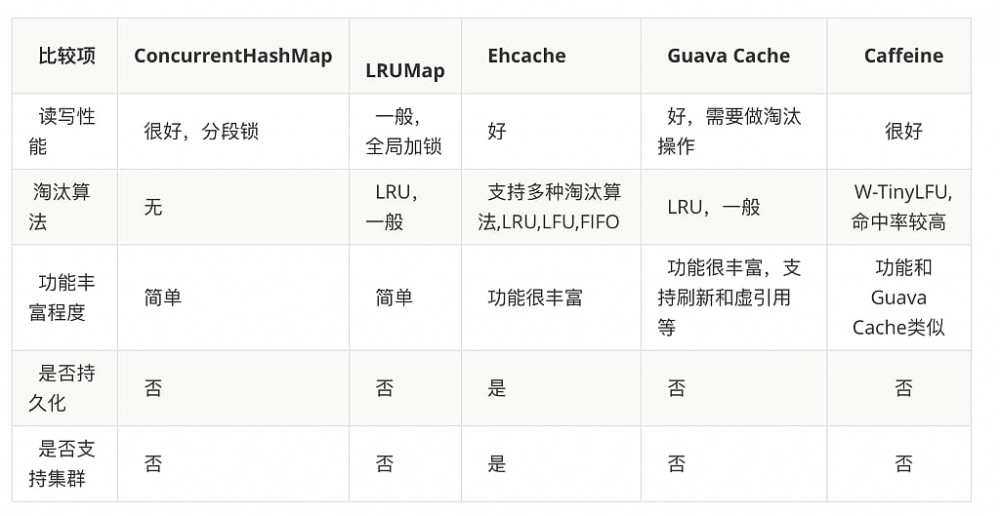 面对如此多的实现方式,根据业务场景选择最适合才是最佳方案,ConcurrentHashMap虽然在功能上较为简单,但是在吞吐量上却更具有优势,而成熟的Cache框架提供丰富多样的特性,也不可避免的因为实现方式的差异带来性能上的损失,所以框架的选择也是一个利弊权衡的过程。
面对如此多的实现方式,根据业务场景选择最适合才是最佳方案,ConcurrentHashMap虽然在功能上较为简单,但是在吞吐量上却更具有优势,而成熟的Cache框架提供丰富多样的特性,也不可避免的因为实现方式的差异带来性能上的损失,所以框架的选择也是一个利弊权衡的过程。
正文到此结束
- 本文标签: 并发 https UI key build queue 分布式 微服务 remote map Collections 企业 生命 id 缓存 unix NOSQL 遍历 同步 删除 服务端 synchronized 服务器 sql 时间 开源 http MQ JVM java 安全 Google 开发 ask 垃圾回收 ConcurrentHashMap 云 压力 API 操作系统 统计 Collection HashMap 线程 IDE list core IO 2019 数据 value src cache 高并发
- 版权声明: 本文为互联网转载文章,出处已在文章中说明(部分除外)。如果侵权,请联系本站长删除,谢谢。
- 本文海报: 生成海报一 生成海报二
热门推荐










相关文章

近期评论
-
666 666
-
666
-
文章和留言都翻到11页了 没有OOM
-
-
朋友,翻页到11页,及以后,会出现OOM,无法访问
-
-
-
-
版本号是多少,你可以下载哪个代码仓库,jdk选1.8 直接跑就行
-
Loading...
![[HBLOG]公众号](https://www.liuhaihua.cn/img/qrcode_gzh.jpg)

